こんにちは、@okazu_dm です。
今回は、ChatGPTの画像認識機能1 (通称GPT-4V)の自動巡回との親和性を探る試みの一つとして、CAPTCHAをChatGPTで解くことが可能かどうかを検証しました。その結果について紹介します。
文中のCAPTCHAの定義
この記事ではCAPTCHA「サイトをbotアクセスから守る目的でアクセス元が人間であるかどうかを自動判別する仕組み全般」をCAPTCHAと呼びます。
音声を文字として入力させるものなどもありますが、今回行った検証で対象とするのは画像を識別させるタイプのCAPTCHAです。これの例としては、以下のように難読化された文字を識別して入力させるものが一般的かと思われます。

また、Googleが提供するreCAPTCHAは、現在v3まで出ていますが、v3はユーザインタラクトを必要としないため、この記事中ではv2を使って対応します。reCAPTCHA v2の画像識別タスクは、画像中から特定の物を見つけるなど、文字認識よりも機械的な対応が難しい内容です。
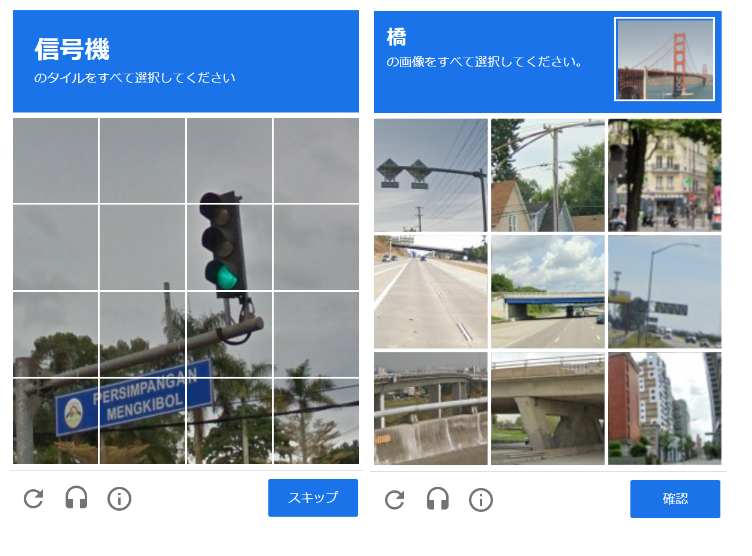
reCAPTCHA v2の画像識別タスクの例
検証の内容
今回は以下の2つを検証しました。
-
ChatGPTで文字識別タイプのCAPTCHAを解けるか
-
ChatGPTでreCAPTCHAを解けるか
それぞれ、WebUIから画像を与えてタスクを解かせる、という方法で3問ずつ検証しました。
文字識別タイプのCAPTCHA
PHPライブラリのSecurimage のサンプルファイル を使って画像を生成しました。
また、後述する過去の検証結果と比較するため、古いバージョン(3.5)を使いました。
検証は、以下のプロンプトで画像を変えたものを3回試すという方法で行いました。

結果、一つも正答することができませんでした。
そのため、Securimageの画像に対する正答率は0/3です。
