作ったもの
Terminal
% python3 tkinter_ner_sub_pred_pair_file_dialog.py
1. 以下のウインドウが立ち上がります。
ファイル選択ダイアログが現れます。
"OK"を押して、任意のディレクトリから任意のテキストファイルを選択します。

ファイル選択ダイアログの表示が、以下に変わります。

以下の画面が表示されます。
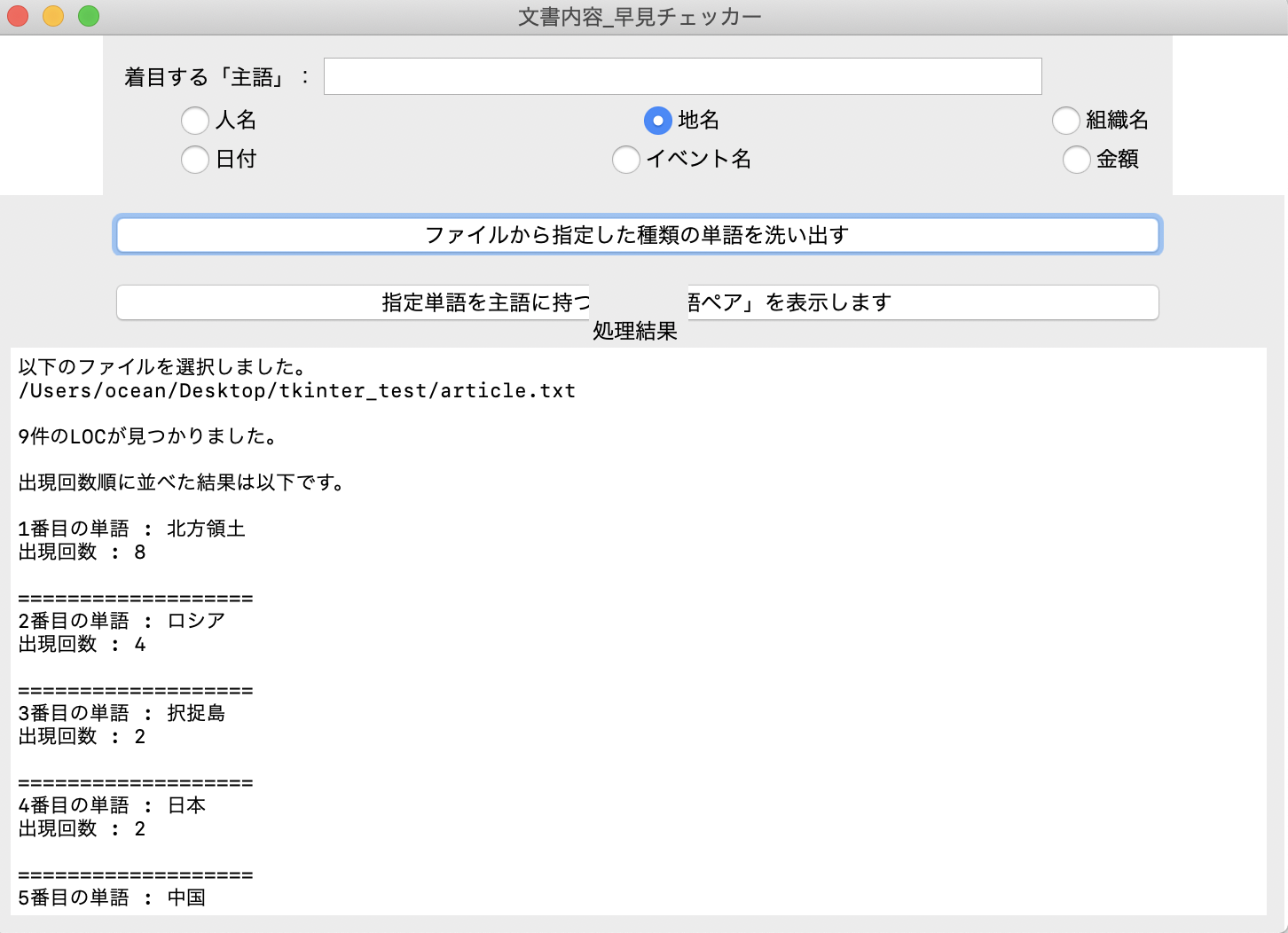
「地名」のラジオボタンを選択し、「ファイルから指定した・・・」ボタンを押す。
( 出力画面を下方向にスクロールすると、画面切れしていた解析結果の続きを確認できる )

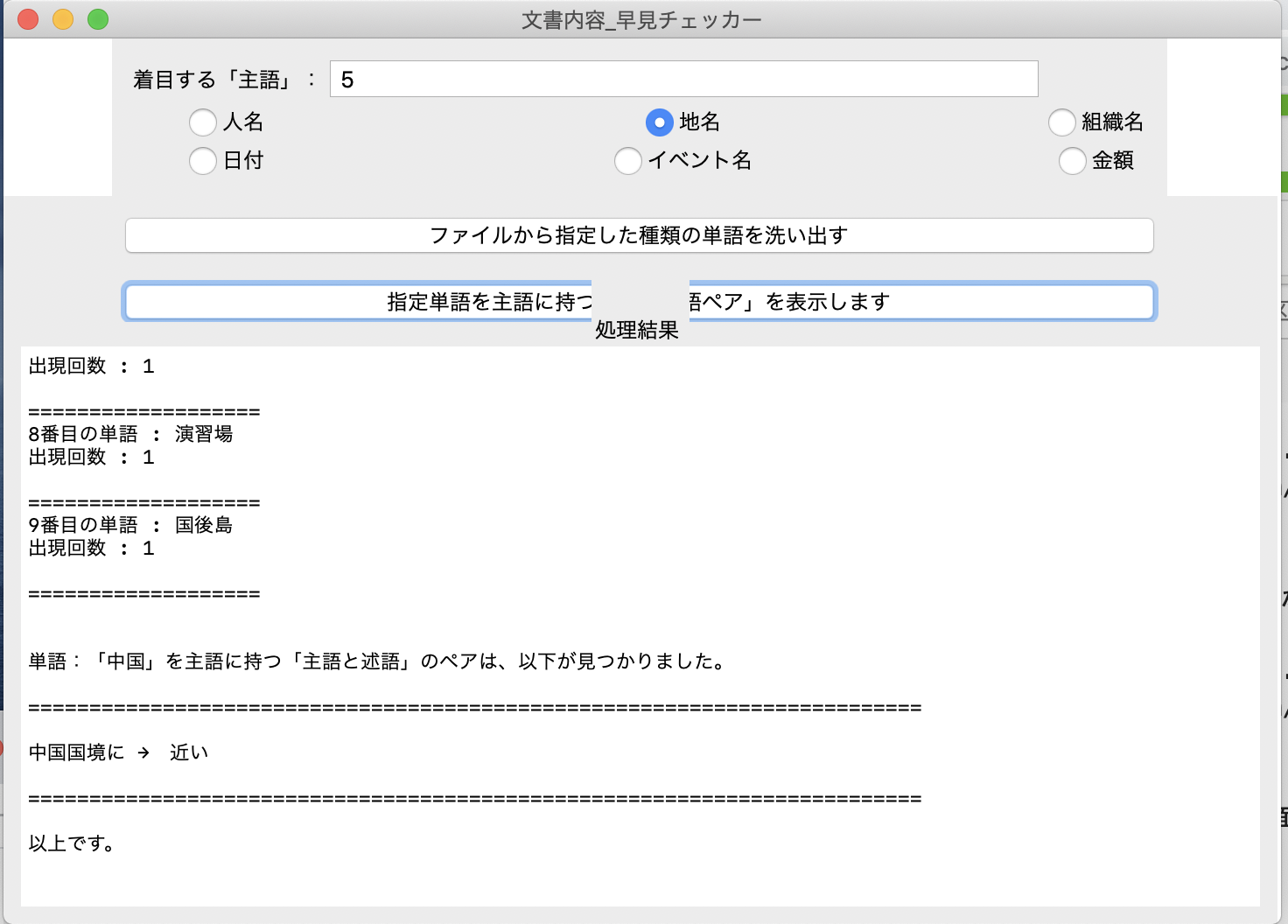
『着目する「主語」』欄に「5」(「中国」)を入力後、「指定単語を主語に持つ・・・」ボタンを押す。
( 出力画面を下方向にスクロールすると、画面の外に表示されている解析結果を確認できる )
『着目する「主語」』欄に「2」(「ロシア」)を入力後、「指定単語を主語に持つ・・・」ボタンを押す。
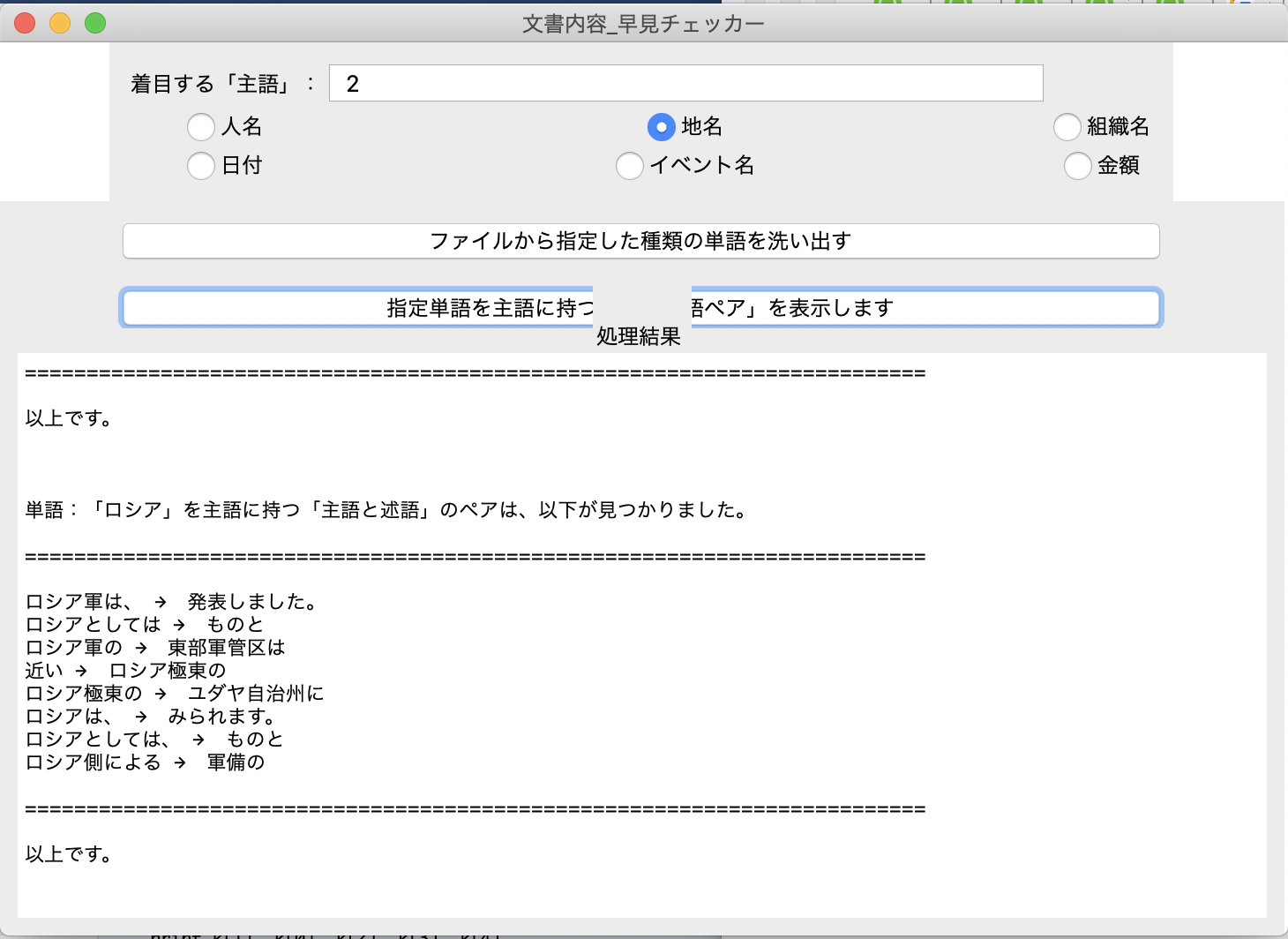
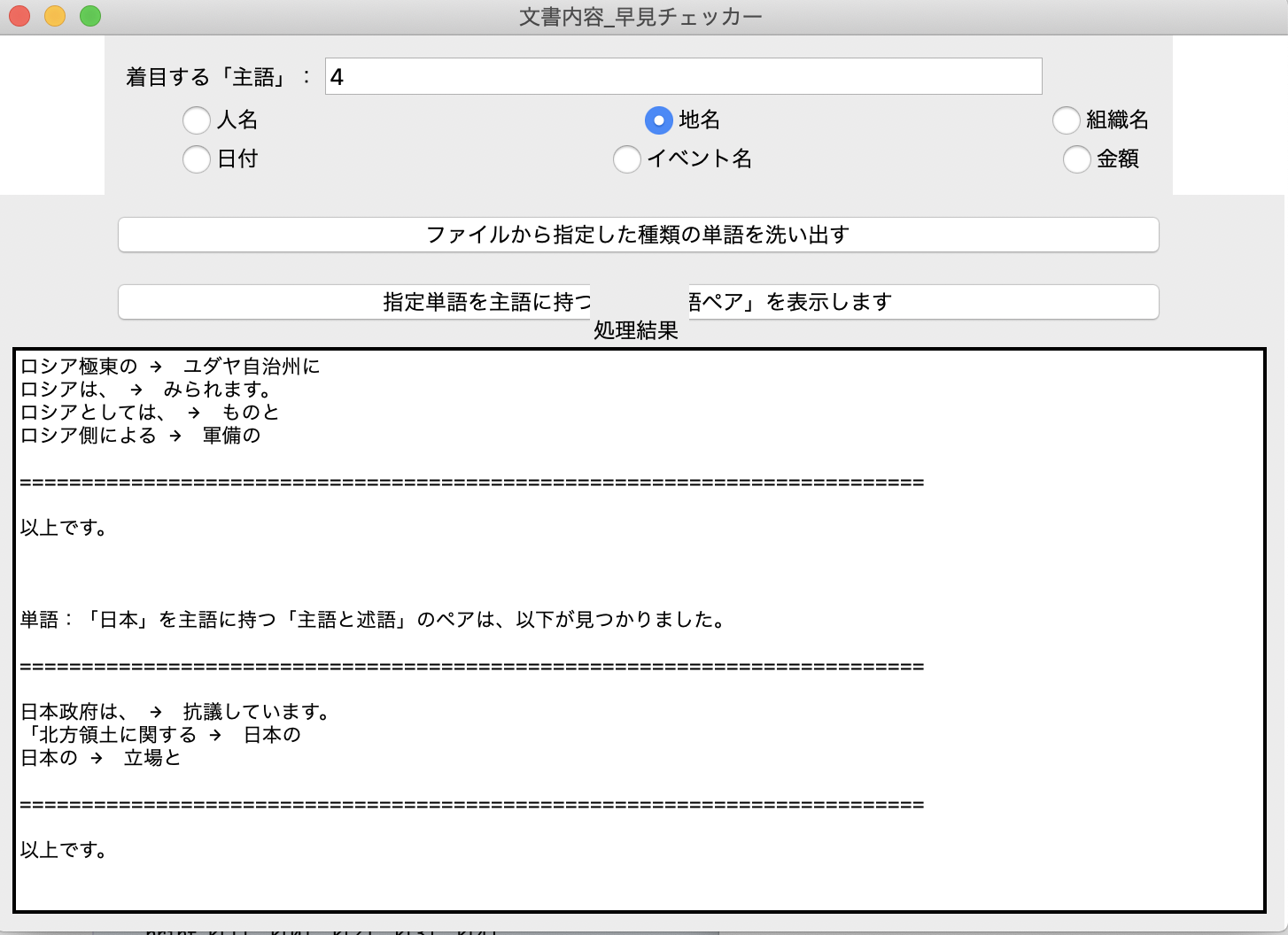
『着目する「主語」』欄に「4」(「日本」)を入力後、「指定単語を主語に持つ・・・」ボタンを押す。
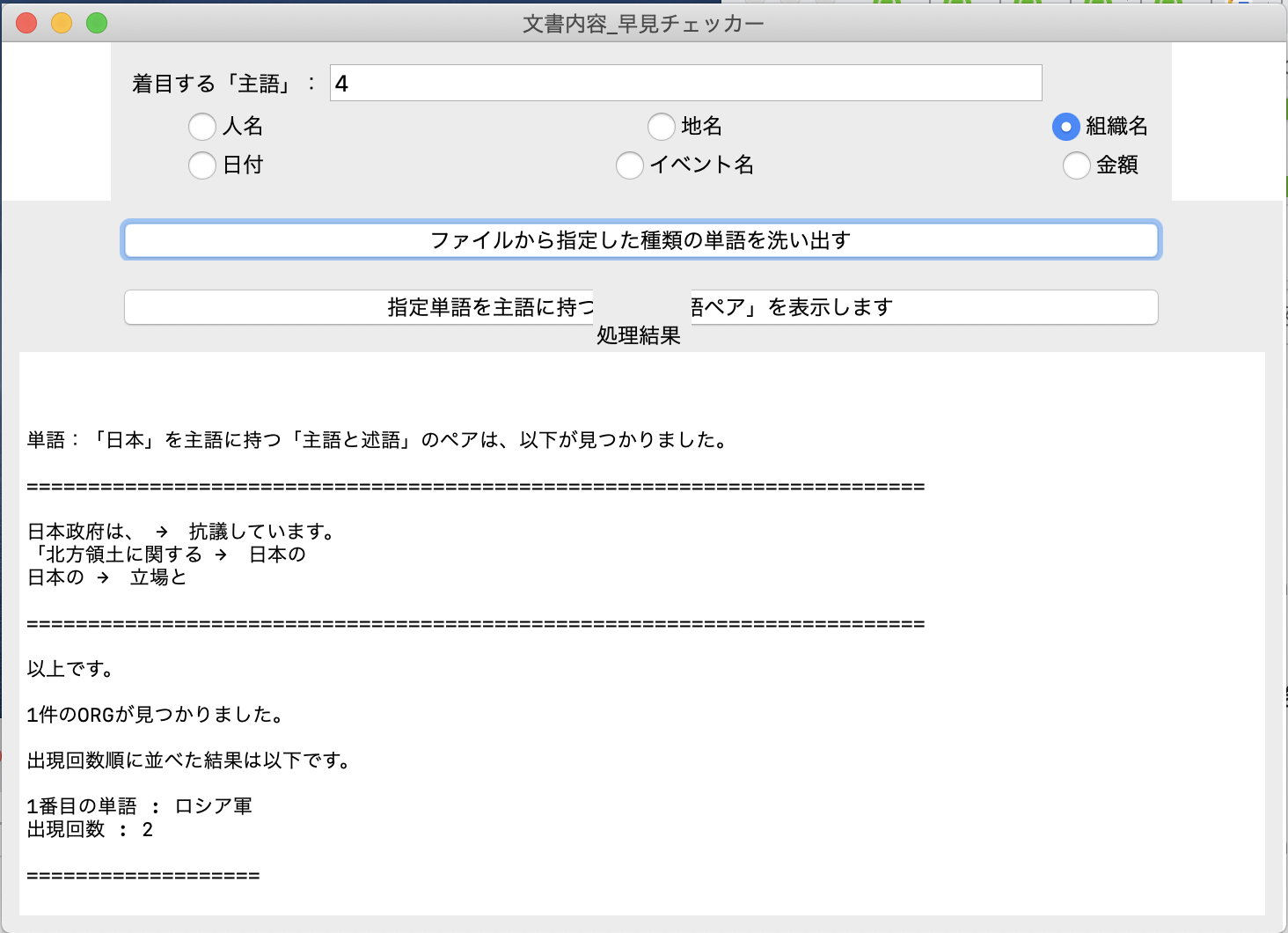
「組織名」のラジオボタンを選択し、「ファイルから指定した・・・」ボタンを押す。
『着目する「主語」』欄に「1」(「ロシア軍」)を入力後、「指定単語を主語に持つ・・・」ボタンを押す。

今回、ツールに読み込ませたファイル(拡張子:".txt") )
__NHK NewsWebの国際面に、2020/12/1に掲載されていた記事__を読み込ませてみました。
article.txt
ロシア軍は、北方領土で地対空ミサイルシステム「S300」の訓練を初めて行ったと発表しました。ロシアとしては北方領土で軍備を強化している姿勢を強調するねらいがあるものとみられます。
ロシア軍の東部軍管区は1日、地対空ミサイルシステム「S300」の訓練を北方領土を含む島々で初めて行ったと発表しました。
