Krakenとは
k-merを用いて多数の配列に対してそれぞれの配列の系統を高速に推定するtoolです。
2019年の末に後続のKraken2の論文がpublish されました
Kraken2とKrakenとの差分としては
1. k-mer/LCAとのindex が大きすぎて負担になっていたので、k-merのminimizerを使うことでLCAとの対応を損なわずindexを圧縮した
2. proteinや16s db への対応
3. hash table を使うことによって高速化(1%未満のqueryのfalse positiveは許容してね)その分早く、memory efficientになった
という感じでこだわりが無ければKraken2を使ってよいと思います。
Krakenアルゴリズム
- readから指定のk に対してすべてのk-mer をrefseq db の近いものにmappingしてunique っぽいk-merごとに近縁種を同定する
- それぞれのreadを mappingされたk-merから重み付けをしてどの分類群に当てはめればいいかを決める
(NCBI refseqのdb からclade-specific k-merを取得して分類します)
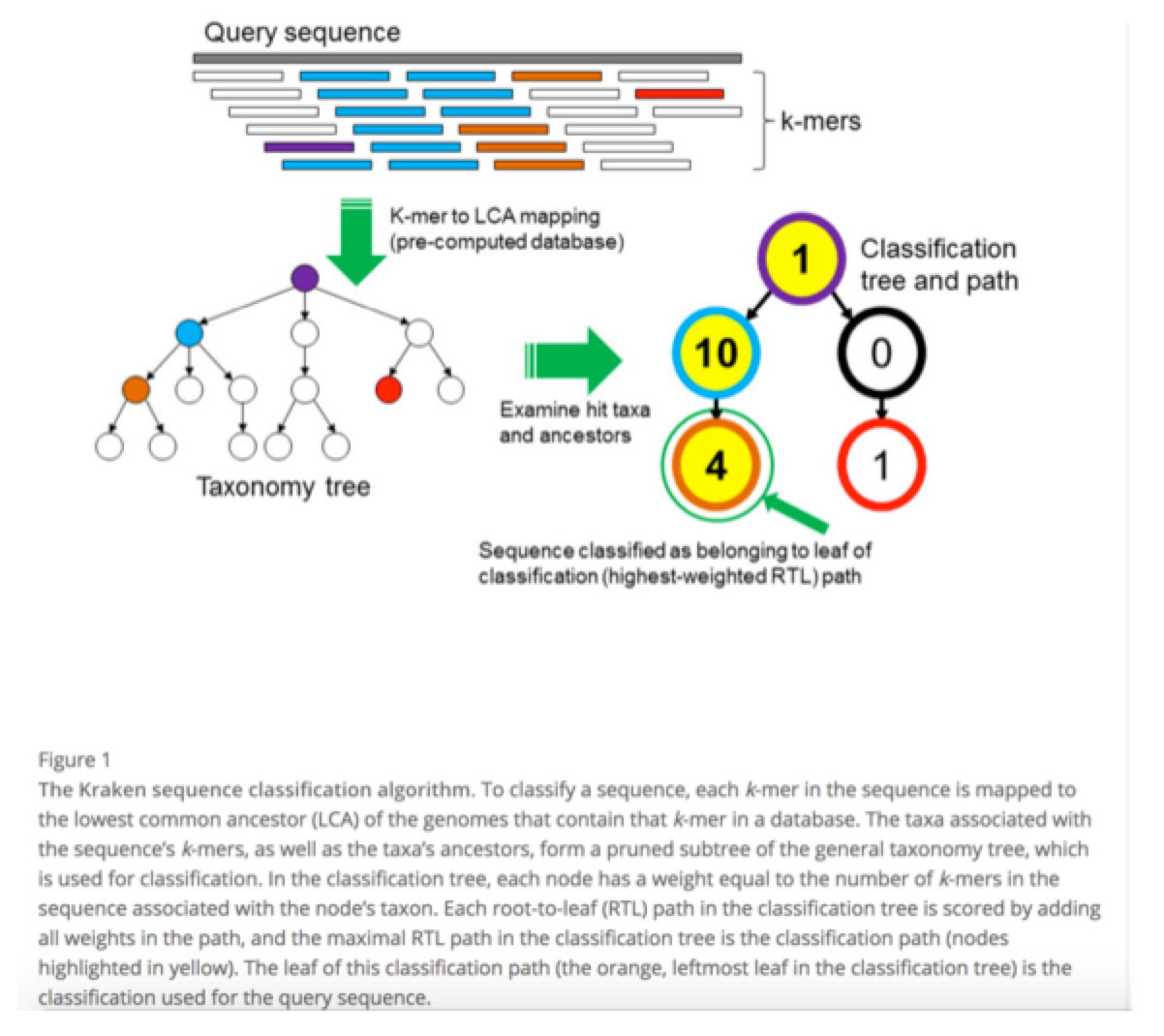
アルゴリズム概略図
Wood DE, Salzberg SL: Kraken: ultrafast metagenomic sequence classification using exact alignments. Genome Biology 2014, 15:R46.より引用
環境構築
conda でやるならば biocondaのpage(https://anaconda.org/bioconda/kraken2)
から行えるが、公式でcondaをサポートする気がないようなので(github のissue で答えていた)
ソースコードから展開する手法を紹介する
wget http://github.com/DerrickWood/kraken2/archive/v2.0.8-beta.tar.gz
tar -zxvf v2.0.8-beta.tar.gz
cd kraken2-2.0.8-beta/
sh install_kraken2.sh ../ # 一つ上の階層に展開する
以上を実行して
上記のmessageが出ればOK
指定したフォルダ以下に以下のようにscript群が展開されているはず
必要なDBのダウンロード
Krakenを実行するためには4つのdb が必要となる
database.kdb: kmerとtaxon の関係性を示すもの(mapping) 1vs 1 のはず
database.idx: step1でk-merを探すために必要なminimizer(seed配列)
