背景
日立製作所大みか事業所では、大みかグリーンネットワーク(OGN, Omika Green Network)として社会全体のカーボンニュートラル達成をゴールに、事業活動と環境負荷低減の両立に取り組んでいます。
日立製作所 大みかグリーンネットワーク
本記事ではOGNの一環として、場内施設の作業効率化を目的としたクラウドサービスと機械学習による遠隔監視についてご紹介します。
目的
工場内の製造現場には人による定期的な状態監視を必要とする作業が多数存在します。なかでも頻度が高く屋外で作業する必要があるものは雨天時などに作業者の負担が大きく、作業ミスが生じる恐れがあります。
上記のような作業ミスは事故につながる恐れがあるため、作業効率化と安全性の観点から監視作業の自動化を目指し、検討を行いました。
取り組み概要
監視作業の自動化の概要は以下の通りです。
まず監視場所にIPカメラと日立制御エッジコンピュータ CE50-10Aを設置し、IPカメラから取得した映像をCE50-10Aを介してGCP(Google Cloud Platform)に送信します。
GCP上では機械学習サービスAutoML Tablesが受信した映像を用いて異常検知モデルを作成します。ここで異常検知モデルとは、入力されたデータを2種類の異常状態、1種類の通常状態に分類するモデルとします。モデルを作成後、監視場所のCE50-10Aはカメラ映像から作成したデータをGCP上のモデルに入力し、継続的に状態分類を行うことで異常検知により監視作業を自動化します。

AutoML Tablesとは
AutoML TablesはGCPが提供する機械学習サービスの1つで、表形式データ(構造化データ)に対する以下の回帰/分類を行う機械学習モデルを作成することができます。
