(本記事は 2018年の技術書展4にて頒布した『WANTEDLY TECH BOOK 4』に掲載した文章です)
はじめに
Redis の Sorted Set を使った一覧画面の実装パターン
Web サービスにおいて Redis の Sorted Set は高速なランキングの実現のためにしばしば用いられる。ランキング・データを Redis に載せることで、高速なデータの取得・ページング・件数計算などが可能になる。ランキングのように順序付けされたコンテンツは Web サービスの一覧画面と呼ばれるページにおいて存在するが、このような画面においてはしばしばリテンションが重要である。レスポンス速度はこのリテンションに対して影響を与えるため、高速な実装が求められる。
一方、時系列で考えた場合、一覧画面の要件はサービスの扱うコンテンツ数が増加するに従って複雑化する。例えば、ユーザーが適切なコンテンツを発見できるようにする必要が出てきて、そのために様々な条件による絞り込みや検索、あるいはパーソナライズされた推薦と言った機能が必要になってくる。
これらの機能をどのように実現したら良いだろうか。通常、絞り込みに使われるようなコンテンツのデータはリレーショナルデータベースに保存されている。一方で、検索の実現には Elasticsearch などの全文検索エンジンが採用されることが多い。また、昨今では機械学習が活用されることも多いが、そのような処理を行うためのライブラリは Python が充実している。このように、ユーザーに価値を提供できる一覧画面に求められる機能は多く、またそれを実装するために最適な技術は必ずしも一つには定まらない。
したがって、複数の異なるシステムコンポーネント−データベースかもしれないしマイクロサービスかもしれない−を用意し、それらを組み合わせることによって一覧画面を実現することが考えられる。しかしこのとき、各システムコンポーネントをどのような方法で統合するのかということが課題になる。
既に述べたように Redis の Sorted Set はランキングに利用されることが多いが、和集合・積集合など組み込みの集合演算の命令を使うことで絞り込みや検索、あるいはパーソナライズと言ったより高度な機能を実現することができる。そこで、異なるシステムコンポーネントから集めた情報をそれぞれ別個の Redis の Sorted Set にキャッシュした上で、それを集約計算して一覧画面に必要な情報を算出するような構成を考えることができる。
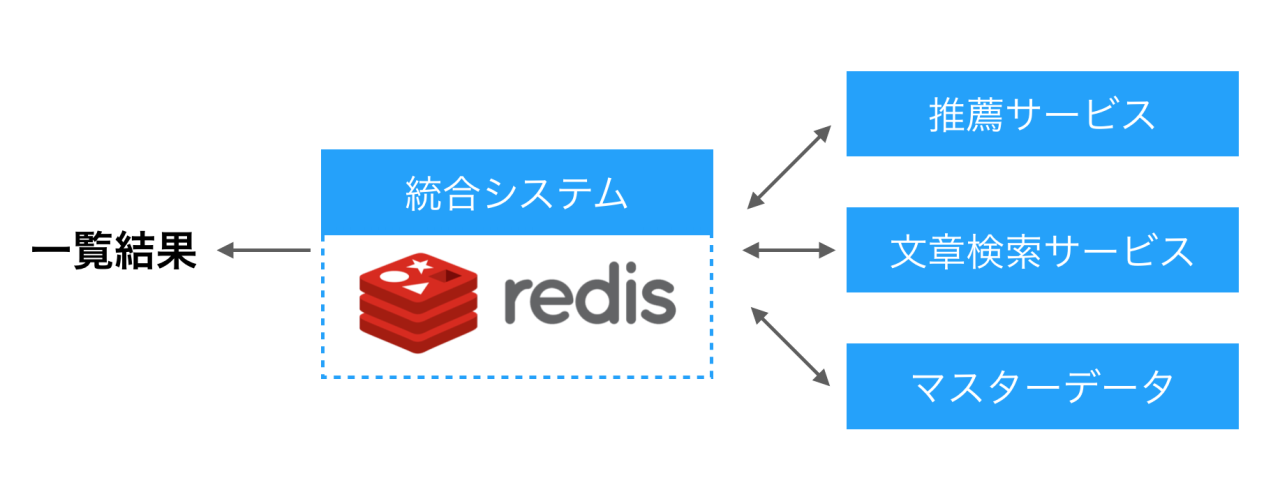
この構成では、任意のシステムコンポーネントからの情報をスコア付きの集合とみなした上で統合することができる。また、レスポンスに必要な全てのデータは一度 Redis に乗るため、計算の内容も様々である各システムコンポーネントがサービスとして求められているレスポンス速度を直接満たさなくても全体として高速に動作すると言った利点もある。
事例
Wantedly Visit では数十万件の募集が存在するが、その一覧画面( https://www.wantedly.com/projects )は上記のような要件を持つ一例である。この画面は実際にこの構成とこれから紹介する RedBlocks を使って実現されている。
実現する上での課題
課題1: オブジェクト指向プログラミングと Redis のコマンド体系のインピーダンス・ミスマッチ
このように Redis の Sorted Set を用いることで一覧画面に必要な機能を実現することができるわけだが、その実装を Redis のコマンドをそのまま呼び出す形で行うと、Ruby などのオブジェクト指向プログラミング言語に於いては高い可読性・変更容易性を実現することができない。
