はじめに
個人的に面白い問題だったので、
いくつかアプローチを試してみました。
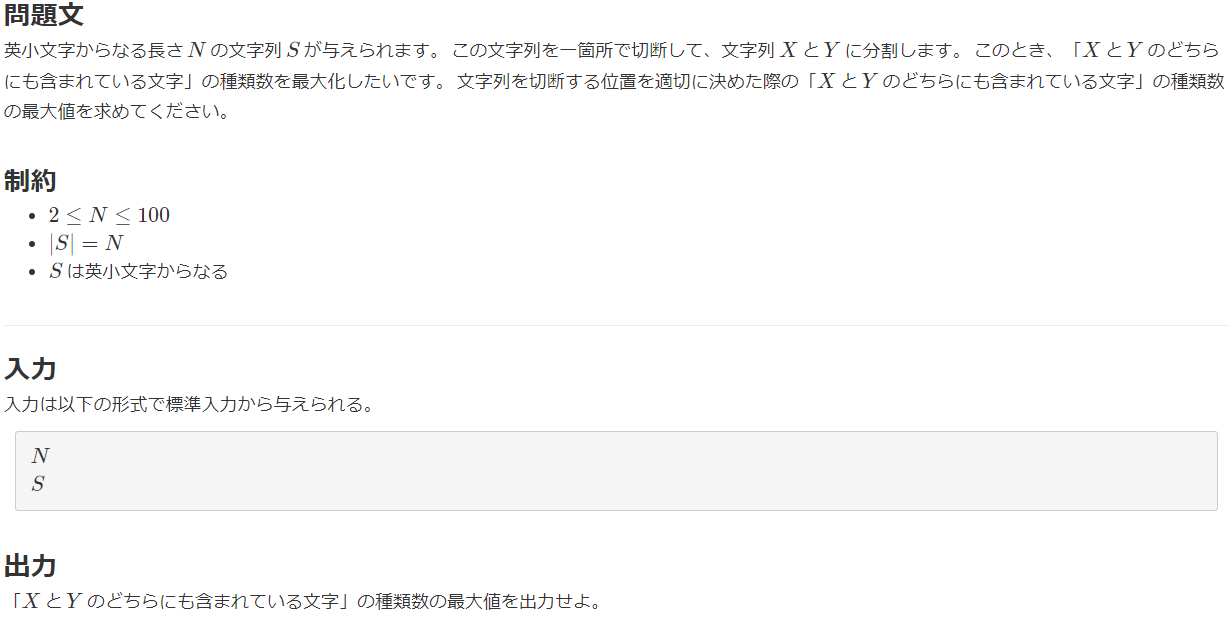
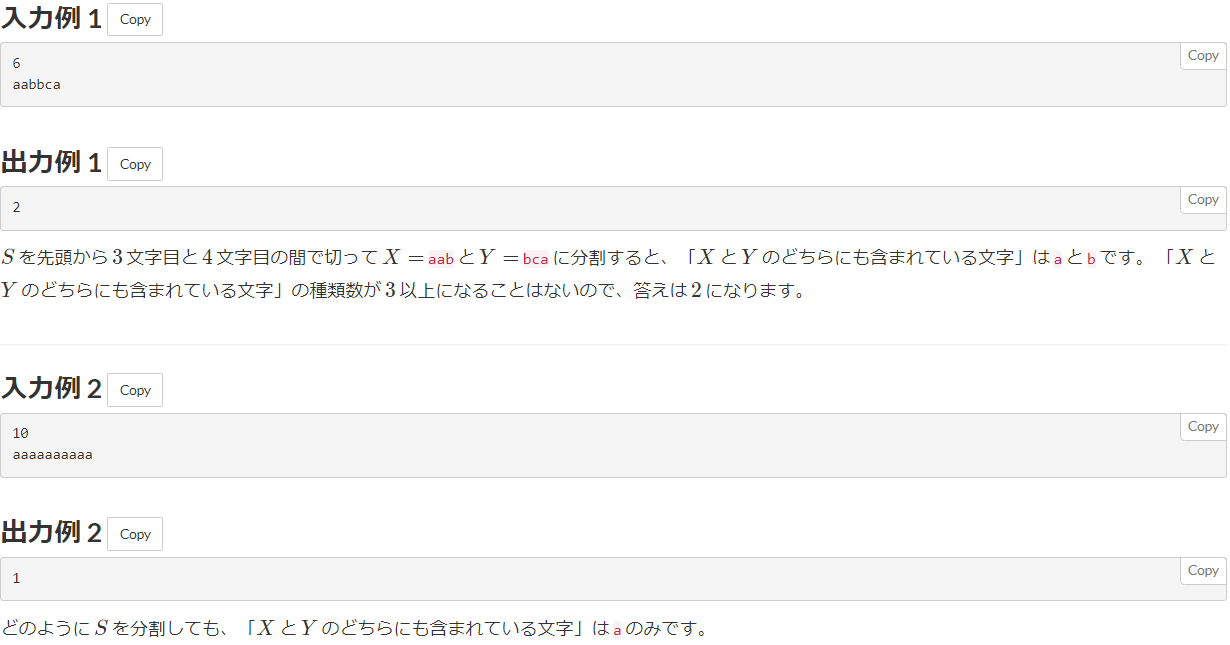
問題
アプローチ 1: for + set
step 1:文字を分割する境界線を for 文で動かしていきます。
step 2:区切った文字列を set に放り込み、重複なしの文字列に分解します。
step 3:両者で同じ文字がないか for 文で確認します。
step 4:境界線の位置別にカウントの最大値を更新
abc098b.cpp
#include <iostream>
#include <set>
using namespace std;
int main() {
int N; string S; cin >> N >> S;
set<char> A;//分割した文字列を格納する箱
set<char> B;//分割した文字列を格納する箱
int ans = 0;
for (int i = 0; i < N-1; i++) { //step 1 :文字を分割する境界を i で回す
for (int n = 0; n <= i; n++) //step 2:区切った文字列を set にブチ込み
A.insert(S[n]);
for (int m = i+1; m < N; m++)//step 2:区切った文字列を set にブチ込み
B.insert(S[m]);
int cnt = 0;
for (auto x : A) { //step 3:両者で同じ文字数をカウント
bool flag = false;
for (auto y : B) {
if (y == x) {
flag = true;
break;
}
}
if (flag)
cnt++;
}
ans = max(ans, cnt); //step 4:境界線の位置別にカウントの最大値を更新
A = {}; B = {};//各箱を都度空にする
}
cout << ans;
return 0;
}
//AC 36ms;
step 3 の簡略化を目指す
contain :対応バージョン C++20~
有識者の解説に感謝です。
但し、2020/8/26 現在 c++20 は atcoder では未対応。
残念。
find:C++17 対応
探索した結果、そのポインタが返るらしい。
但し、以下によると該当値が無い場合は end() を返すとある、少し使いにくい。。
アプローチ 2: for only
調査不足も否定できないですが、set は悪手かもしれません。
有識者の回答を眺めていたら秀逸なアイディアを発見しました。
step 1:文字を分割する境界線を for 文で動かしていきます
step 2:'a' ~ 'z' の何れが文字列に適合するか for で check
