
Deep Learning で物体認識を行うには一般に、高性能なコンピューターが必要です。高性能でも、単なる一般処理向けの CPU では、Deep Learning の処理には非力です。ここ数年、Deep Learning が注目されるようになった切っ掛けも、GPU を Deep Learning 用の演算装置(GPGPU: General Purpose Graphics Processing Unit 汎用GPU) として利用できるようになったからです。なのに Raspberry Pi で Deep Learning? と思ってしまいます。Deep Learning の処理に使える GPU を搭載した PC は、持ち歩くことなんてできません。お試しではなく、まともに Deep Learning の計算をさせようと思ったら、そんな PC が一台では足りませんし、Note PC であっても重量級です。それじゃあ Raspberry Pi では、尚の事だとお思いでしょう。 − その通りです。Raspberry Pi で、Deep Learning の処理を行おうなんて、言ったこともなければ、心に昇ったこともありません。コンピューター・エンジニアリング、或いは、コンピューター・サイエンスの世界では、「クライアント・サーバー・アーキテクチャ」は当然の常識です。重たい処理は、バックのサーバーや汎用・大型コンピューターで行う仕組みです。見た目は子供向けの学習用シングルボードコンピュータ−、頭脳は世界最高水準の並列処理コンピューター、それが今回ご紹介するシステムです。ロマンチックですね。

スマートフォン向けには、Flutter と Firebase を使った「わんぱく Flutter! 第四回 いきなりっ!画像認識をしてみよう。」でも、画像認識について解説しています。
1.準備
以前、職場の技術者が、私が作業に使っている 最軽量 Windows Tablet PC を見て、「それがスーパーコンピューターなの?」と言ってきたことがありました。私はその PC を端末にしてオフィスから、研究所のスーパーコンピューターに接続してプログラムを開発していたのですが、彼はそれを知らなかったらしく、こんな質問をしてしまったようです。ご存知の通り、PC と言うのは、Personal Computer つまり、個人用コンピューターと言う意味ですが、汎用機や大型コンピューターには、それを操作する為の端末、Work Station (WS) と言うコンピューターがあります。汎用機や大型コンピューターには、直接、キーボードやディスプレイは付いていないのです。まあ、当然の常識なので、私たち技術者や研究者の間では説明の必要はないのですが、じゃあ、彼はなぜ知らなかったのでしょうか。深入りはしてませんけどね。
まず、Raspberry Pi を用意することは言うまでもないことなのですが、今、これを読んでいる ちびっこ達は、もう持っていることでしょう。ですから、Google Cloud Vision API を使うために Google Cloud Platform に登録するところから初めましょう。下記の URL からアクセスして下さい。
 図1
図1
もちろん、Google のアカウントは持っていますよね。まだの方は、Google のアカウトも作成しておきましょう。そうしたら、「無料で使ってみる」のボタンを押して、画面の指示に従って登録して下さい。
Google Cloud Platform への登録が終わったら、下記の URL から Cloud Vision API を有効にしましょう。
