環境
python3
準備
まず、DBpediaからデータ取得を簡単にしてくれるライブラリを持ってくる
pip install sparqlwrapper
取得したいデータを決める
まず、DBpediaのページから、決定する。
http://ja.dbpedia.org/page/%E4%B8%AD%E4%BA%8C%E7%97%85%E3%81%A7%E3%82%82%E6%81%8B%E3%81%8C%E3%81%97%E3%81%9F%E3%81%84!
URLで、「http://ja.dbpedia.org/page/{検索語}」
って感じで、
指定する。なお、大文字小文字も区別されるので、注意。
例えば、akb48はヒットしないが、AKB48はヒットする。
なので、wikipedia本家から実際に検索してみて、検索語を確認すれば良い。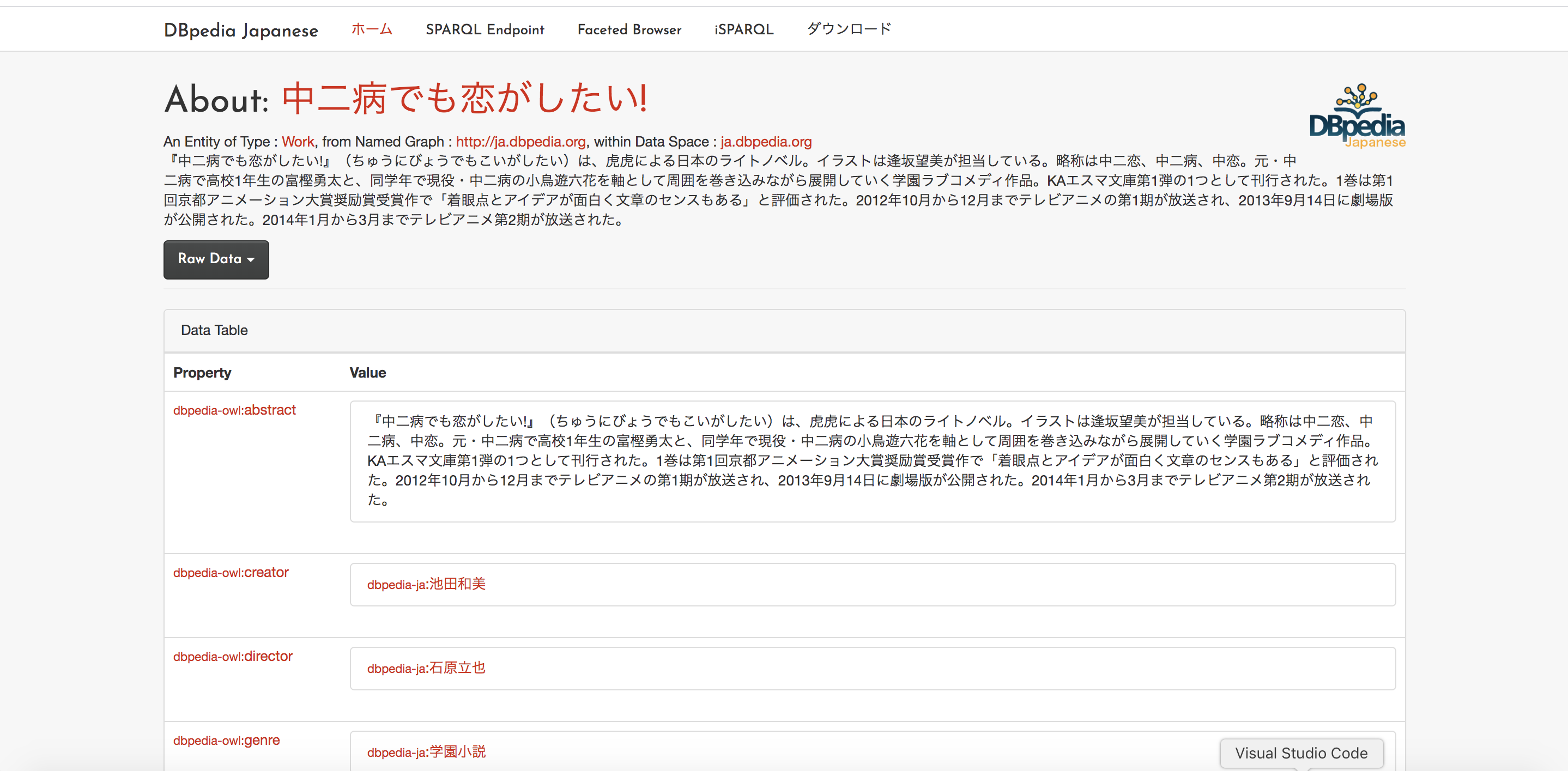
プログラム
取得したいデータを指定する際には、
DBpediaに「dbpedia-owl:abstract」みたいに書いてあるものを
追加していくことになる。
その場合は、select文の「?a」みたいに任意の名前を追加していって、
whereの中でタグを追加していく。
なお、追加するたびに、セミコロンは忘れてはいけない。
# -*- coding: utf-8 -*-
from SPARQLWrapper import SPARQLWrapper
sparql = SPARQLWrapper(endpoint='http://ja.dbpedia.org/sparql', returnFormat='json')
