1. 概要
Azureには機械学習用のサービスがあります。
-
Azure MachineLearning
前々から興味はあったのですが、Azureの認定資格にDP-100という資格を勉強する実践のチュートリアルで触る機会がありました。
その中のAzure Machine Learning Studioという機能で、ノーコードで機械学習の片鱗を体感することができましたので、MSや、その他ブログでよく紹介されている、ロジスティック回帰の分類予測の構築を通して、紹介させていただきます。
※DP-100は主に、Azure MachineLearningの理解度を試す資格なのですが、実はPythonベースの機械学習の最先端の技術情報の要点がまとまっている資格ですので、DP-100のラーニングパスを勉強するだけで、大変ためになる資格であると感じました。
※免責事項(必ず、ご一読ください)
本記事の情報により生じた、いかなる損害や損失についても、当社は一切の責任を負いかねます。
また、誤情報が入り込んだり、情報が古くなったりすることもありますので、必ずしも正確性を保証するものではありませんのでご了承ください。
2.回帰モデルの予備知識
回帰モデルの代表的な手法にロジスティック回帰、または重回帰というものがあります。
これらは、予測に影響を強く与える入力を知る、未知の値の入力に対するもっともらしい予測値を与える、という機能があります。
ロジスティック回帰は、重回帰分析とできることが非常によく似ていますが、
下記の様に比較すると、いくつか相違点があります。
| 適用範囲 | 重回帰 | ロジスティック回帰 |
|---|---|---|
| 出力される回帰式の形 | 直線(まっすぐ) | 曲線(なめらか) |
| 目的変数が確率変数 | 不可能 | 可能*1 |
| 目的変数が二値変数(分類) | 可能 | 可能(カテゴリ変数かつ確率変数のみ)*1 |
| 目的変数が多値変数 | 可能 | 不可能*1 |
| 分析可能な目的変数 | 順序変数 | 確率変数 |
| 多値目的変数の one-hot-vector化の要否 |
必ずしも必要ではない | 必要 |
ロジスティック回帰は、二値変数の回帰(分類) に用途が限定されますが、確率値を出力することが可能である、と言えます。
- *1 … 多値変数もone-hot-vector化すれば可能だが、各値ごとの説明変数のランキングを出力することになるため、結果の説明をするとき、煩雑になりやすい。
- *2 … ロジスティック回帰は目的変数の値域 0.0~1.0に回帰させるが、重回帰は値域 -∞~+∞の範囲で回帰させるため、回帰線の値が0%~100%の範囲外が出力される場合があり、傾向だけでなく、具体的な確率値を回帰線として出力したい場合はロジスティック回帰の使用を推奨する。
3.ロジスティック回帰の概要
ロジスティック回帰モデルは下記の様に表されます。
\sigma(\boldsymbol{x}) = \frac{1}{1 + \exp (-{ \boldsymbol{wx} })}
なお、この関数の形は下記の様な形となっております。(シグモイド関数)

(wikipediaより引用)
- ※注意点※
目的変数の値が切り替わるような(上記でいうと高さ0.5付近の回帰線の高さの)、説明変数の閾値相当の値が"どんな場合"でも逆算できる!と思われるかもしれませんが、説明変数が多変数の場合は、ロジスティック回帰分析でも重回帰分析も原理的にはできません。説明変数が1変数の単回帰の場合のみ可能です。
理由としては、複数x軸に対して、残差が1項(w0)しか存在しないため。
\boldsymbol{wx}=w_0+x_1w_1+x_2w_2+x_3w_3+…+x_nw_n
説明変数x1~xnの各バイアスは、回帰式では1項の重み(バイアス)「w0」に合計して計算されてしまうため、説明変数の閾値相当の値の逆算をする場合は、下記のように1変数に絞り込み、単回帰分析をする必要あり。(1変数づつの分析となり、とても手間がかかります。)
\boldsymbol{wx}=w_0+x_iw_i (i番の説明変数に絞り込み)
4. 構築の流れ
今回は、ロジスティック回帰による「予測」を構築します。
大まかな流れは下記の様になります。
- Azure Machine Learning Studioの起動
- デザイン
- ジョブの状態確認およびモデルのトレーニング
- モデルの予測精度の検証
- 推論のデプロイ
- 推論の実行
※なお、Azure Machine Leaningのコンピューティングインスタンスが既に、プロビジョンされ、起動されている前提で本記事を記載しております。
コンピューティングインスタンスの作成については、Azure Machine Learning Studio からGUIで作成できますので、下記の記事をご覧ください。
5. Azure Machine Learning Studioの起動
Azure Portalより、Azure Machine Learning Studioを起動します。

