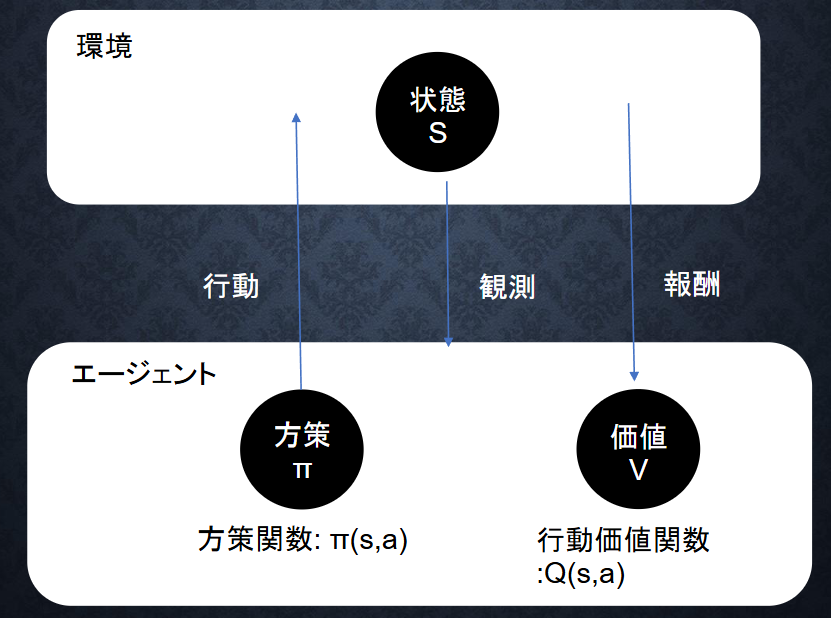
Section1:強化学習
強化学習(Reinforcement Learning, RL)は、エージェント(学習者)が環境と相互作用しながら試行錯誤を通じて最適な行動を学ぶ学習手法
| 要素 | 説明 |
|---|---|
| エージェント | 学習を行う主体(プレイヤー、ロボットなど) |
| 環境 | エージェントが動作する空間(ゲーム、実世界、シミュレーション) |
| 状態 $s$ | 現在の環境の情報(盤面の状態、画面の画像など) |
| 行動 $a$ | エージェントが取る選択(右へ進む、攻撃するなど) |
| 報酬 $r$ | 行動の結果として得られる数値(+1点、-1点など) |
| 方策(policy) | 状態に応じてどの行動をとるかを決定する戦略(確率モデルや関数) |
| 価値関数 | 状態や行動の「良さ」を定量化する関数 |
(参考)代表的アルゴリズム
| カテゴリ | アルゴリズム例 | 特徴 |
|---|---|---|
| 価値ベース | Q学習、SARSA | 状態や行動の「価値」を学習する |
| 方策ベース | REINFORCE | 方策自体を直接学習する |
| アクター・クリティック系 | A2C, A3C, PPO | 方策(アクター)と価値(クリティック)の両方を学習 |
| 深層強化学習 | DQN, DDPG, SAC | ニューラルネットワークで状態や方策を表現 |
(参考)特徴と課題
| メリット | 課題 |
|---|---|
| 自律的に試行錯誤で学習できる | 学習に時間がかかる |
| 明確な教師データが不要 | 状態空間が広いと学習が難しい |
| 長期的な成果を重視できる | 報酬設計(報酬スパース)が難しい |
| 実世界の意思決定に適応可能 | 探索と活用のバランス(exploration vs exploitation)が重要 |
実装演習
Q学習による迷路探索の実装
import numpy as np
import random
# 環境設定
grid_size = 4
state_size = grid_size * grid_size
action_size = 4 # 上下左右
# Qテーブルの初期化
Q = np.zeros((state_size, action_size))
# 行動定義(上:0, 下:1, 左:2, 右:3)
def step(state, action):
row, col = divmod(state, grid_size)
if action == 0 and row > 0: # 上
row -= 1
elif action == 1 and row < grid_size - 1: # 下
row += 1
elif action == 2 and col > 0: # 左
col -= 1
elif action == 3 and col < grid_size - 1: # 右
col += 1
next_state = row * grid_size + col
reward = 1 if next_state == state_size - 1 else 0
done = next_state == state_size - 1
return next_state, reward, done
# ハイパーパラメータ
alpha = 0.1 # 学習率
gamma = 0.99 # 割引率
epsilon = 0.1 # ε-greedy法
# 学習ループ
episodes = 500
for ep in range(episodes):
state = 0
done = False
while not done:
# ε-greedyで行動選択
if random.random() < epsilon:
action = random.randint(0, action_size - 1)
else:
action = np.argmax(Q[state])
next_state, reward, done = step(state, action)
# Q値更新
best_next = np.max(Q[next_state])
Q[state, action] += alpha * (reward + gamma * best_next - Q[state, action])
state = next_state
# 結果の表示
print("Qテーブル(最終的な状態):")
print(Q.reshape(grid_size, grid_size, -1))
実装結果

出力された Qテーブル により、各状態で最適な行動がどれかがわかる。
グリッドの右下(状態15)がゴールで、それを目指すように強化学習が働く。
Section2:AlphaGo
AlphaGo(アルファ碁)は、DeepMind(Google傘下)が開発した囲碁AIであり、ディープラーニングと強化学習を融合させた最先端の人工知能
AlphaGoの構成
-
ポリシーネットワーク(Policy Network)
現在の盤面から「どの手を打つか」を予測するニューラルネットワーク。
人間の棋譜データをもとに教師あり学習 → 強化学習で改善。
出力:盤面上の各位置に着手する確率分布。 -
バリューネットワーク(Value Network)
現在の盤面が「どれだけ勝利に近いか」を予測。
自己対局の結果から学習(強化学習)。
出力:その状態から見た勝率(0~1)。 -
モンテカルロ木探索(MCTS:Monte Carlo Tree Search)
探索アルゴリズム:局面ごとに数万~数百万手を探索。
ポリシーネットワークで枝刈りし、効率的に探索。
バリューネットワークで終局までプレイせずとも勝率を見積もる。
教師あり学習
→ 人間の棋譜データ(30万局以上)でポリシーネットを事前学習
強化学習(自己対戦)
→ AlphaGo同士で数百万局対戦し、ポリシーとバリューを最適化
MCTSによる対局
→ プレイ中はMCTSで次の手を選択し、バリューで評価
(参考)Alpha Go Zeroとの違い
| 項目 | AlphaGo | AlphaGo Zero |
|---|---|---|
| 初期学習 | 人間の棋譜による教師あり学習 | 自己対局のみ(ゼロから) |
| ネットワーク構成 | ポリシーとバリューが別 | 統合された1つのネットワーク |
| 探索アルゴリズム | MCTS(ポリシー+バリュー) | MCTS(統一ネット+強化学習) |
| パフォーマンス | 世界トップレベルに勝利 | さらに高精度・短時間で学習完了 |
実装演習
簡易 AlphaGo(3×3盤面)風の実装(PolicyNet + MCTS)
import numpy as np
import random
class PolicyNetwork:
def __init__(self):
# 盤面9マスに対してスコアを予測する簡単な重み(初期化)
self.weights = np.random.rand(9)
def predict(self, state):
# 入力状態に対応する各手の確率を出力(ソフトマックス)
probs = np.exp(self.weights * state)
probs[state == 0] = 0 # すでに置かれた場所には着手できない
probs /= np.sum(probs) + 1e-8
return probs
def train(self, state, action, reward, lr=0.1):
# 強化学習に基づく重み調整(単純なポリシー勾配)
probs = self.predict(state)
grads = -probs
grads[action] += 1
self.weights += lr * reward * grads
def mcts(state, policy_net, simulations=100):
visit_counts = np.zeros(9)
for _ in range(simulations):
s = state.copy()
for _ in range(5): # シミュレーション5手分
probs = policy_net.predict(s)
action = np.random.choice(9, p=probs)
if s[action] == 0:
s[action] = 1 # 仮に打ってみる
visit_counts[action] += 1
break
return np.argmax(visit_counts)
# 学習
policy = PolicyNetwork()
for episode in range(100):
board = np.zeros(9) # 空の盤面(3x3 = 9マス)
state = board.copy()
