NHKつぶやきビッグデータとは日本語の全てのツイートをデイリーで集計しその日に一番つぶやかれている単語をバブルチャートで紹介するNHKの番組です。

D3.js というJSのライブラリで見た目が似たようなモノは簡単に作れます。
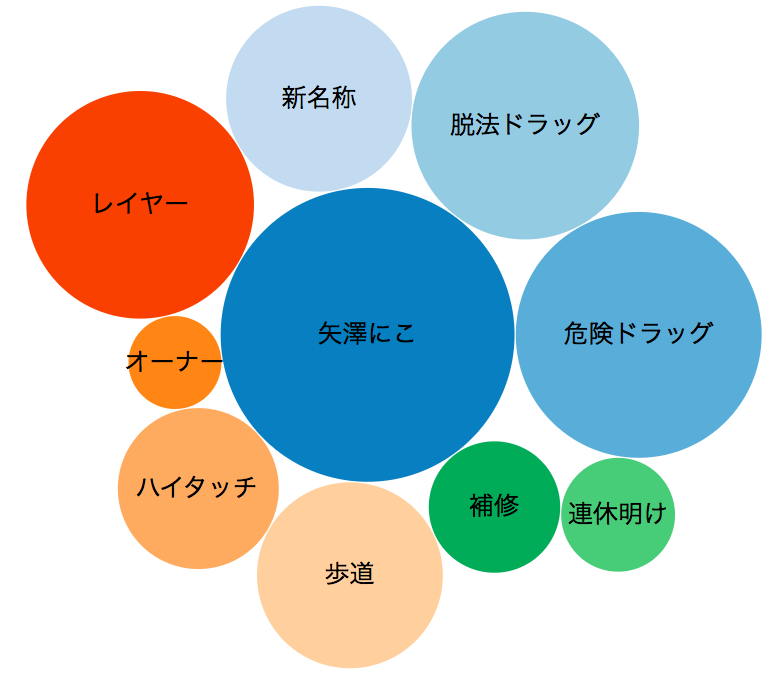
ということでプログラマーじゃなくても簡単に実行でき、本当にビッグになった時にも使える「NHKつぶやきビッグデータ」を作ってみます。
Inazuma システム構成図

今回作ったプログラム
- Inazuma (プログラム全体)https://github.com/AKB428/inazuma
- maki (Twitterデータ収集) https://github.com/AKB428/maki
構成ソフトウェア
- Oracle JDK http://www.oracle.com/technetwork/java/javase/downloads/index.html
- sbt (ビルドツール) http://www.scala-sbt.org/
- scala (Sparkのプログラミングで使用) http://www.scala-lang.org/
- Spark https://spark.apache.org/
- kuromoji (日本語 形態素解析) http://www.atilika.org/
- D3.js http://d3js.org/
- twitter4j (TwitterAPIライブラリ) http://twitter4j.org/ja/
必要システム要件
- マシン台数 = 1台
- OSはJava7以上が動くOSならなんでも可(Windows/Mac/Linux)
今回はSparkをスタンドアローンで動かすため普通のPC-Windowsでも動きます。
データがあまりにもでかくならない限りは動くはずです。(ユーザー辞書にもよるが、データが数ギガバイト以上はやばい気がする)
データが巨大になった時にプログラムはそのままSparkクラスタ実行上ですることができます。
STEP1 データ集計
| INPUT | SNSデータ |
| OUTPUT | CSVテキスト |
Twitterの場合
Streaming APIでツイッターのデータを収集します。
JavaであればTwitter4Jライブラリが利用できます。
https://dev.twitter.com/streaming/overview
Javaでの実装サンプル https://github.com/AKB428/maki/blob/master/src/akb428/maki/SearchMain.java
プログラムのコアロジック
TwitterStream twitterStream = new TwitterStreamFactory().getInstance();
twitterStream.setOAuthConsumer(twitterModel.getConsumerKey(),
twitterModel.getConsumerSecret());
twitterStream.setOAuthAccessToken(new AccessToken(twitterModel
.getAccessToken(), twitterModel.getAccessToken_secret()));
// MyStatusAdapterクラスでTwitterのStatusクラスを処理する
twitterStream.addListener(new MyStatusAdapter(applicationConfParser, bufferedWriter));
ArrayList<String> track = new ArrayList<String>();
track.addAll(Arrays.asList(Application.searchKeyword.split(",")));
String[] trackArray = track.toArray(new String[track.size()]);
// 400のキーワードが指定可能、5000のフォローが指定可能、25のロケーションが指定可能
twitterStream.filter(new FilterQuery(0, null, trackArray));
Twitter以外のSNSの場合(2ch型掲示板など
curlで適当にとってくるなどする。
オリジナルの2chはAPI制度になってデータの取得は難しくなったので素人にはおすすめできない。
2ch以外の掲示板などで練習するといいだろう。
小さいファイルサイズでリアルな会話データが入っているテキストを検証ではよく使うので2ch型の掲示板(最大1000行)は検証データとしては扱いやすいのでお薦めです。
STEP2 データ抽出+データクレンジング