具体的には、Redis のコマンド体系が命令的なものであるため、それをそのまま利用すると手続き的なプログラムになってしまう。この問題は、 単純なキャッシュ目的で Redis を利用しているときには大きく問題にならないが、今回述べたように複雑なシステムを構築する際には問題となる。具体的には、何かアプリケーションの変更を行うときに変更箇所を見つけ出すことが難しかったり、複数の箇所を変更する必要が生じる(変更に対してモジュラでない、関心が分離されていない、と言った状態になる)。
# 非常に単純な集合演算を書くだけでも多くの命令が必要にになる
c = Redis.new
c.zadd("src1", [[32.0, "a"], [64.0, "b"]])
c.expire("src1", 60)
c.zadd("src2", [[44.0, "a"], [21.0, "c"]])
c.expire("src2", 60)
c.zinterstore("dest", ["src1", "src2"])
c.expire("dest", 10)
c.zrevrange("dest", 0, 5) #=> ["a"]
c.zcard("zcard") #=> 1
通常、リレーショナル・データベースをオブジェクト指向の言語から利用する場合、集合指向との概念的な差異(あまり良いメタファーとは言えないが「インピーダンス・ミスマッチ」と呼ぶことがあるので本稿でも用いる)が問題になるため、O/R Mapper による抽象化を行った上で利用することが多い。同様の理由で、Redis の Sorted Set を Ruby から利用する際も OOP に即した形で抽象化を行うことでこの問題を解決することが必要になる。
解消すべき差異の例として、クラスベースの OOP においては、クラスはそれ自体で直接アプリケーションに必要な仕事を果たすわけではなく、インスタンス化を通じてそれを行う。Redis の Sorted Set にクラスとインスタンスのような概念は無いため、key の階層化を通じてこれを実装する必要がある。
課題2: 実装に必要な多くの詳細
- キャッシュの存在の有無をチェックしてなければデータを取得し Redis に保存する
- キャッシュが無い時間が存在しないように差分更新にする
- 直列依存性のないコマンドのパイプライン実行
- Redis の key に使う名前
このような実装詳細を隠蔽することで、アプリケーションを開発する際、
- サービスの仕様として各システムコンポーネントをどう組み合わせるか(AND なのか OR なのか、スコアをどう組み合わせるか)
- それぞれの計算段階におけるデータをどの程度キャッシュするか
と言った統合に関する仕様(これはサービスの価値に直結する)にプログラマは集中できるようになる。
RedBlocks
具体的に上記のような問題を解決するために、RedBlocks という Ruby ライブラリ(gem)を用意した。
以降では、RedBlocks を通じてどのように複数のシステムコンポーネントを組み合わせるかを、実際の一覧画面の実装を通じて紹介する。その後、いくつかの実装詳細について言及し、最後にまとめとする。
Case Study: RedBlocks を用いた一覧画面の実装
この章では、課題1として述べたオブジェクト指向プログラミングと Redis のコマンド体系のインピーダンス・ミスマッチがどのように解決できているのかを実例を通して説明する。そのために、次のような一覧画面を想定する。