for t in range(5): # 最大5手
action = mcts(state, policy)
if state[action] != 0:
continue # 無効な手を飛ばす
state[action] = 1 # プレイヤーの手
reward = 1 if np.random.rand() < 0.5 else -1 # 仮の報酬
policy.train(board, action, reward)
break # 単手プレイで終了
print("学習後のポリシー重み:")
print(policy.weights)
学習が進むと policy.weights が変化し、プレイヤーの着手が改善される。報酬や盤面をより複雑にすれば、さらに本格的な強化学習に発展可能。
Section3:軽量化・高速化技術
なぜ軽量化が必要になるのか
| 課題 | 内容 |
|---|---|
| モデルサイズが大きすぎる | スマホやIoT機器に載せられない |
| 推論が遅い | 自動運転やARでリアルタイム処理が間に合わない |
| 学習時間・消費電力が高すぎる | 開発・運用コストが膨大 |
軽量化手法
| 分類 | 手法名 | 概要と効果 |
|---|---|---|
| 構造の工夫 | MobileNet、EfficientNet、SqueezeNet | 少ない計算で精度を保つ軽量モデル設計 |
| パラメータ削減 | パラメータ剪定(Pruning) | 重要でない重みを削除 |
| 量子化 | Quantization | 32bit → 8bitなど低精度に変換(高速・省メモリ) |
| 知識蒸留 | Knowledge Distillation | 大きなモデルの知識を小さなモデルに転写 |
| 行列分解 | Low-rank Decomposition | 重み行列を低ランク近似 |
| ハードウェア最適化 | TensorRT、ONNX、GPU並列処理 | 推論最適化や高速化 |
(参考)組み合わせ例
| 実用モデル | 使用技術例 |
|---|---|
| MobileNetV2 | Depthwise conv + Inverted residual |
| DistilBERT | Transformerの蒸留版(BERTより高速) |
| TensorRT変換済モデル | 量子化 + プルーニング + 行列最適化 |
実装演習
知識蒸留について実装
import tensorflow as tf
from tensorflow.keras import layers, models, losses
# 教師・生徒モデル(例:ResNet50とMobileNet)
teacher = tf.keras.applications.ResNet50(weights='imagenet', include_top=True)
student = tf.keras.applications.MobileNetV2(weights=None, classes=1000)
# 蒸留損失関数
def distillation_loss(y_true, y_student, y_teacher, alpha=0.1, T=5):
loss_ce = losses.categorical_crossentropy(y_true, y_student)
loss_kd = losses.KLD(y_teacher / T, y_student / T) * (T ** 2)
return alpha * loss_kd + (1 - alpha) * loss_ce
教師モデルの出力を模倣して生徒モデルを学習
⇒実際の学習ループでは teacher(x) の出力と student(x) の出力を比較し、上記の損失を使って生徒モデルを訓練
Section4:応用技術
MobileNet(モバイルネット)は、軽量で高速な畳み込みニューラルネットワーク(CNN)であり、特にスマートフォンやエッジデバイスでの画像認識を目的に設計
| 特徴 | 説明 |
|---|---|
| 軽量 | モデルのパラメータ数が少ない(小さなサイズ) |
| 高速 | 少ない演算量でリアルタイム処理が可能(スマホ・IoTでも動く) |
| 精度と効率の両立 | パラメータ削減と高精度を両立する工夫が多数盛り込まれている |
MobileNetV1 の最大の特徴は、Depthwise Separable Convolution(深さ方向分離畳み込み)を使用
Depthwise Separable Conv
1回の通常の畳み込みを次の2段階に分割:
Depthwise Convolution(空間方向のみ)
各チャンネルに独立したフィルターを適用
Pointwise Convolution(1x1 Conv)(チャンネル方向)
各ピクセル位置のチャンネル情報を統合(線形結合
(参考)MobileNetV2の改良点
| 機能 | 説明 |
|---|---|
| Inverted Residual Block | 通常のResNetとは逆に、「小さい→大きい→小さい」次元の構造 |
| Linear Bottleneck | 出力に非線形活性化(ReLU)を使わず、情報損失を抑制 |
| 残差接続(shortcut) | 小さい特徴量間にショートカット接続を挿入し勾配消失を防ぐ |
実装演習
MobileNetV2 をベースにした画像分類の実装例
import tensorflow as tf
from tensorflow.keras import layers, models
import tensorflow_datasets as tfds
# データセット読み込み(TensorFlow Datasets から)
(ds_train, ds_test), ds_info = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:]'],
shuffle_files=True,
as_supervised=True,
with_info=True
)
# 画像リサイズ・正規化
def preprocess(image, label):
image = tf.image.resize(image, (224, 224)) / 255.0
return image, label
batch_size = 32
ds_train = ds_train.map(preprocess).batch(batch_size).prefetch(1)
ds_test = ds_test.map(preprocess).batch(batch_size).prefetch(1)
# 転移学習:MobileNetV2 のベースモデル(学習済みを利用)
base_model = tf.keras.applications.MobileNetV2(
input_shape=(224, 224, 3),
include_top=False,
weights='imagenet'
)
base_model.trainable = False # 転移学習なのでベースは凍結
# 分類ヘッド追加
model = tf.keras.Sequential([
base_model,
layers.GlobalAveragePooling2D(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.3),
layers.Dense(ds_info.features['label'].num_classes, activation='softmax')
])
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# 学習
model.fit(ds_train, epochs=5, validation_data=ds_test)
# 評価
loss, acc = model.evaluate(ds_test)
print(f"\n✅ 評価結果 - Accuracy: {acc:.4f}")
実装結果

ResNet(転移学習)
ResNet(Residual Network)は、深いニューラルネットワークの学習を容易にするために開発されたCNNアーキテクチャで、2015年のImageNetで圧倒的な精度を記録し、ディープラーニングに革命をもたらしました。ResNetの核となるのは「残差学習(Residual Learning)」という考え方
| 特徴 | 内容 |
|---|---|
| 残差学習 | 恒等マッピングを学習するだけで済むため学習が安定 |
| 深いネットでも勾配が通る | スキップ接続により勾配消失を防ぐ |
| 転移学習に強い | ImageNet学習済モデルが多くのタスクで使える |
深層ネットワークの問題点:勾配消失・性能劣化
