SaaS型Webアプリ診断ツール「AeyeScan」を運営している株式会社エーアイセキュリティラボが、セキュリティテストの自動化、脆弱性診断の内製化、AI/機械学習などの技術情報の共有を目的とした記事です。
AeyeScanの情報はこちら https://www.aeyescan.jp
エーアイセキュリティラボの情報はこちら、https://www.aeyesec.jp

1.はじめに
この記事は、ディープラーニングを解説するものです。入門書および入門記事をベースにしているため、あくまで概要レベルの資料です。また、簡単な説明にするために、数式は極力使わずに解説します。
2.ディープラーニングとは
ディープラーニングは、多層ニューラルネットワークにいくつかの工夫を加えたものです。データの分類や値の予測などに使うことができます。
ディープラーニングが機械学習と一線を画す点は、人間が特徴量設計(分析対象から適切な特徴を見つけて、定量的な値として取り出す作業)を行わなくてよい点です。機械学習では、機械が適切に学習できるようにするために、人間が対象物から適切な特徴量を抽出する必要がありました。そして機械学習の精度は、この特徴量設計に大きく依存していました。つまり、適切な特徴量を考えることが最も大変であるにも関わらず、これを人間が行う必要がありました。それに対して、ディープラーニングでは特徴量設計を行う必要がありません。画像認識であれば画像データをそのまま入力し、音声認識であれば音声データをそのまま入力します。ディープラーニングは、機械学習と比較して計算量が大きく増えるデメリットはありますが、このように特徴量設計をアルゴリズムに任せることができるというメリットがあります。
本資料は以降では、ディープラーニングが生まれるまでの歴史、ディープラーニングの内部構造、ディープラーニングの学習の仕組み、特定分野に最適化されたディープラーニングのアルゴリズムの紹介、現時点でのディープラーニングの問題点、ディープラーニングの実装方法の順に説明します。
3.歴史
ディープラーニングは多層ニューラルネットワークの1つです。そのためディープラーニングの歴史として、多層ニューラルネットワークが生まれるまでの流れを説明します。そしてディープラーニングと呼ばれるようになるまでに、精度を上げるために加えられた工夫について説明します。最後に、ディープラーニングがブレイクするに至ったきっかけを説明します。