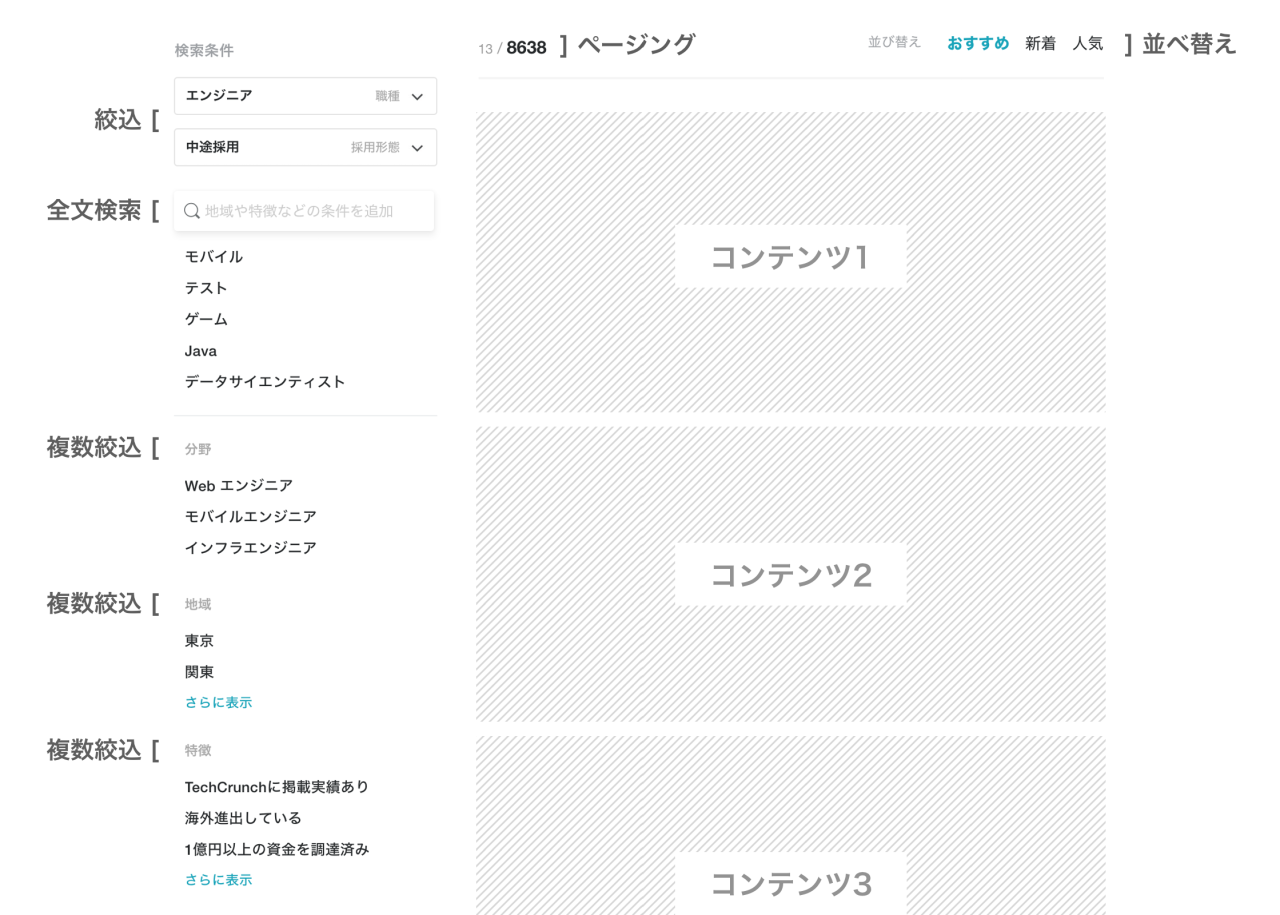
この画面には、主に次の4つの機能が備わっている。また、共通する機能として件数表示とページングができる。
- ランキング(初期状態)
- 絞り込み
- 全文検索
- パーソナライズ(ユーザー登録して利用している場合)
これらの機能を順次実装していき、最後にそれをユーザーの操作に応じて行う service クラスを実装する。
1. ランキング
ほぼ全てのサービスにおいて、一覧画面ではコンテンツ(以下、要素)をどのような優先度で表示するのかということを考える必要がある。これはランキングに相当する。全てのユーザーに同じ順番で見せる場合、ランキングを一つだけ用意すれば良い。ランキングは、それぞれの要素に対してスコアが付いた集合、と捉えられるため、Redis の Sorted Set を利用して実装することができる。
ここでは、一覧画面が扱う要素として募集(Project)を想定した上で、カラムとして monthly_page_view を持った Project というActiveRecord モデルがあるするとする。このカラムの値を利用して PV ベースのランキングを作成したい。このための RedBlocks を用いたコードは次のようになる。
class PageViewSet < RedBlocks::UnitSet
def cache_time
RedBlocks::CachePolicy.hourly
end
def get
Project.pluck(:id, :monthly_page_view)
end
end
このコードは、まず RedBlocks::UnitSet を継承することで集合(Sorted Set)を表すクラス PageViewSet を定義している。この集合は要素として、月間ページビューをスコアに持った募集含んでいる。
このクラスを利用することで、例えば次のようにランキングの先頭5件を取得できる。
pv_set = PageViewSet.new
pv_set.ids #=> [1942, 3921, 354, 1120, 4931]
pv_set.size #=> 5121
ids メソッドが呼ばれると、初回は get メソッドの呼び出しを通じて Project クラスからクエリが発行される。その結果は Sorted Set としてキャッシュされた上で、ids メソッドの返り値となる。二回目以降の ids メソッドの呼び出しではキャッシュが利用されるため非常に高速に返る。同様に、全体の件数も size メソッドを通じてキャッシュされた集合から定数時間で取得することができる。 また、ids メソッドに paginator オブジェクトを渡すことで、定数時間でのページネーションも可能になる。実際の Web サービスの実装では、リクエストパラメータとして渡ってきたページ番号をそのまま渡すことが多いと思われる。
このキャッシュをどの程度の期間 Redis 上に保持するかは cache_time メソッドによって決めることが出来る。このメソッドを定義しない場合、キャッシュする時間はゼロとなり、データは Redis 上には最低限の時間しか生存しない(キャッシュしない場合でも Redis 上にデータが生存する必要がある理由は後述する)。
cache_time は鮮度やコストに応じて必要であれば定義すれば良いので、これ以降のサンプルコードでは省略する。
2. 絞り込み
地域の募集の集合 - RedBlocks::Set の利用