このミサイルシステムは中国国境に近いロシア極東のユダヤ自治州に配備されていたものを移送したということで、軍のテレビ局は、北方領土の択捉島でミサイルシステムを稼働させる映像を流しました。
このミサイルシステムは、射程がおよそ400キロ、戦闘機やミサイルなどを撃ち落とす対空防衛を目的としていて、島にある演習場で訓練することが目的だとしています。
ロシアは、択捉島と国後島には地対艦ミサイルシステムを配備していますが、「S300」の訓練を北方領土で行ったのは初めてで、ロシアとしては、北方領土で軍備を強化している姿勢を強調するねらいがあるものとみられます。
日本政府は、ロシア側による北方領土での軍備の強化について「北方領土に関する日本の立場と相いれず受け入れられない」として繰り返し、抗議しています。
実装コード
tkinter_ner_sub_pred_pair_file_dialog.py
# Tkinterのライブラリを取り込む
import tkinter, spacy, collections, CaboCha, os
import tkinter.filedialog, tkinter.messagebox
from typing import List, TypeVar
from tkinter import *
from tkinter import ttk
from tkinter import filedialog
from tkinter import messagebox
from spacy.matcher import Matcher
# グローバル変数の宣言
exracted_entity_word_list = ""
user_input_text = ""
named_entity_label = ""
T = TypeVar('T', str, None)
Vector = List[T]
# ファイルの参照処理
def click_refer_button():
fTyp = [("","*")]
iDir = os.path.abspath(os.path.dirname(__file__))
filepath = filedialog.askopenfilename(filetypes = fTyp, initialdir = iDir)
file_path.set(filepath)