3.1.形式ニューロンモデル
1943年にマカロックとピッツが生物の神経細胞をモデルとして、「形式ニューロンモデル」を発表しました。このモデルは、入力を与えると0または1を出力する計算機モデルです。
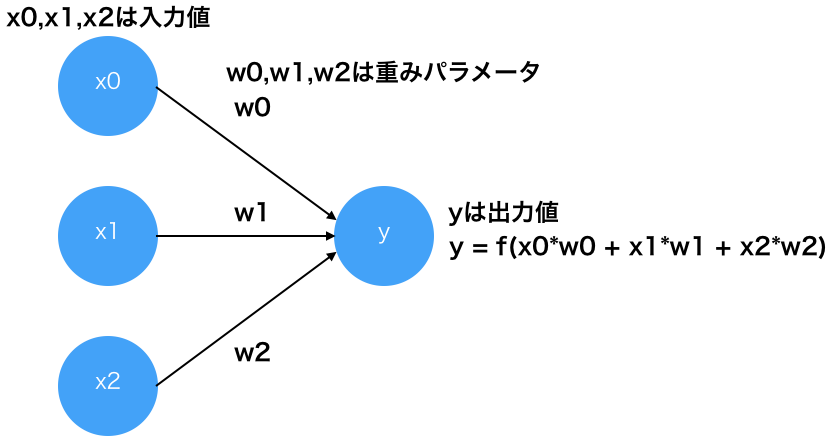
形式ニューロンモデル
上の図のfはニューロンの出力値を決める関数であり、活性化関数と呼ばれます。形式ニューロンモデルではステップ関数(段差のような形状になる関数)を利用します。
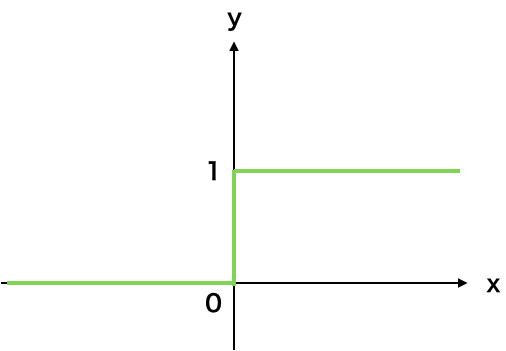
ステップ関数
形式ニューロンモデルでは、重みパラメータの値を事前に人間が決める必要がありました。
3.2.パーセプトロン
1958年にローゼンブラットが、形式ニューロンモデルの重みパラメータを学習により決める「パーセプロトロン」を発表しました。
内部構造は形式ニューロンモデルと同じです。
学習の仕組みは、以下の繰り返しです。
入力値と出力の正解値のペアをサンプルとしてモデルに与える
モデルの出力と正解値が一致しない場合、入力値と出力の正解値をもとに重みパラメータを補正する。
パーセプトロンは大きな注目を集め、1回目のニューラルネットワークのブームになりました。しかし1969年にミンスキーが、パーセプトロンは線形分離可能な場合(2次元でいうと、2つグループを直線で線引きできる場合)にしか重みパラメータの値が収束しないことを指摘し、ブームが終了しました。
当時の時点でも、パーセプトロンを多層化すれば、線形分離不可能な場合にも対応できることが知られていました。しかし、多層化した場合に、入力層と出力層の間の中間層に対して、どのように重みパラメータを補正すればよいのかが当時は不明でした。そのため、パーセプトロンを多層化しても中間層の重みパラメータの補正ができず、精度が低いままでした。
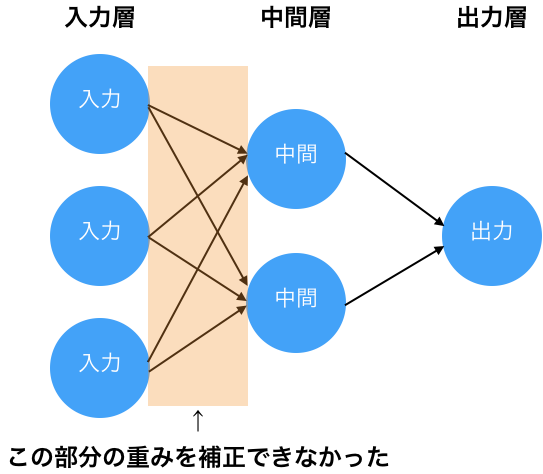
3.3.多層ニューラルネットワーク
1986年にラメルハートらが誤差逆伝搬法を発表しました。誤差逆伝搬法は、多層パーセプトロン(多層ニューラルネットワーク)において、出力層から入力層の方向に、モデルの出力値と正解値の間の誤差を各層の各ニューロンに伝えるアルゴリズムです。これにより、多層ニューラルネットワークにおいて、中間層の重みパラメータを補正できるようになりました。誤差逆伝搬法の登場により、多層ニューラルネットワークは大きな注目を集め、2回目のブームになりました。