ネットワークを深くすると理論上は性能が向上するはず。
しかし実際には、学習が困難になり、性能が悪化することがあった。
解決策:残差接続(ショートカット接続)
中間層に恒等写像(Identity Mapping)を導入。
出力 = 学習したい関数 + 入力(shortcut)という形に
(参考)ResNetの構成
| ResNet名 | ブロック数 | 主な特徴 |
|---|---|---|
| ResNet-18 | 18層(Basic Block) | 軽量で高速 |
| ResNet-34 | 34層(Basic Block) | シンプルな深層構造 |
| ResNet-50 | 50層(Bottleneck) | 高精度、3層構成のBlock使用 |
| ResNet-101 | 101層 | より深く高性能 |
| ResNet-152 | 152層 | ImageNetコンテスト最上位精度 |
実装演習
TensorflowでのResidual Block実装
import tensorflow as tf
from tensorflow.keras import layers, Model
class ResidualBlock(tf.keras.Model):
def __init__(self, filters, stride=1):
super(ResidualBlock, self).__init__()
self.conv1 = layers.Conv2D(filters, kernel_size=3, strides=stride, padding='same')
self.bn1 = layers.BatchNormalization()
self.relu = layers.ReLU()
self.conv2 = layers.Conv2D(filters, kernel_size=3, strides=1, padding='same')
self.bn2 = layers.BatchNormalization()
if stride != 1:
self.shortcut = tf.keras.Sequential([
layers.Conv2D(filters, kernel_size=1, strides=stride),
layers.BatchNormalization()
])
else:
self.shortcut = lambda x: x
def call(self, x, training=False):
shortcut = self.shortcut(x)
x = self.conv1(x)
x = self.bn1(x, training=training)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x, training=training)
x += shortcut
return self.relu(x)
ResNet-18 簡易モデルの構築例
class ResNet(tf.keras.Model):
def __init__(self, num_classes=10):
super(ResNet, self).__init__()
self.stem = tf.keras.Sequential([
layers.Conv2D(64, 7, strides=2, padding='same'),
layers.BatchNormalization(),
layers.ReLU(),
layers.MaxPooling2D(pool_size=3, strides=2, padding='same')
])
# 各ステージのResidual Blocks
self.layer1 = self._make_layer(64, num_blocks=2, stride=1)
self.layer2 = self._make_layer(128, num_blocks=2, stride=2)
self.layer3 = self._make_layer(256, num_blocks=2, stride=2)
self.layer4 = self._make_layer(512, num_blocks=2, stride=2)
self.global_pool = layers.GlobalAveragePooling2D()
self.fc = layers.Dense(num_classes)
def _make_layer(self, filters, num_blocks, stride):
layers_list = []
layers_list.append(ResidualBlock(filters, stride))
for _ in range(1, num_blocks):
layers_list.append(ResidualBlock(filters, stride=1))
return tf.keras.Sequential(layers_list)
def call(self, x, training=False):
x = self.stem(x, training=training)
x = self.layer1(x, training=training)
x = self.layer2(x, training=training)
x = self.layer3(x, training=training)
x = self.layer4(x, training=training)
x = self.global_pool(x)
return self.fc(x)
| 要素 | 説明 |
|---|---|
ResidualBlock |
残差接続を含む基本ユニット |
stride!=1 |
特徴量の空間サイズを縮小する際の調整 |
GlobalAvgPool |
全結合層前の特徴抽出を簡潔化 |
Sequential |
各ステージに複数のResidualBlockを積み上げ |
EfficientNet
EfficientNet(エフィシェントネット)は、精度と効率の両立を実現した畳み込みニューラルネットワーク(CNN)
Compound Scaling(複合スケーリング)
3つの要素(Depth, Width, Resolution)をバランスよく同時にスケールすることで、効率的かつ高性能なモデルを構築する方法。
数式(概要)
与えられたリソース制限のもとで以下のようにスケール:


このCompound Coefficient(複合係数)を調整するだけで、効率的に大規模モデルを作成可能
(参考)構造と特徴
| 構成要素 | 説明 |
|---|---|
| MBConv(Mobile Inverted Bottleneck) | 軽量かつ高性能な構造(元はMobileNetV2) |
| Swish活性化関数 | ReLUよりも滑らかな非線形変換で精度向上 |
| SE Block(Squeeze-and-Excitation) | チャンネル注意機構で特徴の強調 |
| Depthwise Separable Convolution | 畳み込み演算の軽量化技術 |
物体検知とSS解説
物体検知:画像内の複数の物体を検出して、そのクラスと位置(バウンディングボックス)を特定するタスク
入力:1枚の画像
出力:複数の物体に対する
- クラス(例:人、犬、車)
- 位置(バウンディングボックス:x, y, width, height)
| カテゴリ | アプローチ | 代表例 |
|---|---|---|
| 2段階(two-stage) | 候補領域 → 分類+位置調整 | R-CNN、Fast R-CNN、Faster R-CNN |
| 1段階(one-stage) | 直接物体のクラスと位置を予測 | YOLO、SSD、RetinaNet |
Selective Search(選択的探索)は、2段階検出手法(特にR-CNN)で使われた物体候補領域(Region Proposals)生成の古典的手法
「この画像の中で、どこに“物体っぽい”部分がありそうか?」をCNNで見る前に候補を絞る
| 特徴 | 内容 |
|---|---|
| 非学習ベース | CNNを使わない、ルールベース手法 |
| 高精度 | 初期の物体検出(R-CNN)では良い精度を発揮 |
| 低速 | 1枚の画像で数秒かかるためリアルタイムには不向き |
| 後継技術で置換 | 現在ではFaster R-CNNなどで使われる RPN(Region Proposal Network) が主流 |
(参考)現在の主流
| 時代 | 提案方法 | 手法 |
|---|---|---|
| 2014〜2015年 | Selective Search | R-CNN, Fast R-CNN |
| 2015年以降 | RPN(CNNベース提案生成) | Faster R-CNN |