# 固有表現抽出処理
def extract_words_by_entity_label(text, named_entity_label):
nlp = spacy.load('ja_ginza')
text = text.replace("\n", "")
doc = nlp(text)
words_list = [ent.text for ent in doc.ents if ent.label_ == named_entity_label]
return words_list
# 出力処理
def click_export_button():
# 選択された固有表現の種別名を取得
named_entity_label = flg.get()
global user_input_text
f = open(file_path, encoding="utf-8")
user_input_text = f.read()
label_word_list = extract_words_by_entity_label(user_input_text, named_entity_label)
# 指定された固有表現に該当する単語を取得した結果(単語リスト)を、{単語文字列 : 出現回数}の辞書に変換する
count_per_word = collections.Counter(label_word_list)
# 出現回数の多い順番に並べる
freq_per_word_dict = dict(count_per_word.most_common())
#output_list = ["{k} : {v}".format(k=key, v=value) for (key, value) in freq_per_word_dict.items()]
# 単語数を取得する
unique_word_num = len(freq_per_word_dict)
if unique_word_num > 0:
message = "{num}件の{label}が見つかりました。\n\n出現回数順に並べた結果は以下です。\n\n".format(num=unique_word_num, label=named_entity_label)
word_list = list(freq_per_word_dict.keys())