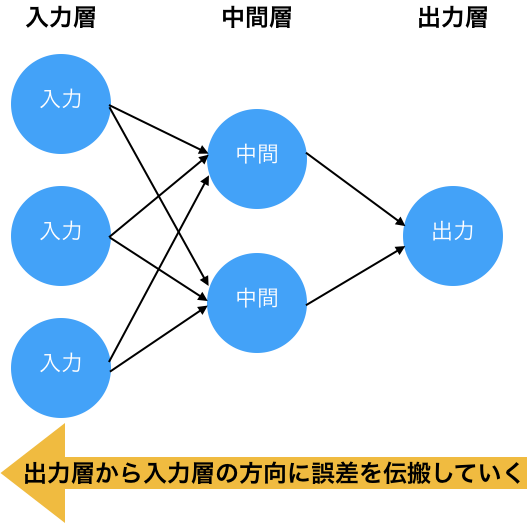
これまでのニューラルネットワークでは、活性化関数としてステップ関数を利用していました。しかし、誤差逆伝搬法では微分可能な活性化関数が必要であるため、多層ニューラルネットワークでは、活性化関数としてシグモイド関数を利用するようになりました。
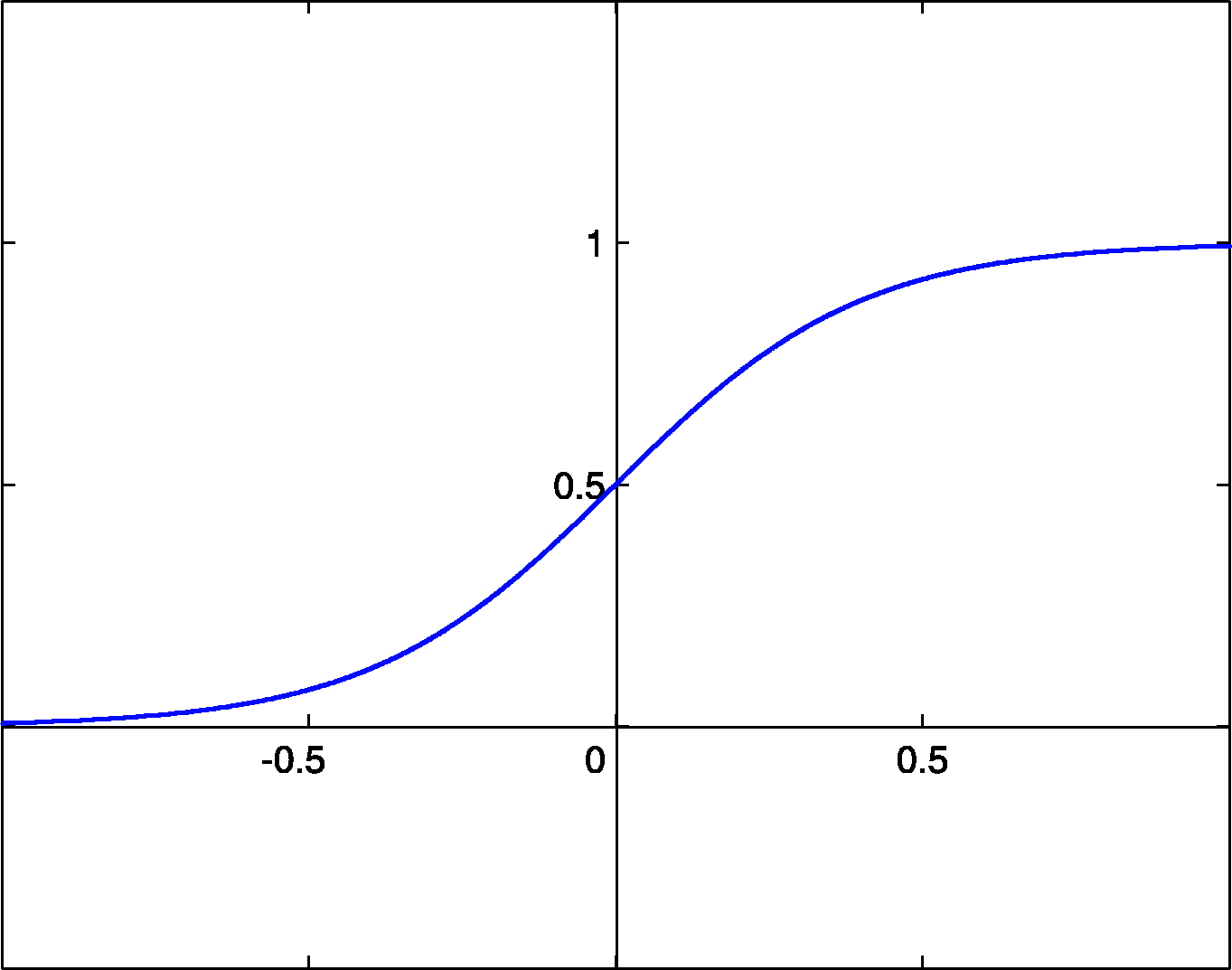
シグモイド関数
https://upload.wikimedia.org/wikipedia/commons/b/b5/SigmoidFunction.png
誤差逆伝搬法の登場により、原理的には中間層の重みパラメータを補正できるようになりました。しかし実際には、中間層の数が多いと、誤差逆伝搬時に各ニューロンの誤差が徐々に小さくなり、重みパラメータの補正値(勾配)が小さくなってしまう現象が発生していました。この現象により、重みパラメータを全体でバランスよく調整することができませんでした。この問題を勾配消失問題と言います。勾配消失問題のため、多層ニューラルネットワークは精度が伸び悩みました。そして、1992年に機械学習アルゴリズムである非線形サポートベクターマシンが登場し、高い精度を出して注目を浴びました。他の機械学習アルゴリズムへ注目が移ることで、ニューラルネットワークの2回目のブームは終わりました。
3.4.ディープラーニング
2006年にヒントンらが、勾配消失問題を解決する方法として、ディープビリーフネットワークを発表しました。そして2008年にビンセントらが、勾配消失問題を解決する方法として、積層デノイジング・オートエンコーダを発表しました。これらの手法がディープラーニングのブレイクスルーになりました。
ディープビリーフネットワークは、制限付きボルツマンマシンを多層化したものです。制限付きボルツマンマシンは、入力からノイズを取り除くニューラルネットワークであり、各ニューロンが確率状態をもつモデルです。
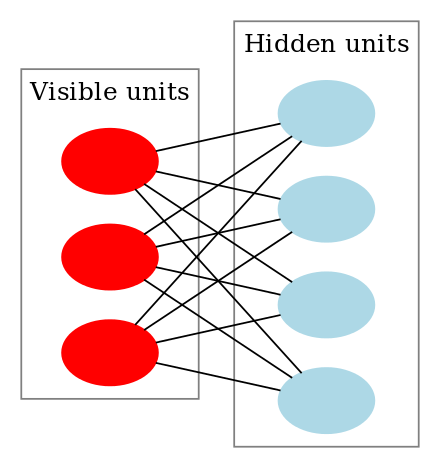
積層デノイジング・オートエンコーダは、デノイジング・オートエンコーダを多層化したものです。デノイジング・オートエンコーダは、入力からノイズを取り除くニューラルネットワークであり、データの次元削減にも利用されるモデルです。
