自分が最近構築していたTwitter 英単語 bot の備忘録でも書いていこうと思います。
英単語 bot を構築しようと思ったきっかけは「英検一級の単語全く頭に入ってこねぇ~」ってことです。今年の10月に英検一級を受けようと考えているのですが、本当に単語が難しいです。TOEICなんか比べ物にならないくらい単語が難しいです。覚えたと思っても、3秒後には忘れています。
そこで「見てもすぐに忘れてしまうなら、忘れるたびに見るしかない」という脳筋な考えに至りました。具体的には、自分が1時間に1回程度は見ているTwitterで英単語を復習する機能をつけられたらいいなぁと考えました。
こんな経緯で英単語 bot を作ろうという結論に至った訳でございます。
今現在、私のアカウントは以下のような機能を持っているアカウントとなっています。(フォロワーの皆様、私のアカウントは1割が bot っぽくなっているだけで残りの9割はきちんと私自身で活用しています。bot だからと突き放さずに今後とも仲良くしていただけると幸いです。)
- あるワードを含むツイート+タイムラインのツイートにいいねする
- あるワードを含むツイートをリツイートする(停止中)
- あるワードを bio に含むアカウントをフォローする
- Excelファイルの英単語を定期的にツイートする
- 自分のみがフォローしている人のフォローを解除する
これにより以下のようなツイートを自動で行っています。
Twiiterを開くと嫌でも目に入り、手軽に復習できるので非常に役に立っています。
interrogation : 尋問、取り調べ
— わかか@英検一級 (@kawaggler) July 25, 2022
[ɪntèrəgéɪʃən]
Police interrogation are now always recorded as to ensure that only legal methods are used.#wakaka_eng#英検1級#TOEIC pic.twitter.com/ODq2LVWKOQ
Twiiter bot を構築する工程は以下のようになっています。
- Python の環境構築
- Twitter API を利用するための Consumer Keys と Authentication Tokens を取得
- tweepy パッケージをダウンロード
- Python で英単語 bot に必要な機能を綴っていく
- Task Scheduler で定期実行できるようにする
では順を追ってみていきましょう。
1. Python の環境構築
Twiiter 英単語 bot を構築したと言いましたが、基本的には他の方の記事をパクって参考にして進めていきました。なのでメインの部分である英単語 bot を構築したコード以外は省略していこうと思います。
まず、Python の環境構築に関してですが、私は Anaconda を利用しました。Anaconda はPython 自身と Python でよく利用される NumPy や Jupyter といったライブラリをまとめてインストールしてくれるパッケージです。端的に言えば、これをインストールするだけで基本的には Python を利用することが出来ます。自分は以下の記事を参考にしてインストールしましたが、検索すれば多くの文献に出会えると思います。
2. Twitter API を利用するための Consumer Keys と Authentication Tokens を取得
ここが結構面倒かもしれません。Twitter API を活用することで操作の自動化などの作業ができるようになるのですが、Twitter API を利用するためにはTwitter に許可をもらい、上に示した鍵を入手する必要があります。許可をもらうためには、Twiiter社に向けて「自分はこんな素晴らしいことをしたいから許可をくれ!」と英文をつらつらと書いていきます。英語に普段から触れていない人にとっては非常に面倒な作業だと思いますが、これに関しても既に様々な記事が存在するので、それらを参考にすればそこまで難しくはないと思います。
3. tweepy パッケージをダウンロード
tweepy とはTwitter API をPython を用いて簡単に扱うことができるようになるパッケージの事です。コマンドライン(Anaconda を利用してPython の環境構築をした方であればAnaconda Prompt を利用すると楽です)で以下のコマンドを入力することでtweepy をダウンロードできます。
pip install tweepy
あとは以下のようにPython のコードを書くことで準備は完了します。
API 情報を記入という部分には先ほど入手したConsumer Keys と Authentication Tokensを記入します。
#ライブラリをインポート
import tweepy
# API情報を記入
BEARER_TOKEN = "******"
API_KEY = "******"
API_SECRET = "******"
ACCESS_TOKEN = "******"
ACCESS_TOKEN_SECRET = "******"
# Twitterの認証
auth = tweepy.OAuth1UserHandler(API_KEY, API_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
# APIインスタンスの生成
api = tweepy.API(auth)
4. Python で英単語 bot に必要な機能を綴っていく
ここまでくれば、あとはひたすらに自分が構築したい機能をPython で書いていくだけです。冒頭に書かせていただきましたが、自分は以下の機能を構築しました。
- あるワードを含むツイート+タイムラインのツイートにいいねする
- あるワードを含むツイートをリツイートする
- あるワードを bio に含むアカウントをフォローする
- Excelファイルの英単語を定期的にツイートする
- 自分のみがフォローしている人のフォローを解除する
上から順に、コードと共にどのような仕様になっているかを記していきます。
あるワードを含むツイート+タイムラインのツイートにいいねする
まずはコードをお見せしたいと思います。
#-------------------------------------------------------------------
# 指定した条件(検索ワード、検索件数)に一致するツイート情報を取得
search_results_favo = api.search_tweets(q="TOEIC", lang = "ja", result_type="mixed",count=30)
timeline_results_favo = api.home_timeline(count=30)
#-------------------------------------------------------------------
# ランダムで選んだツイートにfavoする(n = 30)。普通のツイート・リツイートはfavoする。返信はfavoしない。
def Favorite_Tweet(text):
#意味のないツイートはfavoしない。
if (("副業" in text) or ("24卒" in text) or ("質問箱" in text) or ("セール" in text) or ("売れ筋" in text)):
print("This is a fucking tweet!")