| 2016年以降〜現在 | YOLO/SSD(ワンステージ) | YOLOv3〜v8, SSD |
Mask R-CNN
Mask R-CNNは、物体検出 + セマンティックセグメンテーション(インスタンスセグメンテーション)を同時に行うモデル
| タスク | 内容 |
|---|---|
| 物体検出(Object Detection) | 物体の「位置(矩形)」と「クラス」を検出 |
| セマンティックセグメンテーション | 各ピクセルに「意味的なクラス」を付与 |
| インスタンスセグメンテーション | 同じクラスでも「個別の物体ごと」にピクセル単位で識別 |
Mask R-CNNの特徴
| 特徴・利点 | 説明 |
|---|---|
| 高精度なインスタンス認識 | ピクセル単位の認識で物体の形状を正確に検出 |
| RoI Alignの導入 | マスク精度を大幅に改善 |
| 構造が拡張しやすい | Keypoint検出などの追加も可能 |
| 転移学習に対応 | MS-COCOなどの学習済モデルが多く存在 |
RoI Align(← Fast R-CNNのRoI Poolingの改良)
ピクセルずれを防ぐため、より正確な補間でRoIを抽出
これによりマスクのピクセル単位の精度が向上
Faster-RCNN, YOLO
Faster R-CNN(2015年)
2段階で物体検出を行う手法で、高い精度を誇ります。
先行する R-CNN / Fast R-CNN の改良版で、物体候補の提案までをCNNで自動化
画像 → CNN(特徴抽出)
↓
RPN(物体候補の生成)
↓
RoI Align(領域ごとの特徴抽出)
↓
ヘッドネット(分類 + BBox回帰)
| 項目 | 内容 |
|---|---|
| 精度 | 非常に高い(高精度を重視するタスク向け) |
| 処理速度 | 遅め(2段階構造) |
| 利点 | 正確な位置・クラス分類が可能 |
| 欠点 | 推論時間が長い(リアルタイムに不向き) |
YOLO(You Only Look Once)
YOLOは1段階(one-stage)で画像全体を一度に見る高速な物体検出モデル
| 項目 | 内容 |
|---|---|
| 精度 | 高速ながら比較的高い(特にv4以降) |
| 速度 | 非常に速い(リアルタイムに適している) |
| アーキテクチャ | 一体型CNNで直接クラスと位置を出力 |
| 利点 | 単純・高速・小型デバイスでも動作可 |
| 欠点 | 小さい物体の検出精度はFaster R-CNNより劣ることがある |
画像 → CNN → [BBoxes + Class Scores] → NMS → 出力(物体の位置とクラス)
| バージョン | 主な特徴 |
|---|---|
| YOLOv1 | 最初のYOLO、速いが精度は低め |
| YOLOv2 | Anchor導入、精度と速度向上 |
| YOLOv3 | Darknet-53、マルチスケール出力 |
| YOLOv4 | パフォーマンス最適化、CSPDarknet導入 |
| YOLOv5 | PyTorch実装(Ultralytics)、人気 |
| YOLOv6〜v8 | TTA、AutoLabel、バックボーン進化 |
(参考)Faster R-CNN vs YOLO
| 使用条件 | 推奨モデル |
|---|---|
| 高精度・小物体・厳密な位置が重要 | Faster R-CNN |
| リアルタイム・省リソース・高速処理 | YOLO |
FCOS
FCOS(Fully Convolutional One-Stage Object Detection)は、Anchor(アンカー)を使わずに物体検出を行う革新的な1段階検出モデル
「アンカー」や「物体候補(Region Proposal)」を一切使わず、画像上の各ピクセルから直接物体を検出。
画像 → CNN(Backbone, 例:ResNet + FPN) → 特徴マップ
↓
各ピクセルごとに:
- クラス分類
- BBoxオフセット(左、上、右、下)
- センター度(center-ness)
| 特徴 | 説明 |
|---|---|
| アンカー不要 | IoU計算、Anchor設計、割り当て処理が不要 |
| 簡潔で拡張しやすい | 実装がシンプルで、新しいバックボーンにも対応しやすい |
| センター度スコアで精度向上 | 境界検出の抑制、より正確な中心検出 |
| マルチスケール対応 | FPNにより小〜大物体に対応可能 |
| 精度・速度ともに良好 | RetinaNetに匹敵する精度を1段階で実現 |
Transformer
Transformer は、2017年にGoogleの論文「Attention Is All You Need」で発表された、RNNやCNNを使わずにAttentionだけで構成されたニューラルネットワークモデル
自然言語処理(NLP) のために設計されましたが、現在では画像・音声・時系列データなど、あらゆる系列データの処理に応用

[Encoder(エンコーダ)] ⇨ [Decoder(デコーダ)]がN層ずつ繰り返される構造
| 特徴 | 説明 |
|---|---|
| 並列処理が可能 | RNNと異なり、全単語を同時に処理できる(高速) |
| 長距離依存性を捉えやすい | Attentionによって遠くの単語にも注目可能 |
| 拡張性が高い | 入力・出力の系列長や種類に応じて柔軟に対応可能 |
| モジュール性が高い | 構造が明確で研究・応用しやすい |
(参考)発展モデル
| モデル名 | ベース | 特徴・用途 |
|---|---|---|
| BERT | Encoderのみ | 文の理解タスク(分類・Q&Aなど) |
| GPTシリーズ | Decoderのみ | テキスト生成タスク |
| T5 / BART | Encoder + Decoder | 翻訳・要約などのエンコーダデコーダ型 |
| Vision Transformer | Encoderのみ | 画像分類タスクに応用 |
| DETR | Encoder + Decoder | 物体検出にTransformer応用 |
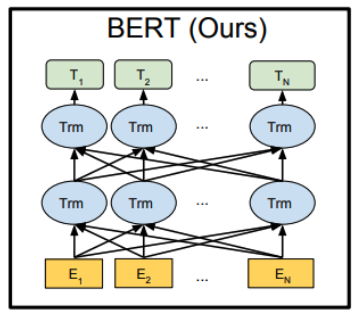
BERT
BERT(Bidirectional Encoder Representations from Transformers)はTransformerベースの自然言語処理(NLP)モデル
| 特徴 | 内容 |
|---|---|
| 双方向(bidirectional) | 前後の単語を同時に参照して文脈を理解 |
| 事前学習+微調整 | あらゆるNLPタスクで転移学習が可能 |
| 精度向上 | 文分類・質問応答・自然言語推論など多くのベンチマークでSOTAを達成 |
| 汎用性 | 単一のモデルをあらゆる下流タスクに利用可能 |
BERTは、Transformer Encoder(のみ)を多数層積んだ構造
| モデル | 層数(Encoder) | ヘッド数 | 隠れ層サイズ | パラメータ数 |
|---|---|---|---|---|
| BERT-Base | 12 | 12 | 768 | 110M |
| BERT-Large | 24 | 16 | 1024 | 340M |
(参考)他モデルとの違い
| モデル | 特徴 |
|---|---|
| GPT(Decoder) | 未来の単語だけを見る(左から右の一方向) |
| BERT(Encoder) | 前後の文脈を同時に参照(双方向) |
| RoBERTa | NSPを削除し、大規模データ・長時間学習 |
| ALBERT | 軽量版BERT。パラメータ共有で効率化 |
| DistilBERT | 小型化・高速化されたBERT |
実装演習
青空文庫から夏目漱石の 「それから」 「こころ」 「夢十夜」 をダウンロードしてくる
!wget https://www.aozora.gr.jp/cards/000148/files/773_ruby_5968.zip
!unzip -O sjjs /content/773_ruby_5968.zip
!wget https://www.aozora.gr.jp/cards/000148/files/56143_ruby_50824.zip
!unzip -O sjjs /content/56143_ruby_50824.zip
!wget https://www.aozora.gr.jp/cards/000148/files/799_ruby_6024.zip
!unzip -O sjjs 799_ruby_6024.zip
Bertモデルのインポート
from transformers import TFBertModel
from transformers import BertJapaneseTokenizer