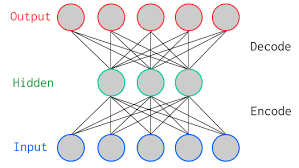
オートエンコーダ
https://upload.wikimedia.org/wikipedia/commons/0/06/AutoEncoder.png
2つの方法が取ったアプローチは同じものでした。多層ニューラルネットワークで学習を行う前に、1層ずつ事前学習(プレトレーニング)を行います。この事前学習では、2つの層の間の入力と出力が同じになるように重みパラメータの調整を行います。そして、全層の重みパラメータの調整が済んだ後に、従来と同様に誤差逆伝搬法を利用して学習を行います。これにより勾配消失問題を回避できることがわかりました。
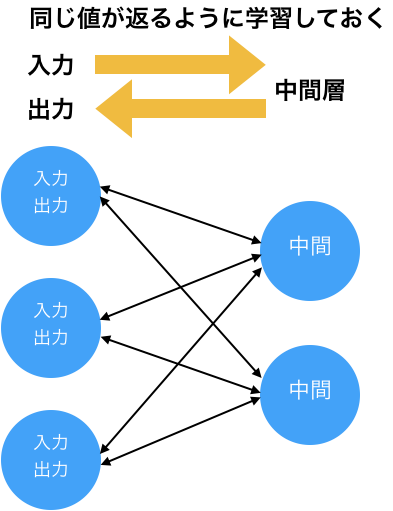
事前学習により勾配消失問題を回避できることがわかり、多層ニューラルネットワークに注目が集まりました。さらに研究が進んだ結果、事前学習を行わずに勾配消失問題を回避する以下の方法が見つかりました。
- 活性化関数にReLUを利用する
- ニューロンの出力を一定確率で0にする(ドロップアウト)
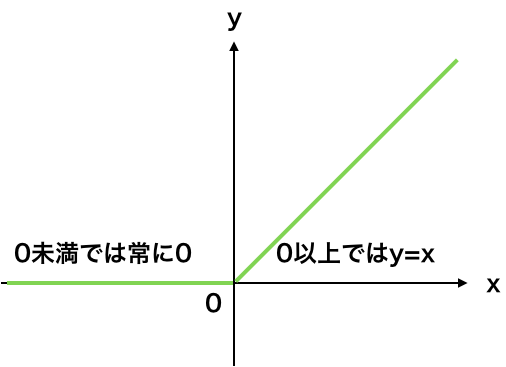
ReLU関数
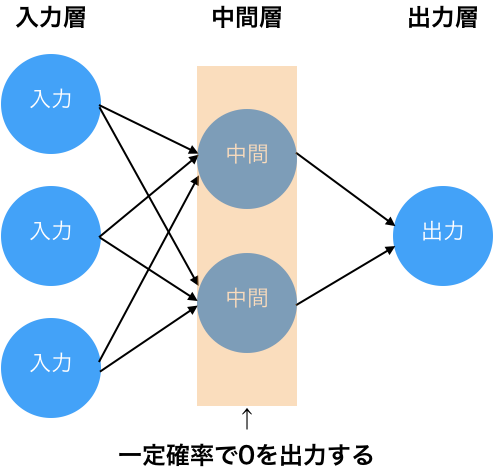
ドロップアウト
ReLUとドロップアウトの発見により、現在では事前学習を行う必要はなくなっています。
3.5.ブレイクのきっかけ
2012年にディープラーニングを世に知らしめるきっかけとなる出来事が起きました。
まず画像認識の世界的なコンペであるILSVRCで、ヒントンが率いるトロント大学のチームがディープラーニングを利用して、2位以下に圧倒的な差を付けて優勝しました。それまでは誰がよい特徴量設計を行うかが争点でしたが、そこにディープラーニングがダークホースとして現れ、優勝しました。
さらにGoogleがディープラーニングのアルゴリズムを利用して猫の自動認識に成功したことを発表しました。この実験では、Youtubeの動画から1000万枚の画像を抜き出し、トレーニングデータとしています。
この2つの出来事により、ディープラーニングのブームが始まりました。
4.内部構造
ディープラーニングの内部構造は多層ニューラルネットワークと同じです。
