PytorchでWord2Vecを実装します.
Word2Vec
Word2Vecを組もうと思った時に,gensimの記事は多くヒットするのですが,Pytorchを使ってWord2Vecを実装している記事が少なかったので載せることにしました.Word2Vecを解説する記事は多いため,解説の手短にします.
Skip-gram

skip-gramは入力単語$w(t)$が与えられた時に,その周辺単語系列${,w(t-1),w(t+1)}$の出力確率を最大化します.したがって最小化する目的変数は次のようになります.
\begin{align}
E
&= -log p( w_{t-1},w_{t+1} | w_{t} ) \\
&= -log p(w_{t-1},w_{t})*p(w_{t+1},w_{t}) \\
&= -log \prod_{i}\frac{exp(p(w_{i},w_{t}))}{\sum_{j}exp(p(w_{j},w_{t}))}
\end{align}
ここで分子はwindowサイズ分の単語ですが,分母は全ての単語数計算する必要があります.それは無理なので,ネガティブサンプリングで近似します.
ネガティブサンプリングのコード
ネガティブサンプリングで出力される単語は,参考文献[1]のように単語の出現頻度で決めます.プログラムは次のようになります.
def sample_negative(sample_size):
prob = {}
word2cnt = dict(Counter(list(itertools.chain.from_iterable(corpus))))
pow_sum = sum([v**0.75 for v in word2cnt.values()])
for word in word2cnt:
prob[word] = word_counts[word]**0.75 / pow_sum
words = np.array(list(word2cnt.keys()))
while True:
word_list = []
sampled_index = np.array(multinomial(sample_size, list(prob.values())))
for index, count in enumerate(sampled_index):
for _ in range(count):
word_list.append(words[index])
yield word_list
モデルの作成
単語の入力はOnehotで単語を表現する方法もありますが,それだと単語の数だけ次元が大きくなってしまうため,Embedding Layerを使って単語ベクトルに変換した後に,EncoderとDecoderにかけます.評価は単語ベクトル同士の内積をとりログシグモイド関数で出力します.計算式は次のようになります.
L= \sum_{i} log \sigma({v'}_{w_{i}}^{T}v_{w_{I}})+\sum_{i}log \sigma(-{v'}_{w_{i}}^{T}v_{w_{I}})
class SkipGram(nn.Module):
def __init__(self, V, H):
super(SkipGram, self).__init__()
self.encode_embed = nn.Embedding(V, H)
self.decode_embed = nn.Embedding(V, H)
self.encode_embed.weight.data.uniform_(-0.5/H, 0.5/H)
self.decode_embed.weight.data.uniform_(0.0, 0.0)
def forward(self, contexts, center, neg_target):
embed_ctx = self.encode_embed(contexts)
embed_center = self.decode_embed(center)
neg_embed_center= self.encode_embed(neg_target)
# 内積
## 正例
score = torch.matmul(embed_ctx, torch.t(embed_center))
score = torch.sum(score, dim=2).view(1, -1)
log_target = F.logsigmoid(score)
## 負例
neg_score = torch.matmul(embed_ctx, torch.t(neg_embed_center))
neg_score = -torch.sum(neg_score, dim=2).view(1, -1)
log_neg_target = F.logsigmoid(neg_score)
return -1 * (torch.mean(log_target) + torch.mean(log_neg_target))
EncoderとDecoderのEmbeddingは別にするのが一般的らしいです.最大化問題なのでマイナスを掛けています.
結果
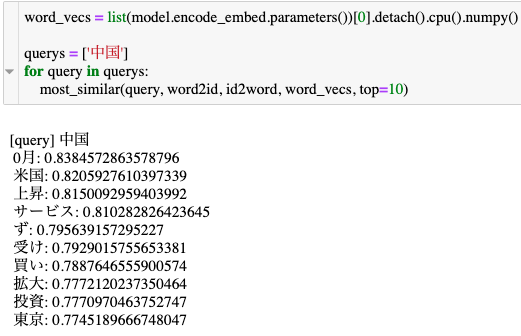
全体的に精度がいまいちで,Schedulerとか学習率とかを適切に設定する必要があります.
コードを整理してないんで,全体コードは整理してから公開します.
参考文献
[1] Distributed Representations of Words and Phrases and their Compositionality
[2] word2vec Parameter Learning Explained