環境
- Tensorflow 2.3.0
- Google Colaboratory
イントロダクション
- (注意) 重きは、多クラス分類の内容ではなく、tf.kerasを使用した事への内容です
- Tensorflow kerasにより多層パーセプトロン(MLP)を作成
- 簡単なtf.kerasの使い方とモデルの保存、保存したモデルの読込を行う
- kaggleをやっている際、必要にかられ、kerasコードの読み方を今一度確認しました
データセット
- scikit-learnに付属のアヤメ品種データ(Iris plants dataset)を用いて検証
- Irisデータセットには(setosa, versicolor, virginica)の3種の情報が格納されている為、多クラス分類に使える
ソースコード全体
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import to_categorical
import tensorflow as tf
import matplotlib.pyplot as plt
# irisデータセット読込
iris = load_iris()
# データセットを訓練データ, テストデータに分割
data_X = iris.data
data_y = to_categorical(iris.target) # one-hotエンコーディング
train_X, test_X, train_y, test_y = train_test_split(data_X, data_y, test_size=0.3, random_state=0)
# モデルの構築
model = tf.keras.models.Sequential([
tf.keras.layers.Input(4),
tf.keras.layers.Dense(100, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax')
])
# モデルのコンパイル
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
loss='categorical_crossentropy',
metrics=['accuracy'])
# モデルの学習
result = model.fit(train_X, train_y, batch_size=32, epochs=50, validation_data=(test_X, test_y), verbose=1)
# Accuracyのプロット
plt.figure()
plt.title('Accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.plot(result.history['accuracy'], label='train')
plt.plot(result.history['val_accuracy'], label='test')
plt.legend()
# Lossのプロット
plt.figure()
plt.title('categorical_crossentropy Loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.plot(result.history['loss'], label='train')
plt.plot(result.history['val_loss'], label='test')
plt.legend()
plt.show()
# model.evaluateを使用し、学習を終えたモデルの誤差と精度を呼び出し
train_score = model.evaluate(train_X, train_y)
test_score = model.evaluate(test_X, test_y)
print('Train loss:', train_score[0])
print('Train accuracy:', train_score[1])
print('Test loss:', test_score[0])
print('Test accuracy:', test_score[1])
# 結果の確認(predict)
pred_train = model.predict(train_X)
pred_test = model.predict(test_X)
pred_train = np.argmax(pred_train, axis=1)
pred_test = np.argmax(pred_test, axis=1)
print(pred_train)
print(np.argmax(train_y, axis=1))
print(pred_test)
print(np.argmax(test_y, axis=1))


データロード
- scikit-learnを使いirisデータのロードを行う
from sklearn.datasets import load_iris
# irisデータセット読込
iris = load_iris()
# サイズを確認
(iris.data.shape), (iris.target.shape)
# ((150, 4), (150,))
print(iris.feature_names) # ラベルの確認
print(iris.data) # 説明変数
print(iris.target_names) # ラベルの確認
print(iris.target) # 目的変数
# データセットのタイプを確認
type(iris.data)
type(iris.target)
# numpy.ndarray
- 説明変数
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]...
- 目的変数
['setosa' 'versicolor' 'virginica']
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
データ処理
- irisの目的変数をニューラルネットワークで扱いやすいone-hotエンコーディングへ変換
from tensorflow.keras.utils import to_categorical
# one-hotエンコーディング
data_y = to_categorical(iris.target)
# 0 => [1, 0, 0]
# 1 => [0, 1, 0]
# 2 => [0, 0, 1]
- 以下の様にも記載可能
# 例: クラスベクトル(整数)をバイナリクラス行列に変換
to_categorical(iris.target,
num_classes=None,
dtype='float32')
-
詳細は以下参照
https://www.tensorflow.org/api_docs/python/tf/keras/utils/to_categorical -
続いてデータセットを訓練データ, テストデータへ分割
# データセットを訓練データ, テストデータへ分割
from sklearn.model_selection import train_test_split
data_X = iris.data
data_y = to_categorical(iris.target) # one-hotエンコーディング
train_X, test_X, train_y, test_y = train_test_split(data_X, data_y, test_size=0.3, random_state=0)
- test_size=0.3
- 学習データ7割, テストデータ3割へ分割
- random_state ランダムシードを設定
ネットワークアーキテクチャ
- 入力層 4変数
- 中間層 100変数
- 出力層 3変数
- 活性化関数 relu
- 損失関数 categorical_crossentropy
- 最適化関数Adam
import tensorflow as tf
# モデルの構築
model = tf.keras.models.Sequential([
tf.keras.layers.Input(4),
tf.keras.layers.Dense(100, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax')
])
# モデルのコンパイル
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
