目次
1. 背景
2. 目的
3. 手法
4. データの確認・前処理
5. 時系列解析
6. 結論
7. 感想
1. 背景
化学工学に関する研究で博士号取得後、化学メーカーで技術職をやっています。
学生時代から現在に至るまで、化学プロセスの数値シミュレーションを専門としており、プログラミング(C++, VB)や数値計算に関する知識・経験はありますが、統計学・ビックデータ解析・AI技術(機械学習・ディープラーニング等)といった最新技術に関する知識が不足していることを日々の業務の中で強く感じていました。
そんな中でアイデミーのオンライン講座の存在を知り、Aidemy Premium Planのデータ分析講座(3ヶ月)を受講するに至りました。
今回の記事では、3ヶ月の学習成果として、Facebook Prophetを使った時系列解析に挑戦した結果を紹介します。
2. 目的
自転車の貸出サービスの一種であるシェアサイクルは、ステーションのある場所ならどこでも自転車を借りて返却できることが特徴で、その利便性と、コロナ禍での三密を避けた移動手段として注目されています。
今回は、時系列解析ライブラリの一つであるFacebook Prophetを用いて、シェアサイクルの利用者数と平均利用時間を気象データから予測することが目的です。
3. 手法
3.1. 実行環境
今回の解析では、Google Colaboratoryを使用します。
Pythonのバージョンは3.7です。
3.2. Facebook Prophetについて
ProphetはFacebookが提供している時系列解析ライブラリで、一般化加法モデルと呼ばれる手法をとっています。
通常の時系列解析(ARIMAモデル、SARIMAモデル等)では、過去のデータと未来のデータの関係性をモデル化して(自己回帰)、予測を行います。
一方、一般化加法モデルでは過去と未来のデータの関係性を考慮せずに曲線をフィッティングして、その曲線を補外することで予測を行います。
Prophetを用いる利点としては、以下の3点があげられます。
- 機械学習や統計解析の知識がなくても簡単に実装できる
- 計算速度が早い
- 外部説明変数の追加が容易である
4. データの確認・前処理
4.1. シェアサイクル利用データ
シェアサイクルの利用データには、千葉市シェアサイクルオープンデータで公開されている、2018年度(2018年4月1日〜2019年3月31日)と2019年度(2019年4月1日〜2020年3月31日)までのデータ(csv形式)を用います
本データは下表に示すように、自転車毎の、利用日/利用された時間帯/利用時間/貸出ステーションの情報/返却ステーションの情報/利用回数から成ることがわかります。
表1. 2018年度のシェアサイクル利用データ




今回は日毎の利用者数と平均利用時間を予測するので、利用日と、自転車毎の利用回数と利用時間を抽出します。
利用者数は1日あたりの自転車毎の利用回数の合計、平均利用時間は1日あたりの自転車毎の利用時間の平均をとります。
