2018年6月、ChromiumのフォーラムでWebGLのCompute shader実装がアナウンスされました。12月現在も実装が進められており、どうにか一部の機能を動かすことができたので今回はこちらを紹介します。
Chrome CanaryでCompute shaderを試す
Compute shaderは2018年12月現在、WindowsのChrome Canaryでしか動作しません。Canaryは通常のChromeとは独立して動かせるので、まずはこれをインストールしましょう。残念ながらmacOSではOpenGLのバージョンの関係で動かすことができず、実装予定もないようです。また、現状Windowsであっても環境によっては動作しません。
(2019/3/11 追記)2019年3月現在、本記事のデモは、後述のコマンドラインオプションを追加することで、Stable〜CanaryまですべてのチャンネルのWindows Chromeで動作します。開発を試す場合は、最新の機能追加やバグフィックスが提供されるので、Canaryをおすすめします。
(2019/4/9 追記)ChromiumベースのEdgeのプレビュー版が出ましたね。試してみたところ、Compute shaderも動作したので追記しておきます。さすがChromium。
Canary起動時に、Compute shaderを有効にする以下の2つ(ないし3つ)のコマンドラインオプションを指定します。通常、Chromeのベータ版の機能の有効設定はchrome://flags/からフラグで設定しますが、Compute shaderにはまだGUIのフラグが用意されていません。一度すべてのCanaryを終了してからでないとコマンドラインオプションで起動しても反映されないので注意して下さい。
-
--enable-webgl2-compute-context
Compute shader(WebGL2ComputeRenderingContext)を有効にします。Chrome Betaあたりに降りてきたらGUIでフラグが用意されるのではないでしょうか。現状、Androidではこのフラグが無視されるようになっているようです。
(2019/1/29 追記)Chrome Canary 74.0.3687.0から、GUIのフラグにWebGL 2.0 Computeが追加されました。こちらのフラグはWindowsとLinux(およびChrome OS)でのみ設定可能です。 -
--use-angle=gl
後述のShader Storage Buffer Objectが現状D3Dバックエンドでうまく動作していない(書き込みが反映されない?)ため、ANGLEをOpenGLバックエンドで起動します。GUIのフラグ(Choose ANGLE graphics backend)でも可。こちらは実装が進めば不要になるはずです。 -
--use-cmd-decoder=passthrough
(2018/12/20 追記)筆者のメイン環境では上記の2つのオプションのみで動作しましたが、このオプションをつけることで動くようになる環境もありました。動かない場合はこちらも追加して試してみてください。
Windowsなので、Canaryのショートカットにコマンドラインオプションを指定しておくのが楽です。