6. デザイン
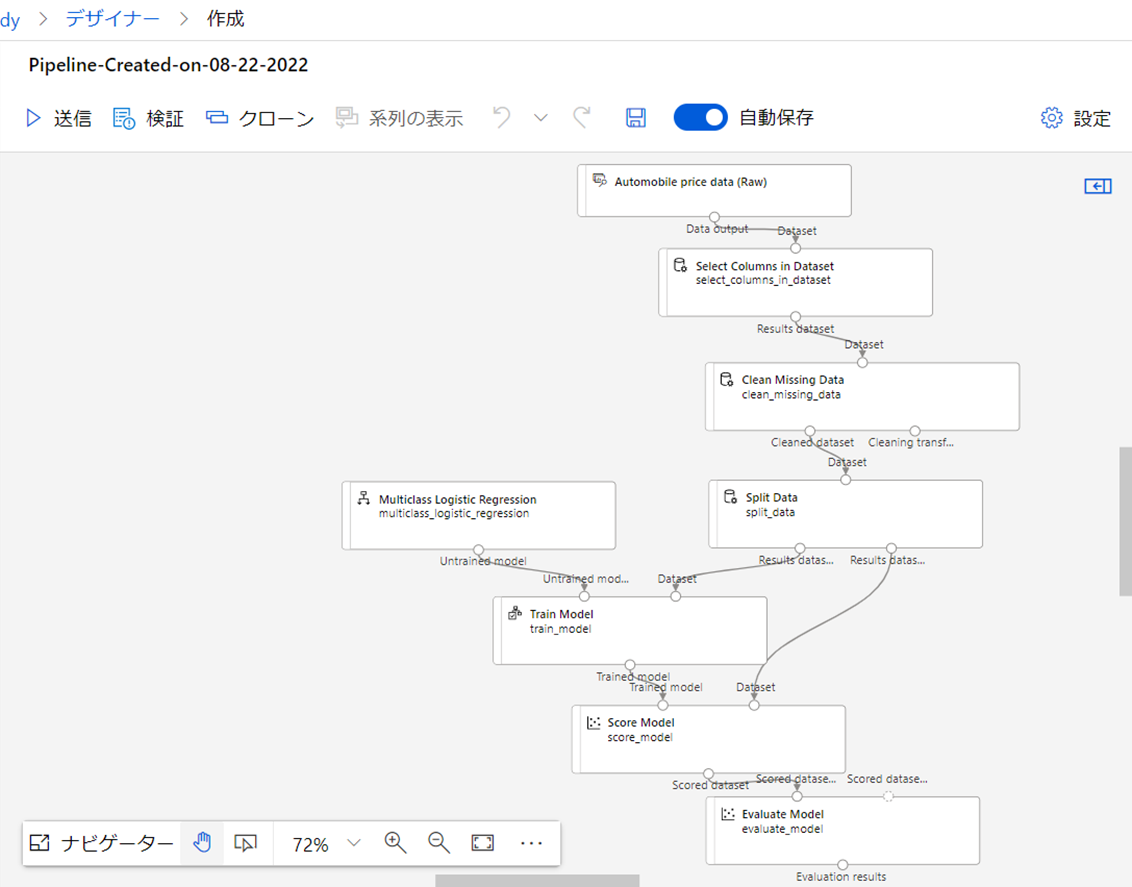
6-1 コンポーネント
下記のコンポ―ネントを配置して下記の画像のようにつなぎ合わせます。
おおよそ、15分ぐらいで作れました。
- Automobile price data(Raw)
- Select Columns in Dataset
- Clean Missing Data
- Multiclass Logistic Regression
- Split Data
- Train Model
- Score Model
- Evalute Model
6-2 基本操作
今回は適当なサンプルデータとしてAutomobile price dataを配置します。

