自己紹介、目的
機械学習をゼロから学んでいる者です。ここまでの学習のまとめとして、3つの手法を用いて画像分類を行いましたので、その結果と簡単な分析をブログに記載します。使用した3手法は以下です。
サポートベクターマシン
ディープラーニングではない機械学習の代表格として。
ディープラーニング(CNN不使用)
結果としては全く上手くいかなかったのですが、比較のため記載します。
畳み込みニューラルネットワーク(CNN)
ディープラーニングの画像分類における有力な手法です。
環境
MacBookAir early 2020, RAM 8GB, CPU intel core i5 (非M1)
OS: macOS Big Sur Ver. 11.4
docker上のJupyter NotebookのPython上にて行いました。ここで使用したdockerイメージには、tensorflow、scikit-learn、pandas、numpy、matplotlib、RandomUnderSamplerをインストールしています。この環境構築は以下の記事を参照してください。
結果概要
データセット
Scikit-learnから入手できるLFW people
4名の画像を各120枚づつ用意。
70%をトレーニング、30%をテストに使用。
各手法における正解率
サポートベクターマシン:正解率85%
ディープラーニング(CNN不使用):正解率25% *適当に分類しても1/4の確率で正解するので、意味ない・・・
畳み込みニューラルネットワーク(CNN):正解率79%
実行内容詳細
Jupyter Notebookではセルごとにpythonを実行できましたので、それと同様に実行した順に記載します。
データセットのインポート
from sklearn.datasets import fetch_lfw_people
LFW peopleのデータセットのインポートです。初回は少し時間がかかります。
データ確認1
face_data = fetch_lfw_people(min_faces_per_person=120)
X = face_data.data
Y = face_data.target
print("input data size:", X.shape)
print("output data size:", Y.shape)
print("label name:", face_data.target_names)
出力
input data size: (1031, 2914)
output data size: (1031,)
label name: ['Colin Powell' 'Donald Rumsfeld' 'George W Bush' 'Tony Blair']
1行目でface_dataにデータを格納しています。LFW peopleのデータセットには5749名分、13,233枚の画像が格納されていますが、人物により画像数にばらつきがあります。min_faces_per_personを指定することで人物毎の最少画像数を指定でき、120を指定すると4名の画像のみとなります。
Xにデータを、Yにターゲットを代入しました。X.shapeでXのサイズを確認して、行数1031は1031枚の画像ということ、列数2914は画像毎のデータ数は2914データ(縦62ピクセル、横47ピクセル)ということがわかりました。
4名の人物の名前を確認したところ、Colin Powell、Donald Rumsfeld、George W Bush、Tony Blairとなりました。
データ確認2
import matplotlib.pyplot as plt
fig, ax = plt.subplots(3, 4)
plt.subplots_adjust(wspace=0.8, hspace=0.5)
for i, axi in enumerate(ax.flat):
axi.imshow(face_data.images[i], cmap='gray')
axi.set(xticks=[], yticks=[], xlabel=face_data.target_names[face_data.target[i]])
plt.show()
出力

matplotlibを用いてどのような画像か確認しました。
サンプル数確認
for i in range(len(face_data.target_names)):
print("{} has {} samples".format(face_data.target_names[i], (Y == i).sum()))
出力
Colin Powell has 236 samples
Donald Rumsfeld has 121 samples
George W Bush has 530 samples
Tony Blair has 144 samples
各人物毎の画像数を確認しました。データ数に偏りがあるので、次のセルでこれを是正します。
アンダーサンプリングによるデータの偏り修正
