1.はじめに
どうも、ARIの名古屋支社に勤務している愛知県民こと、
新藏(にいくら)と申します♪
(/・ω・)/
2022年頃話題になった画像生成AIについて、当時以下の記事で使い方を紹介しました。
簡単な文章を入力するだけで思い通りの画像を作成できる、大変便利なツールです。
あれから2年、最近は画像生成AIを使ってない・・・と思いました。
そこで今回はStable Diffusionに関する技術について記事にします!
画像生成AIに興味のある方や、使ったことがある人の参考になれば幸いです。
(*^^)v
2.画像生成AIとは
まず初めに、画像生成AIとは何かについてですが、
画像生成AIとは、入力したテキストをもとに画像を作成するAIとなります。
参考:https://www.hitachi-solutions-create.co.jp/column/technology/image-generation-ai.html
2年前、記事にしたStable Diffusionは英Stability AI社による画像生成AIで、
ソースコードと様々なモデルが公開されています。
上記を基に改造が可能なので、独自の画像生成AIを作成することも可能です!
■ソースコード
■モデル
3. Stable Diffusionで使われる技術
さて、ここからが本題ですがStable Diffusionで使われる技術を3つ説明します。
3.1.Diffusionモデル
Diffusionモデルとは、拡散過程(ノイズを加える過程)と逆拡散過程(ノイズを除去する過程)
を繰り返して、画像を生成するモデルのことです。
拡散過程により、ノイズが画像に与える影響を学習し、
逆拡散過程により、ノイズ除去の方法を学習することができます。
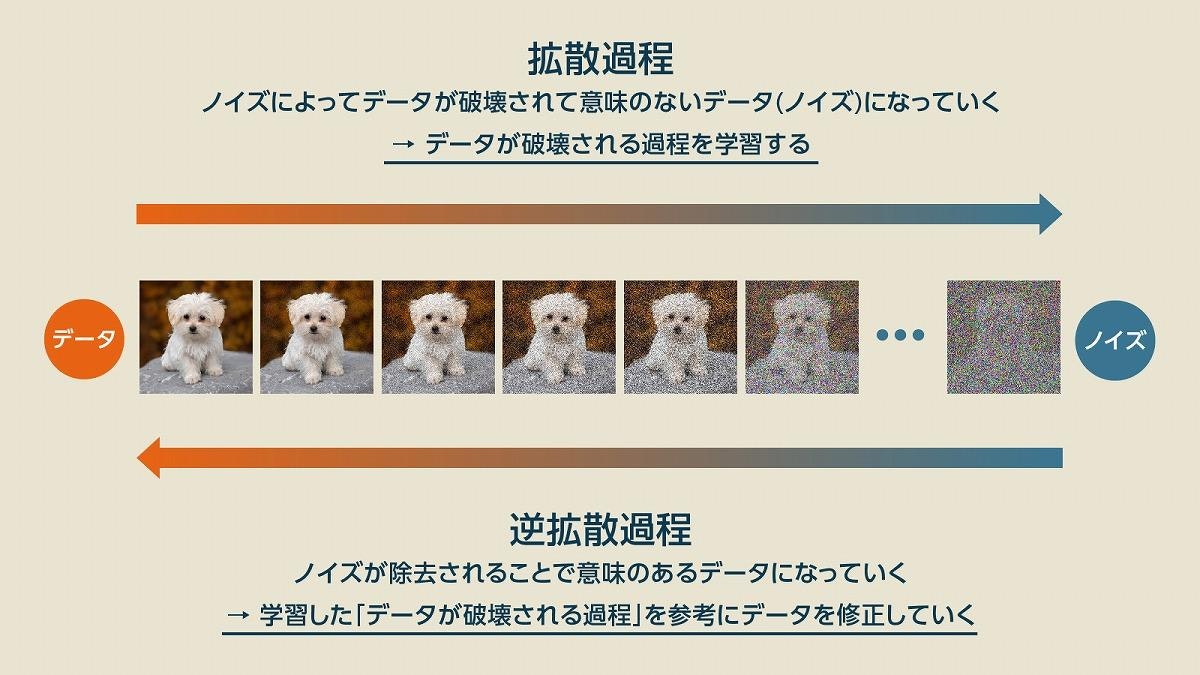 |
|---|
| 出典:https://www.sbbit.jp/article/cont1/128789 |
ちなみに、Diffusionモデルを直訳すると「拡散モデル」となります。
3.2.CLIP
CLIPとはContrastive Language-Image Pre-Trainingの略で、
テキストと画像のペアを学習し、テキストと画像の関連性を評価するモデルとなります。
2021年にOpenAI社が発表しました。
Stable Diffusionでは主に逆拡散過程で使用されていて、
ノイズを除去した画像が、作成したい画像(テキスト入力)とどのくらい一致しているかを評価します。
より詳細には、テキストと画像からベクトルを作成し、成分を比較することで、
テキストと画像の内容が近いかどうかを評価します。
ちなみに、Contrastive Language-Image Pre-Trainingを直訳すると
「対照的な言語イメージの事前トレーニング」となります。
3.3.VAE
VAEとはVariational Auto-Encoderの略で、
対象の画像を圧縮した潜在空間で処理を行ってから
普通の画像に復元することで、処理を軽くできる技術となります。
VAEがないと画像を生成する際にGPUが大量に必要になり、
画像生成に時間がかかります。
ちなみに、Variational Auto-Encoderを直訳すると
「変分オートエンコーダ」となります。
4.おわりに
ここまで読んで下さり、ありがとうございます!!!
(^^)
今回はStable Diffusionで使用されている技術について調べてみました。
CLIPが絵の全体を評価しながら生成しているため、
Stable Diffusionは細部を正確に描写することが苦手なようです。
(生成された画像で、人の髪の流れ・指の本数に異常がある画像を見たことがあります。)
逆に、細部が目立たない風景画やシンプルな画像は得意なので、
これを理解して、今後は画像生成AIを使っていきたいと思います!
この記事を書く際に
「先読み!ITxビジネス講座 画像生成AI 深津貴之著」も読んだので、
気になる方は是非、読んでみてください♪
(:3_ヽ)_