以下は2018年度のデータを処理するコードです(2019年度のデータも同様に処理)。
data_share_cycle_2018 = raw_data_share_cycle_2019.iloc[:, [1,3,14]] # 2018年度のシェアサイクル利用データから利用日/利用回数/利用時間を抽出
data_share_cycle_2018.columns = ['Date', 'Utilization time', 'Number of use'] # カラム名の設定
data_share_cycle_2018 = data_share_cycle_2018.drop(range(0,20)) # 不要な行の削除
data_share_cycle_2018['Date'] = pd.to_datetime(data_share_cycle_2018['Date']) # 日付をdatetime型に変換
data_share_cycle_2018['Utilization time'] = data_share_cycle_2018['Utilization time'] / 60 # 利用時間の単位を分->時間に変換
次に、処理した2018年度と2019年度のデータを結合し、日毎に利用者数と平均利用時間を計算します。
data_share_cycle = pd.concat([data_share_cycle_2018, data_share_cycle_2019],axis = 0) # 2018年度、2019年度のデータの結合
data_share_cycle_user = data_share_cycle.groupby(['Date'])['Number of use'].agg('sum') # 1日あたりの利用回数の合計(延べ利用者数)を計算
data_share_cycle_user = data_share_cycle_user.rename('User') # カラム名の設定
data_share_cycle_time = data_share_cycle.groupby('Date')['Utilization time'].mean() # 1日あたりの平均利用時間を計算
data_share_cycle_time = data_share_cycle_time.rename('Average utilization time') # カラム名の設定
data_share_cycle = pd.concat([data_share_cycle_user, data_share_cycle_time], axis=1) # 利用者数と平均利用時間のデータを結合
print(data_share_cycle) # 画面表示
実行結果は以下の通りです。
表2. 2018〜2019年度のシェアサイクル利用者数・平均利用時間

4.2. 気象データ
気象庁HPから、千葉市の気象データ(csv形式)を取得します。
期間は2018年4月1日〜2022年3月8日、項目は平均気温、平均湿度、降水量の3つを指定しています。