| INPUT | CSVテキスト |
| OUTPUT | テキストデータ(文章以外の文字を排除したデータ) |
データ抽出
収集したデータファイルには、アカウントIDであったりツイート日時であったりの本文以外のデータも入っているため、本文のみ抽出する。
CSV形式であれば、本文の列のみ取得すればいいので容易い。
データクレンジング
抽出したデータには解析に不要なデータ(ボットや荒らし、単語解析不能なアスキーアート)が入っていることもあるので、そのようなデータを削除する。
詳しくは後述
STEP3 解析(ワードカウント)
| INPUT | テキストデータ |
| OUTPUT | CSVテキスト[単語,スコア] スコアでソートされている |
単語ごとにカウントしスコアでソートする。
Sparkプログラムで記述すると以下のようになる。
import java.util.regex.{Matcher, Pattern}
import org.apache.spark.{SparkConf, SparkContext}
import org.atilika.kuromoji.{Token, Tokenizer}
import java.io.PrintWriter
/**
* Created by AKB428
*/
object inazumaTwitter {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Inazuma Application")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val input = sc.textFile(args(0)) // hdfs://
var printRankingNum = 10
var dictFilePath = "./dictionary/blank.txt"
if (args.length >= 2) {
dictFilePath = args(1)
}
if (args.length == 3) {
printRankingNum = args(2).toInt
}
// kuromoji(形態要素解析)で日本語解析
val words = input.flatMap(x => {
// ref:http://www.intellilink.co.jp/article/column/bigdata-kk01.html
val japanese_pattern : Pattern = Pattern.compile("[¥¥u3040-¥¥u309F]+") //「ひらがなが含まれているか?」の正規表現
// 不要な文字列の削除
var text = x.replaceAll("http(s*)://(.*)/", "").replaceAll("¥¥uff57", "")
val tokens: java.util.List[Token] = CustomTwitterTokenizer.tokenize(text, dictFilePath)
val features: scala.collection.mutable.ArrayBuffer[String] = new collection.mutable.ArrayBuffer[String]()
if(japanese_pattern.matcher(x).find()) {
val pattern : Pattern = Pattern.compile("^[a-zA-Z]+$|^[0-9]+$") //「英数字か?」の正規表現
for (index <- 0 to tokens.size() - 1) {
// 二文字以上の単語を抽出
if (tokens.get(index).getSurfaceForm().length() >= 2) {
val matcher : Matcher = pattern.matcher(tokens.get(index).getSurfaceForm())
if (!matcher.find()) {
if (tokens.get(index).getAllFeaturesArray()(0) == "名詞" && (tokens.get(index).getAllFeaturesArray()(1) == "一般" || tokens.get(index).getAllFeaturesArray()(1) == "固有名詞")) {
features += tokens.get(index).getSurfaceForm
} else if (tokens.get(index).getPartOfSpeech == "カスタム名詞") {
// println(tokens.get(index).getPartOfSpeech)
// println(tokens.get(index).getSurfaceForm)