サービスのコンテンツが増加してきたことで、募集を地域によって絞り込む機能を提供したくなったとしよう。地域は、「北海道」「東北」「関東」「北陸」「甲信越」「東海」「近畿」「中国」「四国」「九州」「沖縄」の11地域に分類されるとする。このために、まずは地域ごとの募集の集合を表すクラスを定義する。
class RegionSet < RedBlocks::Set
def initialize(region)
raise ArgumentError unless Project::REGIONS.include?(region)
@region = region
end
def key_suffix
@region
end
def get
Project.where(region_cd: @region).pluck(:id)
end
end
このクラスは次のように具体的な region を引数に与えてインスタンス化することで、先ほどのランキング集合の場合と同様に利用することができる。
set = RegionSet.new('hokkaido')
set.ids #=> [1, ... ] # 北海道の募集のリスト
PageViewSet と RegionSet の違いは、PageViewSet は RedBlocks::UnitSet を継承していたのに対して RegionSet は RedBlocks::Set を継承している点と、RegionSet は key_suffix メソッドを実装している点にある。
RegionSet は各地域に対してそれぞれ異なる集合があり得るため、インスタンスとして生成する際に具体的な地域の指定が必要である。更に、Redis に保存する際の保存先も、例えば「北海道地域の募集の集合」と「関東地域の募集の集合」では異なるため、その保存先を指定するための Redis の key の1部分として key_suffix メソッドを実装する必要がある。key_suffix メソッドはインスタンスレベルで異なる集合を区別できるような文字列を返すように実装する必要がある。
一方、最初に紹介した PageViewSet は実質的にクラスにただ一つの集合しか作り得ないシングルトン集合であったため、それに特殊化した RedBlocks::UnitSet を利用した。このクラスはシングルトンを前提としているため、key_suffix メソッドを実装する必要はない。
また、get メソッドの返り値の型に着目してみると、PageViewSet#get は募集の id とスコアのペアのリストを返しているが、RegionSet#get はただ募集の id のリストを返していることが分かる。RedBlocks の get メソッドでは、id のリストを返した場合に内部的に全てスコア0の Sorted Set として扱う。Redis の集合演算ではスコアはデフォルトで同一要素同士で加算されるため、スコアを暗黙的に零元に設定しておくことでスコアに影響を与えない集合として扱うことができる。プログラマは、スコアを持たない(つまり数学的な意味での)集合を利用したいときにはただ要素のリストを返すだけで良い。今回の場合、地域による絞り込み動作は順序には関与しない仕様にしたいため、RegionSet#get はただ要素のリストを返している。
複数の地域に含まれる募集の集合 - RedBlocks::UnionSet の利用
ここまでで特定の地域による絞り込みができるようになったが、「『北海道』または『関東』の募集を探したい」と言ったユーザーのニーズにも応えられるようにしたい(ユーザー・インターフェースとしては、チェックボックスのように複数選択式のものになる)。
