はじめに
2018年2月よりAlexaスキル開発に着手し、3月にめでたくスキルを公開、現在二作目のスキルを開発中です。そこで、開発時に工夫した点などを簡単に紹介したいと思います。ちなみにスキル開発は、仕事上の開発ではなく趣味の範囲での開発です。
参考までに私の経験値は以下のとおりです。同じような境遇?の人や、これからスキル開発を始める人に、この記事が参考になれば幸いです。
- Alexaスキル開発 ⇒ 初めて
- Node.js ⇒ 初めて
- JavaScript ⇒ 初めて
- AWS ⇒ 初めて
- ソフト開発経験 ⇒ あり(本業です)
「初めて」が多いですが、経験値と、皆さんがネットで公開してくれている貴重な情報を頼りに、なんとかなるレベルです。それと、過去に仕事で音声合成エンジンを利用したソフト開発経験が数年ほどあります。
発話フローの設計
スキル開発では、どのような発話の流れを構築するかが重要です。私の場合、Google Sheetsを使って以下のようなドキュメントを書きました。
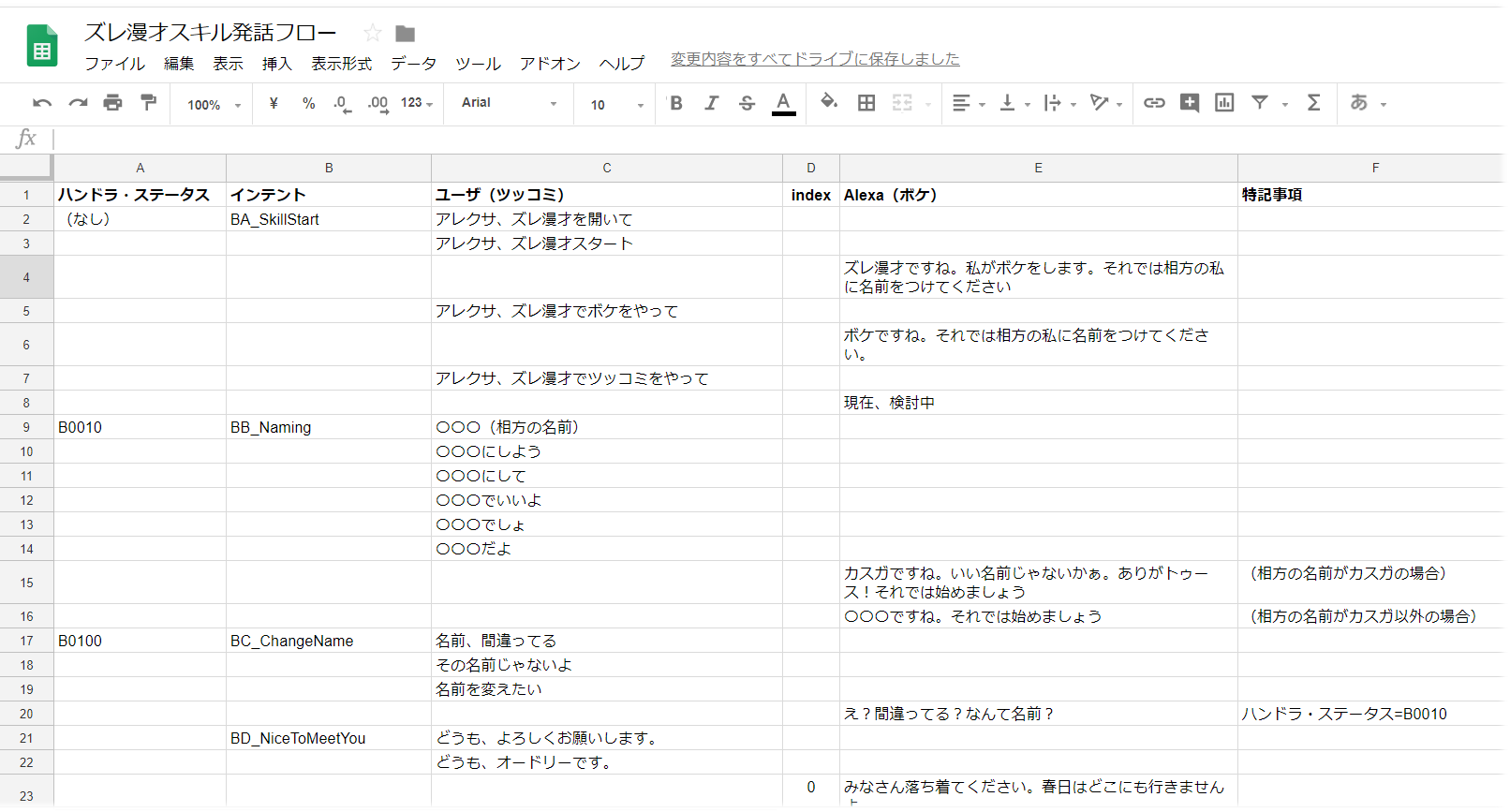
画像は開発段階のものです。仕事ではないので、自分がわかればいい範囲の記述ですが、インテント名に対するユーザーの発話パターンと、それに対するAlexaの発話内容を記述しています。
発話フローが複雑になればなるほど、この手の資料で十分に検討する必要がありますね。
誤読への対応
日本語音声合成エンジンの宿命「誤読」は、避けては通れないものです。私が過去に利用したことがある、いくつかのエンジンは、いずれも「読み上げ辞書」なるもの(IMEで言うと単語登録みたいなもの)を作成することができたのですが、現在公開されているAlexaの仕様には、そのような機能は存在しません。
可能な範囲でなるべく誤読を避ける方法の一例として、私は次のような方法で対応しています。
以下のように、駅名のスロットを作成したとします。この例では「古淵駅」は「コブチエキ」が正しい発話ですが、現在のAlexaは「フルブチエキ」と読み上げます。
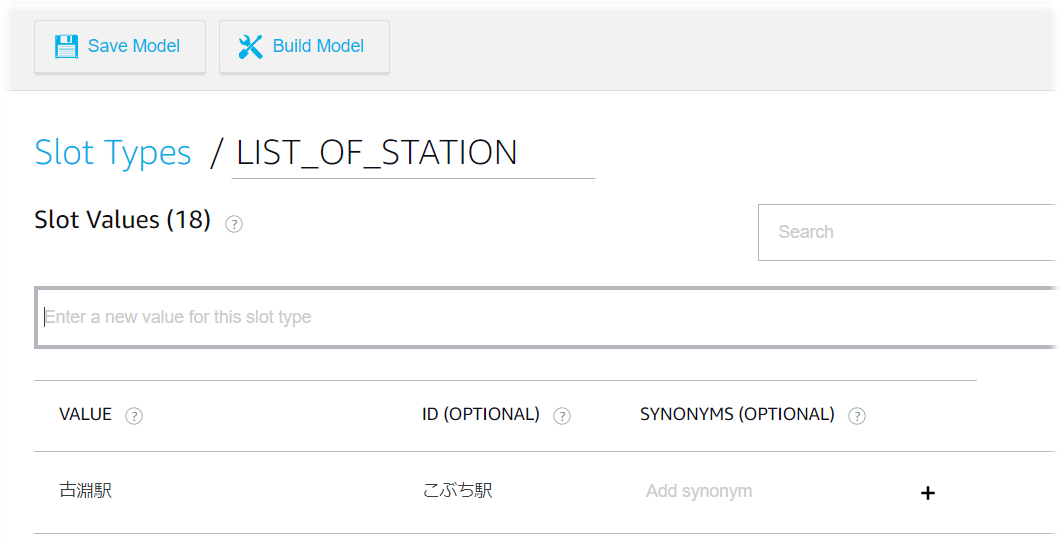
