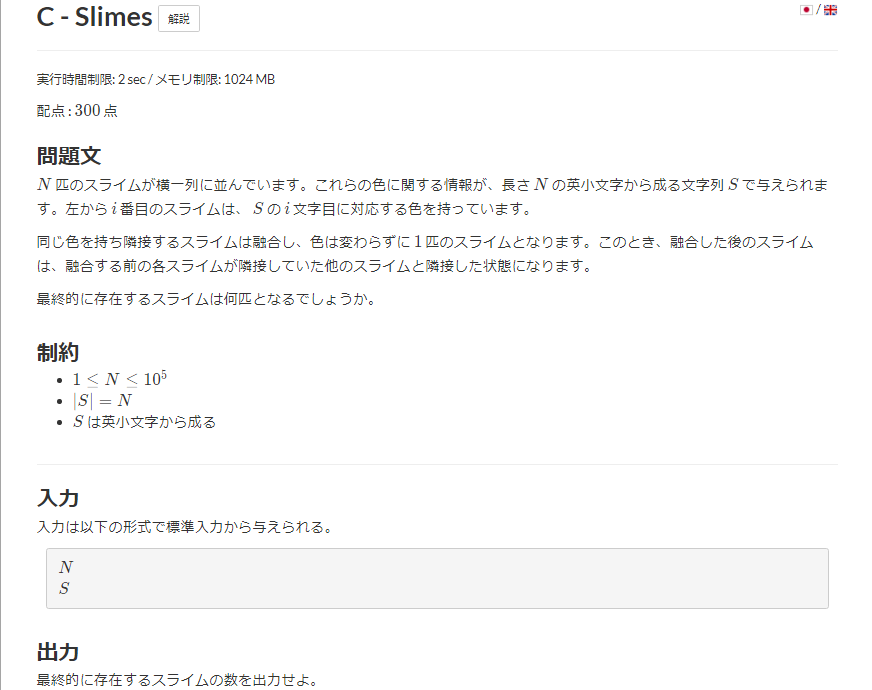
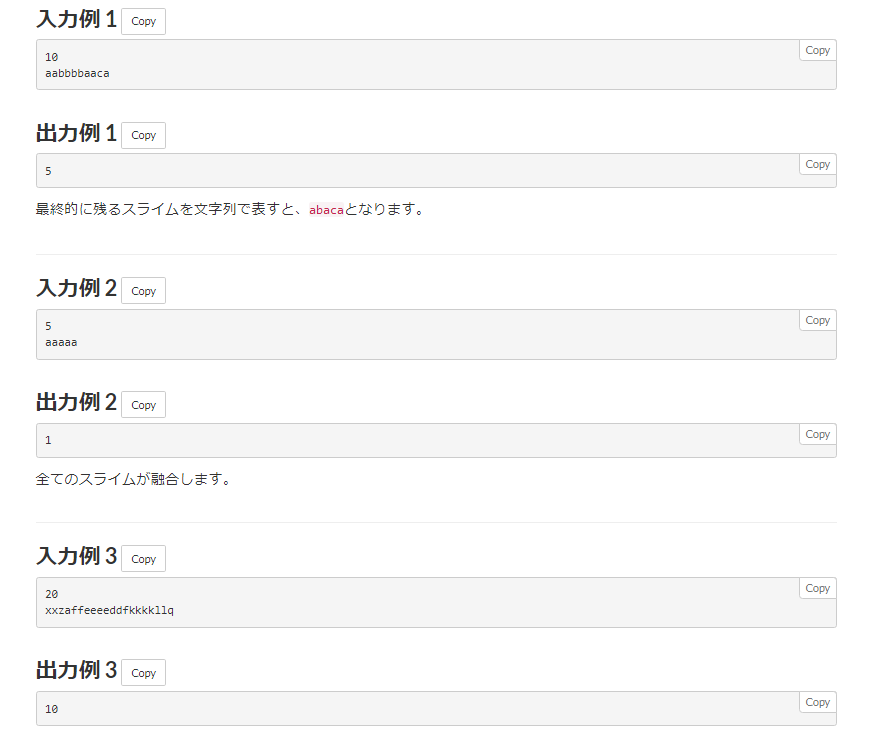
たぶん、そのまま書けば行ける。
イメージとしては S の中から重複をなくした
スリムな文字列を作り直し、その長さを応える
abc142c_r1.py
N = int(input())
S = list(input())
s = S[0]
if N == 1:
print(1)
else:
lis = [s]
for i in range(1,N):
if s != S[i]:
lis.append(S[i])
s = S[i]
print(len(lis))
以下の記述でも OK
abc142c_r2.py
# 重複要素をカウント
def solv1():
N = int(input())
S = input()
num =""
cnt = 0
for s in S:
if num == s:
cnt += 1
num = s
return N-cnt
# 非重複要素をカウント
def solv2():
N = int(input())
S = input()
num =S[0]
cnt = 1
for s in S:
if num != s:
cnt += 1
num = s
return cnt
# print(solv1())#35ms
print(solv2())#31ms
やっていることは、S の整形をせずに、
重複、非重複部分だけをカウントするやり方。
このくらいサクッと出来ないとと言われると耳が痛いが、
冒頭の記述の方が楽で早く、正確に書ける気がした。