表3. 2018年4月1日〜2022年3月8日の気象データ
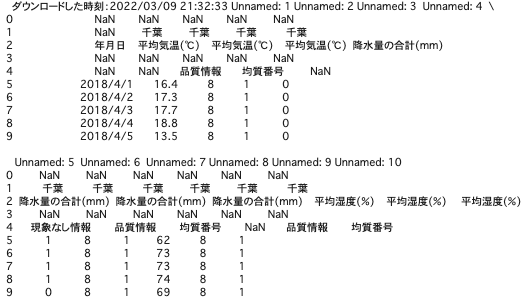
このデータから、品質情報や均質番号といった不要なデータを除き、平均気温、平均湿度、降水量の測定値のみを抽出します。
data_weather = raw_data_weather.iloc[:, [0, 1, 4, 8]] # 必要なカラムの抽出
data_weather.columns = ['Date', 'Temperature', 'Rainfall', 'Humidity'] # カラム名の設定
data_weather = data_weather.drop(range(0,5)) # 不要な行の削除
data_weather['Date'] = pd.to_datetime(data_weather['Date']) #日付をdatetime型に変換
data_weather = data_weather.set_index('Date') # 日付をインデックスに設定
data_weather = data_weather.astype('float64') # 気象データのデータ型をfloat64に設定
print(data_weather) # 画面表示
実行結果は以下の通りです。
表4. 2018年4月1日〜2022年3月8日の平均気温・平均湿度・降水量
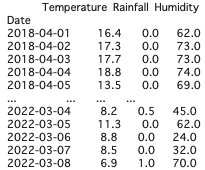
4.3. シェアサイクル利用データと気象データの結合
4.1、4.2で処理したデータを結合します。
また、Prophetでは時間を'ds'というカラムに保持させる必要があるため、'ds'カラムを作り日付を設定します。
data_sharecycle_weather = data_sharecycle.merge(data_weather, how='inner', left_index=True, right_index=True) # シェアサイクル利用データと気象データを結合
data_sharecycle_weather.insert(0, 'ds', data_sharecycle_weather.index) # 'ds'カラムを作り日付を設定
print(data_sharecycle_weather) # 画面表示
実行結果は以下の通りです。
表5. シェアサイクル利用データと気象データの結合
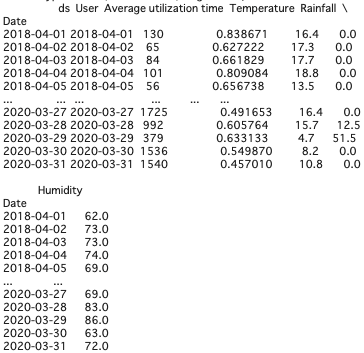
5. 時系列解析
5.1. データの挙動確認
データの前処理が完了したので、時系列解析を行います。
まず、データの挙動を確認するため、利用者数(User)、平均利用時間(Average utilization time)、平均気温(Temperature)、平均湿度(Humidity)、降水量(Rainfall)を時間に対してプロットします。
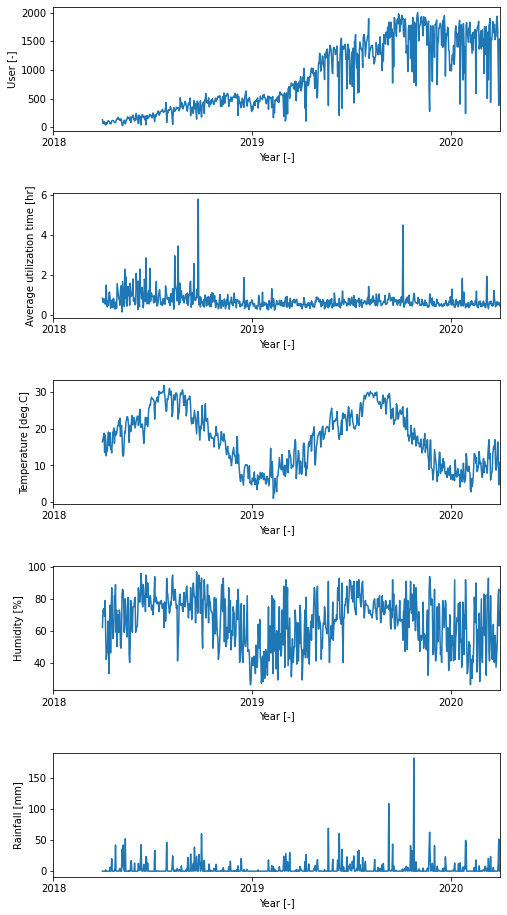
