機械学習超初心者が物体検出のとコンペに参加し、YOLOv5のモデルの実装に挑戦しました。
備忘録として、その方法を何回かに分けて記述しようと思います。
与えられたデータからアノテーションデータ作成
① データの確認
与えられたアノテーションデータは下記のようなデータだったため、
加工してYOLOでも使える様式にする必要がありました。
image_filename: 画像ファイル名
X_min_Ymin_Xmax_Ymax: 対象物の位置を示す物体検出用アノテーションデータ
class: 対象物の名前
| image_filename | X_min_Ymin_Xmax_Ymax | class |
|---|---|---|
| 1234abc.jpg | [700,1000,2000,2500] | A |
| 2345bcd.jpg | [1500,900,2100,1500] | B |
| 3456cde.jpg | [800,1500,1300,2100] | C |
| 2345bcd.jpg | [1000,2000,2100,2800] | D |
| 2345bcd.jpg | [600,1800,1200,2010] | E |
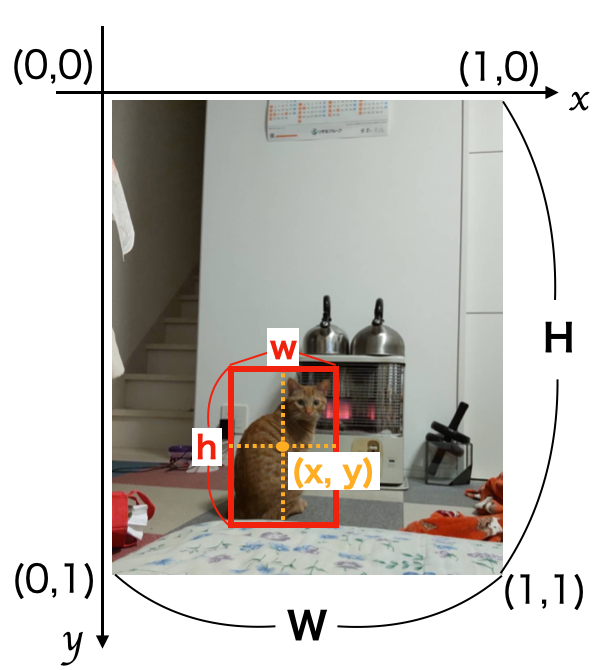
YOLOので必要とされるノテーションデータは下記の通りです。
x = 対象物を囲った四角の中心のx座標
y = 対象物を囲った四角の中心のy座標
w = 対象物を囲った四角の横幅
h = 対象物を囲った四角の縦幅
W = 画像全体の横幅
H = 画像全体の縦幅
| ラベル番号 | 対象物の中心x座標(Wで標準化) | 対象物の中心y座標(Hで標準化) | 対象物を囲った四角の幅(Wで標準化) | 対象物を囲った四角の高さ(Hで標準化) |
|---|---|---|---|---|
| class_number | x/W | y/H | w/W | h/H |
|
② データの加工
qiita.rb
# アノテーションデータの読み込み
import pandas as pd
train_label = pd.read_csv('/content/drive/MyDrive/file_path/data.csv')
train_label
まずラベル番号を作る
qiita.rb
# classの種類と数の確認
from collections import Counter
Counter(train_label['class'])
# classの種類を文字列から数値に置換(ラベル番号は0から振らないと学習時にエラーが出ます)
train_label['class_No'] = train_label['class'].map({
'A':0,
'B':1,
'C':2,
'D':3,
'E':4})
アノテーションデータを作るためにX_min_Ymin_Xmax_Ymaxを分割する
qiita.rb
# カンマ区切りで分割
tmp = train_label['Xmin_Ymin_Xmax_Ymax'].str.split(',', expand=True)
tmp
print(type(train_label))
# 列を追加
train_label['Xmin'] = tmp[0]
train_label['Ymin'] = tmp[1]
train_label['Xmax'] = tmp[2]
train_label['Ymax'] = tmp[3]
# Xminのデータには'['がついているので削除
train_label['Xmin'] = train_label['Xmin'].str.replace('[', '')
# Ymaxのデータには']'がついているので削除
train_label['Ymax'] = train_label['Ymax'].str.replace(']', '')
W(画像全体の横幅)とH(画像全体の縦幅)のデータが無いため画像データより取得
qiita.rb
import cv2
import glob
# ファイルをフォルダから呼び出すためのファイルリストを作成
filename = train_label['filename']
hight =[] #呼び出したHを格納する
width =[] #呼び出したWを格納する
# for文で画像を一つ一つ呼び出し、HとWの情報を読み込む
for i in range(len(filename)):
img = cv2.imread('/content/drive/MyDrive/file_path/' + filename[i])
W, H = img.shape[:2]
hight.append(H)
width.append(W)
print(f"{i}: W:{W}, H: {H}")
# train_labelの表にHとWのデータを追加
train_label['H'] = hight
train_label['W'] = width
分割したX_min_Ymin_Xmax_Ymaxデータが文字列のままだったので数値データに変換
qiita.rb
train_label['class_No'] = train_label['class_No'].astype(int)
train_label['Xmin'] = train_label['Xmin'].astype(int)
train_label['Ymin'] = train_label['Ymin'].astype(int)
train_label['Xmax'] = train_label['Xmax'].astype(int)
train_label['Ymax'] = train_label['Ymax'].astype(int)
x = 対象物を囲った四角の中心のx座標、y = 対象物を囲った四角の中心のy座標
w = 対象物を囲った四角の横幅、h = 対象物を囲った四角の縦幅
を計算する
qiita.rb
# アノテーションデータには画像のラベル番号、x:領域の中心x座標、y:領域の中心y座標、w:領域の幅、h:領域の高さが必要なので作成
train_label['x_width'] = train_label['Xmax'] - train_label['Xmin']
train_label['y_hight'] = train_label['Ymax'] - train_label['Ymin']
train_label['x_center'] = train_label['Xmin'] + train_label['x_width']/2
train_label['y_center'] = train_label['Ymin'] + train_label['y_hight']/2
先ほど算出したデータをHまたはWで標準化したx,y,h,wを計算
qiita.rb
train_label['w'] = train_label['x_width']/train_label['W']
train_label['h'] = train_label['y_hight']/train_label['H']
train_label['x'] = train_label['x_center']/train_label['W']
train_label['y'] = train_label['y_center']/train_label['H']
train_labelの表から必要なアノテーションデータだけを抽出した新たな表を作る
qiita.rb
import pandas as pd
annotation_data = pd.DataFrame()
annotation_data['label'] = train_label['class_No']
annotation_data['x'] = train_label['x']
annotation_data['y'] = train_label['y']
annotation_data['w'] = train_label['w']
annotation_data['h'] = train_label['h']
これでアノテーションデータの作成は完了です。