 図2
図2
説明されている通り、プロジェクトを選択するのではなく、何か新しいプロジェクトを作成しておきましょう。そして、Cloud Vision API は課金の掛かるサービスなので、項目 3 でも説明されているように、課金の設定をして API を有効にして下さい。月に 1,000 回までは課金されません。API を有効にしたら、説明されている通りにサービスアカウントを作成し、「サービスアカウントキー」の json を取得します。これが強調している通り、重要です。このキーを使って Vision API は、利用者の認証を行っています。これも、説明の通りに環境変数 GOOGLE_APPLICATION_CREDENTIALS へ設定しておきます。これで準備完了です。
2.物体認識について
Deep Learning で行う物体認識は、ほぼ CNN(Convolutional Neural Network : 畳み込みニューラルネットワーク)であると言っていいでしょう。最近、AI と持てはやされている技術は、この CNN を Modify つまり、手を加えたものです。
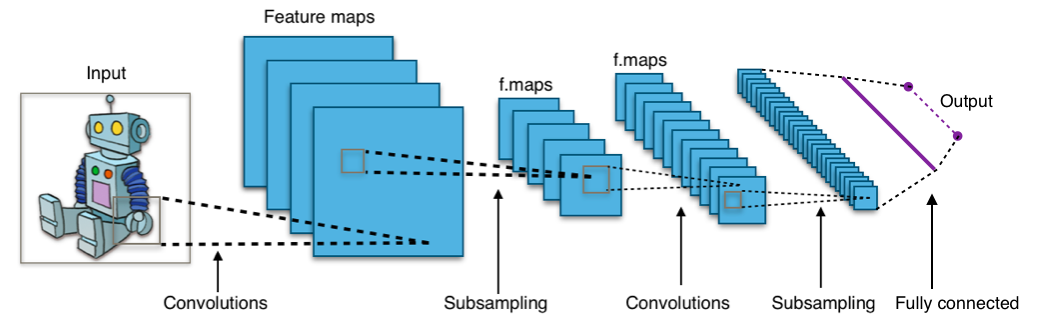 図3 (CC BY-SA 4.0)
図3 (CC BY-SA 4.0)
CNN の基本は、この図の通り、Convolutions 層と、Subsampling で表されている Pooling 層の繰り返しです。Convolutions とは、「畳込み」と訳されていますが、畳込み積分、合成積の事で、従来の画像処理で言うところのフィルター、ぼかし処理に類似した処理です。
式1 : Convolution
u_{ij} = \sum_{p=0}^{with-1}{\sum_{q=0}^{height-1}{x_{(i+p),(j+q)}}} \cdot f_{pq}
u : Convolution 値
i,j : 入力画像の画素インデックス
p,q : フィルターの画素インデックス
x : 入力画像の画素値
f : フィルターの画素値
with : フィルターの横幅
height : フィルターの縦幅
畳込み処理は、加重平均と言うと分かりやすいかも知れません。下記のアニメでは、kernel で表されているフィルターの画素値 f と、input の画素値 x の積をフィルターの (p,q) と入力画像の (i,j) をスライドさせながら足し込んでいるのがよく分かります。
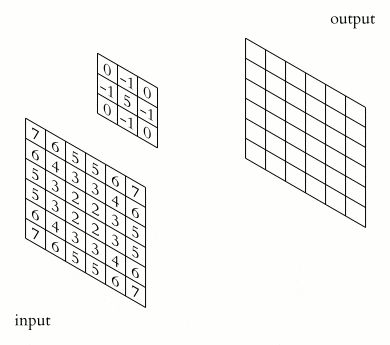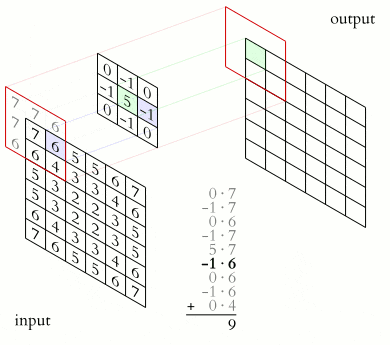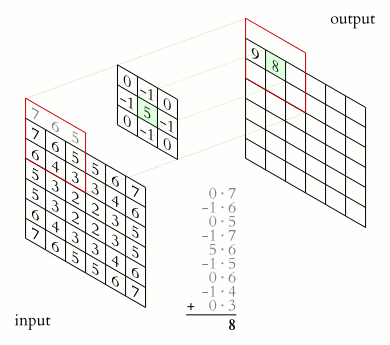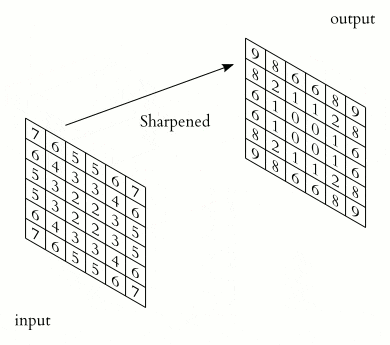 図4 (CC BY-SA 3.0)
図4 (CC BY-SA 3.0)
これを プログラム で書くと、こういう意味となります。
プログラム1
double convolution( int i, int j ){
for(int p = 0; p < with; p++){
for(int q = 0; q < height; q++){
u[i][j] += x[i+p][j+q] * f[p][q];
}
}
return( u[i][j] );
}
これで、説明の必要はなくなったかな?