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
bert = TFBertModel.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
with open('train.txt', 'r', encoding='utf-8') as f:
text = f.read().replace('\n', '')
mecab = MeCab.Tagger("-Owakati")
text = mecab.parse(text).split()
vocab = sorted(set(text))
char2idx = {u: i for i, u in enumerate(vocab)}
idx2char = np.array(vocab)
text_as_int = np.array([char2idx[c] for c in text])
seq_length = 128
# 訓練用サンプルとターゲットを作る
char_dataset = tf.data.Dataset.from_tensor_slices(text_as_int)
sequences = char_dataset.batch(seq_length+1, drop_remainder=True)
def split_input_target(chunk):
input_text = chunk[:-1]
target_text = chunk[1:]
return input_text, target_text
dataset = sequences.map(split_input_target)
BATCH_SIZE = 64
BUFFER_SIZE = 10000
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)
input_ids = tf.keras.layers.Input(shape=(None, ), dtype='int32', name='input_ids')
inputs = [input_ids]
bert.trainable = False
x = bert(inputs)
out = x[0]
Y = tf.keras.layers.Dense(len(vocab))(out)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
checkpoint_callback=tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_prefix,
save_weights_only=True)
model = tf.keras.Model(inputs=inputs, outputs=Y)
def loss(labels, logits):
return tf.keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)
model.compile(loss=loss,
optimizer=tf.keras.optimizers.Adam(1e-7))
model.fit(dataset,epochs=5, callbacks=[checkpoint_callback])
実装したもののランタイムがあまりにも長く結果を見ることができず断念
def generate_text(model, start_string):
# 評価ステップ(学習済みモデルを使ったテキスト生成)
# 生成する文字数
num_generate = 30
# 開始文字列を数値に変換(ベクトル化)
input_eval = [char2idx[s] for s in start_string]
input_eval = tf.expand_dims(input_eval, 0)
# 結果を保存する空文字列
text_generated = []
# 低い temperature は、より予測しやすいテキストをもたらし
# 高い temperature は、より意外なテキストをもたらす
# 実験により最適な設定を見つけること
temperature = 1
# ここではバッチサイズ == 1
model.reset_states()
for i in range(num_generate):
predictions = model(input_eval)
# バッチの次元を削除
predictions = tf.squeeze(predictions, 0)
# カテゴリー分布をつかってモデルから返された言葉を予測
predictions = predictions / temperature
predicted_id = tf.random.categorical(predictions, num_samples=1)[-1,0].numpy()
# 過去の隠れ状態とともに予測された言葉をモデルへのつぎの入力として渡す
input_eval = tf.expand_dims([predicted_id], 0)
text_generated.append(idx2char[predicted_id])
return (''.join(start_string) + ''.join(text_generated))
text = '私は'
mecab = MeCab.Tagger("-Owakati")
text = mecab.parse(text).split()
generate_text(model, text)
実装結果
私は坐復習ちらつい丸かっねぼ廻あおた仕眠く驚ろかす並びあわ蒼い見せれ訴える初手湯藤蔓茶碗聞こえれ誕生肩上遠眼東枕蒐タバコふやけごとうおかしいわけ
このように学習モデルが言葉を予測し、返答しているものの精度が低い
GPT
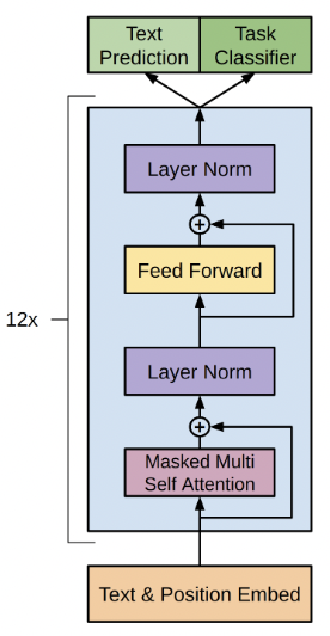
GPT(Generative Pre-trained Transformer) は、OpenAIが開発したTransformerベースの自然言語生成モデル
BERTとは異なり、自己回帰型(autoregressive)でテキストを1単語ずつ生成
| 項目 | 内容 |
|---|---|
| 名前の由来 | Generative(生成)+ Pretrained(事前学習) + Transformer |
| アーキテクチャ | Transformer Decoder のみ使用 |
| モデルタイプ | 自己回帰型言語モデル(Autoregressive LM) |
| 入力形式 | テキストを1単語ずつ左から右へ順に処理 |
GPTのtransformer
| 項目 | GPT | BERT |
|---|---|---|
| モデル構造 | Decoderのみ(左→右) | Encoderのみ(双方向) |
| 目的 | 次の単語の予測(生成) | 文全体の理解(分類・Q&Aなど) |
| 学習方式 | 自己回帰言語モデル | マスク言語モデル(MLM) |
| 出力形式 | シーケンス(テキスト生成) | 文ベクトル・分類結果など |
| 代表用途 | チャット、生成、翻訳、コード生成 | 分類、感情分析、質問応答 |
(参考)GPTの各モデル
| モデル | 年 | パラメータ数 | 特徴 |
|---|---|---|---|
| GPT | 2018 | 117M | 小規模、概念実証 |
| GPT-2 | 2019 | 1.5B | 高品質な長文生成が話題に。当初は非公開 |
| GPT-3 | 2020 | 175B | 巨大モデル、Few-shot学習が可能に |
| GPT-4 | 2023 | 非公開 | マルチモーダル、推論・創造性に優れる |
| GPT-4o | 2024 | 非公開 | オムニ(音声・画像・テキスト同時処理)対応 |
言語認識
言語認識(Language Recognition / Language Identification)とは、ある音声やテキストが何の言語で書かれている(話されている)かを判定する技術
| 項目 | 内容 |
|---|---|
| 入力形式 | 音声 or テキスト |
| 出力 | 対応する言語(例:English, 日本語, Français など) |
| タスク名(英語) | Language Identification(LID) |
| 分類タイプ | 多クラス分類(多言語の中から1つを選ぶ) |
| 難易度 | 言語間の類似性やノイズの影響により高くなることがある |
| データセット名 | 対象 | 備考 |
|---|---|---|
| Common Voice | 多言語音声(Mozilla) | 自由に使える音声コーパス |
| LRE (NIST) | 音声言語識別(政府評価) | 多数言語 × 難易度調整済み |