必要な列を選定するため、Select Columns in Datasetを配置します。
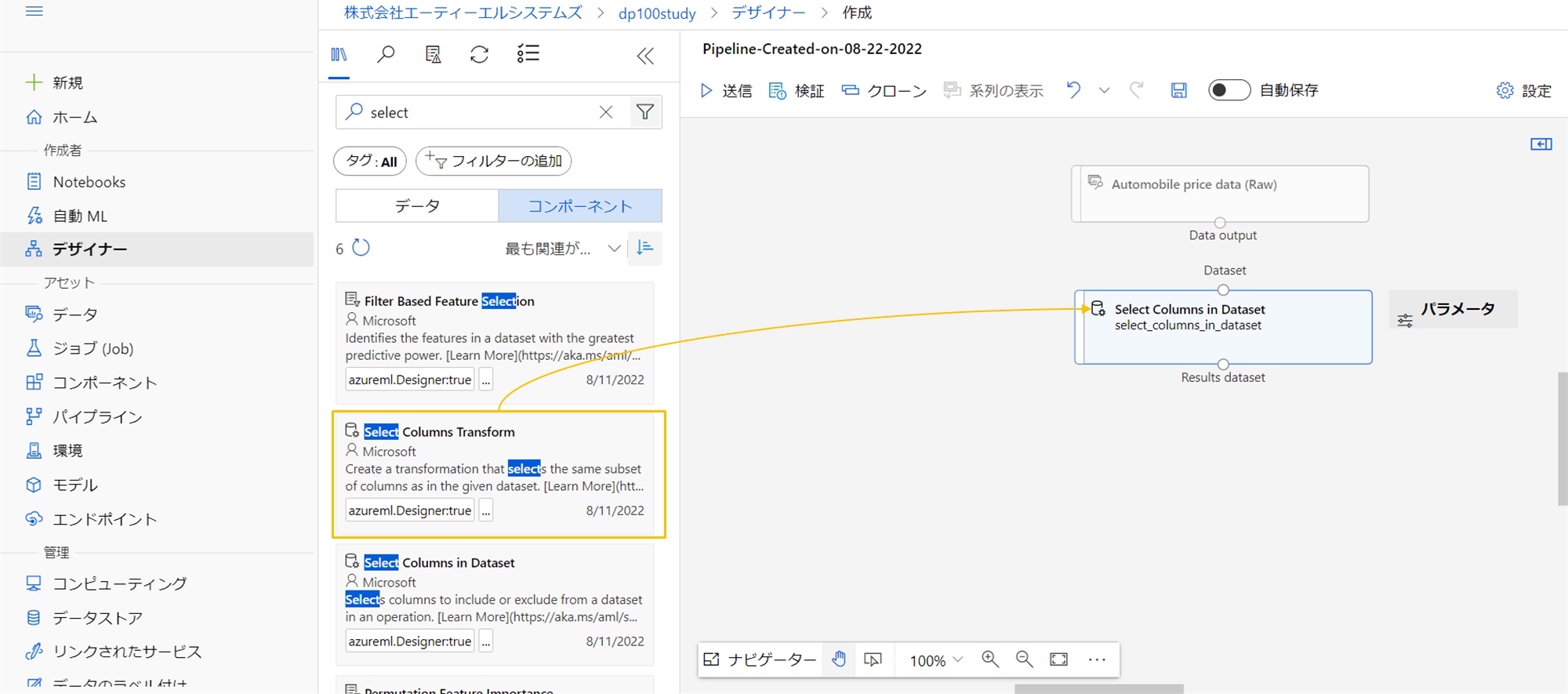
Data outputとDatasetをマウスのドラッグでつなぎます。
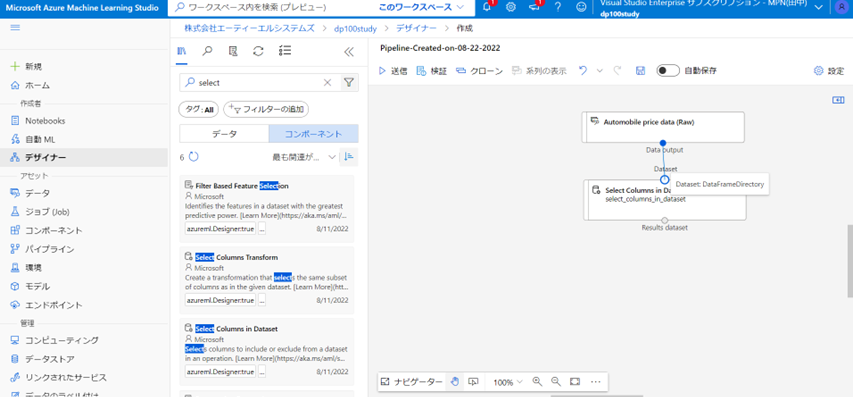
続いて、Clean Missing Dataを配置してつなぎます。

データを分割するため、Split Dataを配置してつなぎます。

今回はロジスティック回帰の多クラス分類を実装してみたいので、Multiclass Logistic Regression
をSplit Dataの隣に配置します。