| モデルの種類 | 目的 |
|---|---|
| バイナリ分類 | 2択の結果を予測 |
| 多クラス分類 | 3つ以上のクラスのうち1クラスを予測(分類) |
| 回帰 | 連続値を予測 |
モデルの訓練データには、下図のように目的変数と1つ以上の説明変数が格納された列で構成された表形式データが必要となります。作成する機械学習モデルでは目的変数が出力、説明変数が入力となります。

AutoML Tablesによる学習で得られる学習済みモデルは、GCP上にデプロイすることでローカルからREST APIで実行(オンライン予測)が可能です。
本記事でやること
本記事ではAutoML Tablesによるモデル作成およびオンライン予測の手順を示すため、下図のように画像を3クラスに分類する多クラス分類モデルを作成します。モデルは分類対象の画像から計算した平均輝度値など計82個の特徴量を説明変数とし、予測するラベル0~2の数値を目的変数とします。

一般的に画像の分類を目的とするモデルでは、下記の記事のように画像自体がモデルの入力となります。
Google Cloudで構築した画像分類モデルをエッジで動かす Qiita
ただし、今回は屋外のIPカメラから取得した画像への適用を想定しており、影などの外乱の影響を受けにくい統計的特徴量を用いた分類モデルを作成する必要があるため、AutoML Tablesを選択しました。
モデルの構築手順
以下Step1~4で訓練データの準備から学習済みモデルのデプロイ、予測までの作業手順を示します。
