はじめに
こんにちは、株式会社エーアイセキュリティラボ 新入社員の大桶です。
前回の記事では業務に必要な知識習得の一つのまとめとして、実際の製品とは異なる研修用の簡易的なクローラーの作成で苦労したところである、aタグとformタグの巡回について書きました。
今回の記事では、簡易クローラーを実装するにあたり作成した設計書やフローチャートと、
作成した簡易クローラーを動かしてみた様子をお見せします。
また、最後にこの課題を通しての感想や学んだことを書きます。
設計
設計書
第1回の記事では課題として定義していただいた要件を紹介しました。
この要件はAeyeScanで実際に使用されているものとは別に研修用の課題として考えていただいたものです。
この要件を受けて、まず以下のような設計書を作成しました。
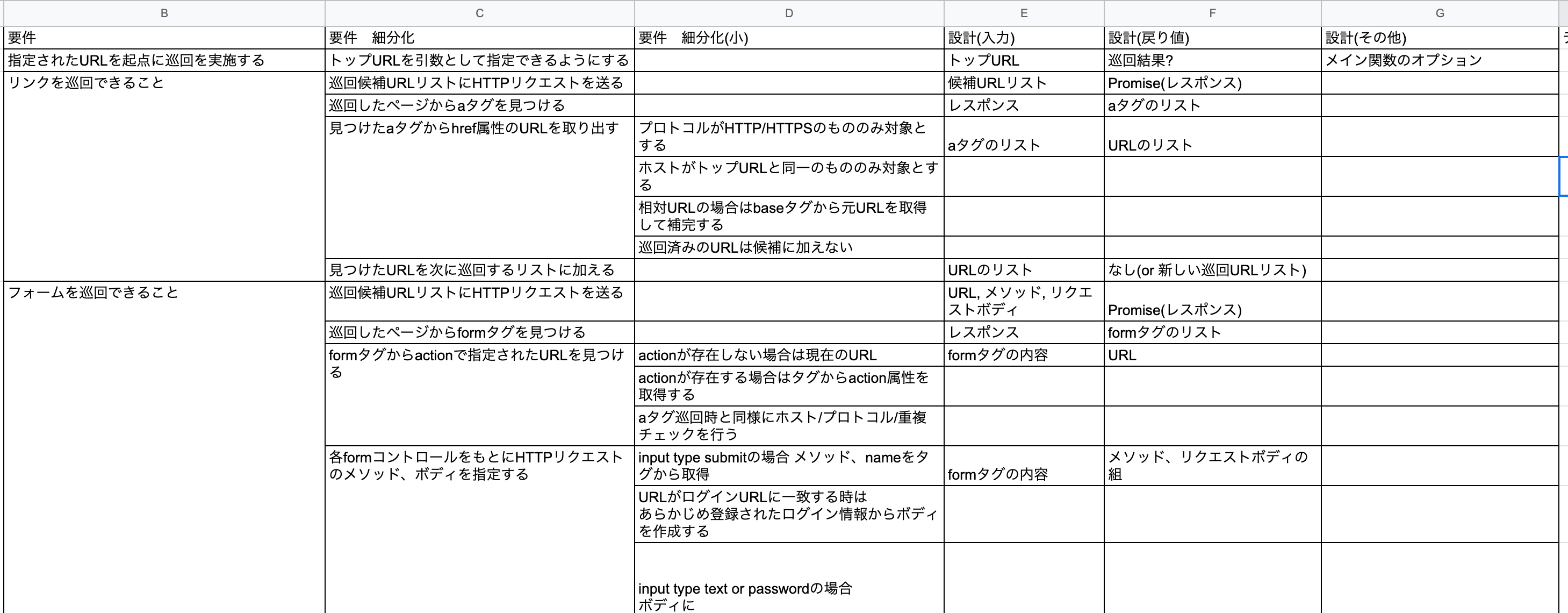
こちらの設計書では、受け取った要件の細分化や、実装するうえで何が入力で何が出力になりそうか?といったことを考えて書き出しました。
この過程で要件から何を作ればよさそうか?というイメージがより具体的になり、次のフローチャートを作成するうえでもこの表をよく見直しました。
フローチャート
次に、設計書をもとにして想定する動作のフローチャートを作成しました。
1枚目は全体図、2枚目はリクエストを送信して次の巡回候補を見つける部分(1枚目の赤いブロック)の拡大図です。