図1. シェアサイクルデータと気象データの可視化
これらのデータの関係性をグラフから読み取ることは困難なので、利用者数・平均利用時間を目的変数、平均気温・平均湿度・降水量を外部説明変数として、Prophetによる時系列解析を実施します。
5.2. シェアサイクル利用者数の時系列解析
5.2.1. 外部説明変数なしの場合
まず、外部説明変数なしで時系列解析を実施します。
Prophetでは、目的変数のカラム名を'y'に指定する必要があるため、利用者数(User)のカラム名を'y'に変更します。
次に、下記コードを実行してProphetによる時系列解析を行います。
from fbprophet import Prophet # Prophetのインポート
real_data_user = data_sharecycle_weather.copy() # データを複製
real_data_user = real_data_user.rename(columns = {'User': 'y'}) # 目的変数のカラム名を'y'に設定
model_user_u = Prophet() # 外部説明変数がない場合の時系列モデルの作成
model_user_u.fit(real_data_user) # 作成したモデルの学習
future_user_u = model_user_u.make_future_dataframe(periods = 707) # モデルによる予測期間を設定
forecast_user_u = model_user_u.predict(future_user_u) # モデルによる予測
model_user_u.plot(forecast_user_u) # 予測結果のプロット
model_user_u.plot_components(forecast_user_u) # トレンドや周期性の分析
実行結果は以下の通りです。
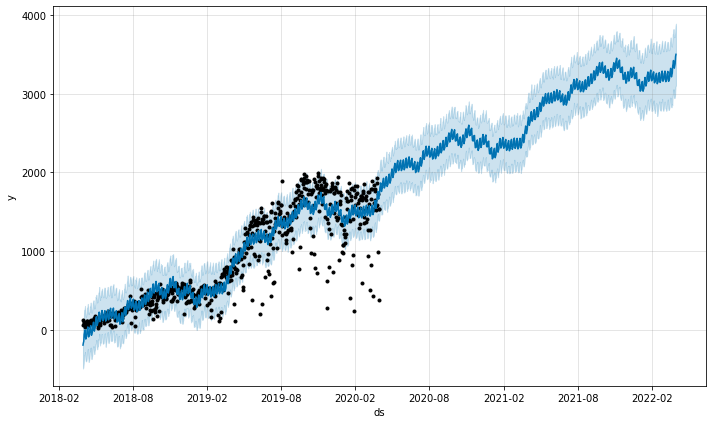
図2. 時系列解析によるシェアサイクル利用者数の予測(外部説明変数なし)
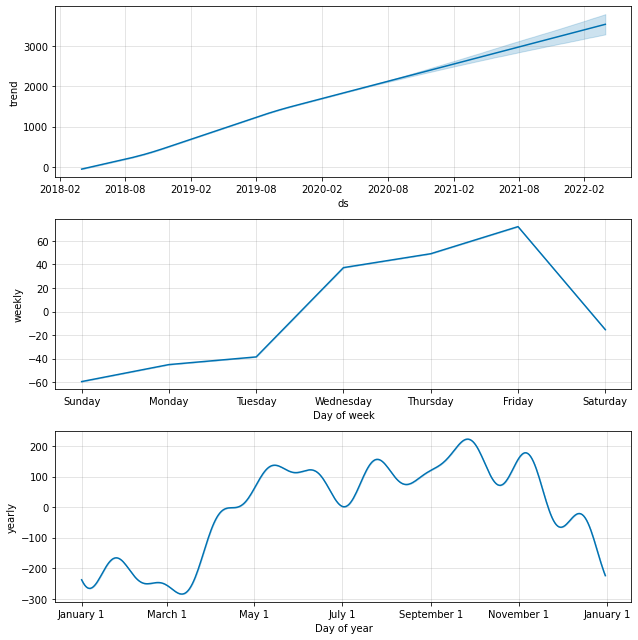
図3. シェアサイクル利用者数のトレンドと周期性(外部説明変数なし)
図2は利用者数の実測値とモデルによる予測値をプロットしたものです。
図3はシェアサイクル利用者数のトレンド(trend)と周期性(weekly, yearly)をプロットしたものです。
これらのグラフから、利用者数は単調増加の傾向にあり、この増加傾向をモデルは概ね再現できていることが分かります。
一方、利用者数の実測値が予測値から大きく外れるものも複数あるため、外部説明変数を追加することでモデルの予測精度が向上するか検討しました。
5.2.2. 外部説明変数ありの場合
まず、外部説明変数として、平均気温、平均湿度、降水量の3つ全てを導入してみます。
これは以下のコードにより実行できます。