word_freq_list = list(freq_per_word_dict.values())
for i in range(unique_word_num):
tmp = "{rank}番目の単語 : {word}\n出現回数 : {count}\n\n===================\n".format(rank=i+1, word=word_list[i], count=word_freq_list[i])
message += tmp
else:
message = "{num}件の{label}が見つかりました。\n\n".format(num=unique_word_num, label=named_entity_label)
textBox.insert(END, message)
global exracted_entity_word_list
exracted_entity_word_list = word_list
return exracted_entity_word_list
def get_subject_predicate_pair_list(sentence: str, subject_word: str) -> Vector:
T = TypeVar('T', str, None)
c = CaboCha.Parser()
tree = c.parse(sentence)
# 形態素を結合しつつ[{c:文節, to:係り先id}]の形に変換する
chunks = []
text = ""
toChunkId = -1
for i in range(0, tree.size()):
token = tree.token(i)
text = token.surface if token.chunk else (text + token.surface)
toChunkId = token.chunk.link if token.chunk else toChunkId
# 文末かchunk内の最後の要素のタイミングで出力
if i == tree.size() - 1 or tree.token(i+1).chunk:
chunks.append({'c': text, 'to': toChunkId})
# ループの中で出力される「係り元→係り先」文字列をlistに格納
pair_list = []
#
for chunk in chunks:
if chunk['to'] >= 0:
pair_list.append(chunk['c'] + " → " + chunks[chunk['to']]['c'])
output_list = [pair for pair in pair_list if subject_word in pair]
return output_list
def click_export_button2():
# 入力された主語単語の文字列を取得
order_num = int(subject_num.get())-1 #ユーザが1を入力したとき、配列の0番地を指定する。
subject_string = exracted_entity_word_list[order_num]
output_list = get_subject_predicate_pair_list(user_input_text, subject_string)
result = "\n".join(output_list)
message = """
単語:「{subject_word}」を主語に持つ「主語と述語」のペアは、以下が見つかりました。
=========================================================================
{result}
=========================================================================
以上です。
""".format(subject_word=subject_string, result=result)
textBox.insert(END, message)
if __name__ == '__main__':
# ウィンドウを作成
root = tkinter.Tk()
root.title("文書内容_早見チェッカー") # アプリの名前
root.geometry("730x500") # アプリの画面サイズ
# ファイル選択ウインドウを作成
# root.withdraw()
fTyp = [("", "*.txt")]