from imblearn.under_sampling import RandomUnderSampler
import pandas as pd
df=pd.DataFrame(X)
df['target']=Y
strategy = {0:120, 1:120, 2:120, 3:120}
rs=RandomUnderSampler(random_state=42, sampling_strategy = strategy)
df_sampled,_=rs.fit_resample(df,df.target)
print(df_sampled.target.value_counts())
出力
3 120
2 120
1 120
0 120
Name: target, dtype: int64
RandomUnderSamplerを用いてデータの偏りを無くしました。
Donald Rumsfeldさんが121枚でしたので、キリのいい120枚で統一しました。
出力にて120枚ずつにアンダーサンプリングできていることが確認できます。
訓練データとテストデータへの分割
from sklearn.model_selection import train_test_split
Y = df_sampled.target.values
X = df_sampled.iloc[:,0:2914].values
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3,stratify=Y, random_state=0)
print(X.shape)
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
# 念のため確認
df = pd.DataFrame(y_train)
df.value_counts()
出力
(480, 2914)
(336, 2914)
(336,)
(144, 2914)
(144,)
3 84
2 84
1 84
0 84
dtype: int64
ダウンサンプリングしたデータフレームからXとYにデータを戻します。
そして大変便利なtrain_test_splitを用いて訓練データとテストデータに分割します。
データのshapeを確認そたところ、それぞれ所望のものとなっていることが確認できました。
さらに念のためy_trainのデータ数を確認したところ、一名につき84枚としっかりデータの偏りがないことを確認しました。
サポートベクターマシン(SVC)にて分類
from sklearn import svm
from sklearn.metrics import accuracy_score
svc = svm.SVC(random_state=42,C=1, kernel='rbf', gamma=0.0000001)
svc.fit(X_train, y_train)
y_pred_svc = svc.predict(X_test)
print ("Accuracy: %.2f"%accuracy_score(y_test, y_pred))
print("predicted", y_pred_svc[0:20])
print("actual", y_test[0:20])
出力
Accuracy: 0.85
predicted [3 1 3 1 1 0 1 3 0 3 0 3 3 2 1 0 0 3 1 1]
actual [2 1 3 1 1 0 1 3 0 3 2 3 3 2 2 0 0 3 1 1]
さすがサポートベクターマシン、精度は85%を記録しました。
記述量もたったこれだけ、なんて簡単なんでしょう!さらに私の環境では1秒足らずで結果を出力します。
出力のpredictedとactualでは、testデータの最初の20枚の正誤について確認しています。
結果については後でもう少し分析します。
ディープラーニング(CNN不使用)にて分類
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation, Dense, Dropout, Input, BatchNormalization
from sklearn.metrics import mean_squared_error
import numpy as np
import pandas as pd
# Yデータをワンホットエンコーディング
y_train_onehot = pd.get_dummies(y_train)
y_test_onehot = pd.get_dummies(y_test)
model = Sequential()
model.add(Dense(2048, input_dim=2914))
model.add(Activation("relu"))
model.add(Dropout(rate=0.2))
model.add(Dense(64))
model.add(Activation("relu"))
model.add(Dropout(rate=0.2))