model_user_thr = Prophet() # 多変量(温度、湿度、降水量)の時系列モデルを作る
model_user_thr.add_regressor('Temperature') # 温度を変数として追加
model_user_thr.add_regressor('Humidity') # 湿度を変数として追加
model_user_thr.add_regressor('Rainfall') # 降水量を変数として追加
model_user_thr.fit(real_data_user) # モデルの学習
future_user_thr = model_user_thr.make_future_dataframe(periods = 707) # 予測期間を設定
data_weather.insert(0, 'ds', data_weather.index) # 気象データに'ds'カラムを追加して日付を設定
future_user_thr = future_user_thr.merge(data_weather, on = 'ds').loc[:,['ds', 'Temperature', 'Humidity', 'Rainfall']] # 'ds'カラムをキーにfuture_user_thrとdata_weatherを結合
forecast_user_thr = model_user_thr.predict(future_user_thr) # 予測
model_user_thr.plot(forecast_user_thr) # 予測結果のプロット
model_user_thr.plot_components(forecast_user_thr) # トレンドや周期性の分析
実行結果は以下の通りです。

図4. 時系列解析によるシェアサイクル利用者数の予測(外部説明変数:温度、湿度、降水量)
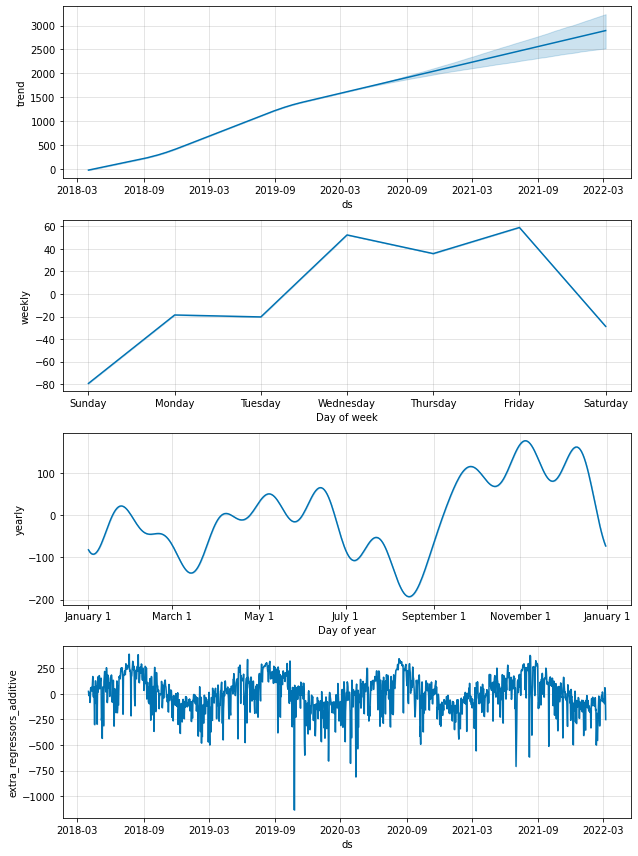
図5. シェアサイクル利用者数のトレンドと周期性(外部説明変数:温度、湿度、降水量)
本結果と、外部説明変数がない場合の結果(5.2.1)を比較すると、トレンドや周期性が異なっており、また外部説明変数の影響(extra_regressors_additive)が数百人単位であることが分かります。
さらに詳しく外部説明の影響を調べるため、予測モデルの評価指標として、二乗平均平方根誤差(RMSE:Root Mean Square Error)を計算して比較します。
5.2.3. 外部説明変数がない場合とある場合のRMSEの比較
RMSEの計算には、以下のコードを実行します。
from fbprophet.diagnostics import cross_validation # 交差検証関数
from fbprophet.diagnostics import performance_metrics # 性能評価関数
df_cv_user_u = cross_validation(model_user_u, initial = '365 days', period = '30 days', horizon = '365 days') # 外部説明変数がないモデルの交差検証