アニメのフィルターは、中心が 5 の「点」の画像強調フィルターの例ですが、このフィルターを縦線・横線・斜め線など、色々なものを用意して、入力画像の 特徴 を捉えます。
式2 : フィルター
\begin{bmatrix} 0 & 3 & 0 \\ 0 & 4 & 0 \\ 0 & 3 & 0 \end{bmatrix}
\begin{bmatrix} 0 & 0 & 0 \\ 3 & 4 & 3 \\ 0 & 0 & 0 \end{bmatrix}
\begin{bmatrix} 3 & 0 & 0 \\ 0 & 4 & 0 \\ 0 & 0 & 3 \end{bmatrix}
\begin{bmatrix} 0 & 0 & 3 \\ 0 & 4 & 0 \\ 3 & 0 & 0 \end{bmatrix}
そして Pooling 層では、Subsampling と表されている通り、Convolution の結果を単純に平均化したり、最大値を取って、Down Sampling 小さな画像に変換します。
CNN は、この Convolution と Pooling をフィルター毎に行う処理を何層 も重ねているものです。数学的には、意外に簡単ですね。
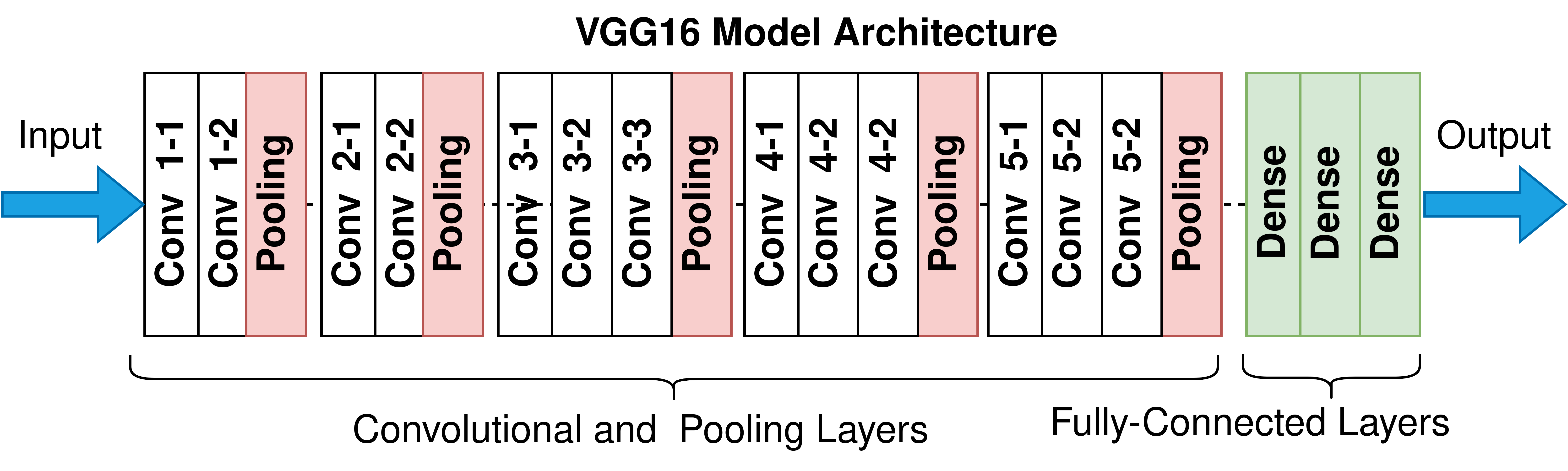 図5 (CC BY-SA 4.0)
図5 (CC BY-SA 4.0)
そうです、しかし、計算量が膨大です。例えば、2014年に ILSVRC(ImageNet Large Scale Visual Recognition Challenge) で優勝した VGG16 と言うモデルでは、16 層の計算を行っています。Deep Learning 深層学習の名前の所以ですね。しかし、まだまだ序の口です。
最後に Fully connected 全結合処理を行います。全結合は、三層のバックプロパゲーションや、サポートベクターマシンによるクラスタリング、分類処理です。Convolution と Pooling で得られた特徴から、分類するわけです。バックプロパゲーションについては、私も別のページで詳細に解説しておりますので、ご参照下さい。
 図6
図6
3.Vision API
Vision API には、物体認識(ImageAnnotator と呼ばれる)以外にも沢山の機能が用意されています。これらを、Raspberry Pi で処理しようとするのは、無知としか言いようがありません。 ー そうです、不可能、あり得ないことなので、冒頭でも述べた通り、説明の必要のない当然のことなのです。しかし、これからコンピューターを学ぶラズパイちびっこ達には、説明が必要でしょう。Raspberry Pi を Google のコンピューターに接続して Raspberry Pi を機能拡張します。これが、コンピューター・エンジニアリング、コンピューター・サイエンスにおける「クライアント・サーバー」技術です。電気的には、Raspberry Pi の上に載せた Hat と同じなのです。
response = client.label_detection(image=image)
labels = response.label_annotations
上記 URL で説明されている通り、物体認識を行いたい画像を Vision API の引数 image に指定して渡すと、戻り値 response に json 形式で返ってくるものです。ターンアラウンドタイムは、悪くても数秒です。(ターンアラウンドタイムと、レスポンスタイムの違いは憶えてますね) 前述の VGG16 のような、より複雑な Deep Learning の処理がこのレスポンスで返ってくるなら充分でしょう。今回は、Python で行いますので、Google Cloud Vision のモジュールを pip でインストールします。
pip install --upgrade google-cloud-vision
Python の環境設定で何か問題が起きたら、下記「Python 開発環境の設定」を参考に調整してみて下さい。
それでは、Raspberry Pi 上のローカルにある JPEG 画像を何か処理してみましょう。物体認識してみたい画像を用意して下さい。
プログラム2
import io
import sys
import cv2
import json
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image, ImageDraw
from google.cloud import vision
ALL_SIZE = 512
PATH = "recognize.jpg"
TMP = "tmp.jpg"
RESULT = "result.jpg"
client = vision.ImageAnnotatorClient()
print("read original: " + PATH)
