こんにちは、アルファアーキテクトでVPoEをやっております胡 恩召(Ethan Hu)です。
先日書いた記事「DSP広告配信最適化における技術概要」の中で、プログラマティック広告のDSP配信最適化の技術を簡単紹介しました。DSP配信最適化に限らず、SSPやDMPなどいろんなアドテック分野に、機械学習技術を利用されています。今回は、機械学習の基礎知識「モデル評価指標」をご紹介いたします。
モデルとは
機械学習のモデルとは、データを入力し、結果を出せるものです。例えば、人間が話している音声を受け取り、それを文字にするモデルはSiriなどの音声認識アシスタントを可能としましたし、道の画像の中で車線や他の自動車を認識するモデルは自動運転を可能としています。
機械学習の目的は、入力と出力の相関関係を構築することです。入力は、生データセットを前処理して、特徴化された「特徴データ」と言います。出力は、モデルのタスクタイプによって違います。例えば、分類モデルの場合、出力は「類別」ですが、回帰モデルの場合、出力は「数値」です。
機械学習のモデルが良いか悪いか、評価することが必要ですが、その評価基準は、「評価指標」と言います。
評価指標
回帰タスク評価指標
MAE
MAE(Mean Absolute Error)は、平均絶対誤差です。RMSE(Root Mean Squared Error)に比べて外れ値の影響を受けにくい特徴があります。外れ値を多く含んだデータを扱う際には、RMSEよりもMAEを使うことが適していそうですね。数学公式は下記です。
MAE = \frac{1}{N} \cdot \sum_{i=1}^{N} |y_i - p_i|
$N$:サンプル数
$y_i$:$i$ 個目サンプルの真実値
$p_i$:$i$ 個目サンプルの予測値
WMAE
WMAE(Weighted Mean Absolute Error)は、ウィト付き平均絶対誤差です。数学公式は下記です。
WMAE = \frac{1}{N} \cdot \sum_{i=1}^{N} w_i \cdot |y_i - p_i|
$w_i$:$i$ 個目サンプルのウィト値
MAPE
MAPE(Mean Absolute Percentage Error)は、平均絶対パーセント誤差です。数学公式は下記です。
MAPE = \frac{100}{N} \cdot \sum_{i=1}^{N} |\frac{y_i - p_i}{y_i}|
$y_i ≠ 0$
MSE
MSE(Mean Squared Error)は、平均二乗誤差です。RMSE同様に、実際の値と予測値の誤差がどれだけあるかを示しており、当然値がモデルの性能がどれだけ悪いかを示す指標の一つです。数学公式は下記です。
MSE = \frac{1}{N} \cdot \sum_{i=1}^{N} (y_i - p_i)^2
RMSE
RMSE(Root Mean Squared Error)は、平均二乗誤差平方根です。実際の値と予測値のズレが小さければ小さいほど、当てはまりの良いモデルだって言えるよね、回帰モデルの最も一般的な性能指標で以下の式で表現されます。数学公式は下記です。
RMSE = \sqrt{\frac{1}{N} \cdot \sum_{i=1}^{N} (y_i - p_i)^2}
RMSPE
RMSPE(Root Mean Square Percentage Error)は、平均二乗パーセント誤差平方根です。数学公式は下記です。
RMSPE = \sqrt{\frac{100}{N} \cdot \sum_{i=1}^{N} (\frac{y_i - p_i}{y_i})^2}
RMSLE
RMSLE(Root Mean Squared Logarithmic Error)は、二乗平均平方根対数誤差です。RMSLEは予測値と実測値の対数差の二乗の総和の平均値のルートをとったもので以下の数式で表現されます。対数をとる前に予測値と実測値の両方に+1をしているのは、予測値または、実測値が0の場合に log(0) となって計算できなくなることを避ける目的があります。数学公式は下記です。
RMSLE = \sqrt{\frac{1}{N} \cdot \sum_{i=1}^{N} (log(y_i + 1) - log(p_i + 1))^2}
分類タスク評価指標
分類タスクの評価指標は、よくある二分類タスクで説明します。分類の実際値と予測値は下記の4種類があります。
| 予測Positive | 予測Negative | |
|---|---|---|
| 実際Positive | TP | FN |
| 実際Negative | FP | TN |
TP:True Positive 真陽性
FN:False Negative 偽陰性
FP:False Positive 偽陽性
TN:True Negative 真陰性
正解率(Accuracy)
正解率は、正や負と予測したデータのうち、実際にそうであるものの割合です。計算式は下記です。
Accuracy= \frac{TP+TN}{TP+FP+TN+FN}