これは、集合で言えば北海道の募集と関東の募集の和集合を作ることに相当する。従って、次のような定式化ができる:
[北海道の募集] ∪ [関東の募集]
RedBlocks::UnionSet を使うことで、この和集合演算を実現できる。
region1_set = RegionSet.new('hokkaido')
region2_set = RegionSet.new('kanto')
regions_set = RedBlocks::UnionSet.new([region1_set, region2_set])
regions_set.ids #=> [921, 324, 21, 39, 101]
公開されている募集のみに絞る - RedBlocks::IntersectionSet の利用
実際のサービスでは、コンテンツには下書き・非公開などの状態が存在し、必ずしもデータベースに登録されている全てのコンテンツを一覧画面に出せるわけではない。このことを制御するため、次のように公開募集の集合で積集合演算を行った結果を常に返すようにしたい:
[公開されている募集] ∩ ([北海道の募集] ∪ [関東の募集])
RedBlocks::IntersectionSet を使うことで、この積集合演算は実現できる。
visible_set = VisibleSet.new
result_set = RedBlocks::IntersectionSet.new([visible_set, regions_set])
さて、公開・非公開などの状態の変更は特にリアルタイムで一覧画面の結果に反映したいものである。そのため、募集の状態の変更に応じて RedBlocks::Set#update! を呼び出して即座にキャッシュを更新するようにする。
class Project < ActiveRecord::Base
# ...
after_save -> { VisibleSet.new.update! }, if: -> { visibility_changed? && visible? }
end
絞り込み結果を PV でソートする
地域による絞り込みを行った結果も、絞り込む前の最初に紹介した PV ランキングに基づいて表示されるようにしたい。これは、最初に作成した PageViewSet を積集合演算に組み込むことで実現できる。
[PageView をスコアに持つ募集] ∩ [公開されている募集] ∩ ([北海道の募集] ∪ [関東の募集])
PageView ではなく最新順で表示すると言ったソート条件の切り替え機能を提供するのであれば、この積集合演算に使うスコア付き集合を変更すれば良い。
[公開日時をスコアに持つ募集] ∩ [公開されている募集] ∩ ([北海道の募集] ∪ [関東の募集])
3. 全文検索
サービスに十分なコンテンツ量と十分多様なユーザーが集まったため、任意のキーワードによる検索機能を入れてより目的の募集に出会いやすくしたい。これまでの計算はリレーショナル・データベースのデータを元にしていたが、今回の機能追加ではよりマッチ度が高い要素から順番にユーザーに表示したいため、全文検索エンジン Elasticsearch へ問い合わせた結果のスコアを採用することにした。
このために特定のキーワードを引数に受け取って Elasticsearch に問い合わせる次のようなモジュールを作成した。Elasticsearch には募集のテキスト情報を同期している。
ProjectSearchService.new("Ruby", format: :id_with_score).perform #=> [[32, 12.1], [811, 11.0], ...]