予想よりも大きく下回っていたため別のセッションで試してもせいぜい1/3の正答率という結果でした。
考察
検証前の予想としては(事前にSNSなどでCAPTCHAを解ける、という趣旨の投稿を見たのもあり)このレベルのものは2/3は超えるだろうと考えていました。しかし予想に反して全問不正解となりました。
当初の予想の根拠を更に挙げると既にこのレベルのOCRはそれなりの精度が出ている、という事実もあります。例えば、過去に行った以下の検証だと文字認識用のモデルを使って97.45%という高い正答率が出ています。
https://qiita.com/AeyeScan/items/bf6d39fc1d63d3c12cf7
ただし、こちらの検証は今回行った検証と前提条件に大きな違いがあり、訓練に500000枚の画像をSecurimageを用いて準備している分だけ過去の検証に使ったモデルの方が有利だと言えます。
そのため、この差を埋めるためにChatGPTにもある程度のボリュームでサンプルとなる入力を与えれば、より適切な比較ができると考えられます。しかし現状では3時間あたりに50件しか送れないという上限とレスポンスも一件あたり数秒から10秒程度かかり、人力で行うには難しい作業です。検証を行った2023年10月末時点ではAPIも公開されていない機能のため今回はChatGPTに対してサンプルデータを与えることは諦めました。最後に正答率を上げる試みとして試しに同じ画像をそのまま拡大して与えても結果は同様でした(0/3か1/3)
reCAPTCHA
次にreCAPTCHAに対して同様の検証を行いました。
こちらは以下のように、問題文も含めて切り出した画像を与えてどの箇所に該当するものがあるかを聞く方法で3回試しました。
こちらについては3問中正答は一つもなく、何度か別の画像を与えても正当できたものが1つもなかったため、そもそも問題の与え方が適切でない可能性に思い当たりました。