iDir = os.path.abspath(os.path.dirname(__file__))
tkinter.messagebox.showinfo('ファイル選択ダイアログ','処理ファイルを選択してください!')
file_path = tkinter.filedialog.askopenfilename(filetypes = fTyp,initialdir = iDir)
# 処理ファイル名の出力
tkinter.messagebox.showinfo('以下のファイルを選択しました。',file_path)
# Frame1の作成
frame1 = ttk.Frame(root, padding=10)
frame1.grid()
# 「」ラベルの作成
t = StringVar()
t.set('着目する「主語」:')
label1 = ttk.Label(frame1, textvariable=t)
label1.grid(row=1, column=0)
#テキストボックス2(「主語述語ペア」の「主語」入力欄)の作成
subject_num = StringVar()
subject_num_entry = ttk.Entry(frame1, textvariable=subject_num, width=50)
subject_num_entry.grid(row=1, column=1)
# ラジオボタンの作成
#共有変数
flg= StringVar()
#ラジオ1
rb1 = ttk.Radiobutton(frame1, text='人名',value="PERSON", variable=flg)
rb1.grid(row=2,column=0)
#ラジオ2
rb2 = ttk.Radiobutton(frame1, text='地名',value="LOC", variable=flg)
rb2.grid(row=2,column=1)
#ラジオ3
rb3 = ttk.Radiobutton(frame1, text='組織名', value="ORG", variable=flg)
rb3.grid(row=2,column=2)
#ラジオ4
rb4 = ttk.Radiobutton(frame1, text='日付',value="DATE", variable=flg)