このモジュールを元に、RegionSet の場合と同様に集合を定義する。RegionSet との違いは、全部検索による該当キーワードへのマッチ度が入ったスコア付きの集合となっている点にある。
class KeywordSet < RedBlocks::Set
def initialize(keyword)
@keyword = keyword
end
def key_suffix
@keyword
end
def get
ProjectSearchService.new(@keyword, format: :id_with_score).perform
end
end
この KeywordSet を用いて、例えば次のような集合を構築できればキーワード検索機能を付加することができる。キーワードによるスコアが既に付いているため、ここではPVランキングの集合は利用していない。
// キーワードだけで絞り込む
[公開されている募集] ∩ [キーワードで絞り込んだ集合]
// 地域とキーワードで同時に絞り込む
[公開されている募集] ∩ ([北海道の募集] ∪ [関東の募集]) ∩ [キーワードで絞り込んだ集合]
4. パーソナライズ
ユーザーの行動データが十分に貯まったので、それを元にしてそれぞれのユーザーに合ったコンテンツを推薦したいとしよう。その場合、あるユーザーがそれぞれのコンテンツをどの程度好むのかの予測数値をスコアを持つような集合を定義する。この計算は大規模なログデータにアクセスする他のマイクロサービスが行っている可能性があるが、集合として抽象化できるという点は変わらない。
class PersonalizedSet < RedBlocks::Set
def initialize(user_id)
@user_id = user_id
end
def key_suffix
@user_id
end
def get
RecommendationService.get_personalized_ranker
end
end
ここで定義した PersonalizedSet の使い方は色々な可能性がある。ほぼ全ての募集に対してある程度妥当な予測数値が付けられるのであれば単独でスコア付けに利用できるかもしれないし、一部の募集に対してだけ予測数値が付いて他はゼロになっているような疎な集合であれば、0..1 に正規化した上で一般的な人気度をスコアに持つ集合と足し合わせて利用できるかもしれない。念のため定式化すると、次のようになる:
[公開されている募集] ∩ [パーソナライズされたスコアを持つ集合] ∩ (その他の絞り込み条件) // パーソナライズだけ
[公開されている募集] ∩ [パーソナライズされたスコアを持つ集合] ∩ [一般的な人気度をスコアに持つ集合] ∩(その他の絞り込み条件)// パーソナライズ + 人気度
5. 全ての統合
ここまで、RedBlocks を用いて定義した集合を組み合わせることで、様々な機能を実現できることを見てきた。実際のサービスでは、これをユーザーの入力に応じて動的に行う必要がある。それを例えば次のような service クラスを作成することで行う。
class ProjectListingService
def new(params, user_id: nil)
# ...
@set = build_set(params, user_id)
end
def fetch(per: 10, page: 1, format: :ids)
paginator = build_paginator(per, page)
case format
when :ids then set.ids(paginator)
when :count then set.size
end
end
private
def build_set(params, user_id)
sets = params.each do |k,v|
...
end
sets << VisibleSet.new
sets << PersonalizedSet.new(user_id) if user_id
RedBlocks::IntersectionSet.new(sets, cache_time: 10.minutes)
end
end
ここで、新たに RedBlocks::IntersectionSet に cache_time オプションを追加していることに注意しよう。ここまで、RedBlocks::IntersectionSet や RedBlocks::UnionSet と言った合成型の集合についてそれがどの程度の期間キャッシュされるのかについては言及していなかったが、実はデフォルトでは計算に必要な最低限の期間しか生存しない。しかしこのコードでは、絞り込みなどを行った上でのページングが再計算せず高速で行われるように、最終的な出力結果に対しては10分間のキャッシュを行うように設定している。
変更に対するモジュラ性の検討
さて、ここまでで RedBlocks をつかうことで一覧画面をどのように実装するかをおおよそ見ることができた。この実装方法について変更に対するモジュラ性の観点からどのような改善ができたのか、あり得る変更に対してどのように関心を分離できているかを明らかにしておきたい。
- 同様のロジックを持つ集合をクラスベースでまとめ上げることができる(例:地域クラス - 北海道インスタンス)
- これにより、新たな地域を絞り込み項目に追加する際には、それを地域のリストに追加するだけで済むようになる
- 各サブシステムへのアクセスがクラスの get メソッドに抽象化される
- これにより、サブシステムの置き換えと言った変更が get メソッドの実装に局所化されることになる
- 速度的な最適化は暗黙的なキャッシュにより行われる
- これにより、遅いサブシステムにはキャッシュを入れる、と言ったロジックに関係のないコードが省略される
- データを引く部分を Set クラス、統合を
ProjectListingServiceで行うという分離ができている- これにより、「言語」と言った全く新しい絞り込み項目を追加する際も他の Set クラスは一切変更せずに済む
- 具体的には 1) 新規に