手順の前提条件として、既にGCP上に学習、予測を行うための作業用プロジェクトを作成したものとします。また、監視場所のCE50-10Aについては、GCPをコマンド操作するためGoogle Cloud SDKを導入しているものとします。
Step1:訓練データの準備
学習のため、CSV形式の訓練データをGCP上にアップロードします。
初めにGoogleCloudプラットフォームにアクセスします。下図を参考に、作業用プロジェクトが有効化されていることを確認し、ページ上部の検索ボックスからVertex AIへ移動します。

移動後、左サイドのメニューからDATA>データセットへ移動し、データセットを作成します。今回は図のように表形式の回帰/分類を選択し、”データソースを選択”からCSV形式の訓練データをアップロードします。保存するGCP上の場所が指定できない場合は新規に作成してください。
また、注意点としてアップロードするCSVファイルは1ファイルにつき最低1000行のデータが必要なため、それ以下の場合は警告やエラーが発生することがあります。

CSVファイルのアップロードが完了すると、下図の画面へ遷移します。特に警告やエラー等が発生しなければ、右サイドの”新しいモデルをトレーニング”をクリックし、学習に関する設定を行います。

トレーニング方法の設定画面が表示されるので、下図のように各オプションを選択します。
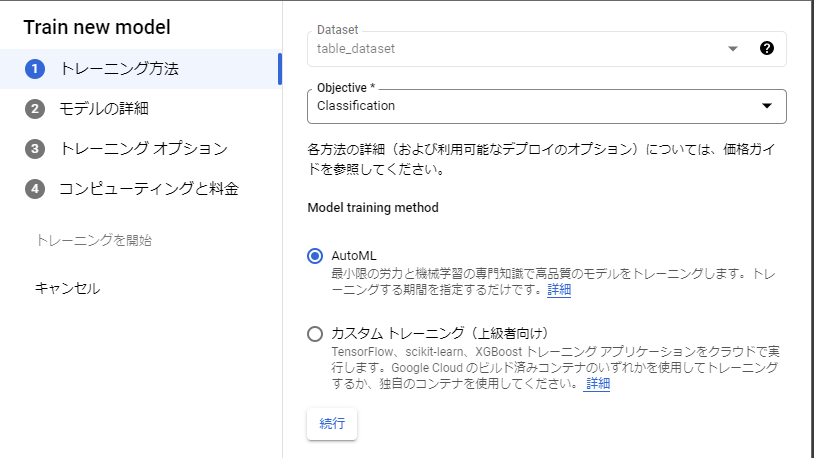
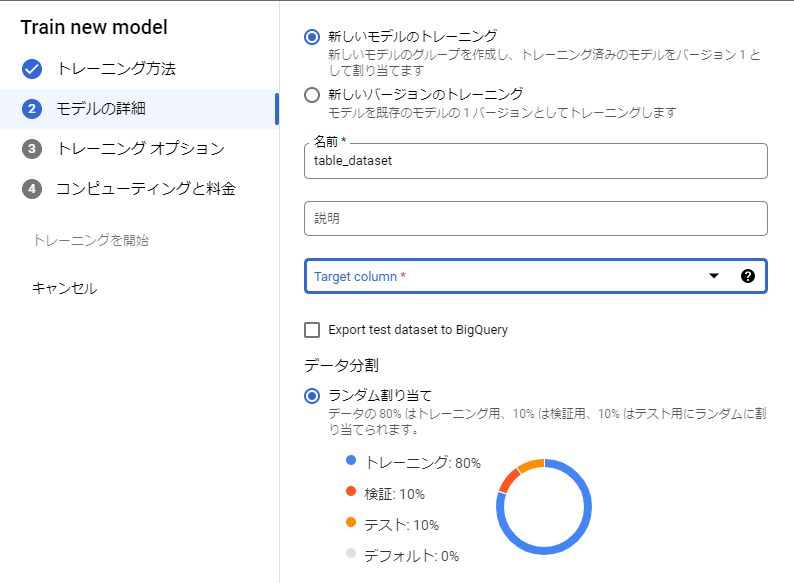
モデルの詳細ではTarget columnにモデルの目的変数となる列を指定します。また、”詳細オプション”では訓練データに対する学習、検証、テスト用の割合を設定でき、デフォルトではアップロードした全訓練データに対し学習:80%、検証:10%、テスト:10%と設定されています。