#普通のツイートをfavoする。
elif "@" not in text:
try:
api.create_favorite(result.id)
print("Favo Succeeded")
except Exception as e:
print(e)
#リツイートをfavoする。
elif "RT @" in text:
try:
api.create_favorite(result.id)
print("Favo Succeeded")
except Exception as e:
print(e)
#返信はfavoしない。
else:
print("Exclude because that was a reply")
for result in search_results_favo:
Favorite_Tweet(result.text)
print("\n\n")
for result in timeline_results_favo:
Favorite_Tweet(result.text)
#-------------------------------------------------------------------
各セクションごとに大体のやっていることは記載してはいますが、簡単にどのような仕様かを説明したいと思います。現在は TOEIC というワードを含むツイートを30件取得してきています。初めはそれらを見境なくいいねしていたのですが、クソみたいなプロフ誘導のツイートだったり、質問箱だったりすることが多かったのでそれらを除外しています。また、会話に参加しておらず、元のツイートをいいねしていないのにも関わらず返信をいいねすると「なんだこいつ?」と思われかねないと感じたので、現在は普通のツイートとリツイートのみをいいねするようにしています。タイムラインのツイートに関しても同様です。
あるワードを含むツイートをリツイートする(停止中)
次は自動でリツイートする機能についてです。
#-------------------------------------------------------------------
# 指定した条件(検索ワード、検索件数)に一致するツイート情報を取得
search_results_retweet = api.search_tweets(q="英語学習", lang = "ja", result_type="mixed",count=7)
#-------------------------------------------------------------------
#ランダムで選んだツイートをRTする(n = 3)。リツイートのみをRTする。普通のツイート・返信はRTしない。
def Retweet_Tweet(text):
#意味のないツイートはRTしない。
if (("副業" in text) or ("24卒" in text) or ("匿名質問" in text) or ("セール" in text)):
print("This is a fucking tweet!")
#リツイートされたものをRTする。
elif 'RT @' in text:
try:
api.retweet(result.id)
print("Retweet Succeeded")
except Exception as e:
print(e)
#普通のツイート・返信はRTしない
else:
print("Exclude because that was not a retweet")
for result in search_results_retweet:
Retweet_Tweet(result.text)
#-------------------------------------------------------------------
基本的な仕様は先ほどのいいねの場合と違いはありません。匿名箱などはまず除外してしまいます。そのうえでリツイートするツイートを決めるのですが、ここが難しくて、何も決めないと、他の方のちょっとした進捗ツイートとかをリツイートすることになってしまい、またしても「なんだこいつ?」と思われてしまいます。そこで私はリツイートされたものだけをリツイートするような仕様にしました。こうすることで変な奴と思われることは避けられると思います。ですが、いまいち使い勝手がよくないので現在は停止中です。機械学習などを用いてもっと柔軟にリツイートするような仕様にできたらなぁと思ってはいます。
あるワードを bio に含むアカウントをフォローする
次は自動フォローの機能です。
#-------------------------------------------------------------------
# 毎日以下のワードを含むアカウントを順番にフォローしていく。
Follow_dayly = ["TOEIC", "英語初心者", "英検", "IELTS", "英語学習","英会話"]
# ソースコードに依存せずに、日にちによって変化する変数を定義
#1月1日から数えて何日目かを計算し、modを使って上のlistを回す
Today = datetime.date.today().today()
New_year_day = datetime.date(2022,1,1)
Day_count = (Today-New_year_day).days
# 指定した条件(検索ワード、検索件数)に一致するアカウント情報を取得
Today_word_number = np.mod(Day_count, len(Follow_dayly))
search_results_follow = api.search_users(q = Follow_dayly[Today_word_number], count = 10)
#-------------------------------------------------------------------
#指定したワードを bio に含む人をフォローする。
def Follow_users(bio):
if (("副業" in bio) or ("24卒" in bio)):
print("Fuck off!")