"C:\Users\[user]\AppData\Local\Google\Chrome SxS\Application\chrome.exe" --enable-webgl2-compute-context --use-angle=gl
筆者の環境ではこれで下記のデモが正常に動作するようになりましたが、WindowsマシンでもGPUやディスプレイドライバによってはCompute shaderが有効にならない(WebGL2ComputeRenderingContextが取得できない)ようです。古いマシンやCPU内蔵のGPUだと怪しいです。このあたり詳しい条件がよくわからないので、ご存知の方がいれば教えてください。
Compute shaderのデモ
Compute shaderのデモを2つ作ってみました。上記の手順でCanaryを設定して再生してみてください。
Boidsシミュレーション
まずはBoidsシミュレーションを実装してみました。Boidsは分離(Separation)、整列(Alignment)、結合(Cohesion)のそれぞれの相互作用を計算する必要があるので、相互作用計算を並列化できるCompute shaderのサンプルとしてまずまず適切だと思います。Compute shaderを使って1パスでBoidsの座標と速度を計算し、インスタンシングを使って1ドローで描画しています。CPUでは命令の発行以外なにもしていません。

*上記のソースコードにはレンダリング用のヘルパークラスが多く含まれていてわかりにくいため、今回のデモで重要なファイルを記載します。
-
Main.ts
→メインのクラスです。Compute shaderのGLSLや処理はすべてここにあります。 -
LightingShaderProgram.ts
→レンダリング用のシェーダーのクラスです。Vertex shaderおよびFragment shaderのGLSLはここにあります。
実装にあたって以下の書籍を参考にしました。このシリーズはUnityに限らず3Dグラフィックスの知識として参考になり、とても面白いのでオススメです。
Bitonicソート
並列計算可能なソートアルゴリズムのひとつであるBitonicソートをCompute shaderで実装しました。選択した要素数のランダム配列をCPU(JavaScriptの標準のsort())とGPU(Compute shader)でそれぞれソートを実行し、実行時間を計測します。計測後、ソート結果が正しいかどうかを検証します。
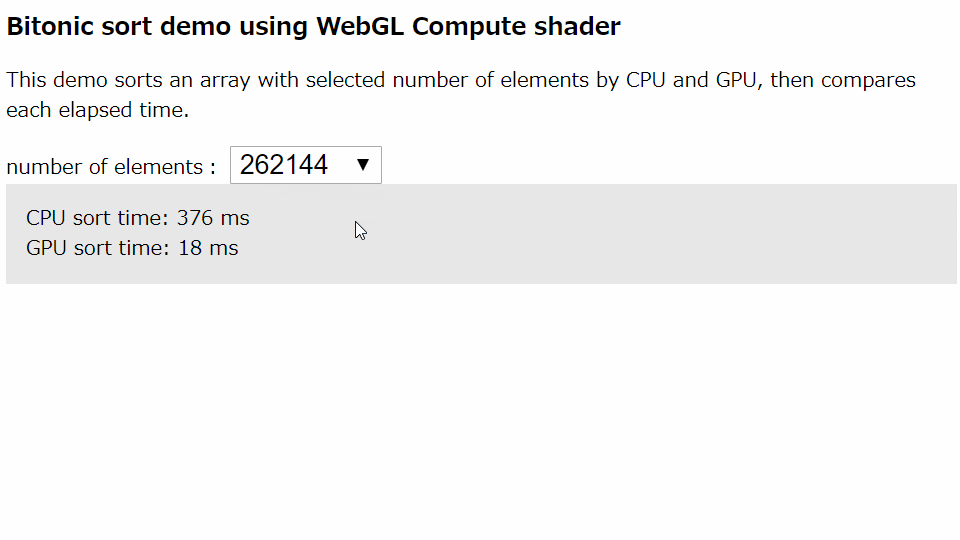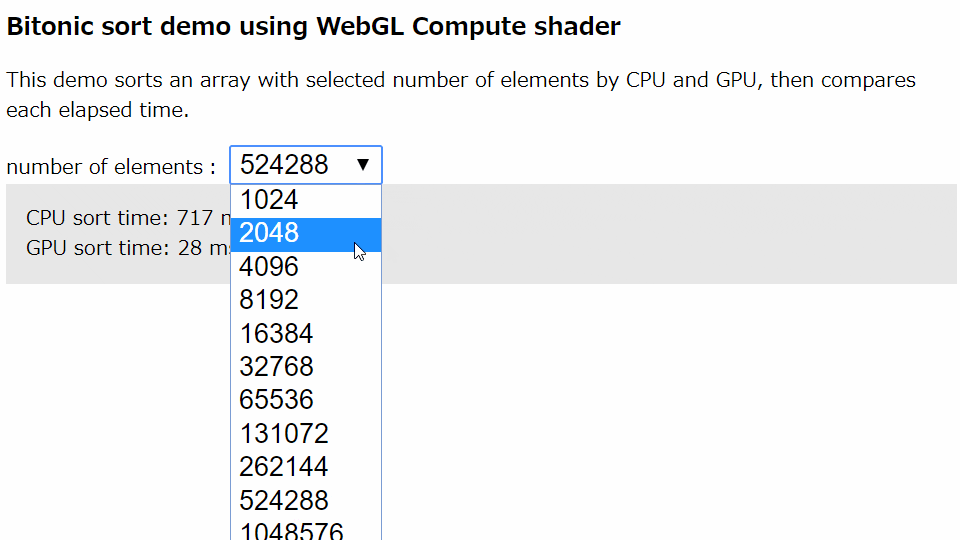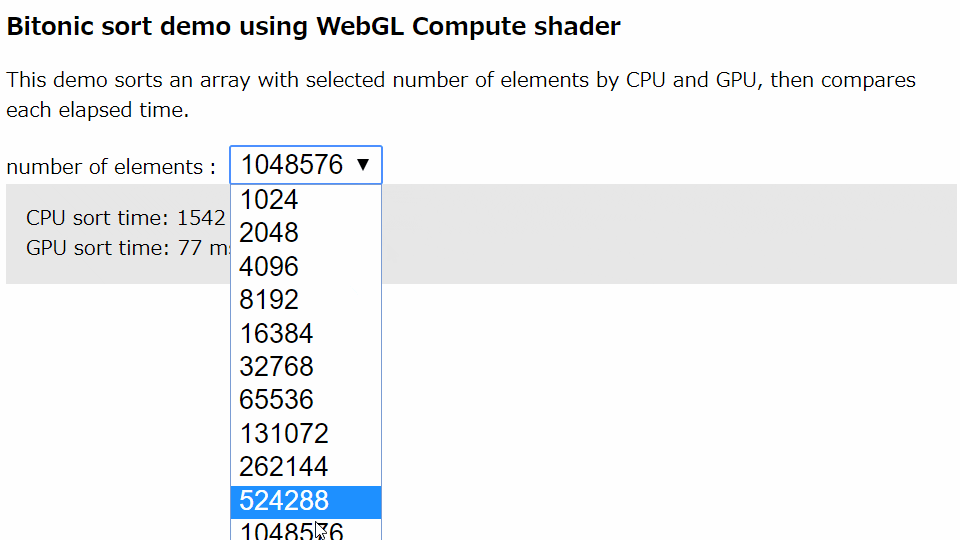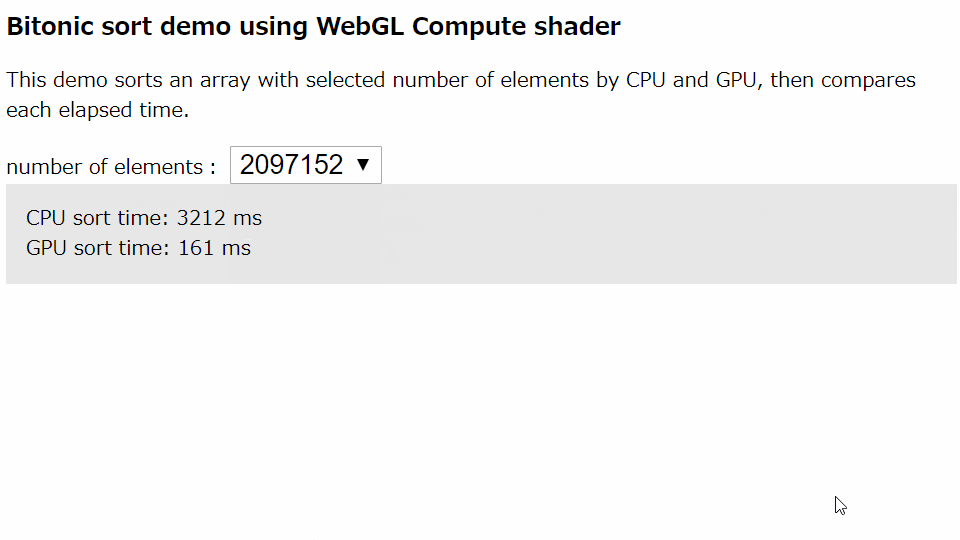
CPUソートでは単純にsort()の実行時間を計測します。GPUソートではGPUへの配列の転送~Compute shader実行~CPUへの配列の書き戻しまでの実行時間の計測します。繰り返し使用することを考え、シェーダーのコンパイルなどの初期化の時間は含めていません。筆者の環境1では要素数が2097152の場合、CPUでの実行時間3375msに対しGPUでは130msと、GPUのソートの方が25倍も高速でした。(6年も前のCPUとほぼ最新のハイエンドGPUを比較するのは卑怯かもしれませんが・・・)