適合率(Precision)
適合率は、正と予測したデータのうち,実際に正であるものの割合です。計算式は下記です。
Precision= \frac{TP}{TP+FP}
再現率(Recall)
再現率は、実際に正であるもののうち,正であると予測されたものの割合です。計算式は下記です。
Recall = \frac{TP}{TP+FN}
特異度(Specificity)
特異度は、実際に負であるもののうち,負であると予測されたものの割合です。計算式は下記です。
Specificity = \frac{TN}{FP+TN}
F値(F-measure)
F値は、再現率と適合率の調和平均です。計算式は下記です。
F-measure = \frac{2\cdot Recall \cdot Precision}{Recall+Precision}
ROC曲線
ROC(Receiver Operating Characteristic)曲線は、分類器のパラメータを変化させながら,縦軸に $\frac{𝑇𝑃}{𝑇𝑃 + 𝐹𝑁}$、横軸に $\frac{𝐹𝑃}{𝐹𝑃 + 𝑇𝑁}$ をとった曲線です。
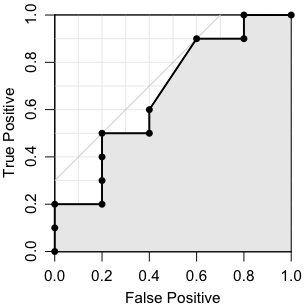
図1: ROC曲線
左下の (0,0) で始まって,右上の (1,1) で終わる。横軸が (0,0) から (0,1)まで上昇し、そこから水平に (1,1) まで続く曲線になれば理想的な分類器です。
AUC
AUC(Area Under the Curve)は、ROC曲線のROC曲線下の面積です。分類器の性能の良さを表します。0から1までの値をとり、完全な分類が可能なときの面積は1で、ランダムな分類の場合は0.5になります。図1のグレー面積は、分類器のAUC値です。
ランキングタスク評価指標
ランキングタスクの評価は、よく検索エンジンやレコメンドシステムで使います。その評価指標は、主にMRR(Mean Reciprocal Rank)やMAP(Mean Average Precision)やNDCG(Normalized Discounted Cumulative Gain)があります。
MRR
MRR(Mean Reciprocal Rank)は、ランキングリストを上位から見て、最初の適合アイテムの順位をそのまま計算に利用したシンプルな指標です。計算式は下記です。
MRR = \frac{1}{N} \sum_{i=1}^{N} \frac{1}{rank_i}
MAP
MAP(Mean Average Precision)は、平均適合率の平均です。計算は二ステップが必要です。お先にAP(Average Precision)を算出し、その後MAPを算出します。
(1) AP(Average Precision)
AP = \sum_{k=1}^{N} \frac{Precision(k) \cdot y_k}{\sum_{i=1}^{k}y_i}
$y_k$ の値は、上位$k$番目が適合アイテム場合1、それ以外は0です。
(2) MAP(Mean Average Precision)
MAP = \frac{1}{N} \sum_{i=1}^{N} AP(i)
NDCG
NDCG(Normalized Discounted Cumulative Gain)は、正規化され順位を含めて正解データのランキングをどれだけ再現できるのかの評価の指標を表しています。計算方法は下記のステップです。
(1) CG(Cumulative Gain)
CG_k = \sum_{i=1}^{k} relevant(i)
$k$:上位$k$番目アイテム(Top $k$)
$relevant(i)$:$i$ 個目アイテムの相関レベル
(2) DCG(Discounted cumulative gain)
DCG_k = \sum_{i=1}^{k} \frac{2^{relevant(i)} - 1}{log_2(i + 1)}
(3) IDCG(Ideal DCG)
IDCGは、最適なDCGです。
IDCG_k = \sum_{i=1}^{|Relevant|} \frac{2^{relevant(i)} - 1}{log_2(i + 1)}
$|Relevant|$:アイテムの相関関係の高い順のリスト
(4) NDCG(Normalized DCG)
NDCG_k = \frac{DCG_k}{IDCG_k}
まとめ
数年前から、人工知能や機械学習やビッグデータなど分野が人気になっており、よく使ってるサービスは、アドテック業界のサービスだと思いますが、アドテック業界のエンジニアとしてのスキルアップ・レベルアップとして大きな成長ができることも魅力だと思います。
アルファアーキテクトは現在IPOを目指しています。『VeleT』の発展を加速させるため、 現在インフラエンジニア、バックエンドエンジニア、テックリードなどを積極的に募集しています。動画広告サービス『VeleT』の開発を一緒に推進してくれる方、是非応募をお待ちしています!