そこで、ID(OPTIONAL)に、正しく読み上げるための文字列を定義して、その文字列を発話するように実装します。以下は、インテントのrequestから定義した値を取得するコード例です。
const Station = this.event.request.intent.slots.Station
// Alexaが認識した文字列。この文字列を発話することが多いと思われる。
const alexaSpeech = Station.value;
// VALUEの値はこれ
const value = Station.resolutions.resolutionsPerAuthority[0].values[0].value.name;
// IDの値はこれ。これを発話して誤読を避ける。
const speech = Station.resolutions.resolutionsPerAuthority[0].values[0].value.id;
そもそも、IDの使い方として問題ないか不明ですが(問題ないと思っていますが)、お気づきの点があれば、ご指摘頂けると幸いです。
感じたことなど
正直なところ、この部分だけの記事が書けそうですが、Qiitaの主旨からちょっと外れるので簡潔に。あくまで私感です。
- 現在、言語が日本語の場合、アクセントがつけられません。個人的にはかなり残念です。Amazonにリクエストし開発部隊にエスカレーションする旨の回答を頂きました。
- 「スマートスピーカーは、あれば便利だよね」は、健常者視点の言葉。障がいを持った人や、お年寄りなど、体の自由がきかない人たちには生活必需品になる可能性を秘めている。
- 見た目のわかりやすさ、デザイン性が高くなると、音声(文章表現)だけで伝えるのは難しくなる傾向にある。
- 最近のWEBページはデザイン性の高いものが多い。しかし、WEBアクセシビリティ規格に真剣に対応したWEBサイトは数少ない(せいぜい文字の大きさを変えられるぐらい)。
- これからの時代、「スマートスピーカーが読み上げやすい情報提供」が求められると思う。
- スマートスピーカーの登場で、情報のバリアフリー化(アクセシビリティの向上)機運がもっと高まればいいなと思う。
スキル開発者の皆さん、不具合報告など建設的な意見をAmazonへ報告して、日本語上手なAlexaに育てていきましょう。