なお、ディープラーニングでは中間層の活性化関数としてReLUを一般に利用しますが、出力層の活性化関数は目的に応じて変えます。分類が目的である場合、ソフトマックス関数(各ラベルの確率を返す関数)を利用します。値の予測(回帰)が目的である場合、恒等関数(入力と出力が一致する関数。数式で書くと、y=x)を利用します。
5.学習の仕組み
ディープラーニングの学習の仕組みを説明します。学習にはまず、学習の進捗度合いを定量的に表す「誤差関数」が必要です。次に、誤差関数の値をもとに重みパラメータを補正する処理が必要です。ディープラーニングではこれに「誤差逆伝搬法」を利用します。さらに、誤差関数は理論的にはすべてのサンプルとすべての重みパラメータを組み合わせた数式になり、このままでは誤差関数を扱う際の計算量が現実的な範囲を超える可能性があります。それを回避するために「ミニバッチ法」と呼ばれる近似計算の仕組みを利用します。以下ではこの順に説明します。
5.1.誤差関数
ディープラーニングでは、モデルの出力値と正解値の不一致度合いを定量化するために、誤差関数を定義して利用します。誤差関数には、一般には平均二乗誤差または交差エントロピー誤差を利用します。イメージとしては、平均二乗誤差では出力値と正解値の間の距離を誤差の目安として利用します。また、交差エントロピー誤差では出力値を確率として捉え、正解値に対する尤度(どのくらいうまく状況に合致するかの度合い)を誤差の目安として利用します。
5.2.誤差逆伝搬
ディープラーニングの目標は、誤差関数の値を最小化するような重みパラメータを見つけ出すことです。重みパラメータの最適値は、数式を解いて答えを計算できる(=解析的に解ける)ものではなく、重みパラメータに補正値を繰り返し加えていき、最適値になるのを待つ必要があります。重みパラメータの補正値は、数式としては、誤差関数を重みパラメータで偏微分したもの(「勾配」と呼ばれる)を微量にしたもの(微量度合いは「学習率」と呼ばれる)です。誤差逆伝搬はこの偏微分の計算(=「勾配」の計算)を順序良くうまく行うアルゴリズムです。
5.3.ミニバッチ学習