model.add(Dense(4))
model.add(Activation("softmax"))
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
history = model.fit(X_train, y_train_onehot, epochs= 50, batch_size= 32, verbose=1, validation_data=(X_test, y_test_onehot) )
# スコア出力
score = model.evaluate(X_test, y_test_onehot, verbose=1)
print("evaluate loss: {0[0]}\nevaluate acc: {0[1]}".format(score))
pred = np.argmax(model.predict(X_test), axis=1)
print("predicted", pred[0:20])
print("actual", y_test[0:20])
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
出力
--epocについては省略--
evaluate loss: 1.386299729347229
evaluate acc: 0.25
predicted [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
actual [2 1 3 1 1 0 1 3 0 3 2 3 3 2 2 0 0 3 1 1]
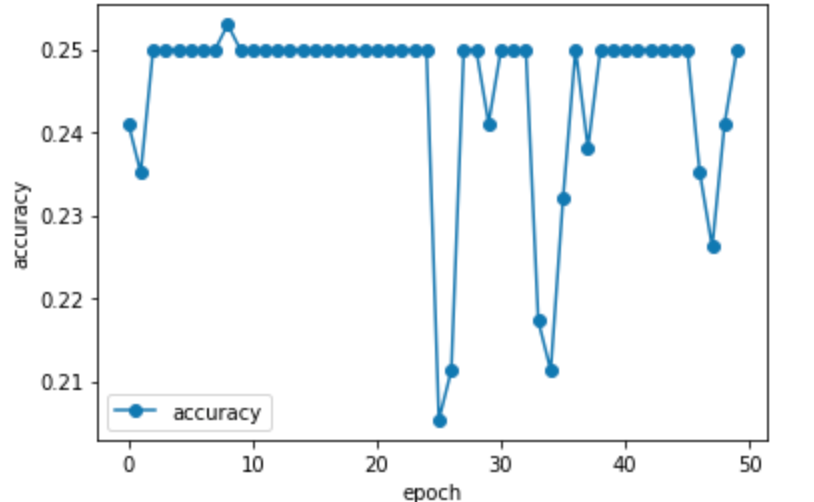
サポートベクターマシンでできるならCNNを使用しないディープラーニングでもできるでしょ!?との思いからやってみたものの、結果は散々でした。何度パラメータを変えても精度は25%になります。predictedを見ると分かるように、適当に結果を出力しているだけでした。どこかの設定ミスったのかな・・・。
ちなみに、ディープラーニングではYのラベルはワンホットエンコーディングをしなければエラーとなりました。多値分類でディープラーニングの出力層にsoftmaxを使用しているので、ワンホットエンコーディングが必要なようです。
畳み込みニューラルネットワーク(CNN)
from tensorflow.keras.layers import Dense, Dropout, Flatten, Activation
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.utils import to_categorical, plot_model
from tensorflow.keras.callbacks import EarlyStopping
import numpy as np
import matplotlib.pyplot as plt
# Yデータをワンホットエンコーディング
y_train_onehot = pd.get_dummies(y_train)
y_test_onehot = pd.get_dummies(y_test)
# Xデータを画像形式に変換
# Convレイヤーは4次元配列をとる(バッチサイズx縦x横xチャンネル数)
X_train = X_train.reshape(-1, 62, 47 , 1)
X_test = X_test.reshape(-1, 62, 47 , 1)
# モデルの定義
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3, 3), input_shape=(62,47,1)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.4))
model.add(Conv2D(filters=32, kernel_size=(3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.4))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(4))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# early stoppingも導入する
earlyStopping = EarlyStopping(monitor = 'val_loss', patience = 50, mode ="auto")
history = model.fit(X_train, y_train_onehot, batch_size=64, epochs=1000, verbose=1, validation_data=(X_test, y_test_onehot))
# スコア出力
score = model.evaluate(X_test, y_test_onehot, verbose=1)