plot.plot_cross_validation_metric(df_cv_user_u, metric = 'rmse') # 外部説明変数がないモデルの日毎のRMSEををプロット
df_cv_user_thr = cross_validation(model_user_thr, initial = '365 days', period = '30 days', horizon = '365 days') # 外部説明変数があるモデルの交差検証
plot.plot_cross_validation_metric(df_cv_user_thr, metric = 'rmse') # 外部説明変数があるモデルの日毎のRMSEをプロット
performance_metrics(df_cv_user_u).mean(axis=0) # 外部説明変数がないモデルの全期間のRMSEの平均を計算
performance_metrics(df_cv_user_thr).mean(axis=0) # 外部説明変数があるモデルの全期間のRMSEの平均を計算
ここで fbprophet.diagnostics の 交差検証関数 cross_validation と 性能評価関数 performance_metrics をインポートしています。
plot.plot_cross_validation_metric 関数に cross_varidation 関数の出力である df_cv_user_... を引数として渡すことで交差検証の評価指標をプロットできます。
また、performance_metrics 関数に df_cv_user... を引数として渡すことで、MSE(平均二乗誤差)・RMSE(MSEの平方根をとったもの)・MAE(平均絶対誤差)・MAPE(平均絶対パーセント誤差)といった統計量を計算することができます。
実際にコードを実行すると、以下の結果が得られました。
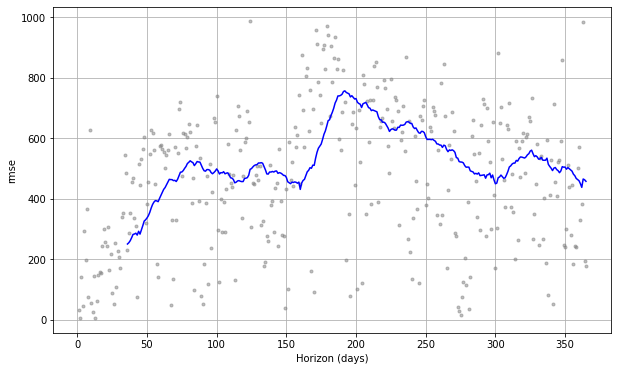
図6. 日毎のシェアサイクル利用者数のRMSE(外部説明変数なし)

図7. 日毎のシェアサイクル利用者数のRMSE(外部説明変数:平均気温、平均湿度、降水量)
図6と図7を比較すると、図7の方が日毎のRMSEの値が小さく、外部説明変数の導入によりモデルの予測精度が向上することを確認できました。
また、performance_metrics 関数により計算した全期間のRMSEの平均は、外部説明変数なしの場合は526.128274、平均気温・平均湿度・降水量を外部説明変数とした場合は438.714517でした。
平均気温・平均湿度・降水量の組み合わせを変えて、同じようにRMSEを計算した結果を下表に示します。
表6. 外部説明変数の組み合わせによるシェアサイクル利用者数のRMSEの変化
| 外部説明変数 | RMSE |
|---|---|