LanguageSetクラスを定義, 2) Service クラスの変更 の2点を行えば良い - また、各集合のスコアをどのように利用するか、AND にするか OR にするかと言った変更の際は service クラスのみの変更で済む
- これは次節で述べるが、Redis に関する様々な詳細実装を省略できる
- これにより、本来のアプリケーション・ロジックのみが記述される
このように RedBlocks を適切に用いて実装することで、クラスベースのオブジェクト指向プログラミングの概念を利用して適切に関心を分離した形で、一覧画面を実装できることが分かった。
実装に関する詳細
先ほどの章では、RedBlocks を使うことで Redis をオブジェクト指向の枠組みで取り扱うことができることを説明した。この章では「課題2: 実装に必要な多くの詳細」についてより詳しく述べる。具体的にライブラリが裏で行っている仕事について、以下の6点を取り上げる。
- キー体系
- キャッシュとして動作させる
- Redis 上のデータの生存期間
- キャッシュを差分更新にする
- 空集合を表現する
- 集合の最適化
ここでは実装上の詳細について取り上げるため、特に全体としてまとまりがあるわけではない。興味のある話題だけを選択的に見てもらえれば幸いである。
キー体系
Redis を利用するには当然キーを指定する必要があるわけだが、このキーについて RedBlocks では次のような体系を用いている:
<全体の名前空間>:<クラスレベルの識別子>:<インスタンスレベルの識別子>
まずキーが3階層に分けれている。最初の階層は全体の名前空間を表していて、デフォルトで "RB" となる。二つ目の階層はクラスレベルの識別子を表していて、RedBlocks::Set を継承したクラスの名前がデフォルトで利用される。三つ目の階層はインスタンスレベルの識別子を表していて、主に key_suffix メソッドの実装を通じてプログラマが指定する。例えば、先ほど出てきた「北海道」地域にある募集の集合、次のようなキーが構築される。
r = RegionSet.new('hokkaido')
r.key #=> "RB:RegionSet:hokkaido"
合成型の集合のキー
RedBlocks::UnionSet など合成型の集合の場合は、key_suffix の決定を自動で行う。ルールは、内包する全ての集合のキーをソートして | によって結合したものとなる。
r1 = RegionSet.new('hokkaido')
r2 = RegionSet.new('kanto')
RedBlocks::UnionSet.new([r1, r2]).key_suffix #=> "[RB:RegionSet:hokkaido|RB:RegionSet:kanto]"
RedBlocks::UnionSet.new([r1, r2]).key #=> "RB:RedBlocks::UnionSet:[RB:RegionSet:hokkaido|RB:RegionSet:kanto]"
これによって、カスタムクラスを定義することなく簡単に和集合や積集合と言った合成集合を作ることができている。
キャッシュとして動作させる
キャッシュとして動作させる、つまり「無ければ元データを取得しキャッシュに乗せて次回以降はそれを使う」という動作を実現するために、次のようにデータ取得の際にキャッシュの有無をチェックしている。
module RedBlocks
class Set
def disabled?
RedBlocks.client.ttl(key) < RedBlocks.config.intermediate_set_lifetime # この lifetime はデフォルトで30秒
end
def ids(...)
update! if disabled?
...
end
end
end
このコードは、該当のインスタンスに相当する Redis の Sorted Set の生存期間がまだ30秒以上あれば有効であり、そうでなければ無効と判定してデータの更新を行っている(0ではなく30秒である理由は次で説明する)。
Redis 上のデータの生存期間
RedBlocks を通じて利用する Sorted Set はキャッシュとして一定期間 Redis 上に存在させることができるが、その一方で ZINTERSTORE(dest, src1, src2, ...) や ZUNIONSTORE(dest, src1, src2, ...) と言った演算を Redis 上で行うためには、キャッシュ期間をゼロに設定されている(つまり結果を返した直後に消滅して良い) Sorted Set であっても最低限存在しなければならない期間が存在する。
RedBlocks ではこれをデフォルトで30秒と定め、「(get メソッドを通じたデータの取得も含めて)ids を呼び出してから最終結果取得までの全ての工程が30秒以内に終了する」という仮定の元に正常に動作することを保証している。
以下に示す実装の通り、キャッシュとして存在する時間とは別で30秒は必ず存在するように全ての生存期間が設定されている。
module RedBlocks
class Set
def expiration_time
RedBlocks.config.intermediate_set_lifetime + cache_time
end
def update!
...
RedBlocks.client.expire(key, expiration_time)
end
end
end
キャッシュを差分更新にする
キャッシュの更新の際、一度全てを削除してから新しくデータを入れるという方法だと、瞬間的にサービスにおけるコンテンツの件数がゼロになってしまう。一瞬であってもその状況は好ましくないため、実際のキャッシュの更新処理では更新の前後で削除された要素のみを明示的に Sorted Set から取り除いている(増分に関してはスコアのみが変わる可能性もあるため、全てを更新する必要がある)。
module RedBlocks
class Set
def update!
...