ディープラーニングの誤差関数は、理論上は、すべてのサンプルの入力値とすべての重みパラメータを組み合わせたものです(以降、この誤差関数を{真の誤差関数}と呼ぶ)。重みパラメータを補正するためには、{真の誤差関数}の勾配を計算する必要があります。しかし、サンプル数が多いと勾配を求めるための計算量が膨大になり、現実的な時間では計算が終わらない可能性があります。そのため、ディープラーニングの実装では、計算量を減らすために近似処理を利用して学習します。具体的には「すべてのサンプルから一部を取り出して、{{{{真の誤差関数}の近似}の勾配}の近似}を計算し、それをもとに重みパラメータを補正する」というプロセスを繰り返し行います。この処理はミニバッチ学習と呼ばれ、以下の手順で行います。
- すべてのサンプルから少数のサンプル(=ミニバッチ)を選び出す。
- ミニバッチ内のサンプルとすべての重みパラメータを組み合わせた誤差関数を、{{真の誤差関数}の近似}として考える。
- {{{真の誤差関数}の近似}の勾配}の計算も計算量が多いため、{{{{真の誤差関数}の近似}の勾配}の近似}を考える。
- 1サンプルとすべての重みパラメータを組み合わせた誤差関数の勾配を計算し(※この誤差関数の勾配であれば計算量は十分に小さい)、ミニバッチ内の全サンプル分を合算して平均の勾配を計算する。この平均の勾配を、{{{{真の誤差関数}の近似}の勾配}の近似}とする。
- {{{真の誤差関数}の近似}の勾配}の近似}を元に、重みパラメータを補正する。
- 手順1に戻る。
6.最適化されたディープラーニング
ディープラーニングでは、解決したいテーマに合わせて最適化されたモデルが発表されています。以下では、代表的なテーマである画像認識と自然言語処理の2つを対象に有名なモデルを説明します。
6.1.画像認識
画像認識に最適化されたモデルとしては、畳み込みニューラルネットワークが有名です。畳み込みニューラルネットワークは生物の視覚野をもとに考案されたモデルであり、1998年にルカンらがその有用性を示しました。畳み込みニューラルネットワークでは、物体の位置がズレていても物体を認識できるようにするために、多層ニューラルネットワークに「畳み込み層」と「プーリング層」を追加しています。「畳み込み層」は特徴を抽出するフィルタの役割を担当し、「プーリング層」は特徴を要約する役割を担当します。
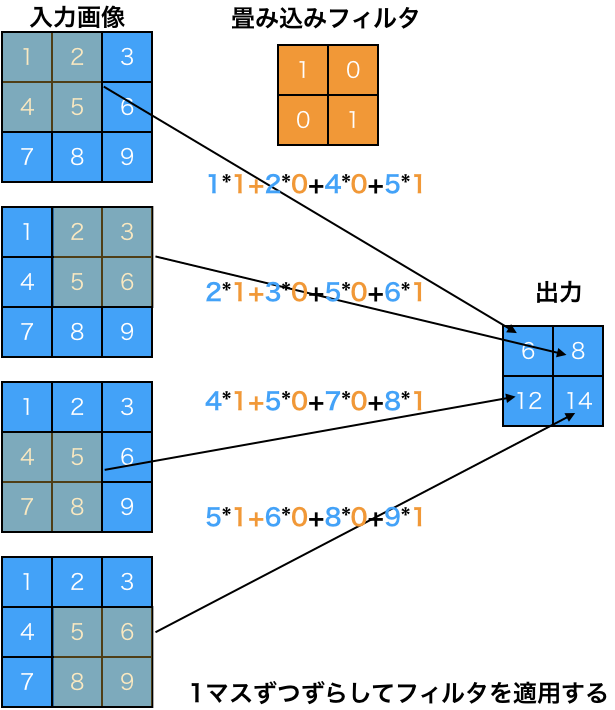
畳み込み層の処理

プーリング層の処理
画像認識は多層ニューラルネットワークの初期から研究が続けられているテーマであり、既に人間の認識精度を超えていると言われています。
