GPUの悲鳴
アセットまぁまぁおるなーっていうシーンでテクスチャ表示にしてみるとー
ドゥン!
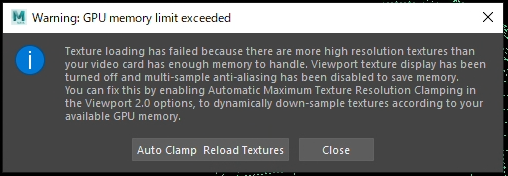
auto Clamp使いなさいよ、って書かれてるんですが
使ってるんですよauto Clamp。
じゃぁどうしたらいいんすか問題が起きました。
現状把握
GPUメモリーがというのであればこのコマンドで使用状況を見れるはず。
print(cmds.memory(summary=True))
print(cmds.ogs(gpu=True))
準備したデータ
- 4Kテクスチャを36つないだ枚ほど用意し、1:1でlambertにつないだデータ
- 同じテクスチャを512にリサイズしたデータ
これをviewPortの設定をいじりつつ確認してみます。
1,4Kテクスチャ + autoClamp ON
['\n', '5600.730 Mb\tCurrent\n']
2594
2,4Kテクスチャ + customClamp 512
['\n', '3105.922 Mb\tCurrent\n']
177
3,512テクスチャ + autoClamp ON
['\n', '3065.641 Mb\tCurrent\n']
160
1と2を比較すると、今回の状況下では手動で指定したほうが良さそうですね。
2と3を比較すると、事前にリサイズしても大して効果は無さそうですね。