loss='categorical_crossentropy',
metrics=['accuracy'])
# モデルの学習
result = model.fit(train_X, train_y, batch_size=32, epochs=50, validation_data=(test_X, test_y), verbose=1)
Epoch 1/50
4/4 [==============================] - 0s 36ms/step - loss: 1.0097 - accuracy: 0.5810 - val_loss: 0.7336 - val_accuracy: 0.6222
Epoch 2/50
4/4 [==============================] - 0s 6ms/step - loss: 0.7082 - accuracy: 0.7048 - val_loss: 0.6553 - val_accuracy: 0.6000
Epoch 3/50
4/4 [==============================] - 0s 5ms/step - loss: 0.5494 - accuracy: 0.7905 - val_loss: 0.4738 - val_accuracy: 0.9111
- model.fitのverbose=0を設定する事により途中結果の出力をしない
モデル評価
# model.evaluateを使用し、学習を終えたモデルの誤差と精度を呼び出し
train_score = model.evaluate(train_X, train_y)
test_score = model.evaluate(test_X, test_y)
print('Train loss:', train_score[0])
print('Train accuracy:', train_score[1])
print('Test loss:', test_score[0])
print('Test accuracy:', test_score[1])
4/4 [==============================] - 0s 2ms/step - loss: 0.0649 - accuracy: 0.9714
2/2 [==============================] - 0s 2ms/step - loss: 0.1223 - accuracy: 0.9778
Train loss: 0.06492960453033447
Train accuracy: 0.9714285731315613
Test loss: 0.12225695699453354
Test accuracy: 0.9777777791023254
# 結果の確認(predict)
pred_train = model.predict(train_X)
pred_test = model.predict(test_X)
pred_train = np.argmax(pred_train, axis=1)
pred_test = np.argmax(pred_test, axis=1)
print(pred_train)
print(np.argmax(train_y, axis=1))
print(pred_test)
print(np.argmax(test_y, axis=1))
[1 2 2 2 2 1 2 1 1 2 1 2 2 1 2 1 0 2 1 1 1 1 2 0 0 2 1 0 0 1 0 2 1 0 1 2 1
0 2 2 2 2 0 0 2 2 0 2 0 2 2 0 0 1 0 0 0 1 2 2 0 0 0 1 1 0 0 1 0 2 1 2 1 0
2 0 2 0 0 2 0 2 1 1 1 2 2 1 1 0 1 2 2 0 1 1 1 1 0 0 0 2 1 2 0]
[1 2 2 2 2 1 2 1 1 2 2 2 2 1 2 1 0 2 1 1 1 1 2 0 0 2 1 0 0 1 0 2 1 0 1 2 1
0 2 2 2 2 0 0 2 2 0 2 0 2 2 0 0 2 0 0 0 1 2 2 0 0 0 1 1 0 0 1 0 2 1 2 1 0
2 0 2 0 0 2 0 2 1 1 1 2 2 1 1 0 1 2 2 0 1 1 1 1 0 0 0 2 1 2 0]
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0
2 1 1 2 0 2 0 0]
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0
1 1 1 2 0 2 0 0]
モデルの保存
# jsonファイルでモデルを保存
# 重みをhdf5で保存
config = model.to_json()
with open('model.json','w') as file:
file.write(config)
model.save_weights('weights.hdf5')
モデルの読込
with open('model.json','r') as file:
model_json = file.read()
model = tf.keras.models.model_from_json(model_json)
model.load_weights('weights.hdf5')
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.01),
loss='categorical_crossentropy',
metrics=['accuracy'])
train_score = model.evaluate(train_X, train_y)
test_score = model.evaluate(test_X, test_y)
print('Train loss:', train_score[0])
print('Train accuracy:', train_score[1])
print('Test loss:', test_score[0])
print('Test accuracy:', test_score[1])
4/4 [==============================] - 0s 2ms/step - loss: 0.0649 - accuracy: 0.9714
2/2 [==============================] - 0s 2ms/step - loss: 0.1223 - accuracy: 0.9778
Train loss: 0.06492960453033447
Train accuracy: 0.9714285731315613
Test loss: 0.12225695699453354
Test accuracy: 0.9777777791023254
- tf.keras.models.model_from_jsonについての詳細は以下参照
https://www.tensorflow.org/api_docs/python/tf/keras/models/model_from_json
参考文献
- https://snova301.hatenablog.com/entry/2018/10/29/175028
- https://aidiary.hatenablog.com/entry/20161108/1478609028
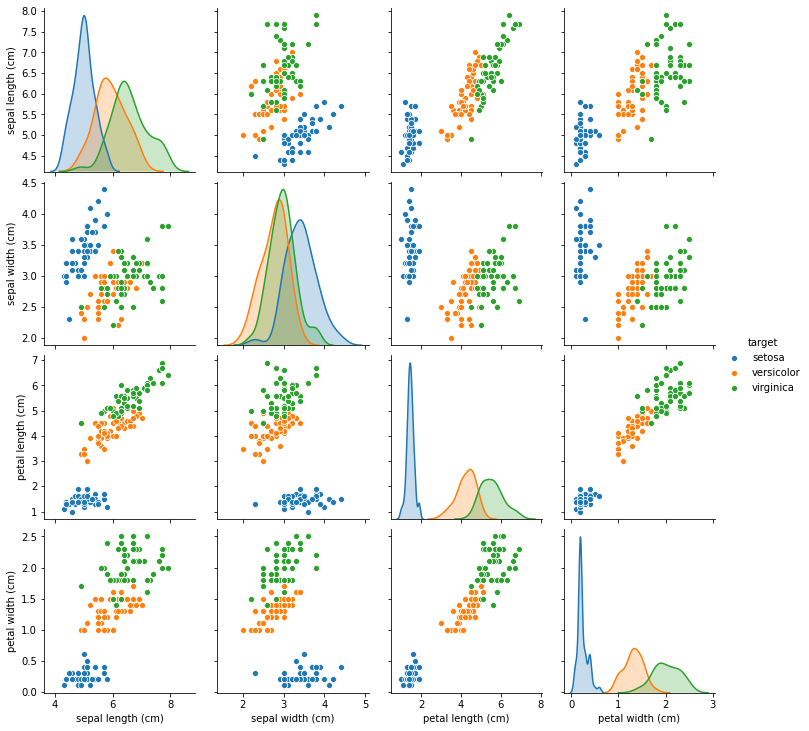
おわり (データの中身を把握するには)
- pandasを使ってみる
- seabornを使ってみる
import pandas as pd
import seaborn as sns
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
df.loc[df['target'] == 0, 'target'] = "setosa"
df.loc[df['target'] == 1, 'target'] = "versicolor"
df.loc[df['target'] == 2, 'target'] = "virginica"
df.head(2)
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | setosa |
sns.pairplot(df, hue="target")