Bitonicソートについては同じものをWebMetal(prototype WebGPU proposal by WebKit)でも実装しているので良かったら下記の記事も見てください。こちらであればiOSやmacOSでも動作します。
はじめてのCompute shader
まずは一番単純なCompute shaderを実装してみましょう。CPUで定義した配列をGPUへ転送し、Compute shaderで配列の各要素にそれぞれのスレッドID(0~7の値)を出力します。出力した値をCPUに転送し、正しく取得できれば成功です。
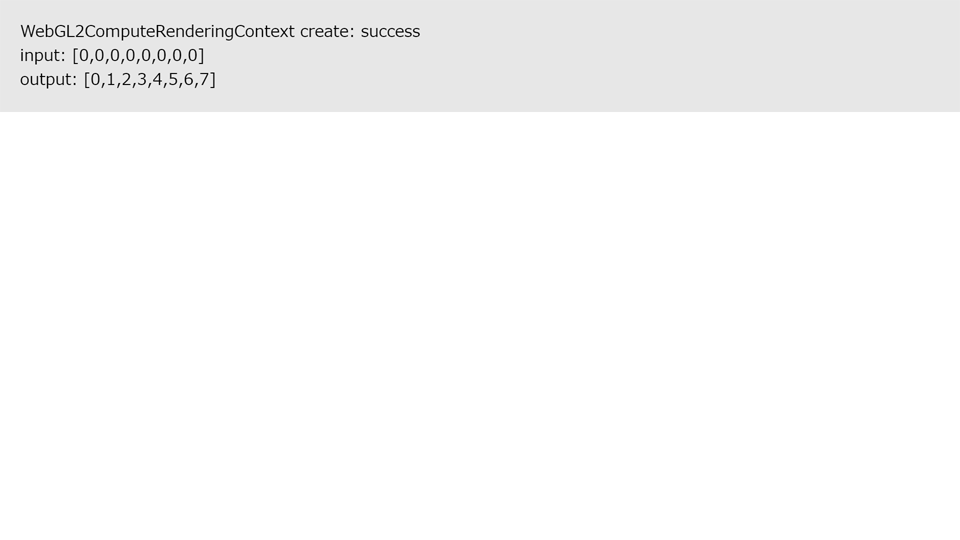
以下がソースコードです。それほど長くないので処理を1つずつ解説します。
// Canvas setup
const canvas = document.createElement('canvas');
// Create WebGL2ComputeRenderingContext
const context = canvas.getContext('webgl2-compute');
if(!context)
{
console.log('WebGL2ComputeRenderingContext create: failure');
return;
}
// ComputeShader source
// language=GLSL
const computeShaderSource = `#version 310 es
layout (local_size_x = 8, local_size_y = 1, local_size_z = 1) in;
layout (std430, binding = 0) buffer SSBO {
float data[];
} ssbo;
void main() {
uint threadIndex = gl_GlobalInvocationID.x;
ssbo.data[threadIndex] = float(threadIndex);
}
`;
// create WebGLShader for ComputeShader
const computeShader = context.createShader(context.COMPUTE_SHADER);
context.shaderSource(computeShader, computeShaderSource);
context.compileShader(computeShader);
if(!context.getShaderParameter(computeShader, context.COMPILE_STATUS))
{
console.log(context.getShaderInfoLog(computeShader));
return;
}
// create WebGLProgram for ComputeShader
const computeProgram = context.createProgram();