| なし | 526.128274 |
| 平均気温 | 444.985843 |
| 平均湿度 | 523.378159 |
| 降水量 | 493.331935 |
| 平均気温、平均湿度 | 431.475637 |
| 平均気温、降水量 | 439.15357 |
| 平均湿度、降水量 | 501.017269 |
| 平均気温、平均湿度、降水量 | 438.714517 |
表6から、平均気温・平均湿度・降水量の少なくとも1つ以上を外部説明変数に設定すると、外部説明変数がない場合に比べてRMSEが減少してモデルの予測精度が改善し、特に平均気温・平均湿度を外部説明変数にしたときRMSEは最も小さい値をとります。
なお、平均気温・平均湿度に加えて降水量を説明変数に追加するとRMSEが増加してモデルの予測精度が低下します。
これは、平均気温・平均湿度と降水量が違いに独立な外部説明変数ではないため(気温により飽和水蒸気圧が決定され、空気中の水分量(∝湿度)が飽和水蒸気圧を越えると雨が発生する)、過学習を起こしたことが原因の一つと考えられます。
実際に平均気温・平均湿度・降水量の相関係数を求めてみると、下表に示すように、平均気温と平均湿度、平均湿度と降水量の間に相関があることが確認できます。
また、実際のシェアサイクルの利用者数は降水量ではなく、降水の有無(降水量がゼロであるか否か)に左右されると考えられます。降水量には降水の有無以外の情報も余分に含まれており、予測精度を下げる要因になった可能性が高いです。
表7. 平均気温・平均湿度・降水量の相関係数
| Temperature | Rainfall | Humidity | |
|---|---|---|---|
| Temperature | 1.000000 | 0.068051 | 0.576584 |
| Rainfall | 0.068051 | 1.000000 | 0.398757 |
| Humidity | 0.576584 | 0.398757 | 1.000000 |
5.3. シェアサイクル平均利用時間の時系列解析
5.2と同様の手順で、平均利用時間の予測を行います。
5.3.1. 外部説明変数なしの場合
まず、外部説明変数がない場合のシェアサイクル平均利用時間の時系列解析を行った結果を下図に示します。

図8. 時系列解析によるシェアサイクル平均利用時間の予測(外部説明変数なし)
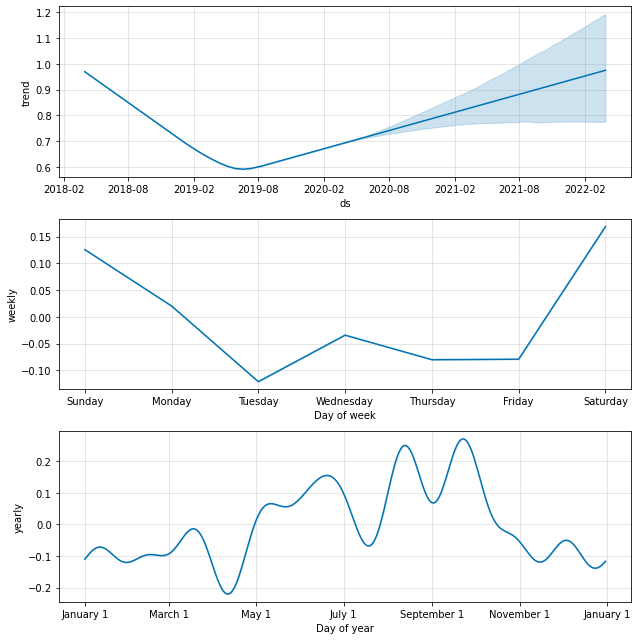
図9. シェアサイクル利用者数のトレンドと周期性(外部説明変数なし)
図8において平均利用時間の実測値と予測値が大きく異なるものが複数ありました。
また、図9からトレンドは下に凸のカーブを描いていること、weeklyの周期性において休日(Sunday, Saturday)の平均利用時間が平日よりも長いことが確認できます。
5.3.2. 外部説明変数ありの場合
次に、外部説明変数に平均気温・平均湿度を設定して、シェアサイクル平均利用時間の時系列解析を行います。