| WiLI (Wikipedia Language Identification) | テキスト | 235言語、Wikipedia由来 |
(参考)使用ライブラリ・モデル
テキスト向け
langdetect(Google翻訳ベース)
langid.py(軽量・高精度)
Hugging Face Transformers(例:XLM-Rを言語識別に使用)
音声向け
Kaldi(音声認識フレームワーク)
ESPnet、SpeechBrain(PyTorchベース音声AI)
Whisper(OpenAI、音声認識+言語識別)
CTC
CTC(Connectionist Temporal Classification) は、主に音声認識や手書き文字認識など、「入力と出力の長さが一致しない系列データ」に対して使われる損失関数(Loss function)およびデコーディングアルゴリズム
問題点:入力と出力の長さが違う
音声波形は 1000 フレームあっても、話された単語は10文字
文字ごとの時間位置(アライメント)が不明
解決:CTCはアライメント不要で学習できる
各時刻で出力候補(文字+空白)を出し、すべての整合パターンを確率的に合算して学習
| タスク | 説明 |
|---|---|
| 音声認識(ASR) | 音声波形(長い系列) → 文字列(短い系列) |
| 手書き文字認識 | 筆跡軌跡(連続入力) → 単語や文字 |
| 歌詞合わせ(Lyrics) | 音声と歌詞のアラインメント |
| ラベルなしの時系列学習 | 時間的な位置情報が無いデータに有効 |
CTCの基本構造
1.時系列の入力をLSTMやCNNなどでエンコード
2.各時刻でSoftmaxを通じて「文字 + blank」の出力分布を得る
3.CTCロスは、「正しい文字列」に変換できるすべてのパスの確率の合計を最大化
(参考)使用例モデル
| 分野 | 使用モデル例 |
|---|---|
| 音声認識 | DeepSpeech(CTCベース) |
| 手書き認識 | OCR with CTC |
| 発話検出 | Wav2Vec 2.0(CTCファインチューニング) |
| 音楽・歌詞対応 | Aligning Lyrics to Music |
DCGAN
DCGAN は、GAN(Generative Adversarial Network)に畳み込みニューラルネットワーク(CNN)を取り入れて安定化させたモデル
「リアルな画像をゼロから生成する」
→ ノイズベクトル(乱数)から意味のある画像(例:人の顔、数字、風景など)を生成
基本構造
| モジュール | 役割 |
|---|---|
| Generator(G) | ノイズ(z)から画像を生成する |
| Discriminator(D) | 画像が「本物」か「偽物」かを判定する(2値分類) |
| 通常のGAN | DCGANの工夫 |
|---|---|
| 全結合層 | **畳み込み(Conv)と逆畳み込み(ConvTranspose)**を使用 |
| バッチノーマライゼーションなし | BatchNormありで学習安定化 |
| 活性化関数:ReLUなど | Generator:ReLU(出力層はTanh) Discriminator:LeakyReLU |
1. Discriminatorの学習
本物画像 → 正解は「1」
Generator画像(偽物)→ 正解は「0」
2クラス分類モデルとして学習
2. Generatorの学習
ノイズ → Gが画像生成 → Dが「本物だと思ってしまう」ように学習
Dを騙すようにGを改善していく
Conditional GAN
Conditional GAN(条件付き生成敵対ネットワーク)とは「ラベルや条件に応じて、制御された画像やデータを生成できるGAN」
なぜ「条件付き」が必要か?
通常のGAN(例:DCGAN)はノイズからランダムな画像しか生成できません。
→ たとえば、「数字の3だけを生成したい」など、特定のカテゴリに応じて制御することができない。
そこで、ラベル情報(条件)を与えて目的のデータを生成できるようにしたのが cGAN です。
基本構造
| モジュール | 通常のGAN | cGAN(条件付き) |
|---|---|---|
| Generatorの入力 | ノイズz | ノイズz + 条件(ラベルや画像など) |
| Discriminatorの入力 | 画像のみ | 画像 + 条件(同じ条件かどうかを判定) |
代表的な拡張モデル
| モデル名 | 内容 |
|---|---|
| AC-GAN | 条件分類器をDiscriminatorに組み込む(auxiliary classifier) |
| pix2pix | 条件を「画像」にする → 画像から画像への変換モデル |
| StarGAN | 1つのG/Dで複数ドメインの変換に対応できる |
| Text-to-Image GAN | 条件を「文章」にして画像を生成(例:テキスト→鳥画像) |
Pix2Pix
Pix2Pix は、画像から画像への変換(Image-to-Image Translation) を行う条件付きGAN(cGAN)モデル
| 入力画像 | 出力画像 |
|---|---|
| ラフな線画 | フルカラー画像 |
| 白黒写真 | カラー化写真 |
| 地図画像 | 航空写真 |
| セグメンテーションマスク | 実画像 |
| スケッチ | 写真風画像 |
➜ 入力画像に対応する教師画像(正解画像)が必要 → ペア画像の教師あり学習
| モジュール | 概要 |
|---|---|
| Generator(G) | 入力画像(例:スケッチ) → 出力画像(例:写真)を生成 |
| Discriminator(D) | 入力画像と出力画像のペアが本物か偽物かを判定する |
(参考)メリット・デメリット
| 項目 | 内容 |
|---|---|
| ✅ 制御性あり | 入力に対応した出力画像が得られる(例:マスク → 写真) |
| ✅ 高精度 | U-Net + L1 により構造を保った正確な画像を生成 |
| ❌ 教師あり | ペア画像(入力・出力の対応関係)が必要 |
| ❌ 解像度制限 | 高解像度生成にはCycleGANやPix2PixHDのような拡張が必要 |
A3C
A3C(Asynchronous Advantage Actor-Critic) とは複数のエージェントを並列に動かしながら、ポリシーと価値を同時に学習するActor-Critic法の強化学習アルゴリズム
従来の深層強化学習の課題
| 課題 | 説明 |
|---|---|
| 経験再利用が必要 | DQNはExperience Replayに依存していた |
| 学習が安定しにくい | 同じ状態が何度も現れる必要がある |
| 並列処理が難しい | 同時に学習を進めると競合や非定常性が発生する |
➡ A3Cは経験再利用なしでも安定して学習でき、複数エージェントを非同期に動かすことで効率的に環境を探索
基本構成
| モジュール | 役割 |
|---|---|
| Actor | 方策(Policy)π(s)を学習(どの行動を選ぶか) |
| Critic | 価値関数V(s)を学習(現在の状態がどれだけ良いか) |
| 特徴 | 内容 |
|---|---|
| 非同期並列学習 | 複数のスレッド(ワーカー)が別々の環境で同時に探索・学習 |
| 共有ニューラルネット | 各スレッドがパラメータを共有しており、非同期に更新 |
| 値関数 + 方策関数 | Actor-Critic構造により、高バイアス・高分散を打ち消す |
| Advantage使用 | 学習を安定させるためにAdvantage = Q(s, a) − V(s) を導入 |
DQNとの違い
| 項目 | DQN | A3C | |
|---|---|---|---|
| 学習の仕組み | 経験再生(replay buffer) | 非同期スレッドによるリアルタイム学習 | |
| 探索方法 | ε-greedy | ポリシーに基づくサンプリング | |
| 出力 | Q(s, a) | π(a s), V(s) | |
| 並列化のしやすさ | 難しい | 容易(並列探索可能) | |
| 安定性 | バッチ学習で安定 | Advantageで安定 |
Metric-learning(距離学習)
Metric Learning(距離学習)とは「データ間の類似度や距離を学習することで、意味的に近いデータを近づけ、異なるデータを遠ざけるように表現空間を構築する機械学習手法」
| 入力データA | 入力データB | 学習の目的 |
|---|---|---|
| 類似 | 類似 | → 埋め込み空間で近くに配置したい |
| 異なる | 異なる | → 埋め込み空間で遠ざけたい |
➤ 目的は、距離関数(Metric)を学習可能にすること!