RedBlocks.client.pipelined do
RedBlocks.client.zrem(key, removed_ids) if removed_ids.size > 0
RedBlocks.client.zadd(key, all_entries)
RedBlocks.client.expire(key, expiration_time)
end
end
end
end
空集合を表現する
Redis の Sorted Set の仕様では、内包する要素が0件であるという状態と、Sorted Set 自体が存在しないという状態を区別できない。しかし、RedBlocks のユースケースにおいては、「空の集合である」という状態もキャッシュしたい(例えば、特定のキーワードによる全文検索の結果が0であるということ自体もキャッシュしたい)。
このため、実際にコンテンツに対応する要素以外に、id が 0 の要素を常に加えるようになっている。この 0 は実在する要素の id として取り得ない値を想定しており、RedBlocks.config.blank_id を通じて別の値にも設定することができる。
集合の最適化
最後に、集合構造を最適化する RedBlocks::Set#unset について紹介する。
状況として、「職種」と「地域」と言った複数の観点での絞り込みができる仕様があるとする。例えば、次のようなクエリがあり得る:
// pattern 1
([エンジニアの募集] ∪ [デザイナーの募集]) ∩ ([北海道の募集] ∪ [関東の募集] ∪ [東海の募集])
// pattern 2
[デザイナーの募集] ∩ [北海道の募集]
このとき、両者を同時に処理できるように一般的なプログラムを書くと、後者は次のような構造になる可能性が高い。
pattern1_set = RedBlocks::IntersectionSet.new(RedBlocks::UnionSet.new([engineer_set, designer_set]), RedBlocks::UnionSet.new([hokkaido_set, kanto_set, tokai_set]))
pattern2_set = RedBlocks::IntersectionSet.new(RedBlocks::UnionSet.new([engineer_set]), RedBlocks::UnionSet.new([hokkaido_set]))
当然ながらこの集合構造は冗長であり、最初に示したようなクエリに変換できると良い。形式的に言って内部に1つの集合を持つような積集合はその内部の集合と等価であるため、このような冗長な構造を再帰的に最適化するために unset メソッドを用意している。この例では、以下のように動作する。
pattern2_set.unset #=> RedBlocks::IntersectionSet.new(engineer_set, hokkaido_set)
制限事項
以上、この節で紹介した実装詳細のうち、次の二つのアイデアについて制限事項を検討する。
- Redis を演算とキャッシュの二つの目的で利用
- Redis のキーの自動生成
これらはクイックに低レイテンシーな検索・フィルタリングシステムを構築することに寄与している(1 により単純なシステム構成になり、2によりプログラミング上の些事が消失する)。 しかしながら、いくつかの状況においてはこのアプローチは適さないと思われる。
まず1については、Redis 上での演算を前提としているため、演算性能もまた Redis の上限に制約される。これは数十万件程度のデータが対象であば問題にならないが、数千万件以上のデータがある場合は性能上の問題が出る。このような規模に成長した場合は、演算の責務を Redis に担わせるのではなく別のシステムコンポーネントに担わせるのが妥当だろう。
次に2については、クラス名というプログラム上の実体からキーを生成しているため、それの変更に影響を受ける。これがキャッシュの Thundering Herd を引き起こす可能性が原理的に存在する。そのような非常に高並列性のアプリケーションにおいては、演算をオンラインで行うのではなく、オフラインで行っておくなど、異なるアプローチを検討するべきだと思われる。
おわりに
本稿では、Redis の Sorted Set の Web サービスにおける活用方法として、一覧画面の実装での利用を挙げた。特に、現実的な価値提供のためには複数のシステムコンポーネントが必要であるという観点からそれらの「統合」に課題があることを指摘し、その基幹部分に Redis の Sorted Set を使うことを提案した。
その上で、それを現実的に保守可能な形で実装するために RedBlocks という抽象化を行い、実際のアプリケーションで求められる仕様をピックアップしながらそれを上手く記述できることのケーススタディを行った。このケーススタディの中では、HTTP サーバーではなく ActiveRecord を介してデータベースへ問い合わせるようなサンプルコードも掲載しているが、マイクロサービスの導入期には HTTP による通信とデータベースへの直接参照が混合するケースも多く、そういった部分も含めて現実的に使っている統合手法として紹介した。
また、RedBlocks については更に踏み込んで、アプリケーションのロジックを完結に記述できるようにするために裏にどのような仕事を隠蔽する必要があったかを紹介した。特に、複雑な Redis のデータ構造をどのようにクラスベースのオブジェクト指向プログラミングに落とし込むか、それと関連してどのようにシステマチックにキーを管理するかというようなトピックは、他の Redis のデータ型に対しても適用できる可能性もあり、今後の応用が見込める。