ここで、平均気温・平均湿度を外部説明変数に設定した理由は、5.2.3で平均気温・平均湿度・降水量が互いに相関しており、また降水量が特徴量として適切でない可能性が高いことが理由です。

図10. 時系列解析によるシェアサイクル平均利用時間の予測(外部説明変数:気温、湿度)
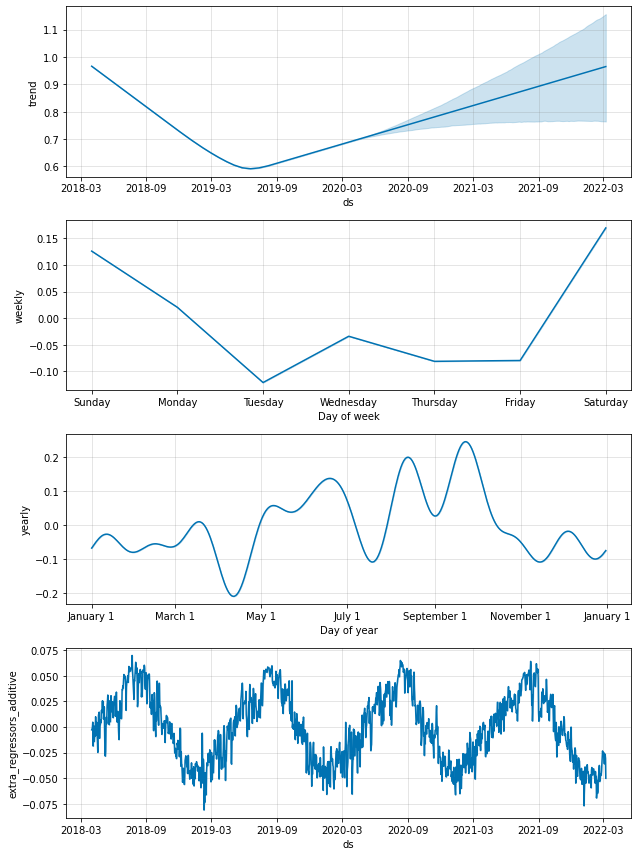
図11. シェアサイクル利用者数のトレンドと周期性(外部説明変数:気温、湿度)
本結果と5.3.1を比較すると、トレンドおよび周期性の差異は目視では分かりません。
また、外部説明変数の影響(extra_regressors_additive(縦軸の単位:hr))も、たかだか数分程度であることが分かります。
さらに詳しくモデルの予測精度を比較するため、RMSEを計算してみます。
5.3.3. 外部説明変数がない場合とある場合のRMSEの比較
外部説明変数がない場合と、外部説明変数に平均気温・平均湿度を設定した場合の日毎の平均利用時間のRMSEを下図に示します。
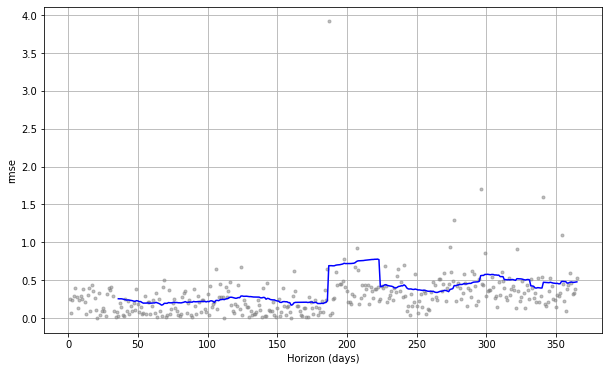
図12. 日毎のシェアサイクル平均利用時間のRMSE(外部説明変数なし)
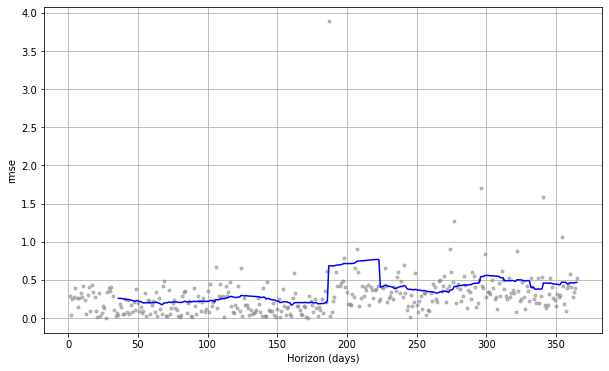
図13. 日毎のシェアサイクル平均利用時間のRMSE(外部説明変数:平均気温、平均湿度)
図12と図13はほぼ同じ形状のグラフです。
また、performance_metrics 関数により計算した全期間のRMSEの平均は、外部説明変数なしの場合は0.377797、外部説明変数に平均気温・平均湿度を設定した場合は0.371233であり、ほとんど違いがみられませんでした。
よって、気象データを外部説明変数に設定してもモデルの予測精度を改善できないことが分かりました。
6. 結論
シェアサイクルの利用者数と平均利用時間について、気象データ(平均気温・平均湿度・降水量)を外部変数として時系列解析を実施し、以下の結論を得ました。
- シェアサイクル利用者数のモデル予測精度は気象データを外部説明変数とすることで向上し、平均気温と平均湿度を外部説明変数としたときに最もモデルの予測精度が高くなる。
- シェアサイクル平均利用時間のモデル予測精度は、気象データを外部説明変数としても向上しない。
7. 感想
今回、Prophetを用いた時系列解析に挑戦してみて感じたことは、機械学習の数学的な理論やアルゴリズムを深いところまで理解していなくても、解析自体はできる、ということが分かりました。
しかし、一方で、様々な分析対象に対してケースバイケースで最適な手法を選択して分析し、結果を正しく解釈するためには、どのような選択肢(手法)があるのか、そして各手法の得手・不得手について深く理解する必要があるということも実感しています。
AI技術は発展途上にあるので今後も学習を継続して最新技術をキャッチアップするとともに、数学的な理論やアルゴリズムについても理解を深めたいと考えています。