| 学習形式 | 説明 |
|---|---|
| Siamese | 2つのデータの類似・非類似を判定するペア形式 |
| Triplet | Anchor + Positive + Negative の3つ組で距離関係を学習 |
| N-pair / Proxy | 複数クラスをまとめて同時に学習(分類器のような学習が可能) |
| 利点・欠点 | 内容 |
| ✅ 汎用性 | ラベルがなくても、距離に意味を持たせれば応用範囲が広い |
| ✅ 新規クラス対応 | 既知のクラスだけでなく、未知のデータにも対応しやすい |
| ❌ 学習が難しい | Tripletの選び方(Hard Miningなど)が精度に大きく影響 |
| ❌ 精度調整が繊細 | 距離のスケール調整、margin選択、ベクトル正規化などが必要 |
Metric Learningと分類学習
| 観点 | 分類(Classification) | Metric Learning |
|---|---|---|
| 出力形式 | ラベル(softmaxなど) | ベクトル間距離 |
| 学習目標 | クラスに正しく分類する | 類似データ間の距離関係を正しく学習する |
| 応用例 | 一般的な分類タスク | 類似画像検索、顔認証、クラスタリングなど |
| 未知クラスへの対応 | 苦手 | 得意(新しいクラスにも距離で対応可能) |
MAML(メタ学習)
MAML(Model-Agnostic Meta-Learning) とは「少数のデータでもすぐに学習・適応できるモデルを作るためのメタ学習アルゴリズム」
| 問題 | MAMLが解決すること |
|---|---|
| 新しいタスクにすぐ学習したい | 初期パラメータを良い位置にしておく |
| タスクごとのデータが少ない | 少ないデータでも高性能な適応ができる |
| 多タスク環境がある | どのタスクでもすぐ適応できるようにする |
| 特徴 | 説明 |
|---|---|
| ✅ モデル非依存(Agnostic) | ニューラルネットでも決定木でも適用可能 |
| ✅ few-shotに強い | 1〜5個のデータでも高速に適応可能 |
| ✅ 実行時の学習が前提 | 実行時(テスト時)にも「数ステップの学習」が行われる(Adaptation) |
応用例
| 分野 | 応用内容 |
|---|---|
| few-shot分類 | 数枚の画像から新しいクラスを即座に認識 |
| ロボット制御 | 未知のタスク(障害物回避など)への即時適応 |
| 強化学習 | 少数試行で新しい環境に順応(Meta-RL) |
| 自然言語処理 | 新しい言語やドメインへの転移学習 |
| 医療画像 | 少数の疾患画像から診断モデルを素早く更新 |
グラフ埋め込み(GCN)
グラフ埋め込み(Graph Embedding)とはグラフ構造(ノード・エッジ)を保持したまま、ノード・エッジ・グラフ全体をベクトル表現に変換する手法
| 問題 | 解決方法 |
|---|---|
| グラフは構造が複雑 | → 数値ベクトルにして機械学習で扱いやすくする |
| ノード分類・リンク予測などに使いたい | → 各ノードを意味のあるベクトルに埋め込む |
「画像」の畳み込みと「グラフ」の違いは?