Train Modelを配置し、Multiclass Logistic RegressionをSplit DataをそれぞれUntrained modelとDatasetにつなぎます。
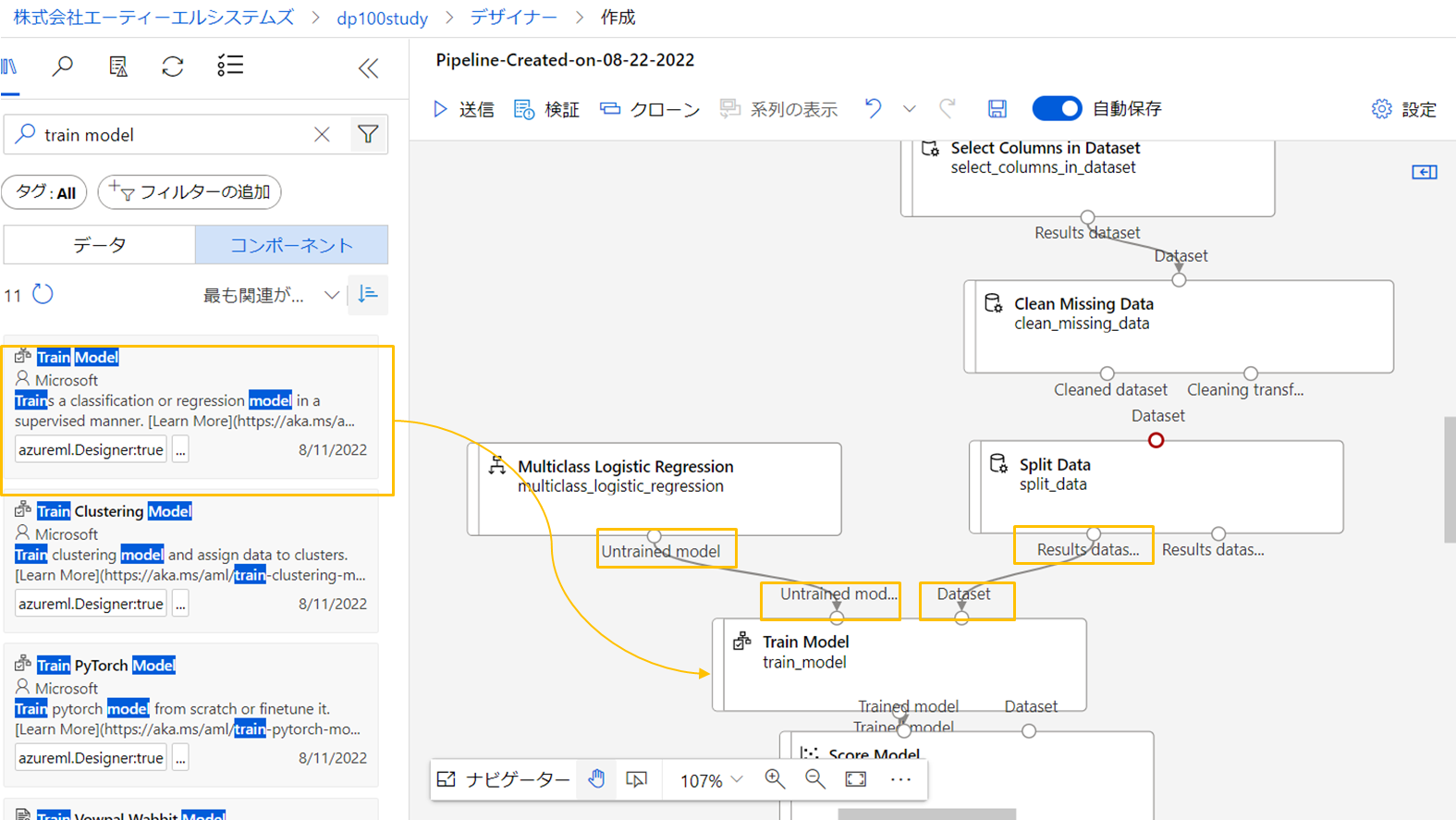
あとは、同様に残りのコンポーネントをつないでいきます。
- Score Model(Split Dataの1つ余った右側の出力を、ScoreModelの評価用に接続します)
- Evalute Model
7. 各パラメータの設定
デザインが終わったら、とりあえず、送信を押してみましょう。
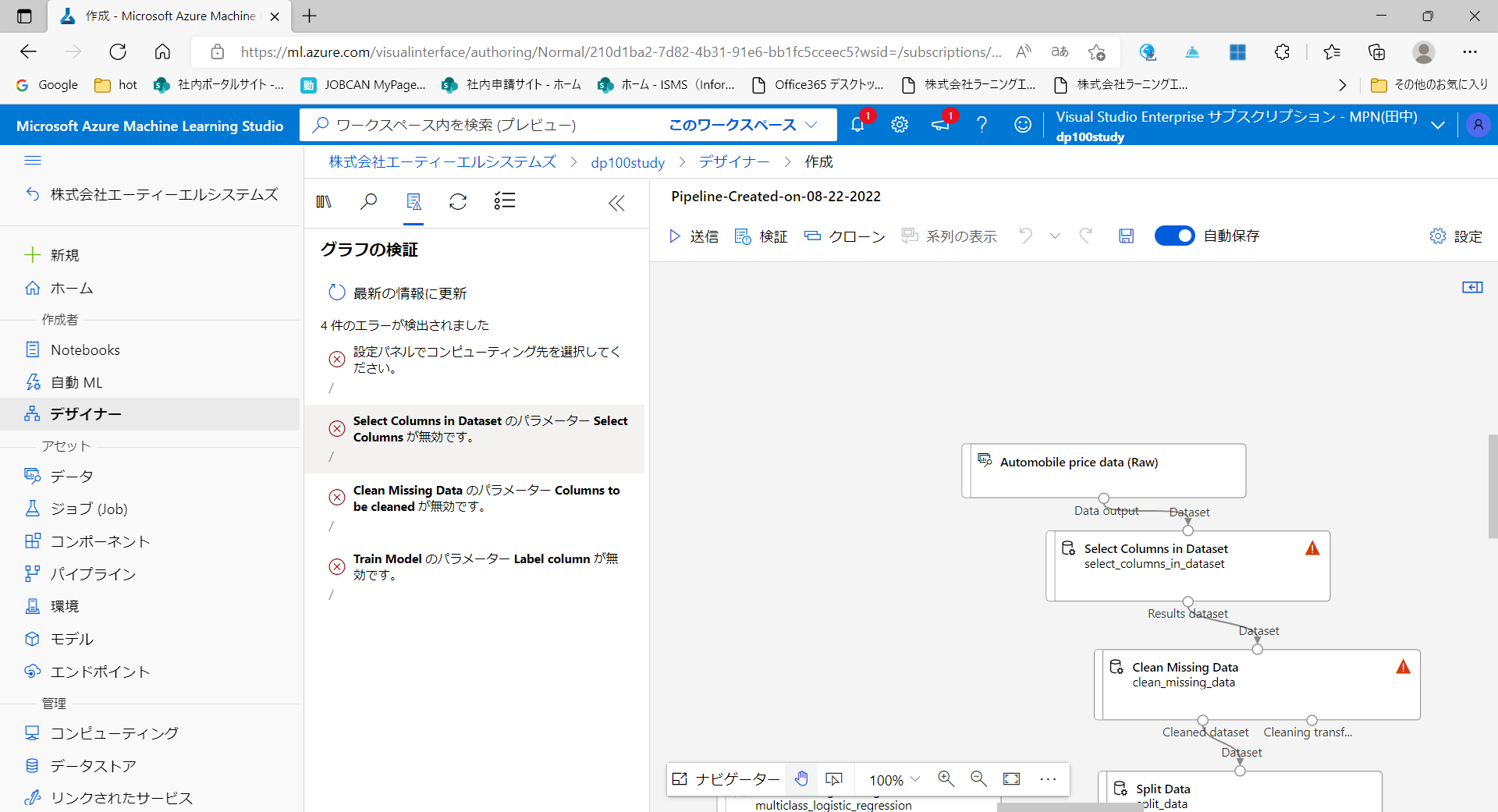
おやおや..エラーが出力されていますね...これらのエラーは、各コンポーネントの必要最低限の設定値を設定しないまま押すと出力されるものなので、以下の「!」の付いているコンポーネントにそれぞれ設定をしていきましょう。
-
Select Columns in Dataset
...まず、目的変数を決めていませんでしたね!
Automobile price dataをダブルクリックすると、右からペインが出てきて、出力が見えると思いますので、そこをクリックします。
プレビューする縦棒グラフのボタンがあるので、これをクリックします。