elif not result._json["following"]:
api.create_friendship(user_id = result._json["id"])
print("You've followed " + result._json["name"])
else:
print("We are already friends!")
for result in search_results_follow:
user_name = result._json["name"]
user_bio = result._json["description"]
user_name_bio = user_name + user_bio
Follow_users(user_name_bio)
#-------------------------------------------------------------------
ここでは1行目にあるワードを bio に含むアカウントを日ごとにフォローしています(今日は TOEIC を bio に含む人を 10人フォローする、明日は英語初心者を含む人をフォローという感じ)。毎日ワードを固定してしまうと同じアカウントをフォローしてしまい、上手く機能しなかったのでこのような仕様にしました。今日が一年のうち何日目かを計算して、modを用いてリストを回しましたが、おそらくもっとスマートな書き方があると思います。あとは例のごとく、自分に関係のなさそうな就活アカウントなどを除外してフォローしていくという仕様にしています。
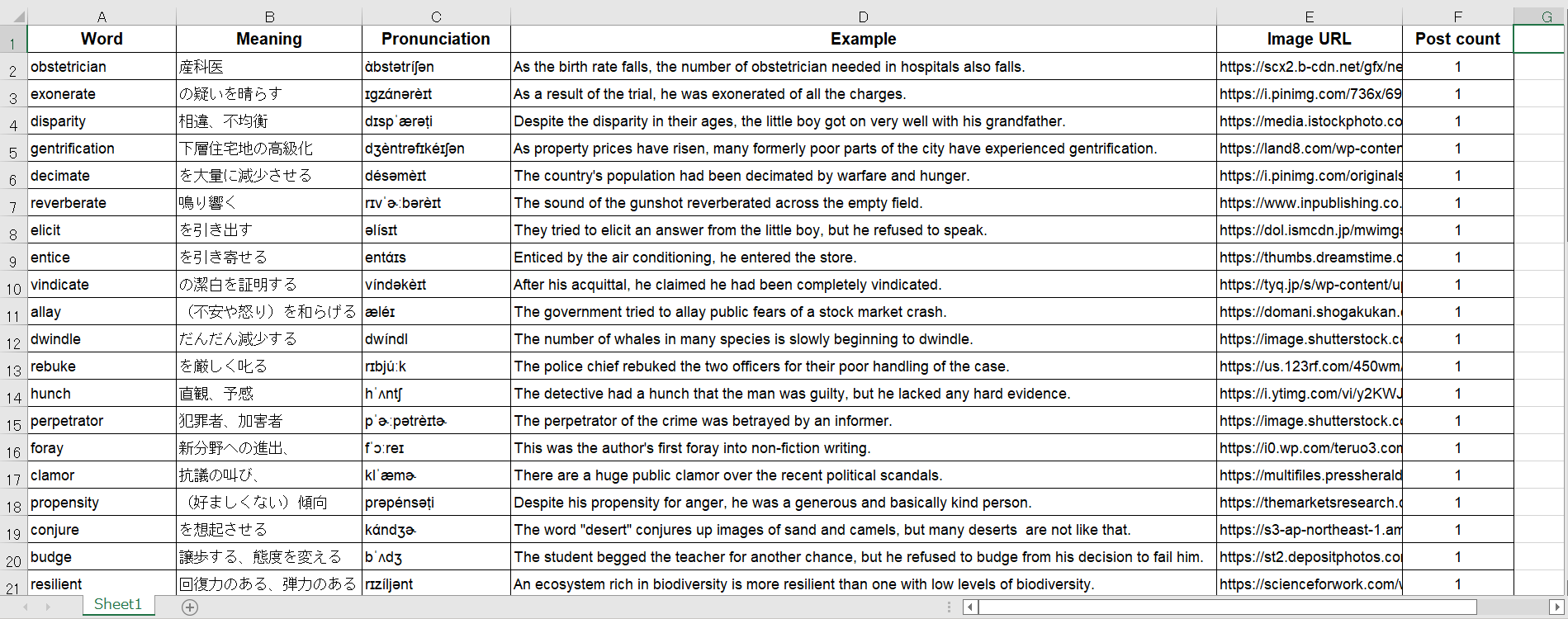
Excelファイルの英単語を定期的にツイートする
万を持して英単語 bot の説明です。英単語ファイルの上から順番にツイートしていく方法は以下の記事の方法を参考にさせていただきました。非常に参考になりました。
#-------------------------------------------------------------------
# 英単語ファイルを Dataframeに変換
df = pd.read_excel("Eng_words.xlsx")
#-------------------------------------------------------------------
# 投稿された回数の少ない単語の中で一番上にある単語を投稿する
row_posted = 0 #行番号。Post Count が全て0の場合に備えて初期値は0としておく
count_standard = df["Post count"][0] #この値と各行のPost Countを比較していく。初期値は0行目
for i in range(len(df)):
# standard よりも小さいものが現れたら standard を移していく
# 最終的に一番小さいものの中で一番上にある単語が Post される (row_posted)
if df["Post count"][i] < count_standard:
count_standard = df["Post count"][i]
row_posted = i
#-------------------------------------------------------------------
# ツイートを構築する
The_text = df.iloc[row_posted]["Word"] + " : " + df.iloc[row_posted]["Meaning"]\
+ "\n[" + df.iloc[row_posted]["Pronunciation"] + "]\n\n"\
+ df.iloc[row_posted]["Example"] + "\n\n#wakaka_eng\n#英検1級\n#TOEIC"
#-------------------------------------------------------------------
# 画像ファイルをサーバーから添付する
img = requests.get(df.iloc[row_posted]["Image URL"]).content
result_img = api.media_upload(filename='img.png', file=BytesIO(img))
#-------------------------------------------------------------------
# ツイートを投稿する
tweet = api.update_status(status = The_text, media_ids=[result_img.media_id])
#-------------------------------------------------------------------
# DataframeのPost countを更新する
add_list = []
for i in range(len(df)):
if i != row_posted:
add_list.append(0)
else:
add_list.append(1)
df["Post count"] += pd.Series(add_list)
#-------------------------------------------------------------------
#StyleFrameを用いてExcelファイルを整えてから出力する