CNNでは画像の近傍ピクセルから特徴を集める(2Dグリッド構造)
GCNではノードの近隣ノードから情報を集約する(グラフ構造)
応用例
| 分野 | GCNの利用例 |
|---|---|
| SNS分析 | 友人関係のグラフからユーザ属性予測 |
| サイバーセキュリティ | 通信ログをグラフ化し、異常検出 |
| 薬物発見 | 化合物構造(グラフ)を分類し、有効性を予測 |
| 知識グラフ | エンティティと関係のグラフから推論 |
| 自然言語処理 | 文法構造や依存構造をグラフにして意味解析 |
メリット・デメリット
| 項目 | 内容 |
|---|---|
| ✅ 高性能 | 構造 + 属性を活かしたノード表現が可能 |
| ✅ 汎用性 | 様々なグラフタスクに適応可能(分類、回帰、予測など) |
| ❌ 拡張性 | 全ノードを扱うため、大規模グラフには非効率(→GraphSAGEなどが対応) |
| ❌ 過平滑化 | 層を重ねすぎると、埋め込みが似通い過ぎて情報が失われる(over-smoothing) |
Grad-CAM, LIME, SHAP
Grad-CAM(Gradient-weighted Class Activation Mapping)
CNNベースの画像モデルにおいて、「どの部分のピクセルが判断に影響を与えたか」を可視化する手法
画像分類で「この猫ってどこを見て“猫”と判断したの?」を知りたい
CNNの中間層(特徴マップ)と最終出力の勾配(gradient)を使って注目領域をヒートマップで表示
原理
1.任意の**畳み込み層(例:最後のConv層)**の出力(特徴マップ)を取得
2.特定クラスの出力に関する勾配を計算(逆伝播)
3.勾配を特徴マップごとに平均して重みとし、線形結合+ReLU
4.得られたマップを元画像に重ねてヒートマップ表示
LIME(Local Interpretable Model-agnostic Explanations)
どんな機械学習モデルでも使える「ローカル解釈可能な説明手法」
→ 特定の入力サンプルに対して、どの特徴が予測にどれくらい影響したかを線形モデルで説明
原理
1.入力データを少しずつ改変して類似データを多数作成
2.各データに対する元モデルの出力を取得
3.入力サンプル周辺のデータに対し、線形回帰で「ローカルな説明モデル」を学習
4.係数の大きさ=その特徴の重要度を可視化
SHAP(SHapley Additive exPlanations)
「各特徴量が最終予測にどれだけ貢献したか」を公平に分配する理論的な手法。
ゲーム理論におけるShapley値を機械学習に応用したもので、LIMEより理論的根拠が強い
原理
1.全ての特徴の組み合わせ(特徴を加えたり除いたり)を試す
2.特徴の有無による出力の差分を多数計算
3.平均的な貢献度として**各特徴に「Shapley値」**を割り当て
(高速化のためにTreeSHAPなどの近似アルゴリズムが実用化)
使い分けまとめ
| 目的 | 推奨手法 |
|---|---|
| 画像分類で「どこを見てるか」を見たい | Grad-CAM |
| どんなモデルでも簡易な局所解釈をしたい | LIME |
| 厳密で公平な特徴の影響を見たい(数値) | SHAP |
| 手法 | 対応データ | モデル依存性 | 出力形式 | 特徴 |
|---|---|---|---|---|
| Grad-CAM | 画像 | CNN特化 | ヒートマップ | 視覚的に直感、局所注目可視化 |
| LIME | テキスト・画像・表 | モデル非依存 | 特徴ごとの重み | 特定入力に対する局所的説明 |
| SHAP | 主に表形式 | モデル非依存(TreeSHAPあり) | SHAP値(貢献度) | グローバル+ローカルで公平に説明 |
実装演習
Interpretabilityを実装
import numpy as np
import cv2
import tensorflow as tf
from tensorflow.keras.applications import VGG16
class GradCam:
def __init__(self, model):
self.model = model
# 畳み込み最終層の名前を確認するため
print([layer.name for layer in self.model.layers])
def gradcam_func(self, x, layer_name):
# 一枚の画像だと、バッチの次元がないので足す
X = x[np.newaxis, ...]
# 正規化
X = X / 255.
# 畳み込み層の最後の層の出力を受け取る
conv_feature = self.model.get_layer(layer_name).output
model = tf.keras.Model([self.model.inputs], [conv_feature, self.model.output])
# 勾配を記録するために tf.GradientTape() を使う
with tf.GradientTape() as tape:
# numpy配列を勾配を計算するためにtfの型に変換する
X = tf.cast(X, tf.float32)
conv_feature, outputs = model(X)
# どのクラスを予測したか
predicted_class = tf.math.argmax(outputs[0])
# 予測したクラスの出力を取得する
class_outputs = outputs[:, predicted_class]
# 勾配を計算する
grads = tape.gradient(class_outputs, conv_feature)
print('予測クラス', predicted_class.numpy())
# 平均を取る(GAP)
weights = tf.math.reduce_mean(grads, axis=(1, 2))
cam = conv_feature @ weights[..., tf.newaxis]
cam = tf.squeeze(cam)
# reluに通す
cam = tf.nn.relu(cam)
cam = cam / tf.math.reduce_max(cam)
# 正規化を戻す
cam = 255. * cam
# numpy配列にする
cam = cam.numpy()
cam = cam.astype('uint8')
# カラーマップを作る
jetcam = cv2.applyColorMap(cam, cv2.COLORMAP_JET)
# BGRからRGBに変換
jetcam = cv2.cvtColor(jetcam, cv2.COLOR_BGR2RGB)
jetcam = cv2.resize(jetcam, (224, 224))
jetcam = jetcam + x / 2
return jetcam
model = VGG16(weights='imagenet')
gradcam = GradCam(model)
image = cv2.imread('../data/interpretability_example_input.png')
image = cv2.resize(image, (224, 224))
cam = gradcam.gradcam_func(image, 'block5_conv3')
if ENV_COLAB:
from google.colab.patches import cv2_imshow
cv2_imshow(image)
cv2_imshow(cam)
else: # Jupyter
from matplotlib import pyplot as plt
cv2.imshow('',image)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.imwrite('../data/interpretability_example_output.png', cam)
cam_read = cv2.imread('../data/interpretability_example_output.png')
cv2.imshow('',cam_read)
cv2.waitKey(0)
cv2.destroyAllWindows()
予測クラス 999(トイレットペーパー)でGrad-CAMを試すとヒートマップが確認された
トイレットペーパーの真ん中あたりが影響力が高い


Docker
「アプリケーションとその実行環境をまるごとパッケージ化して、どこでも同じように動作させることができる仮想化技術」
軽量なコンテナ型仮想化を用いた開発・配布・実行環境
サーバー・ローカルPC・クラウドなどどこでも同一動作が可能
| 従来の問題 | Dockerによる解決 |
|---|---|
| 開発環境が本番と違って動かない | → 同じコンテナで再現性100% |
| ライブラリのバージョン依存が面倒 | → イメージに必要な環境をすべて閉じ込められる |
| 「動くPCと動かないPC」が発生する | → コンテナはどこでも同じように動作する |
| 用語 | 説明 |
|---|---|
| イメージ | アプリやミドルウェア、設定を含む「ひな型」 |
| コンテナ | イメージを実行した「実体」。仮想マシンに近いが軽量 |
| Dockerfile | イメージを作るためのレシピファイル(OS、依存、コピー、コマンドなどを記述) |
| Docker Hub | 公式・ユーザー投稿のイメージ共有サイト(GitHubのようなもの) |
| ボリューム | コンテナ外のデータを永続化する仕組み(データベース保存などに使う) |
実用例とメリットデメリット
| 分野 | 活用例 |
|---|---|
| Web開発 | Django / Flask のローカル環境構築 |
| データサイエンス | JupyterLab + GPU環境をコンテナで統一 |
| DevOps | CI/CD パイプラインにDocker組み込み |
| クラウド運用 | AWS / Azure / GCP にDockerごとデプロイ |
| チーム開発 | 「このDockerfileで動くよ!」という再現性のある環境共有が可能 |
| 項目 | 内容 |
|---|---|
| ✅ 再現性 | どこでも同じ環境・同じ挙動が保証される |
| ✅ 軽量 | 仮想マシンより遥かに軽い(OSを含まない) |
| ✅ ポータビリティ | 他人のPC・サーバー・クラウドなど、環境問わず実行可能 |
| ❌ 学習コスト | 初学者にはDockerfile/Volume/Networkなどの概念がやや複雑 |
| ❌ パーミッション | Linux系権限管理に慣れていないと詰まることがある |