次のトレーニングオプションでは訓練データのデータ型を確認します。今回は画像から計算した特徴量をするため、数値型を指定します。データ型は手動で設定可能です。

最後に学習にかかるノード時間を設定して学習を開始します。
Step2:モデルの学習と評価
学習の進行状況は、MODELDEVELOPMENT>トレーニングから確認できます。
学習時間については、今回1000行×82列の訓練データに対し1ノード時間で実行したところ約2時間かかりました。
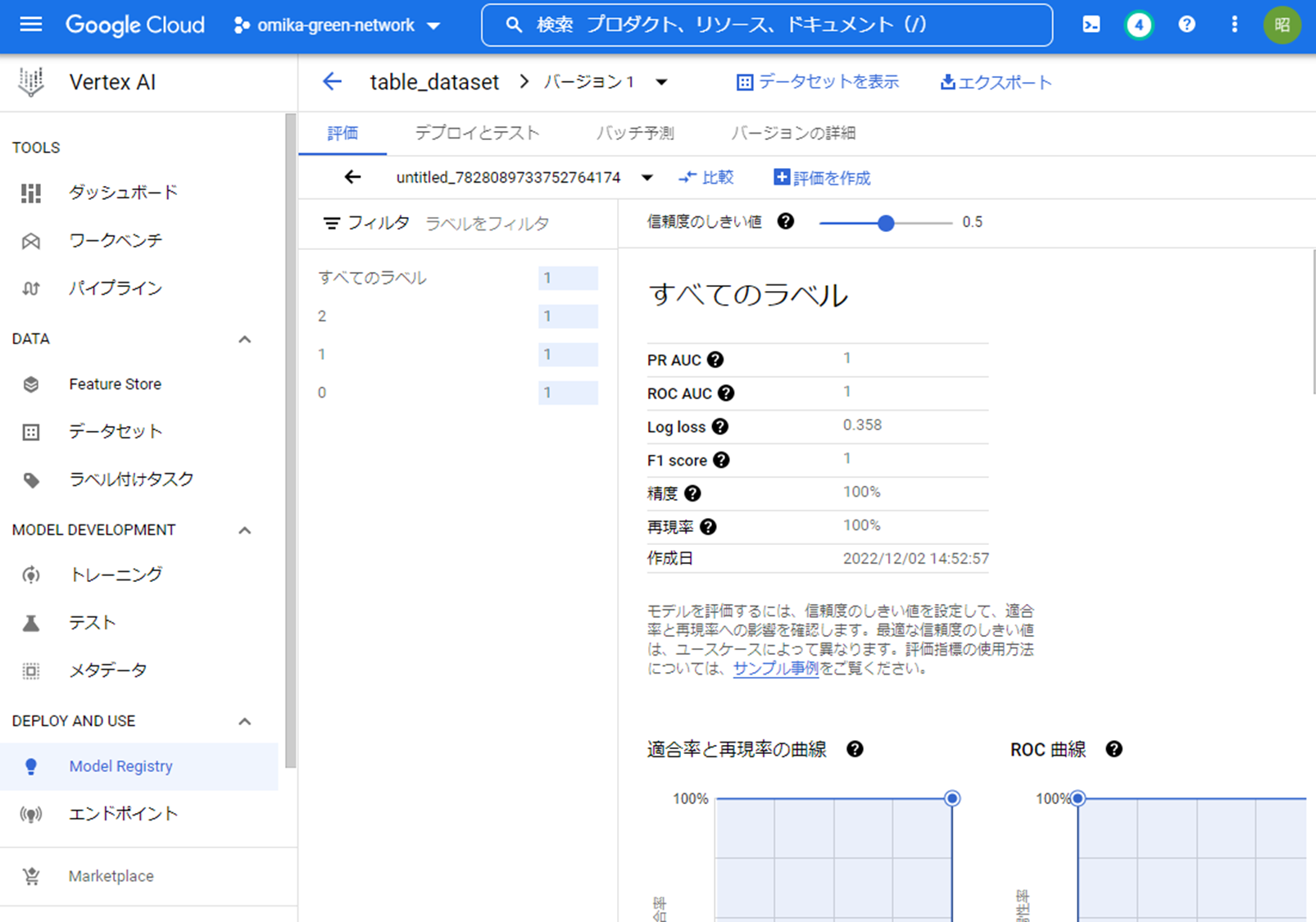
学習が完了すると次のような画面が表示され、学習したモデルの再現率や適合率などの評価指標を確認することができます。
Step3:デプロイ
作成した学習済みモデルでオンライン予測を行うためには、GCP上のエンドポイントにモデルをデプロイする必要があります。
モデルのデプロイはModelRegistryを開き、デプロイしたいモデルのオプションから”エンドポイントにデプロイ”を選択します。デプロイ作業は5~15分程度かかります。

デプロイが完了すると、ステータスがアクティブになります。
Step4:学習済みモデルの実行
デプロイ完了後、アクティブと表示されたモデルを選択し、ページ上部の”リクエストの例”をクリックします。
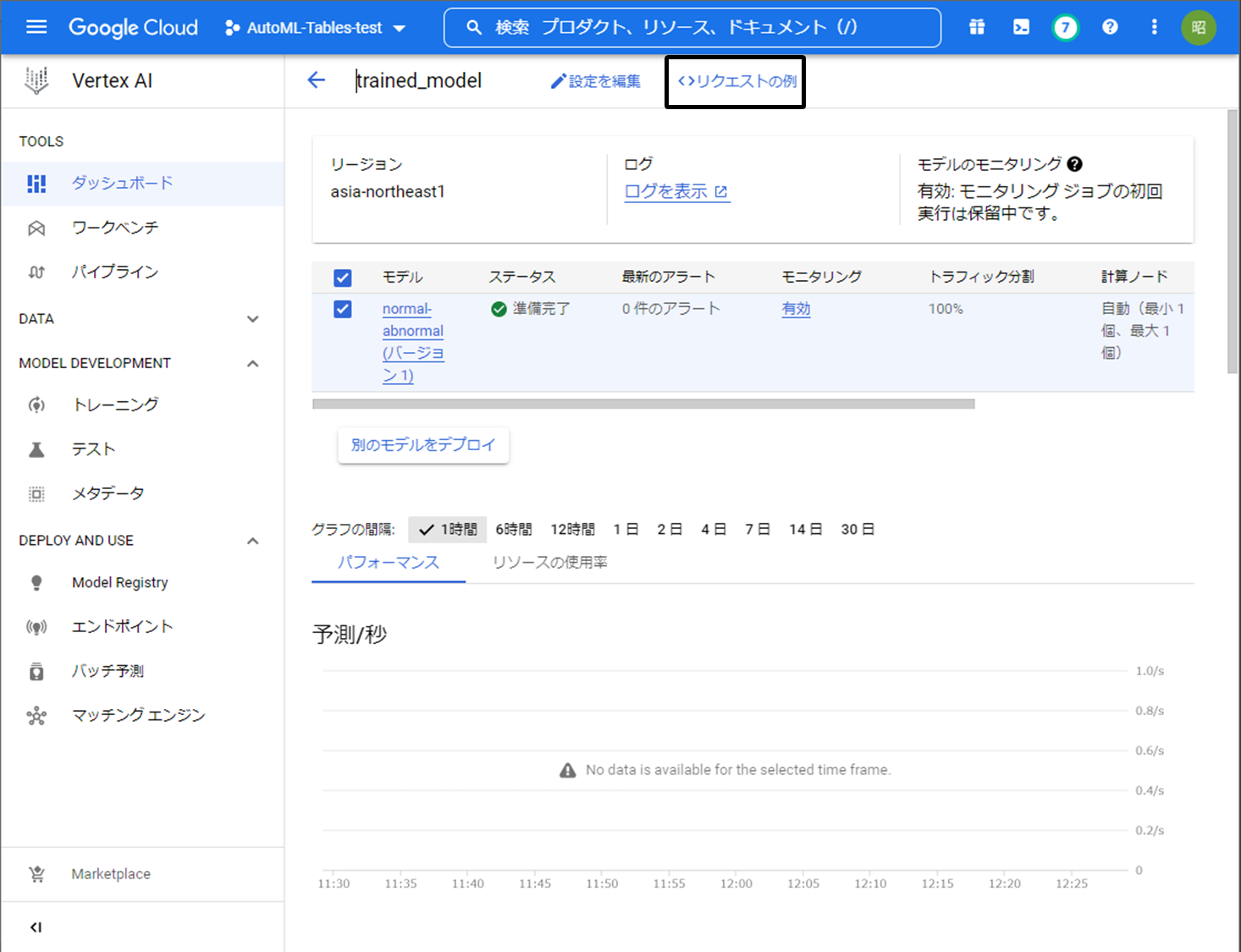
オンライン予測では、下図のようにREST APIによるリクエスト方法が提供されています。
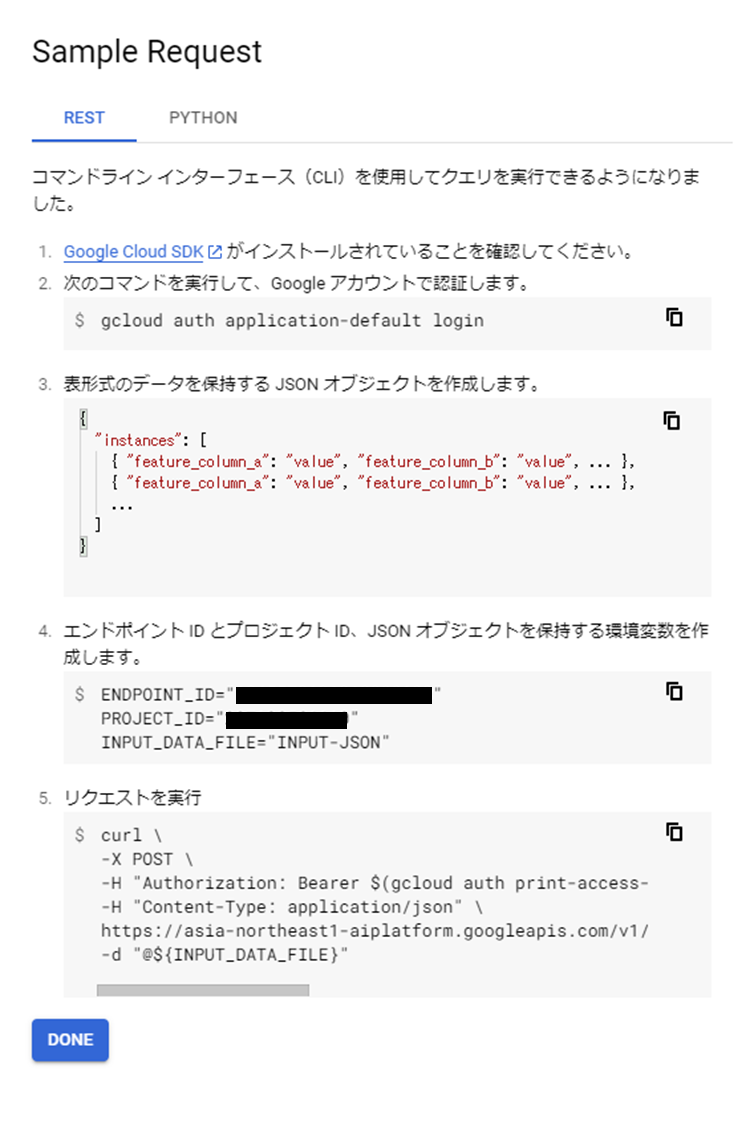