taxonomy/nodes.dmp: taxonomy tree structure + ranks (重みづけの表、おそらく分類が上にいくほど大雑把になるほど重くなる)
taxonomy/names.dmp: 系統の名前の表
それぞれのdbをまとめたセットとして公式が管理しているDBをhttps://ccb.jhu.edu/software/kraken2/index.shtml?t=downloads からダウンロードすることができる
MiniKraken db : 5.5Gb
Standard Kraken db : ~30Gb
その他、Kraken2から対応するようになった16Sのファイルもダウンロードすることができる
Standard,MiniKrakenDBを使った際にどのくらいのパフォーマンスがでるか示した表が以下です(kraken HPより)
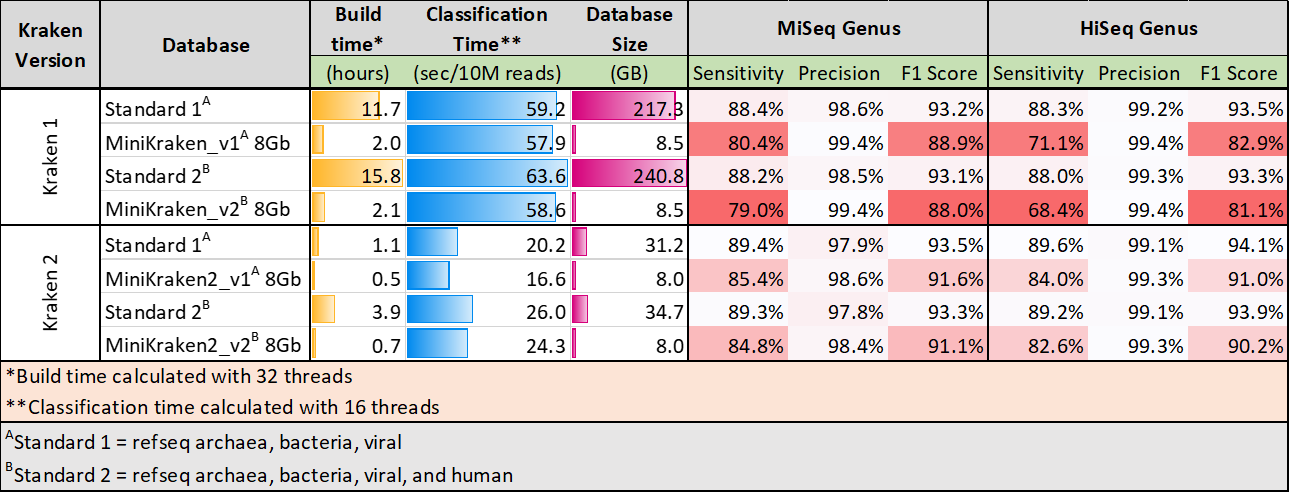
今回はminikraken2をダウンロードする
# 場所はコマンドで指定するのでどこでもいいが、Kraken2以下に保存する
wget ftp://ftp.ccb.jhu.edu/pub/data/kraken2_dbs/old/minikraken2_v2_8GB_201904.tgz
# .tgz で保存されるので展開(.tar.gz と同じ)
tar -xzvf minikraken2_v2_8GB_201904.tgz
解析の実行
実行時にはdbとinputの配列を指定する
minikraken2の場合だとdefaultで8Gbのメモリを確保するので、それ以上のメモリを確保するようにする
# classifyの実行
/kraken_path/kraken2/kraken2 --db minikraken2_v2_8GB_201904_UPDATE /sequence_path/~~.fa
メモリが足りないときのエラー

Loading database information...Failed attempt to allocate 8,000,000,000bytes;
you may not have enough free memory to load this database.
If your computer has enough RAM, perhaps reducing memory usage from
other programs could help you load this database?
classify: unable to allocate hash table memory
参考
Kraken2のgithub wiki
Kraken2HP
Kraken2の論文
Kraken2のアルゴリズムやコマンドについて概説したサイト
少し古いですが各種の系統推定のtoolを比較した論文