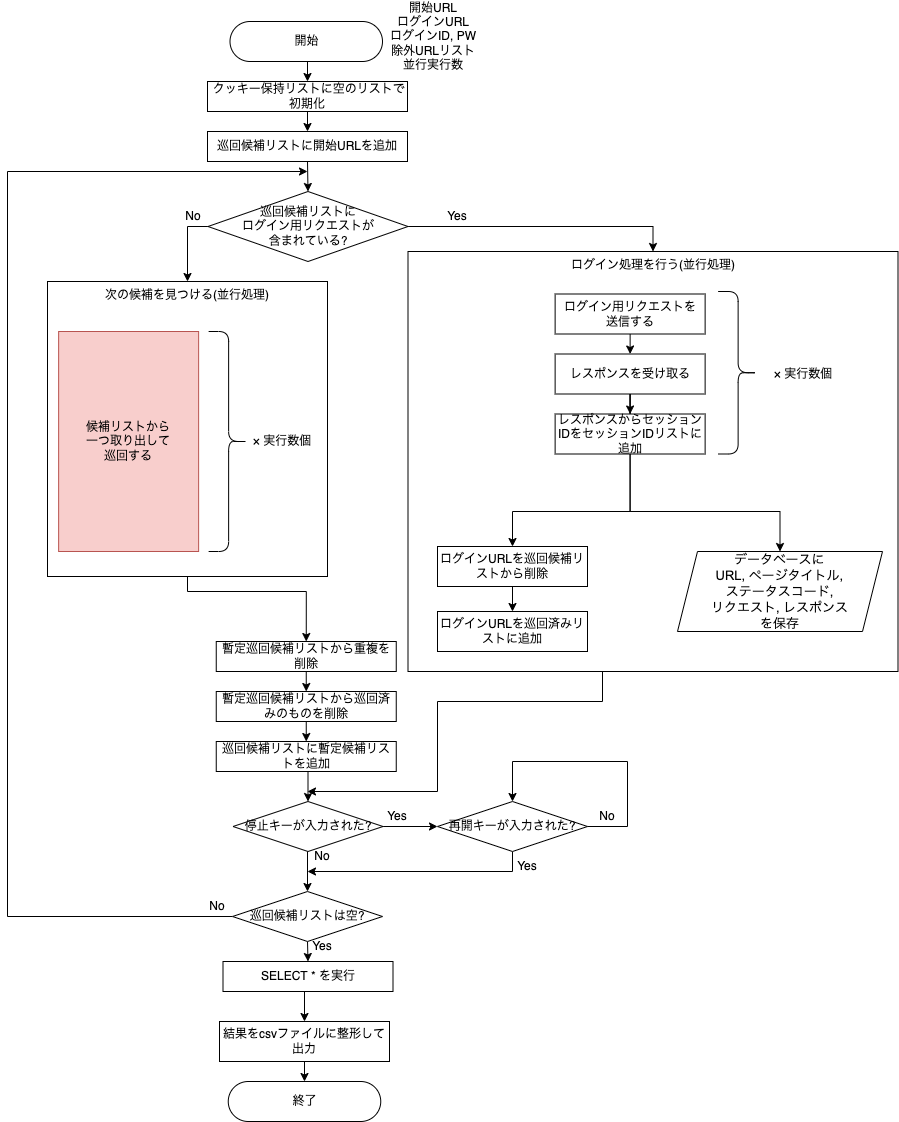
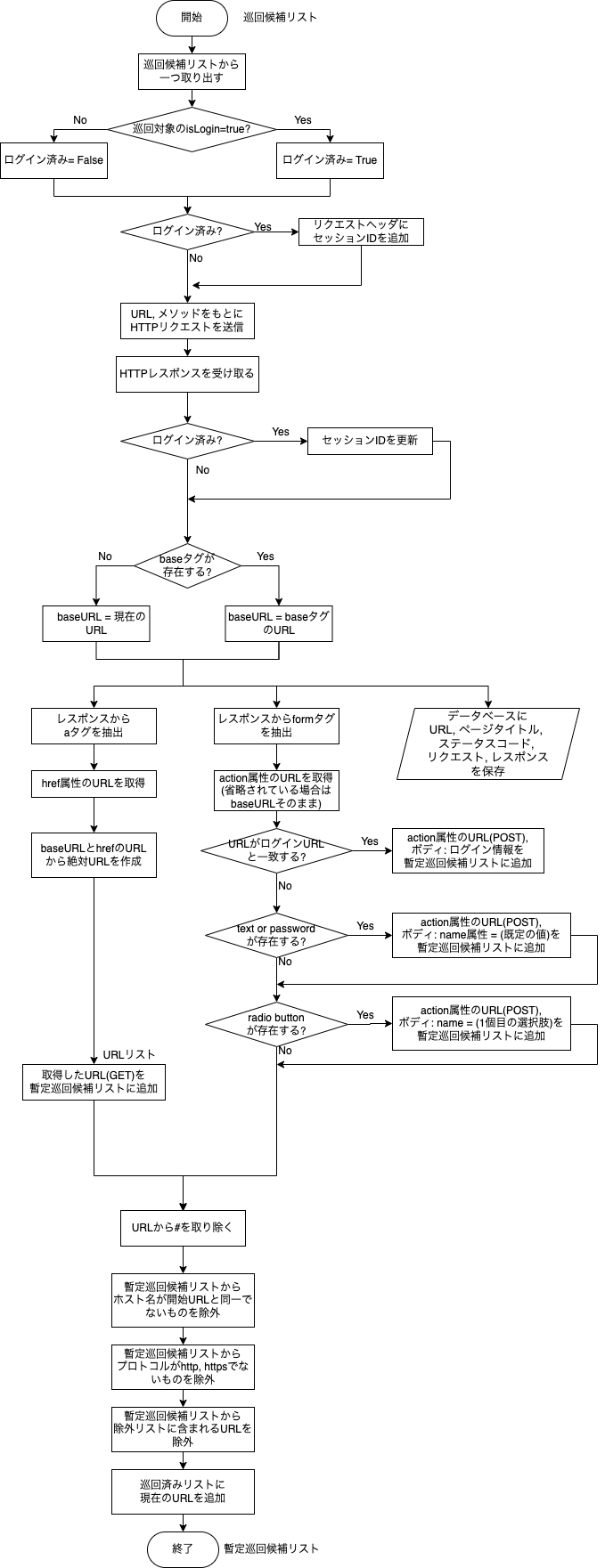
1枚目について、大まかな流れは以下のようになります。
- 巡回候補リストに開始URLが一つ入っている状態から開始
- 巡回候補リストから(並列実行数)個取り出してリクエストを送信する。数が足りない場合はあるだけ取り出す。また、ログイン用のリクエストがある場合はログインを実行する。
- レスポンスを解析し、新たな巡回候補を見つけて巡回候補リストに加える。巡回結果はデータベースに保存する。
- 巡回候補リストが空になるまで2.~3.を繰り返す。この時、停止キーが押された場合は再開キーが押されるまで巡回を中断する。
- 巡回候補リストが空になったら巡回を終了し、データベースに保存された巡回結果を取得してCSVファイルに出力する。
手順2、3 について詳しく書いたものが2枚目になります。こちらについての解説は前回の記事をご参照ください。
手順3について「巡回結果はデータベースに保存する」という部分は前回書いていませんでしたが、nodeからpostgresを利用して巡回時のリクエスト、レスポンスやステータスコードなどをデータベースに保存しています。