print("evaluate loss: {0[0]}\nevaluate acc: {0[1]}".format(score))
pred_cnn = np.argmax(model.predict(X_test), axis=1)
print("predicted", pred_cnn[0:20])
print("actual", y_test[0:20])
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
出力
--999/1000までのepocは省略--
Epoch 1000/1000
6/6 [==============================] - 1s 112ms/step - loss: 0.0164 - accuracy: 0.9881 - val_loss: 1.3945 - val_accuracy: 0.7917
5/5 [==============================] - 0s 18ms/step - loss: 1.3945 - accuracy: 0.7917
evaluate loss: 1.3944944143295288
evaluate acc: 0.7916666865348816
predicted [3 1 3 1 1 0 1 3 0 3 2 0 3 1 3 3 0 3 1 1]
actual [2 1 3 1 1 0 1 3 0 3 2 3 3 2 2 0 0 3 1 1]
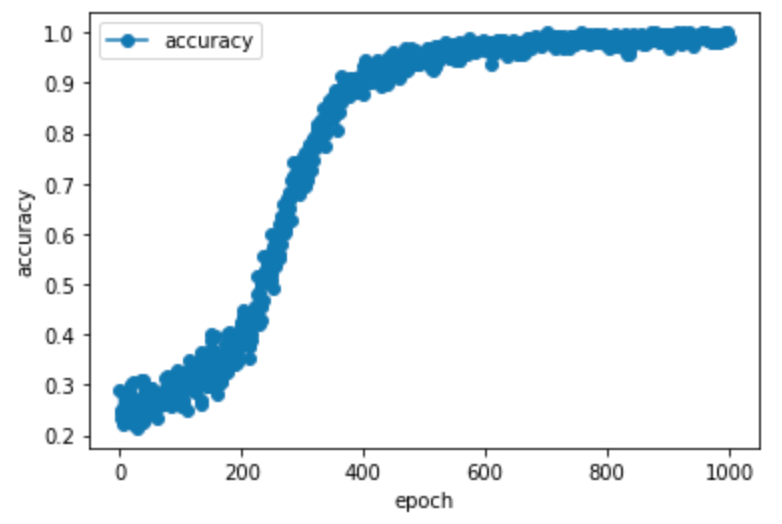
いや、さすがCNN。これぞディープラーニング。epoc毎の精度の上昇は見ていて気落ちがいいです。しかしながら、trainデータには精度98〜100%が出たのですが、testデータでの精度は79%でした。完全に過学習してます。
結果について
データ分析的なこともしたいので、サポートベクターマシン(SVC)と畳み込みニューラルネットワーク(CNN)がどのような誤分類をしたのか確認しました。
分析用のデータフレーム作成
result_svc = []
for i in range(len(y_test)):
if y_pred_svc[i] != y_test[i]:
result_svc.append([i, y_test[i], y_pred_svc[i]])
result_svc = pd.DataFrame(result_svc, columns = ["index number","actual","predict" ])
result_cnn = []
for i in range(len(y_test)):
if pred_cnn[i] != y_test[i]:
result_cnn.append([i, y_test[i], pred_cnn[i]])
result_cnn = pd.DataFrame(result_cnn, columns = ["index number","actual","predict" ])
このセルにてSVCとCNNのテストデータの予想が外れた結果のみを抽出して、result_svcとresult_cnnというpandasのデータフレームを作成しました。
サポートベクターマシン(SVC)の結果のまとめ
result_svc.groupby(["actual","predict"]).count().set_axis(["回数"], axis='columns')
出力
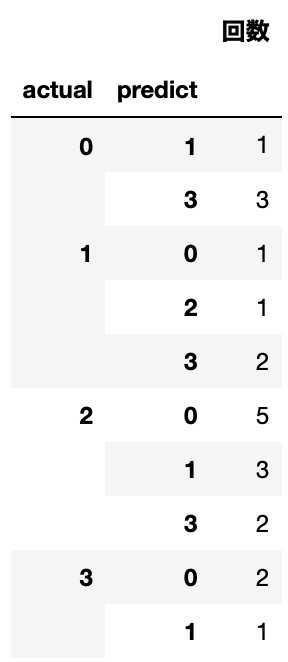
"actual"と"predict"列でgroupbyを使用して、それぞれの回数を見てみました。例えば、表の一番上の結果は「0」の人を「1」の人に誤分類する回数は1回ということを表しています。ちなみにテストデータは各人物84枚です。
SVCの結果では、「2」の人を予想することが難しく、「2」の人を「0」の人に間違えることが多い(5回)ことがわかりました。
ちなみに、0〜3の人はそれぞれ['Colin Powell' 'Donald Rumsfeld' 'George W Bush' 'Tony Blair']です。
畳み込みニューラルネットワーク(CNN)の結果のまとめ
result_cnn.groupby(["actual","predict"]).count().set_axis(["回数"], axis='columns')
出力
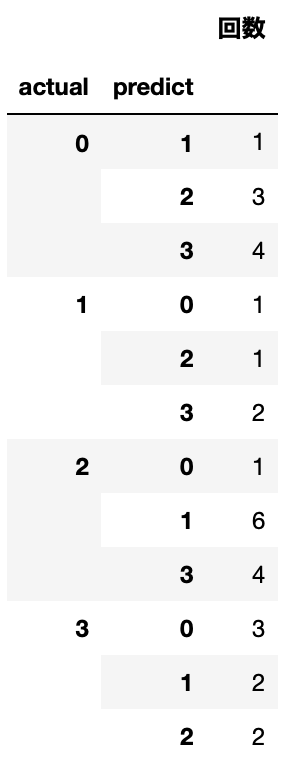
SVCと同様に"actual"と"predict"列でgroupbyを使用して、それぞれの回数を見てみました。CNNも「2」の人を分類するのが難しく、CNNの場合は「1」の人に誤分類することが多い(6回)ようです。
最後に
CNNの精度を上げる手法として画像の水増しする方法もあるのですが、そこまでは行いませんでした。
ハイパーパラメータの調整と合わせて今後時間があったらやってみようと思います。