問題として試しにChatGPTが指す位置がこの問題の意図するものと同じものなのかを確かめるために問題の回答とは直接関係ない質問をいくつか行いました。
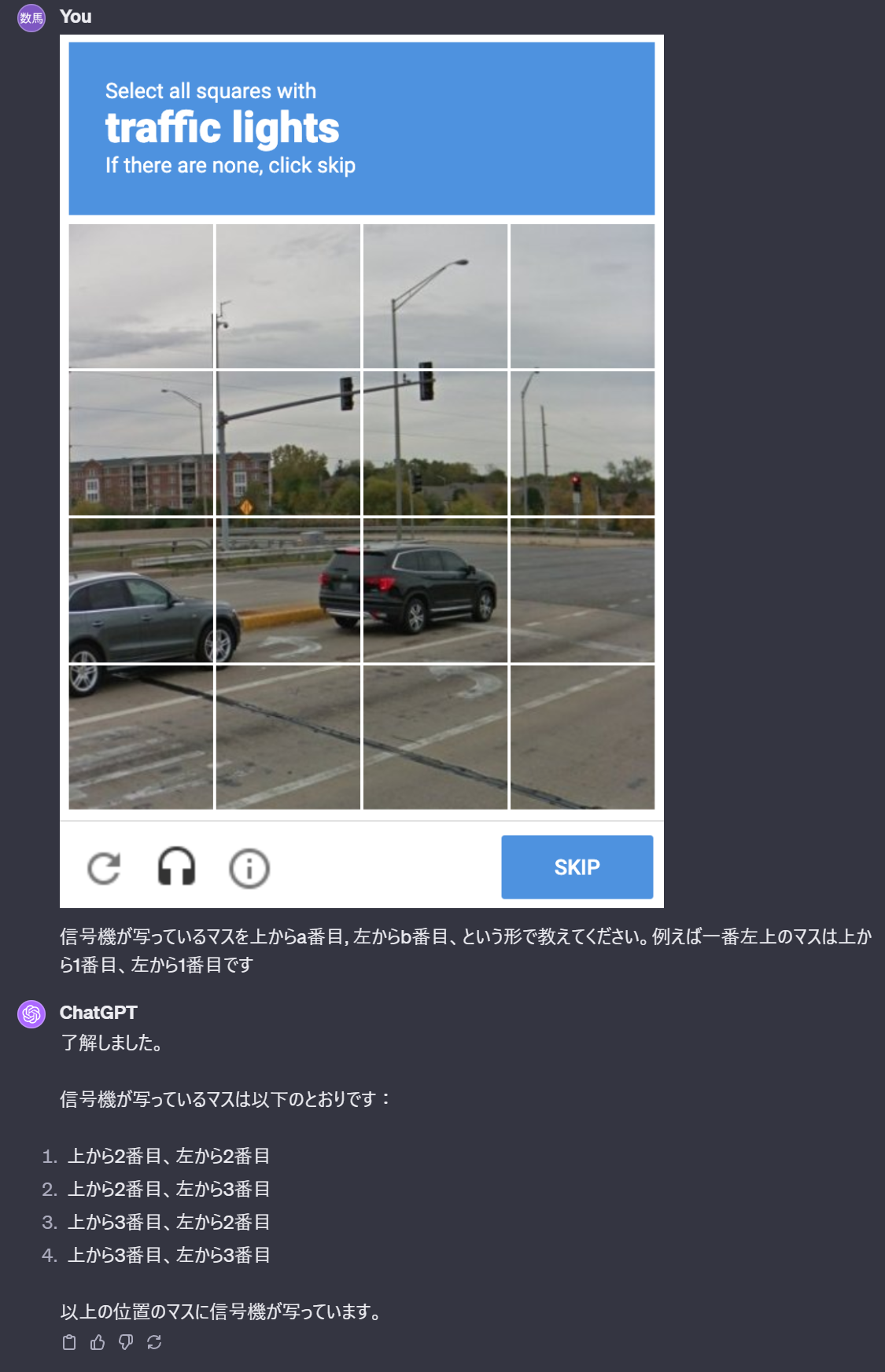
例えば、以下のように画像にいくつのマスに分かれているかを質問したところ、意図した答えとしては16でしたがChatGPTとしては20のマスに分かれていると回答しました。
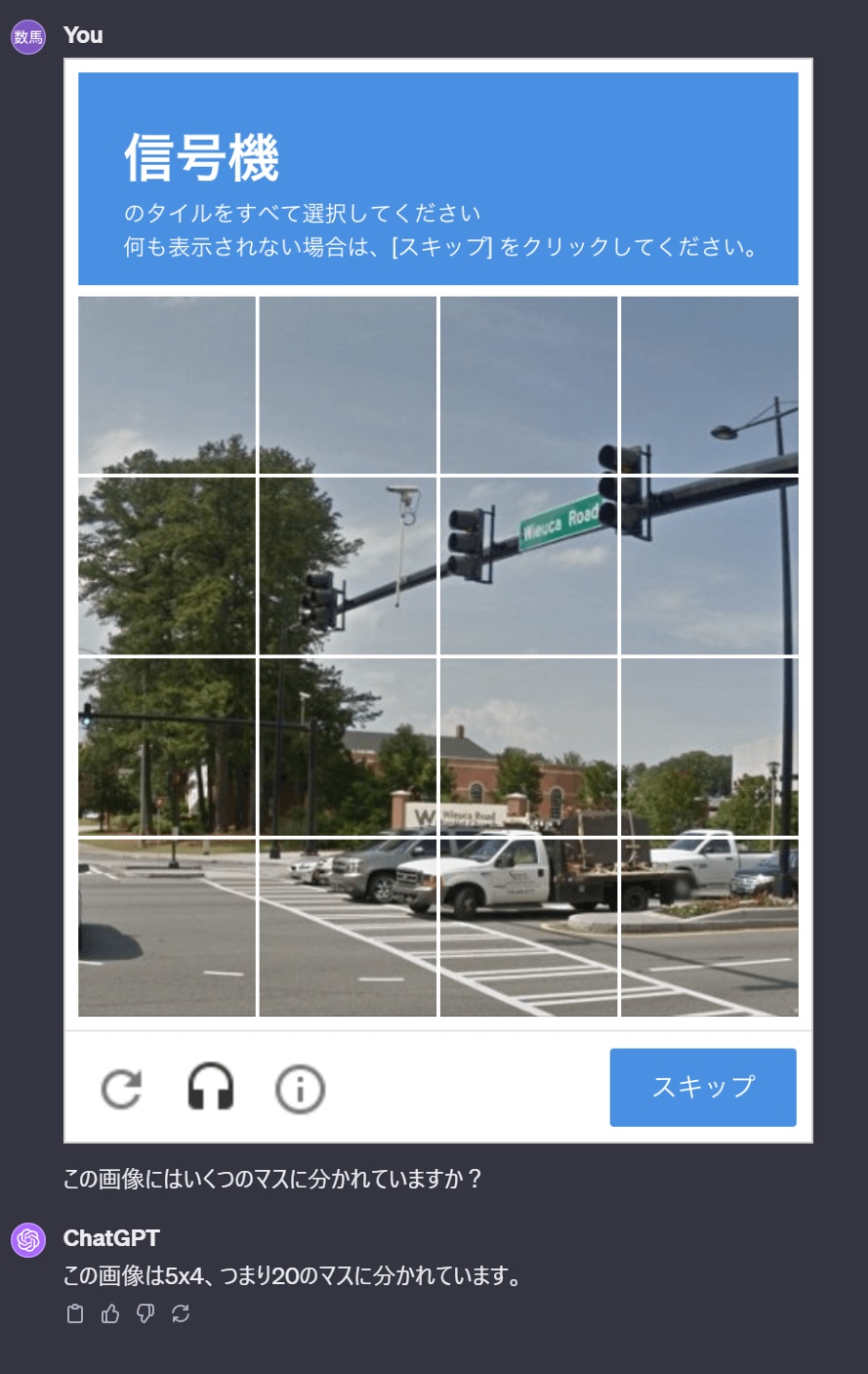
この他に、マスの座標を指定して「そのマスに何が写っているか」を説明させてみると違うマスに写っているものを説明したことから、画像自体を説明することはできるがマスで分割された位置をChatGPTに説明させることは難しいと判断しました。
認識しやすく画像を加工した場合
次に試したのは「画像中には4x4の16マスに分割されている箇所があります」という追加情報を質問の最初につけることでしたが、こちらでも特に正当数は増えず、そもそも幾何学的な位置で回答させるという手法が難しいと判断しました。
そのため、回答方法自体を変えるために画像を加工して以下のような質問をしました。
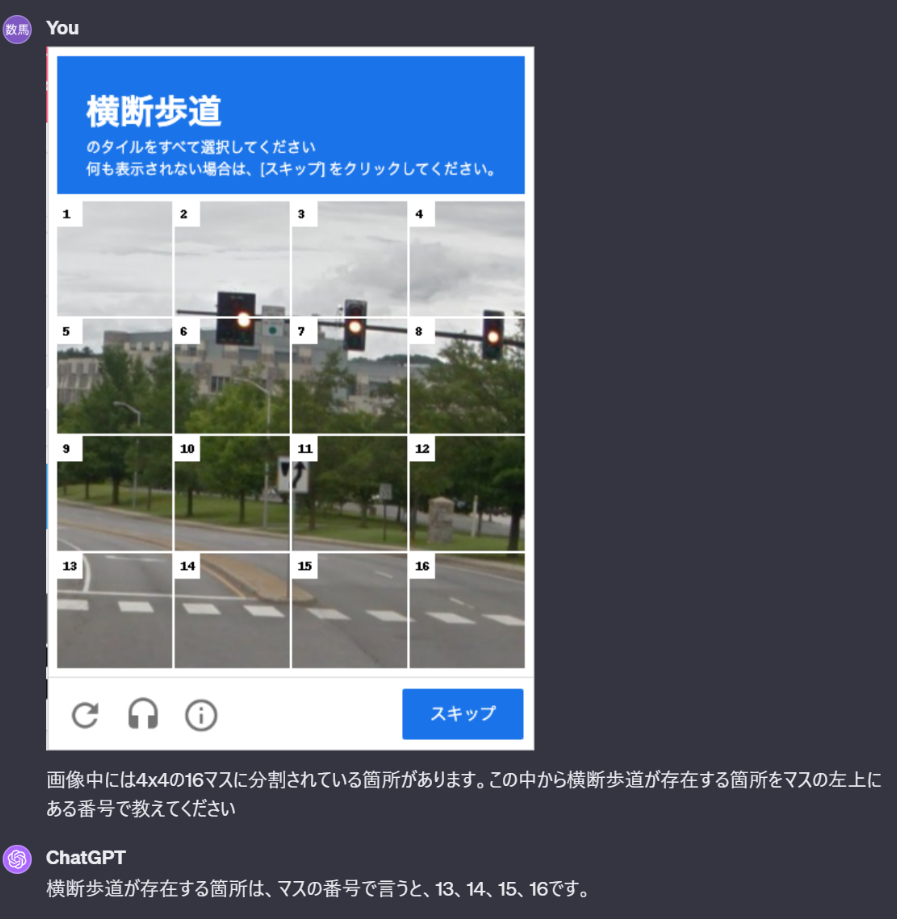
それぞれのマスの左上に番号を振った画像を与えて、その番号で答えるようにしたところ、正答率は0/3から2/3に向上しました。
このように画像中に情報を付加してテキストで与えていたプロンプトとは別に指示を与えるなどのコミュニケーションを行う手法を、「Visual Referring Prompting」と紹介している論文があり、特に注目してほしい箇所を丸で囲む手法や、今回のように指し示す対象としての番号を画像中に付加する手法などが紹介されています。
検証結果
以上から、今回の検証の結果は以下となります。