このフローチャートはコーディング中に今処理のどの部分を作っているか、というイメージを保つのに役立ちました。また、実装が終了した処理を塗りつぶしながら進めることで進捗の把握や実装漏れの防止にも利用できました。
実装
簡易クローラーの実装にあたり、作成したクラスとその概要を以下の表に示します。
| 名前 | 概要 |
|---|---|
| AtagHandler | HTML文書中のaタグの解析を行い、hrefで指定されたURLを取得する。 |
| FormtagHandler | HTML文書中のformタグの解析を行い、inputタグやselectタグ、の内容やオプションを取得する。 |
| Crawler | 巡回対象リストと巡回済みリストの管理や巡回を行う。また、ログインを実行する。 |
| Database | postgreSQLによるデータベース操作を行う。 |
| PauseResume | キー入力の待機と、キー入力に対応した停止フラグ(=trueの場合巡回停止)の切り替えを行う。 |
| UrlUtil | URLからプロトコルとファイル名を除いたパスを取り出すなどの操作を行う |
このように機能ごとにクラス分けをすることで、単体テストを実施しやすくなりました。
恥ずかしながら学生時代に自分用に作っていたコードではとりあえず一つのファイルに書いてみて、関数が増えてきたら場当たり的にクラスを作成することが多かったので、今回の課題であらかじめクラス設計を考えて実装する経験ができてよかったと思います。