context.attachShader(computeProgram, computeShader);
context.linkProgram(computeProgram);
if(!context.getProgramParameter(computeProgram, context.LINK_STATUS))
{
console.log(context.getProgramInfoLog(computeProgram));
return;
}
// input data
const input = new Float32Array(8);
// create ShaderStorageBuffer
const ssbo = context.createBuffer();
context.bindBuffer(context.SHADER_STORAGE_BUFFER, ssbo);
context.bufferData(context.SHADER_STORAGE_BUFFER, input, context.DYNAMIC_COPY);
context.bindBufferBase(context.SHADER_STORAGE_BUFFER, 0, ssbo);
// execute ComputeShader
context.useProgram(computeProgram);
context.dispatchCompute(1, 1, 1);
// get result
const result = new Float32Array(8);
context.getBufferSubData(context.SHADER_STORAGE_BUFFER, 0, result);
console.log(result);
まずはCanvasからコンテクストを取得します。Compute shaderの機能はWebGL 1.0やWebGL 2.0とは別のコンテクストにより提供されます。getContext()の引数contextTypeにwebgl2-computeを指定してください。前述の通り対応環境であればCanaryのフラグを有効にしておくことでWebGL2ComputeRenderingContextオブジェクトが取得できます。
▼ コンテクストの取得
// Canvas setup
const canvas = document.createElement('canvas');
// Create WebGL2ComputeRenderingContext
const context = canvas.getContext('webgl2-compute');
次にシェーダーを記述します。Compute shaderはGLSL ES 3.1の機能なので、まずはバージョンディレクティブ#version 310 esを指定します。これをシェーダーソースの一行目(改行もダメ)に書かないとGLSL ES 3.1の構文が書かれたシェーダーはコンパイルエラーになります。このあたりはWebGL 2.0でもおなじみですね。
▼ バージョンディレクティブの指定
// ComputeShader source
// language=GLSL
const computeShaderSource = `#version 310 es
...