style = Styler(horizontal_alignment=utils.horizontal_alignments.left, font_size = 11,\
wrap_text = False, shrink_to_fit=False)
style_for_Postcount = Styler(font_size = 11, wrap_text = False, shrink_to_fit=False)
with StyleFrame.ExcelWriter('Eng_words.xlsx') as writer:
sf = StyleFrame(df)
sf.apply_column_style(cols_to_style=["Word","Pronunciation","Meaning", "Example", "Image URL"], styler_obj=style)
sf.apply_column_style(cols_to_style="Post count", styler_obj=style_for_Postcount)
sf.set_column_width(columns = ["Word","Pronunciation"], width=20)
sf.set_column_width(columns = ["Meaning","Image URL"], width=25)
sf.set_column_width(columns = "Example", width=95)
sf.set_column_width(columns = "Post count", width=15)
sf.set_row_height(rows=list(range(1,len(df)+2)), height=20) #sf では1番上の行は0行目ではなく1行目なので注意
sf.to_excel(writer, index=False)
#-------------------------------------------------------------------
コードを実行するたびに以下にあるEng_words.xlsx というエクセルファイルの単語群の中からツイートされた回数(Post count) が少ないものを抽出してツイートをするという形になっています。こうすることで満遍なく単語を抽出することができます。エクセルファイルは自身の手で作製しているので少し面倒にはなりますが、今後テキストくらいは自動でエクセルファイルに書き込めるようにしようと思います。その単語に適した画像選ぶのが一番時間かかってるから良い感じのを自動で見繕ってくれるといいんだけどなぁ...。これは結構難しそうですが、誰かいい案があれば教えてください(現在、明らかにボトルネックになっています)。本当にお願いします。
自分のみがフォローしている人のフォローを解除する
これは最近実装した機能です。自動化している訳ではなく、1か月に一回くらいおこなっています。ほとんど下に添付した記事と同じ内容ですが、注意が出る関数などがあったので少し改良しました。
#-------------------------------------------------------------------
cols = ['user_id']
follower_id_df = pd.DataFrame([], columns=cols)
following_id_df = pd.DataFrame([], columns=cols)
# フォロワーの取得
follower_ids = tweepy.Cursor(api.get_follower_ids, cursor=-1).items()
for follower_id in follower_ids:
record = pd.Series([follower_id], index=follower_id_df.columns)
follower_id_df.loc[len(follower_id_df)] = record
print(follower_id_df)
# フォローしている人の取得
following_ids = tweepy.Cursor(api.get_friend_ids, cursor=-1).items()
for following_id in following_ids:
record = pd.Series([following_id], index=following_id_df.columns)
following_id_df.loc[len(following_id_df)] = record
print(following_id_df)
#-------------------------------------------------------------------
# 一方的にフォローしている人を抽出
# この名前を"name"にするのではなく、"user_name"にすることが意外と重要。
# このDataFrameからSeriesを生成すると、Series.nameを抽出した際にはindexの"name"ではなく、Series自体のNameが優先される。
unidirectional_follow_df = pd.DataFrame([], columns=['user_id', 'user_name', 'screen_name', 'description'])