# オリジナル画像の読み込み
img = cv2.imread(PATH)
h, w = img.shape[:2]
print("write resized: " + TMP)
# リサイズ画像の書き込み
image_size = ALL_SIZE
height = round(h * (image_size /w))
img2 = cv2.resize(img,dsize=(image_size,height))
cv2.imwrite(TMP,img2)
print("re-read resized: " + TMP)
# リサイズ画像の再読み込み
with open(TMP, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
print("object recognition")
# 物体認識実行
objects = client.label_detection(
image=image).label_annotations
print(objects)
img2 = img.copy()
print("font setting")
# フォントの設定
fig = plt.figure(figsize=(11.46, 6.45), dpi=96)
color = (200, 200, 0)
font_color = (0, 180, 180)
font = cv2.FONT_HERSHEY_SIMPLEX
h, w = img2.shape[0:2]
count = len(objects)
for obj in objects:
# フォント実サイズ取得
obname = obj.description + " " + str(round(obj.score,2))
(font_w,font_h),baseline = cv2.getTextSize(
text=obname,
fontFace=font,
fontScale=1,
thickness=1
)
# テキスト書き込み
cv2.putText(
img2,
obname,
(20, h - int((font_h + baseline) * 1.2) * count),
font,
1,
font_color,
thickness=3
)
count = count - 1
print("write result: " + RESULT)
# 結果書き込み
cv2.imwrite(RESULT,img2)
cv2.imshow("recognized object",img2)
cv2.waitKey(0)
cv2.destroyAllWindows()
些か、Google のサンプルよりは複雑ですが、Raspberry Pi で処理することを考えて、画像を縮小したり、画像に結果を書き込むために、フォントの処理を追加しています。しかし、横幅 512 dot の数百[kB] 画像であれば、転送に時間は掛かりません。 Raspberry Pi におけるポイントは「画像縮小」 です。冒頭の "ALL_SIZE" で縮小サイズを指定しています。また、読み込む元画像は、"PATH" に指定して下さい。"TMP" は縮小画像、"RESULT" は結果画像です。
 図7 元画像
図7 元画像
 図8 縮小画像 67[KB]
図8 縮小画像 67[KB]
 図9 結果画像
図9 結果画像
処理結果は元画像に書き込んでいますが、縮小画像に書き込むようにしてもいいかも知れません。
この鳥は何だか分かりますか? 鳥に興味がない人は、「鳥」としか答えないでしょう。物体認識の結果もそんな感じです。ホオジロですけど、 ー "Bird(鳥)","Branch(枝)","Twig(小枝)","Beak(くちばし)","Tree(木)","Songbird(鳴鳥)","Plant(植物)","Tail(尾)","Terrestrial plant(陸生植物)","Cedor Waxwing(ヒメレンジャク:スズメ目の小鳥)" ー まあいいのではないでしょうか。ヒメレンジャクと答えているのが興味深いですね。ホオジロも同じスズメ目の小鳥ですが、東アジアに分布してる鳥なので、US ではヒメレンジャクでいいのかも知れませんね、顔の模様も似ています。
Reference:
1).「深層学習」-岡谷貴之 講談社
2).「TensorFlow で学ぶディープラーニング入門」 -中井悦司 マイナビ出版
3)."Convolutional neural network" - Wikipedia
https://en.wikipedia.org/wiki/Convolutional_neural_network
4)."Kernel (image processing)" - Wikipedia
https://en.wikipedia.org/wiki/Kernel_(image_processing)