6.2.自然言語処理
自然言語処理の分野には、文章の分類や単語の意味の特定、文章の自動生成など様々なテーマが存在します。ディープラーニングで有名なモデルとしては、「特定の文章の後に続く単語を予測する」テーマで利用される、リカレントニューラルネットワークがあります。リカレントニューラルネットワークは、通常の多層ニューラルネットワーク(フィードフォワードニューラルネットワークとも呼ばれる)の中間層にループ結合を持たせたモデルであり、時系列データの学習に対応しています。中でも、エルマンネットワークとLSTM (Long short term memory network) のモデルが有名です。
エルマンネットワークは、中間層のループ構造により、中間層のニューロンの前回の出力値を次の入力値の一部として利用します。
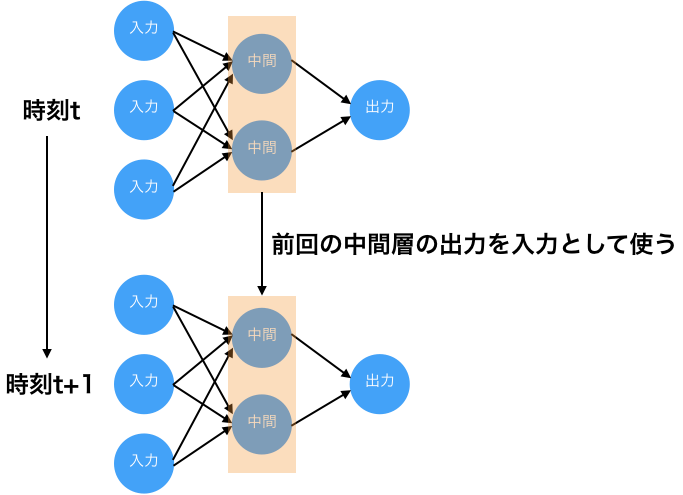
エルマンネットワーク
LSTMは、単純なニューロンの代わりに、重みを記憶するLSTMブロックを採用したモデルです。現在のリカレントニューラルネットワークでは主流のモデルです。

7.問題点
ディープラーニングを利用する上での最大の問題点は、人間がチューニングすべきハイパーパラメータが多いことです。中間層の数をいくつにするか、中間層のニューロンの数をいくつにするか、学習率をいくつにするか、活性化関数に何を利用するか、層の配置関係(直列・並列)をどのようにするか、画像認識の場合では畳み込み層の数をいくつにするか、畳み込み層のサイズをいくつにするかなど、チューニングの選択肢が数多く存在します。そしてチューニング次第で精度が大きく変わります。そのため現時点では、未知のテーマにディープラーニングを利用する場合は何度も繰り返し実験を行う必要があります。
8.参考文献
- 山下 隆義 (2016) 『イラストで学ぶ ディープラーニング』,講談社.
- 巣籠 悠輔 (2016) 『Deep Learning Javaプログラミング 深層学習の理論と実装』,インプレス.
- 巣籠 悠輔 (2017) 『詳解 ディープラーニング TensorFlow・Kerasによる時系列データ処理』,マイナビ出版.
- Aurélien Géron (著), 下田 倫大 (監修), 長尾 高弘 (翻訳) (2018) 『scikit-learnとTensorFlowによる実践機械学習』,オライリージャパン.