step 3:両方の文字列に含まれていればカウント
step 4:境界線の位置別にカウントの最大値を更新
abc098.cpp
#include <iostream>
#include <set>
using namespace std;
int main() {
int N; string S; cin >> N >> S;
int ans = 0;
for (int i = 0; i < N; i++) { //step 1 :文字を分割する境界を i で回す
int cnt = 0;
for (char c='a'; c <= 'z'; c++) {//step 2:'a' ~ 'z' の何れが適合するか確認
bool left = false, right = false;
for (int n = 0; n <= i; n++) {
if (S[n] == c)
left = true;
}
for (int m = i+1; m < N; m++) {
if (S[m] == c)
right = true;
}
//step 3:両方の文字列に含まれていればカウント
cnt += (left == true && right == true);
}
ans = max(ans, cnt);//step 4:境界線の位置別にカウントの最大値を更新
}
cout << ans;
return 0;
}
//AC 7ms;
素晴らしい!! good idea の出会いに感謝。
アプローチ3 :for only ver2
アプローチ2 と step の踏み方は同じだが
書き方が変わり、for 文を削減している。
abc098.c
#include <iostream>
#include <string>
#include <set>
using namespace std;
int main() {
int N; string S; cin >> N >> S;
int ans = 0;
for (int i = 0; i < N-1; i++) {
string A = S.substr(0, i + 1);
string B = S.substr(i + 1, N - i - 1);
int cnt = 0;
for (char c = 'a'; c <= 'z'; c++) {
if (A.find(c) != string::npos && B.find(c) != string::npos)
cnt++;
}
ans = max(ans, cnt);
}
cout << ans;
return 0;
}
//AC 5ms;
時短の為に for を減らしている。
また find の使い方が素晴らしい。
これは検索したい element が含まれていない場合 error となる。
しかし string::npos (該当なしの意図)を
使うことで上手く error を回避している、素晴らしい!