ただ、viewportでの表示を眺めていると明らかに2より3の方が表示までの時間が短いんですよね。
profiler
表示までの時間が気になるので、profilerでテクスチャーのプレビューが終わるまでの内容を比べてみます。
1,4Kテクスチャ + autoClamp ON
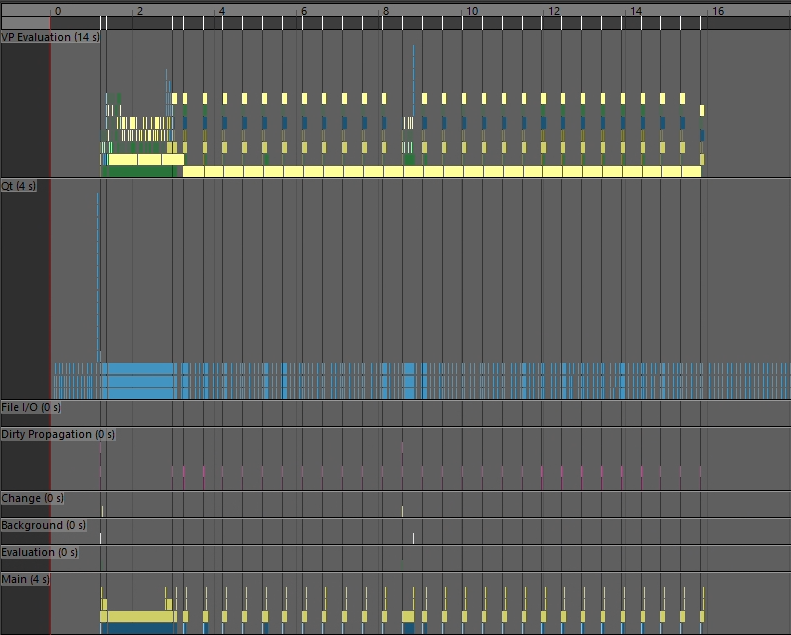
2,4Kテクスチャ + customClamp 512
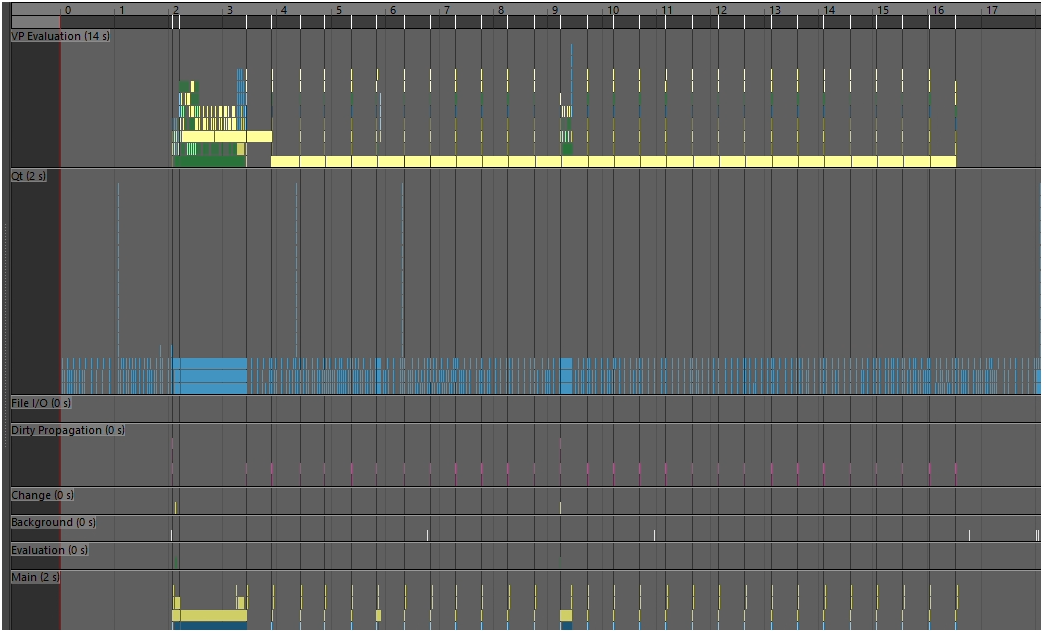
3,512テクスチャ + autoClamp ON
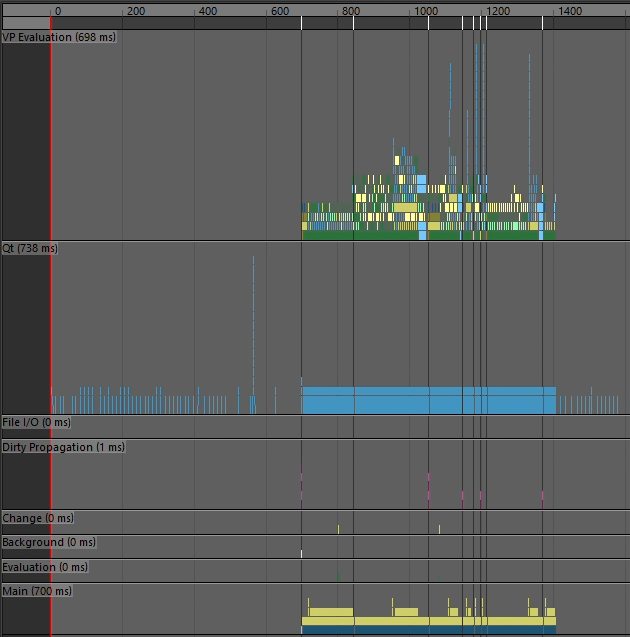
おー 結果が流石に変わりましたね。
1と2の状況で幅を利かせてるものをみてみると、まぁなんかテクスチャをロードしてるっぽいですね。
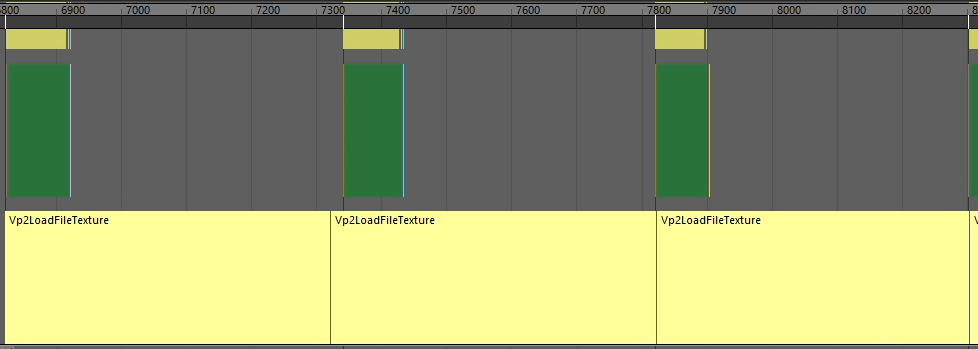
ざっくり結論
- テクスチャをあらかじめリサイズしても、clampを使用してもGPUメモリの使用量はさほど変わらない。
- テクスチャの解像度が低い方がviewPortの負荷が軽い。
なので、
リサイズできるならリサイズしたほうがいい
という雑な結論をとりあえず置いときます。
※実は以前同じような検証をしたときには clampを使用しても高解像度テクスチャの方がGPUメモリの使用量多かったんですよねぇ。これはmayaのアップデートによって改修されたのですかね? リリースノートをちゃんと読もう。