目的変数として二値のカテゴリ変数が望ましいので、今回は、例としてdieselかgasの二値となっているfuel-typeに決めておきます。
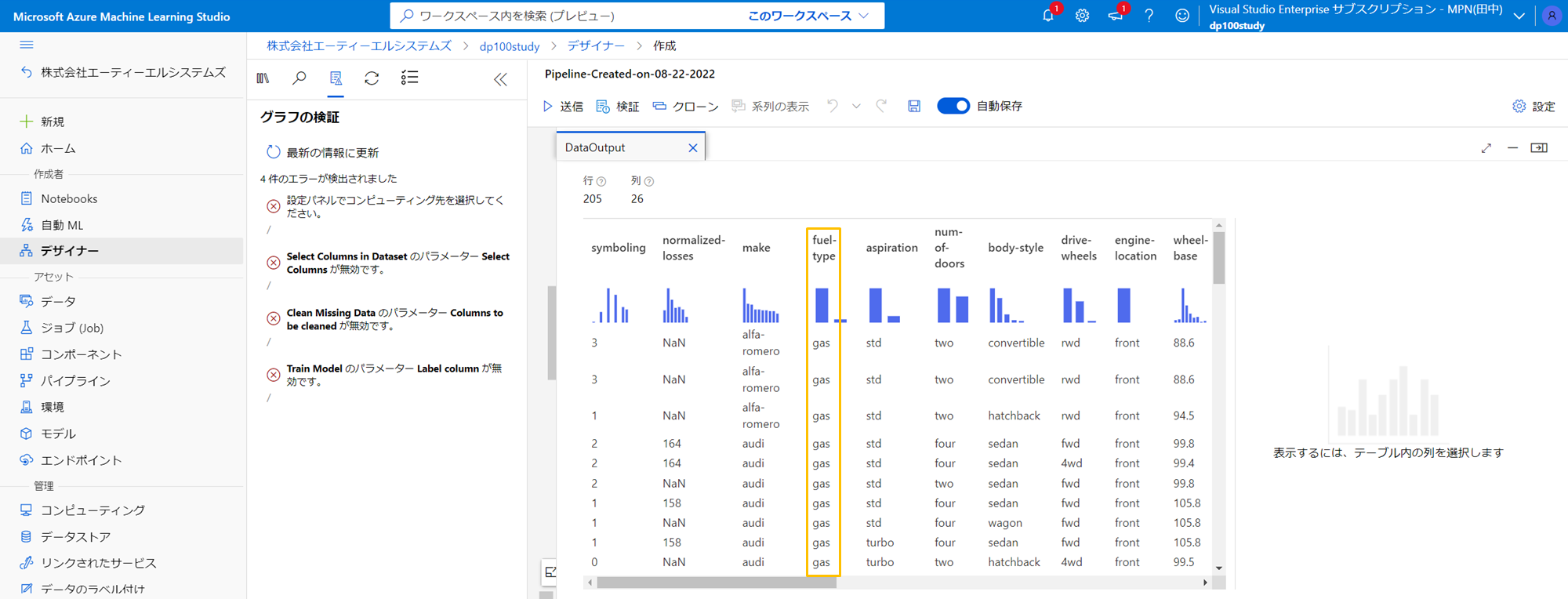
ペインをいったん閉じて、Select Columns in Datasetをダブルクリックします。すると、以下のように表示されるため、下記順序でプルダウンメニューから、目的変数fuel-typeと、いくつかの適当な説明変数を選択します。(画像で隠れていますが + ボタンで列を追加できます。)