sparql.setQuery("""
PREFIX dbpedia-owl: <http://dbpedia.org/ontology/>
SELECT ?a ?b ?o WHERE {
<http://ja.dbpedia.org/resource/中二病でも恋がしたい!> rdfs:label ?label;
<http://dbpedia.org/ontology/director> ?a ;
<http://dbpedia.org/ontology/productionCompany> ?b ;
<http://dbpedia.org/ontology/abstract> ?o .
}
""")
results = sparql.query().convert()
print(results)
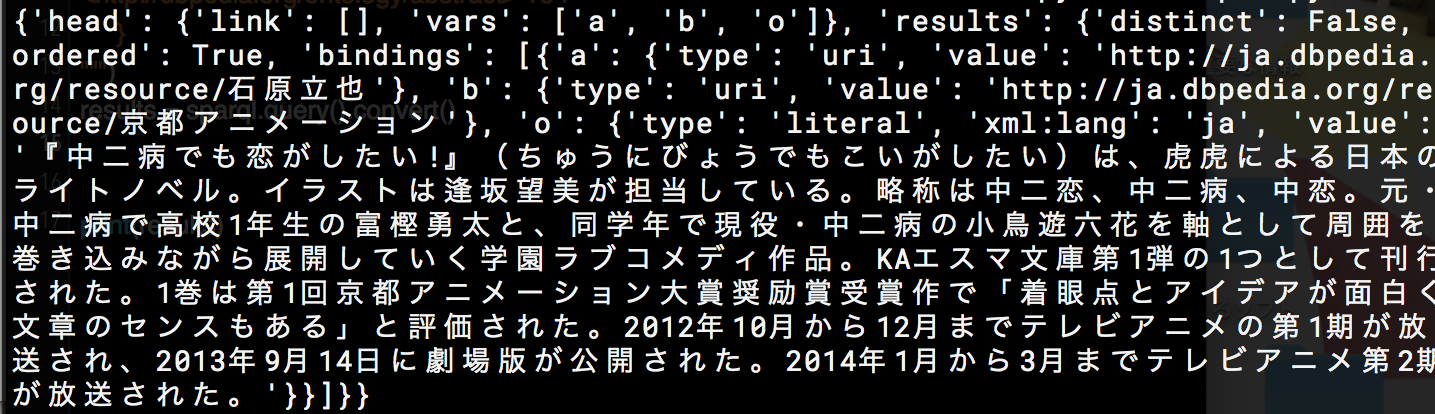
取得結果
こんな感じで、タイトルも概要も取得できる。
感想
dbPediaは大学生の時授業内でやったことあったけど、めっちゃ前だったので使い方とかほとんど忘れていた。
しかもあの時はPHPでやっていたので、今回pythonでやってみたらうまくいったので嬉しい。
あと、直接HTMLのタグを指定してwikipediaからスクレイピングするなんてナンセンス!DBpedia使いましょうねみたいな記事を見たことあるけど、
DBpediaだけじゃ全てのデータを取得できるわけではなさそうなので、
結局はHTMLのpタグの要素を動的に取得したりするみたいな処理をやる必要がありそう。