EDNPOINT_ID、PROJECT_IDは実行中の環境の値が自動で表示されるので、モデルに入力したいデータをjson形式で作成し、上記のコマンドを用いてGCPに送信することでモデルの実行結果を得ることができます。
実行結果
GCP上でリクエストが処理されると、モデルの実行結果を下記形式で得ることができます。
{
"predictions": [
{
"scores": [
0.74153870344161987,
0.145133301615715,
0.1133279651403427
],
"classes": [
"0",
"1",
"2"
]
}
],
"deployedModelId": "-",
"model": "-",
"modelDisplayName": "-",
"modelVersionId": "1"
}
Scoresの3つ数値はclassesの0,1、2とそれぞれ対応しており、例えば上記の場合、classes:0のScoresが0.74と最も高い値を示しています。したがって、モデルに入力されたデータに最も近いクラスはclasses:0であるという予測結果がわかります。
まとめ
本記事では現場の状態監視の作業効率化のため、AutoML Tablesを用いて画像分類による異常検知モデルを作成しました。さらに、GCP上で学習済みモデルを実行し、結果をCE50から取得することで本システムの適用性を示しました。
参考資料
免責・商標類
- 本記事に記載した手順は、その動作や結果を保証するものではありません。
- 製品の改良により、予告なく記載されている仕様が変更になる場合があります。
- 本記事に記載の会社名、製品名などは、それぞれの会社の商標もしくは登録商標です。