features += tokens.get(index).getSurfaceForm
}
}
}
}
}
(features)
})
// ソート方法を定義(必ずソートする前に定義)
implicit val sortIntegersByString = new Ordering[Int] {
override def compare(a: Int, b: Int) = a.compare(b)*(-1)
}
// ソート
val result = words.map(x => (x,1)).reduceByKey((x,y) => x + y).sortBy(_._2)
// ソート結果から上位を取得
for (r <- result.take(printRankingNum)) {
println(r._1 + " " + r._2)
}
// 結果をCSVファイルに保存
val out = new PrintWriter("data.csv")
for (r <- result.take(printRankingNum)) {
out.println(r._1 + "," + r._2)
}
out.close
sc.stop
}
}
object CustomTwitterTokenizer {
def tokenize(text: String, dictPath: String): java.util.List[Token] = {
Tokenizer.builder().mode(Tokenizer.Mode.SEARCH)
.userDictionary(dictPath)
.build().tokenize(text)
}
}
引数に、データファイル、ユーザー辞書、表示するランキング数(デフォルト10)を受け取り実行する。
ユーザー辞書はこのような形式でカスタム名詞として登録する。
魔法科高校の劣等生,魔法科高校の劣等生,魔法科高校の劣等生,カスタム名詞
セーラームーン,セーラームーン,セーラームーン,カスタム名詞
七つの大罪,七つの大罪,七つの大罪,カスタム名詞
ハイキュー,ハイキュー,ハイキュー,カスタム名詞
ラブライブ,ラブライブ,ラブライブ,カスタム名詞
ばらかもん,ばらかもん,ばらかもん,カスタム名詞
東京喰種,東京喰種,東京喰種,カスタム名詞
月刊少女野崎くん,月刊少女野崎くん,月刊少女野崎くん,カスタム名詞
実行
sbt コンソールに入りrunする
run [data_file_path] [kuromoji_dict_path] [rank_take_num]
run ./private/1433194505.txt ./dictionary/anime_2015_2Q.txt 20
STEP4 CSV to JSON
| INPUT | CSVテキスト[単語,スコア] |
| OUTPUT | JSON |
"矢澤にこ",11200
"歩道",10183
"レール",1212
上記のようなCSVをD3.jsが読み込める形にJSON化します
rubyなどでCSVからハッシュマップを作りJSON.dumpします。
require "json"
def build_children(title, value)
children = {}
children['name'] = title
children['children'] = []
children['children'][0] = {'name' => title, 'size' => value}
children
end
def build_data(csv_data_map)
data = {}
data['name'] = 'flare'
data['children'] = csv_data_map.map{|k, v| build_children(k,v)}
JSON.dump(data)
end
csv_data_map = {}
open(ARGV[0]) {|file|
while line = file.gets
record = line.split(',')
csv_data_map[record[0]] = record[1]
end
}
puts build_data(csv_data_map)
出来上がったJSON
{
"name": "flare",
"children": [
{
"name": "矢澤にこ",
"children": [
{
"name": "矢澤にこ",
"size": "11200"
}
]
},
{
"name": "10183",
"children": [
{
"name": "10183",
"size": "70"
}
]
},
STEP5 データを見る
tubuyaki_bigdata.htmlをブラウザで開くとdata.jsonがロードされD3.jsが実行され以下のようなグラフが表示されます。