保存を押します。

-
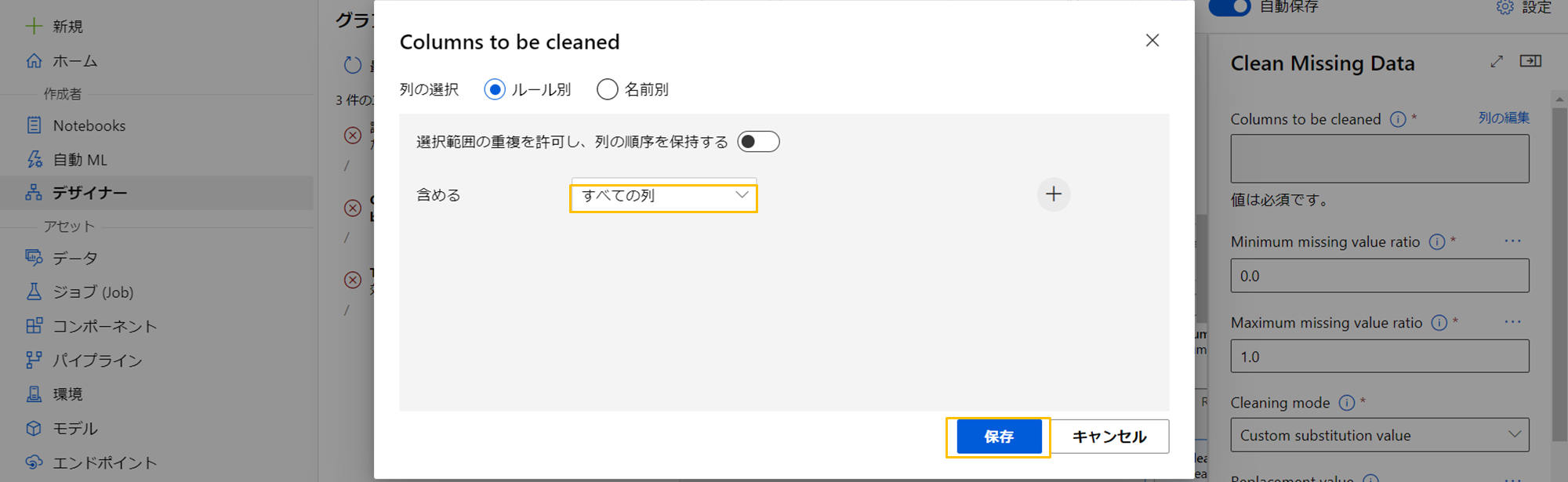
Clean Missing Data
あと、欠損値の除去すべき列の設定もしていないままでした。すべての列の欠損値を除外するようにしましょう。(おそらく欠損値が紛れているとエラーが起こると思われます。)
-
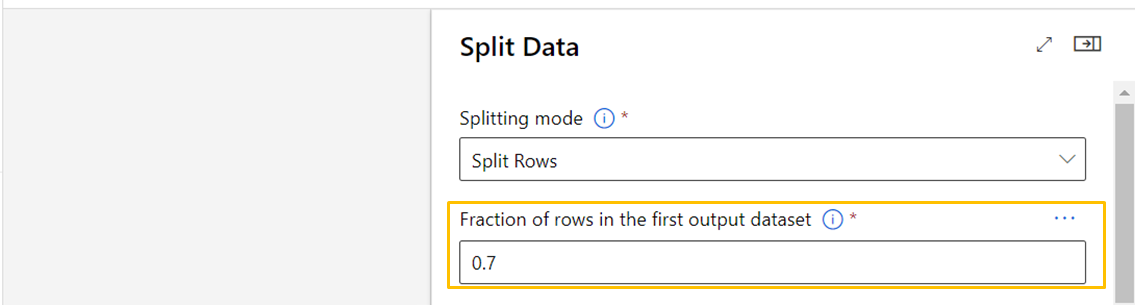
Split Data
こちらはデータをトレーニングデータ/テストデータをどの割合で分割するかを設定できます。一般的には0.7:0.3がよく使用されるため、0.7を設定します。
-
Train Model
最後に、何を回帰モデルを回帰させるのかを決める必要があるので、fuel-typeに設定します。

-
設定パネル
歯車ボタンがあるので、そこでコンピューティング先を設定できます。今回は、事前に作成したdp100studyというコンピューティングインスタンス(起動済み)を選択します。