- Securimageに対しての正答率 0/3
- reCAPTHCAに対しての正答率 0/3
- ただしVisual Referring Promptingを利用した場合 2/3
結論
今回の検証の結果から、ChatGPTの画像認識機能が自動巡回に利用可能か、という観点で考察をしました。
2023年10月末の検証時点では、精度が充分ではなく、自動巡回などに活用するには不向きであると結論づけました。
Securimageによる出力をそのまま与えても現状だと精度は低く、自動化の観点では実用レベルではありません。reCAPTCHA v2に対してもそのままだと正答は難しい、というレベルです。ただし、画像を加工する手法としてVisual Referring Promptingという名前が既に提案されており、実際に一定の効果も期待できるため攻撃に利用可能なノウハウとして悪用され得る可能性はあります。
今回の検証自体の大きな問題としてChatGPT自体の精度を測るにはデータの数が圧倒的に少ないという点がありますが、この点については今後GPT-4の上限緩和と速度の向上でより多くのデータで検証が可能になると予測されます。
頻繁にモデルのアップデートが行われているプロダクトでもあるため、検証結果の再現性はおそらく低いです。こちらについては一例と捉えていただければと思います。
おわりに
エーアイセキュリティラボは、生成AIを活用したSaaS型のWebアプリケーション脆弱性診断ツールAeyeScanを提供しています。かんたんに高精度なWeb診断を実施することができることから、Webアプリ診断の内製化ツールとして多くの企業様にご活用いただいております。
今回解説したGPT-4Vの技術の研究開発も行っており、AeyeScanにも随時アップデート予定です。ご興味ある方はぜひトライアルにてお試しください。
AeyeScanの詳細はこちら: https://www.aeyescan.jp