tubuyaki_bigdata.htmlの中身は以下のD3.jsのバブルチャートのサンプルHTMLを改良したものになります。
http://bl.ocks.org/mbostock/4063269
解析のチューニング
データクレンジングを工夫する
Sparkの解析結果に単語として不要なワードなどがTOPスコアを持って出現することはよくあります。
Twitter、その他のSNSでそれぞれのサービスに特有のジャンクワードデータはあるため、Sparkに渡す前にデータクレンジングをするのをお薦めします。
Twitterであれば以下のようなプログラムでクレンジングします。
class TwitterDataCleansing
open(ARGV[0]) {|file|
while line = file.gets
puts line.gsub(/(全員|ふぁぼ|ファボ|定期|相互)/, ' ')
end
}
end
Twitterの場合「〜した人全員RT」「◯◯たん可愛い 定期」「相互フォローお願いします!」・・といった糞みたいな意味のないツイートを除外します。
こういったサービスの特有のワードは各々のサービスごとに違うためそれぞれにクレンジングプログラムを用意するのがいいでしょう。
ユーザー辞書を追加する
データクレンジングを行い、Spark+kuromojiでデータを解析した後やるべきチューニングはユーザー辞書の追加です。
集計結果に「月刊」「少女」と出てた場合**「月刊少女野崎くん」の辞書の追加が必要だというのがわかります。
集計結果に「けい」「おん」と出てた場合「けいおん」**の辞書の追加が必要だというのがわかります。
このように集計対象のジャンルドメインに詳しくない人が辞書のチューニングするのは難しいでしょう。
辞書の追加はwikipedia APIを使って単語や登場人物や用語を拾うなどして追加するなどのテクニックがあります。
アニメタイトルのリストであれば以下にAPIとツールを用意しています。
- 辞書作成ツール https://github.com/Project-ShangriLa/CreateDictionary
- アニメAPI https://github.com/Project-ShangriLa/sora-playframework-scala
Advance ちょっとひと味
ファイルをHDFSから取り込みたい時
今回はスタンドアローンプログラムでしたのでファイルもローカルファイルシステムから読み込む想定でプログラム実行していますが、Sparkの並列分散の強みを活かすならHDFS上にファイルは配置をしたほうがいいです。
build.sbtに以下の記述を追加し
libraryDependencies += "org.apache.hadoop" % "hadoop-client" % "2.6.0"
ファイルパスを hdfs://usr/menma/twitter.csv のようにすればHDFSからファイルを読むことができます。
hadoopのバージョンは最新は2.7ですのでライブラリのバージョンは使用しているHadoopサーバーに合わせてください。
ライブラリの書き方は以下を参考にしてください。
Sparkクラスタで動かしたい時
sbt assemblyでjarを作ってspark-submitコマンドで実行するのが楽です。
spark-submitにjarを渡すためにsbt assemblyするためのbuild.sbt
本物のつぶやきビックデータとFirehose契約について
本物のNHKつぶやきビックデータはNTTデータ様がスーパーなシステムで構築されています。
公開されてる資料によればちょっとレガシーなHaooop1のMapReduceな構成で動いているようです。
NTTデータはTwitterとFirehose契約(わかりやすく言うとTwitterと直接専用線でつなぐイメージ)を結んでいるためデータの欠損なく日本語のツイート情報が収集できますが、個人やFirehose契約を結んでいない企業がTwitterストリームを完全に収集するのは難しいため、対象とすべきジャンルをいくつか絞って集計するのがいいでしょう。
NTTデータはそもそも日本語のツイートを全て集めて解析して再販するサービスを展開しているため専用線を引いていますが、普通の企業はそこまでは不要なはずなので特定のジャンルの解析に特化し自社のサービスの最適化につなげるといいでしょう。
Twitter、「NTTデータは今後もFirehoseを利用する」とGnipの発表に補足説明
↑を今北産業で説明すると・・
結構前) NTTデータ「TwitterとFirehoseを契約しTwitterデータの再販サービスをします」
↓
最近)Twitter「全ての企業のFirehose契約をやめます。Gnipという企業のみにデータを提供します」
↓
その後)Twitter「NTTデータのFirehose提供はやめません」