簡易クローラーを動かしてみた
作成した簡易クローラーを実際に実行してみます。
対象のサイトは書籍「気づけばプロ並みPHP」に沿って作成した擬似ショッピングサイトと、自作したそれらのインデックスページです。
これらの巡回対象サイトはローカルホストに配置していて、hostsファイルには127.0.0.1 scan.example.com を設定しています。
まず、configファイルがこちらになります。
{
"startURL": "http://scan.example.com/PHPLearning/site/index.php",
"loginList": [
{
"url": "http://scan.example.com/PHPLearning/site/staff_login/staff_login_check.php",
"name": "staff1",
"account": {
"code": "1",
"pass": "test1234"
}
}
],
"excludeList": [
"http://scan.example.com/PHPLearning/site/idx_add.html",
"http://scan.example.com/PHPLearning/site/staff_login/staff_logout.php"
],
"numClient": 3,
"pgConfig": "postgres://crawler@localhost:5432/node_crawler",
"outputPath": "./output/output.csv"
}
ここで巡回開始URL(startURL)や並行実行数(numClient)などを指定できます。
次に、実行してみたスクリーンショットがこちらです。
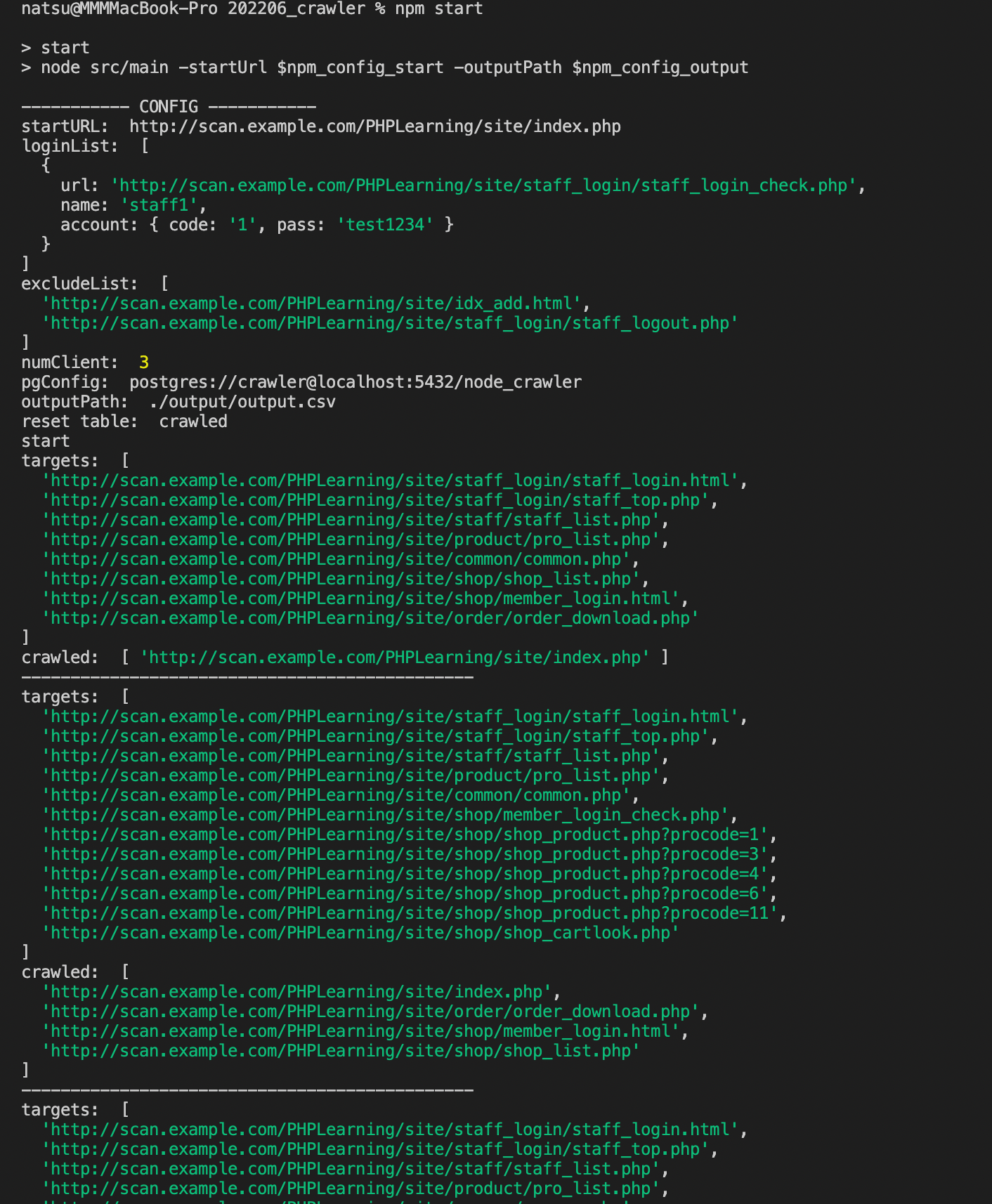
実行中にはメインループの各イテレーションごとに現在の巡回対象URLリストと巡回済みURLリストを表示しています。
巡回中にQキーを押すと一時停止し、Rキーを押すと再開できます。
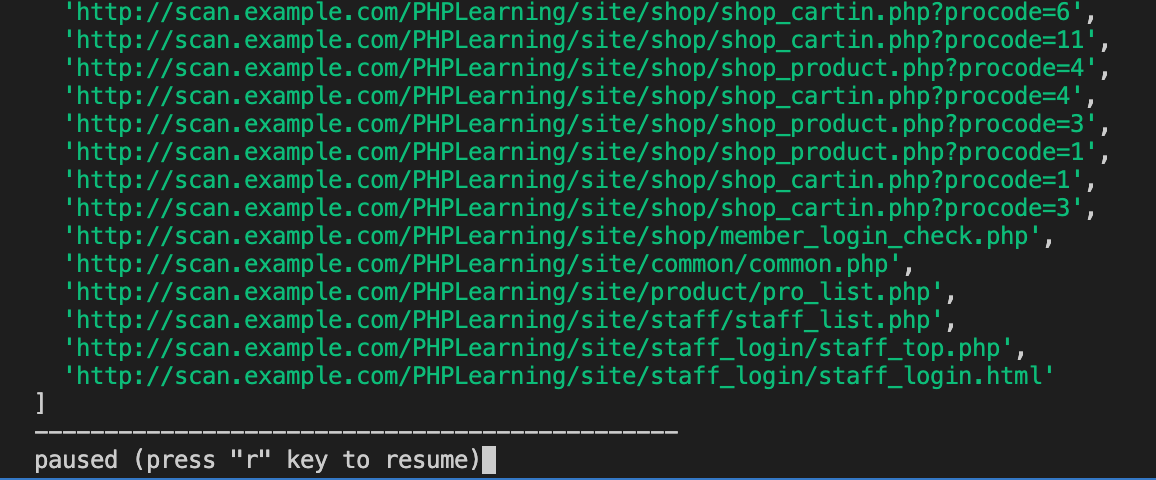
また、巡回結果をそれぞれデータベースに保存しています。
巡回対象リストが空になると終了し、データベースに保存した巡回結果をCSVファイルに自動的に出力します。
出力されたCSVファイルがこちらです。
巡回結果としてURL、ページタイトル、ステータスコード、リクエスト、レスポンスが保存されています。

こちらのCSVより、ログイン実行後のリクエストにはセッションIDがセットされていて、リクエストごとに更新されていることが確認できます。