-
その他コンポ―ネント
それぞれのコンポーネントで、望ましい設定がされているかの確認は省略します。(このデフォルト設定でもとりあえず動きます。)
7-3 送信
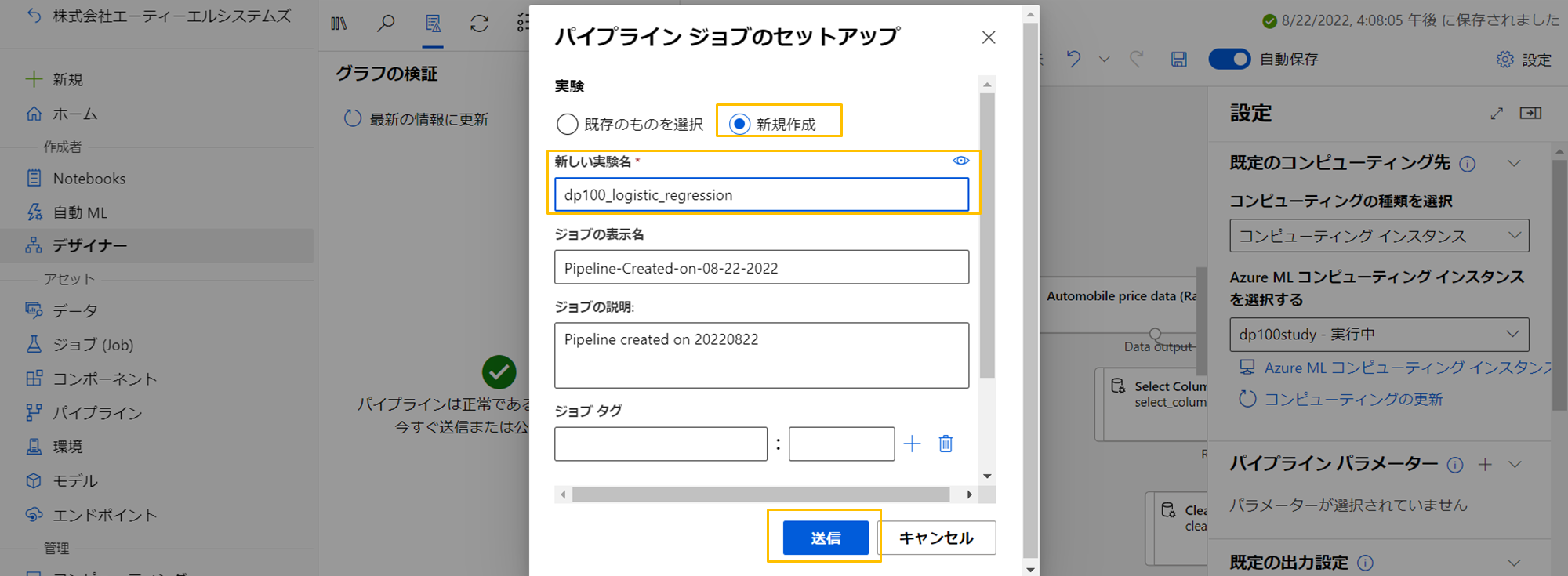
送信ボタンを押すと下記のダイアログが出てきます。今回初めての実験なので、任意の実験名を付けて、送信しましょう。
※Azure Machine leaningは、学習や推論をそれぞれジョブという単位としており、それらの集合を実験と括って管理しています。
8. ジョブの状態管理およびモデルの予測精度の確認
8-1 ジョブの状態管理
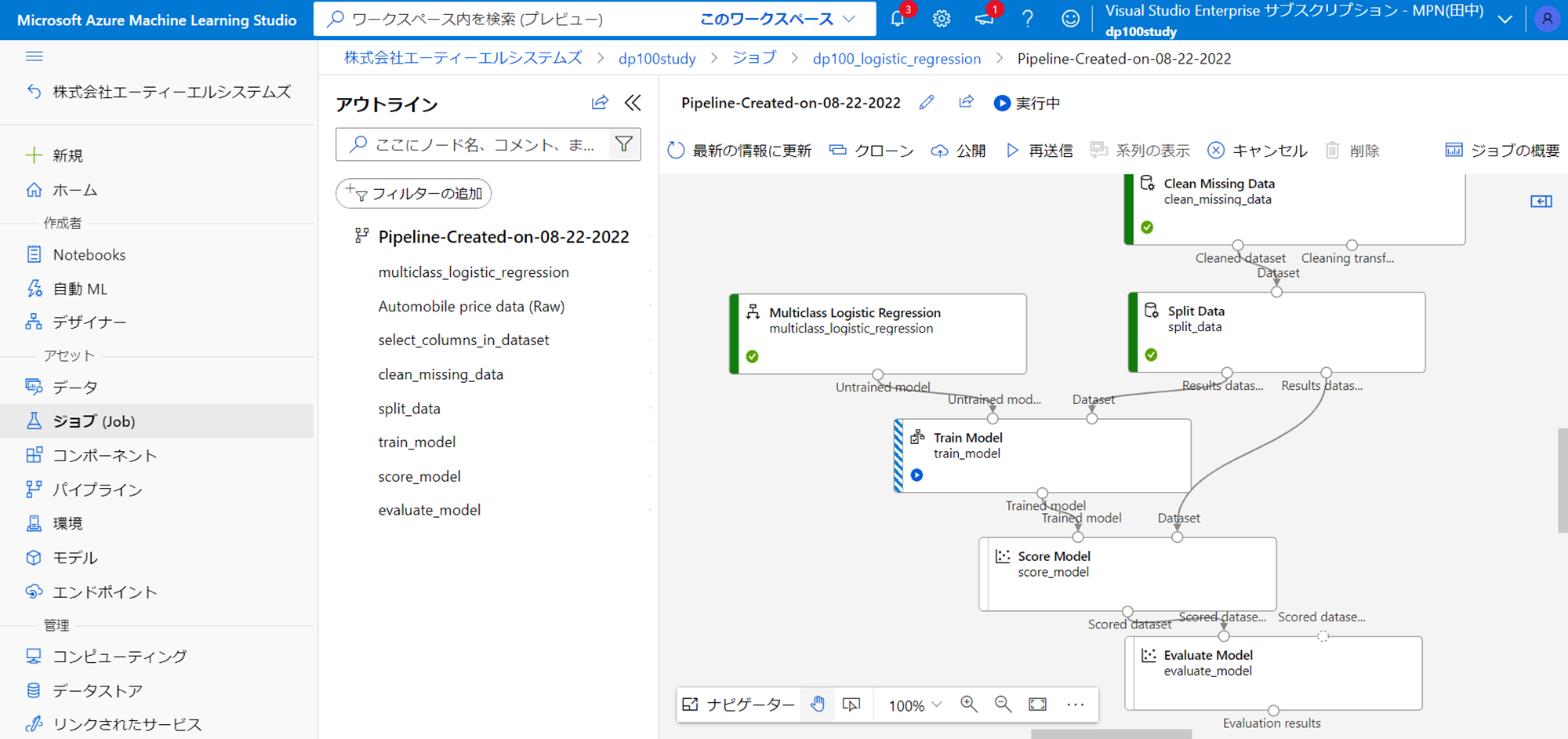
左のキューに送信済みジョブと表示されたので、ジョブがどうなっているか、ジョブの詳細をクリックしてみてみましょう。