for following_id in following_id_df['user_id']:
if following_id not in follower_id_df['user_id'].values:
user = api.get_user(user_id = following_id)
record = pd.Series([user.id, user.name, user.screen_name, user.description], index=unidirectional_follow_df.columns)
unidirectional_follow_df.loc[len(unidirectional_follow_df)] = record
print(unidirectional_follow_df)
# 一方的にフォローしている人をリムーブする
removed_users_df = pd.DataFrame([], columns=['user_id', 'user_name'])
for i, user in unidirectional_follow_df.iterrows():
# userはDataFrameの列から生成されるSeriesである。
api.destroy_friendship(user_id=user.user_id)
# "user_name"にしたことによって、ここで確実にuserというSeriesのindexである"user_name"を抽出することができる。
record = pd.Series([user.user_id, user.user_name], index = removed_users_df.columns)
removed_users_df.loc[len(removed_users_df)] = record
print(removed_users_df)
#-------------------------------------------------------------------
先ほどの記事において使われていたPandas.DataFrameのappendメソッドが将来的に廃止される方向性であるという表示がされていたので、Pandas.Dataframeのlocを使用しました。ここでは行番号を指定して新しい行を生成しているので、ilocを用いるのかなと思ったのですが、ilocだと"iloc cannot enlarge its target object"というエラーが出てしまい、実行できませんでした。普通に列を取得する際にDataFrame.loc[0]のようにするとエラーが出るのに対して、新しく列を生成する際にDataFrame.loc[5]のようにすると実行できるらしいです。自分にはなぜか分かりません。誰か分かる方がいたら教えてください。
ソースコードの中でもコメントしたのですが、Seriesのindexに"name"を使用して、Series.name のようにアクセスしようとしても、Series自体につけられている名前が返されてしまい、indexにアクセスできません。そのため、今回はunidirectional_follow_df では"user_name"を採用しています。
5. Task Scheduler で定期実行できるようにする
以上に示したコードを自動化する際に、私はWindowsのタスクスケジューラを用いました。サーバーを借りてそこで動かすという選択肢もあったのですが、タスクスケジューラで試してみて特に不自由なかったのでそのままにしています。
基本的には以下の記事を参考にさせていただきました。初めはPythonスクリプトを指定してタスクスケジューラに読み込ませていたのですが、上手く動いてくれませんでした。そこで、以下の記事のようにバッチファイルを作成して、実行しました。
具体的には、以下のようなバッチファイルを作成しました。
call C:\Users\***\Anaconda3\Scripts\activate.bat
python C:\Users\***\Desktop\Python\1.Favo.py
python C:\Users\***\Desktop\Python\3.Follow.py
python C:\Users\***\Desktop\Python\4.Eng_words_tweet.py
最後に、PCがスリープの状態でもタスクスケジューラが起動してくれるように設定しました。この際にも上手く動いてくれずにつまずいたことがあったのですが、以下の記事で解決法を提示してくれていました。
6. まとめ
そんなこんなで無事、英単語 bot を構築することができました。やはりいい感じの英単語の画像を調べることが一番時間がかかり、面倒な作業なのでここをも自動でやってくれるようなシステムも作りたいなぁとは思っています。相当難しそうですが。
加えて、プログラムでツイートをいいねする際には、自分がいいねしたくないようなツイートをいいねしてしまうことがどうしても起こってしまいます。ここを機械学習を用いて本当に自分がツイートしたいツイートのみをいいねするというシステムを開発することが自分の中では次のステップかなと思っています。これに関しては、今後日記のような形で開発の経過を投稿していくと思うので、アドバイスなどいただけると本当にありがたいです。
ではこの記事は終わらせていただきます。
質問やアドバイスなどあればどんどんコメントしていただけると幸いです。
ここまで読んでいただきありがとうございました。