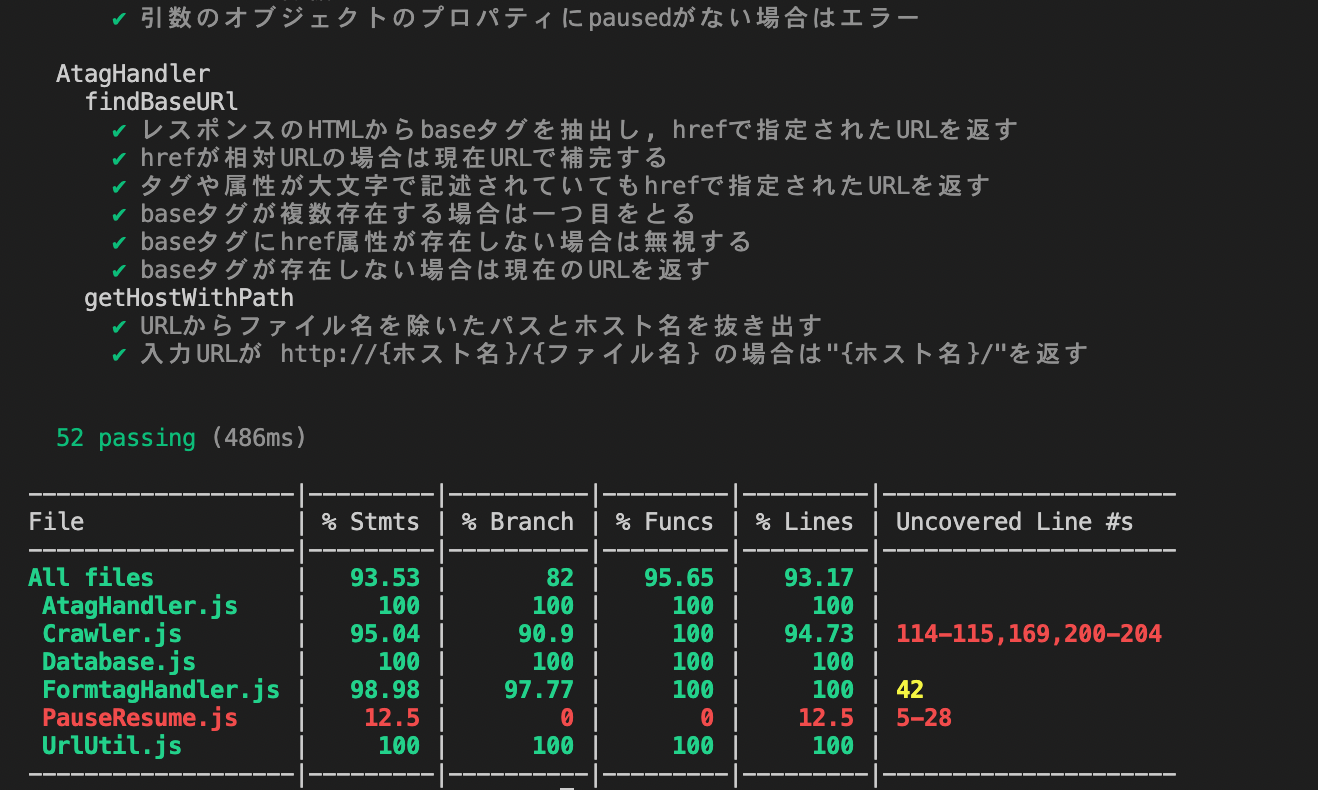
また、この簡易クローラーに対してのmochaによる自動テストコードも作成しました。
巡回停止/再開など一部の項目は手動テストに回していますが、正常動作を含む52個の項目を自動でテストできます。
課題を通しての感想
課題として簡易クローラーを作ってみて、難しいところも色々とありましたが一応形にすることはできたので、難易度としてはちょうどよかったのではないかと思いました。
現在、業務で取り組んでいる問題はこの課題よりもさらに難しいですが、課題で学んだHTTPやJavaScriptの知識や、クローラーを作るうえでの基本的な考え方などは役立っていると感じます。書籍など机上で学んでいた時は実際の業務で触るような複雑なクローラーの仕様はイメージのみしか理解できませんでしたが、今は当時より実際のコードを読んで踏み込んだ理解ができていて、この課題を通して実務に携わるうえでの思考の土台ができたのではないかと思います。
おわりに
今回の記事では簡易クローラーの実装にあたり作成した設計書や、完成した簡易クローラーを実行してみた様子をお見せしました。
簡易クローラー作成についてフォーカスした記事はこちらで以上となります。
次回の記事では入社してからの約半年の振り返りを書いてみようと思います。