トレーニングジョブが正常に実行されているようですね。(青の車線がかかっているコンポーネントが今実行されている箇所です。)
モデルの評価(Evalute Model)が終わるまで、気長に待ちましょう。(^^)
無事終わったようです。Score Modelをダブルクリックして開きましょう。
8-2 モデルの予測精度の確認
Evalute Model のメトリックタブを開きます。

Overall_Accuracy(全体正解率)が0.8834であるので、おおむねまあまあな精度のモデルができたかな、と思います。
また画像を開くと、再現率などを確認するための混合行列のヒートマップを確認できます。
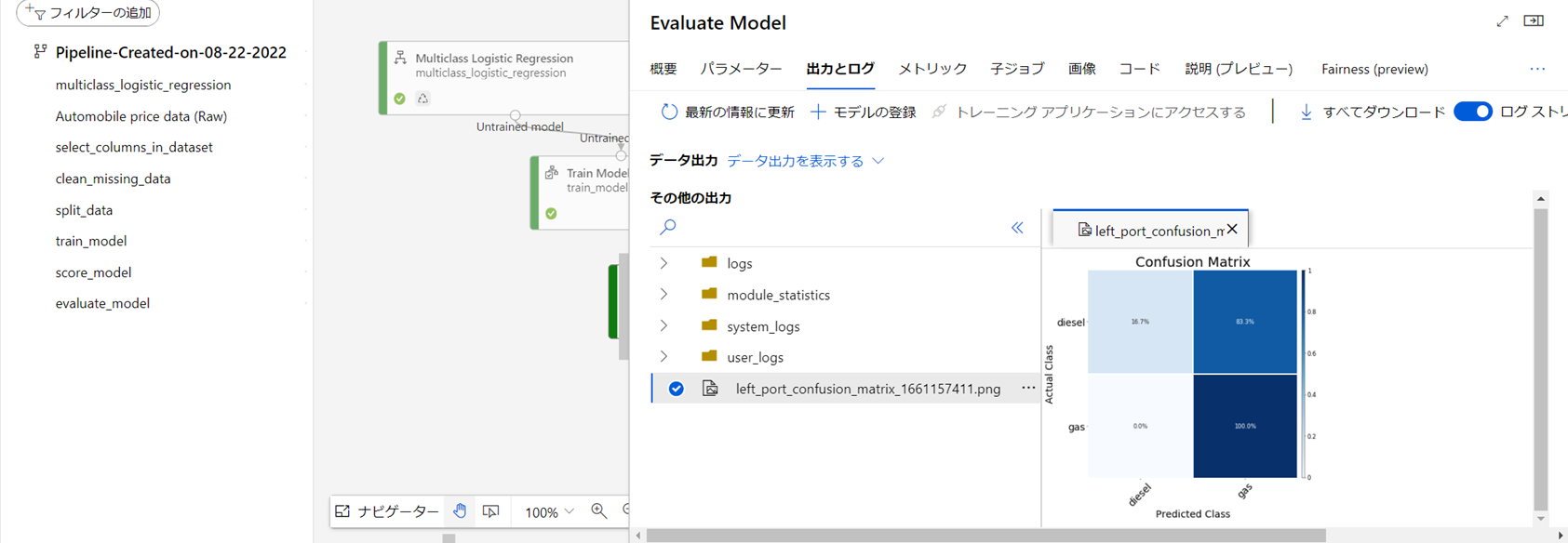
gasをgasと100%予測できているようですが、dieselは83.7%はgasと誤識別するモデルのようです。dieselのデータが少ないのかもしれません。
※Score Modelを開いたところ、std_log.txtでなにやらPythonのエラーが出力されておりましたので、後日調査しようと思います。

9. 推論のデプロイ
ジョブの画面の上部メニューの推論パイプラインの作成をクリックします。
今回はデプロイまでの大まかな流れの解説なので、構造が簡単な「バッチ推論パイプライン」を作成してみます。

10. 推論の実行
トレーニングモデルより、自動でパイプラインが生成されます。
最後に送信ボタンを押して、実験名は、分かりやすい名前を付けましょう。

「ジョブの詳細」をクリックして動作確認をします。正常にロジスティック回帰モデルによる分類予測が動いているようですね。(トレーニングデータだから当たり前ですが)

11. 最後に
実は、本記事の大まかな各ステップは、MSLearnや、Microsoftも公式ドキュメントでチュートリアルに、より詳細に紹介されています。
- [演習 - Azure Machine Learning デザイナーを使用して回帰を調べる](https://docs.microsoft.com/ja-jp/learn/modules/create-regression-model-azure-machine- - チュートリアル: デザイナー - コードなし回帰モデルをトレーニングする
私の所感ですが、チュートリアルを実際にやってみると理解がより早く深まるような感じでした。
※以下、個人の感想です。
触った感じ、sparkネイティブな感じではなかったので、次回は、sparkを使っているAzure Databricks(DP-100にも少し出ます)や開発環境に関する記事について執筆してみようと思います。
最後まで読んでいただき、ありがとうございました!
余談ですが、弊社はfacebookもしております!