rb4.grid(row=3,column=0)
#ラジオ5
rb5 = ttk.Radiobutton(frame1, text='イベント名',value="EVENT", variable=flg)
rb5.grid(row=3,column=1)
#ラジオ6
rb6 = ttk.Radiobutton(frame1, text='金額',value="MONEY", variable=flg)
rb6.grid(row=3,column=2)
# Frame2の作成
frame2= ttk.Frame(root, padding=10)
frame2.grid()
# 固有表現単語を抽出した結果を表示させるボタンの作成
export_button = ttk.Button(frame2, text='ファイルから指定した種類の単語を洗い出す', command=click_export_button, width=70)
export_button.grid(row=0, column=0)
# 「主語述語ペア」を抽出した結果を表示させるボタンの作成
export_button2 = ttk.Button(frame2, text='指定単語を主語に持つ「主語述語ペア」を表示します', command=click_export_button2, width=70)
export_button2.grid(row=1, column=0)
# テキスト出力ボックスの作成
textboxname = StringVar()
textboxname.set('\n\n処理結果 ')
label3 = ttk.Label(frame2, textvariable=textboxname)
label3.grid(row=1, column=0)
textBox = Text(frame2, width=100)
textBox.grid(row=3, column=0)
file_selected_message = """以下のファイルを選択しました。\n{filename}\n\n""".format(filename=file_path)
textBox.insert(END, file_selected_message)
# ウィンドウを動かす
root.mainloop()