`;
次に出てくるのはwork groupのサイズ指定です。work groupはスレッド(Compute shaderの最小実行単位)を複数まとめたグループで、work group単位でShared memory(今回は出てきません)を共有します。ハードウェア観点でいうと同じwork group内のスレッドは同じGPUコアのグループ(NVIDIA GPUではStreaming Multiprocessor、AMD GPUではCompute Unit)で実行されるはずで、このサイズはCompute shaderの実行性能に関わってきますが、とりあえず今は単にスレッドをまとめたものと考えておいてください。
layout修飾子でwork group内のスレッド数を3次元で指定しますが、必ず3次元にする必要はありません。たとえばテクスチャなど2次元の計算対象に対してスレッドを割り当てて処理をしたいのであれば2次元に、3次元の空間を分割してスレッドを割り当てたいのであれば3次元に、と柔軟に指定できます。後述するスレッドIDを識別するビルトイン変数と組み合わせて、計算時の利便性のために3次元になっているんだと思います。
今回は1次元の長さ8の配列を処理したいので、8 * 1 * 1を指定しています。このサイズには上限があり、仕様上、getParameter()でGL_MAX_COMPUTE_WORK_GROUP_SIZE(0x91BF)およびGL_MAX_COMPUTE_WORK_GROUP_INVOCATIONS(0x90EB)を取得できる予定ですが、現状未実装です。GL_MAX_COMPUTE_WORK_GROUP_SIZEはx, y, zそれぞれの次元のwork groupスレッドの最大数を、GL_MAX_COMPUTE_WORK_GROUP_INVOCATIONSではwork group内の総スレッド(x * y * z)の最大数が取得できます。実際にはこの値は多くても1024だと思います。work group内の総スレッド数は最大でも1024に抑えておきましょう。
(2019/2/4 追記)getIndexedParameter(MAX_COMPUTE_WORK_GROUP_SIZE, index)およびgetParameter(MAX_COMPUTE_WORK_GROUP_INVOCATIONS)が実装されました。筆者の環境1で試したところ、MAX_COMPUTE_WORK_GROUP_SIZEは(1536, 1024, 64)が、MAX_COMPUTE_WORK_GROUP_INVOCATIONSは1536が取得できました。
余談ですがGLSLやHLSLではグループのサイズをシェーダーで指定しないとならないのですね・・・。CUDAやMetalではグループ内のスレッド数を実行時に指定できるため、サイズを変更するのにシェーダーの再コンパイルが必要なGLSLはちょっと不便に感じます。
▼ work groupのサイズ指定
layout (local_size_x = 8, local_size_y = 1, local_size_z = 1) in;
次にShader Storage Buffer Object(SSBO)を定義します。Compute shaderにはVertex shaderやFragment shaderのようにin / outにあたるものはなく、VRAM上のSSBOかテクスチャに直接アクセスして書き換えることで計算結果を出力します。今回はstd430のメモリレイアウトで0番のbindingに、dataというfloatの可変長配列をもった構造体をssboというインスタンス名で定義しています。定義の方法は一見複雑ですが、Uniform Buffer Object(UBO)に近いです。
▼ SSBOの構造定義
layout (std430, binding = 0) buffer SSBO {
float data[];
} ssbo;
いよいよCompute shaderの実際の計算処理に入ります。といっても、今回の例ではそれぞれのスレッドでスレッドIDを配列に代入するだけの簡単な処理です。gl_GlobalInvocationIDというGLSLの組み込み変数で、実行されているCompute shaderのスレッドIDが取得できます。繰り返しになりますが、Compute shaderの最小実行単位はスレッドです。今回、Compute shaderを8スレッドを起動しますが、それぞれのスレッドが正しいデータにアクセスするために、自身を識別するための情報が必要になります。その情報が格納されるのが下記のビルトイン変数です。
-
uvec3 gl_NumWorkGroups
後述のdispatch()で指定した、実行中のwork groupの数。すべてのスレッドで共通の値。今回のサンプルでは[1, 1, 1]。 -
uvec3 gl_WorkGroupID
現在のスレッドのwork groupのID。work group内のすべてのスレッドで共通の値。今回のサンプルではwork groupは1つなのですべて[0, 0, 0]となる。 -
uvec3 gl_WorkGroupSize
実行中のwork group内のスレッド数。すべてのスレッドで共通の値。さきほどシェーダー内でlayout修飾子で指定したものと同一。今回のサンプルでは[8, 1, 1]。 -
uvec3 gl_LocalInvocationID
現在のスレッドのwork group内のID。work group内のすべてのスレッドで一意となる。今回のサンプルではスレッドごとに[0, 0, 0]~[7, 0, 0]の値となる。 -
uvec3 gl_GlobalInvocationID
現在のスレッドのID。すべてのスレッドで一意となる。gl_WorkGroupID * gl_WorkGroupSize + gl_LocalInvocationIDと同じ意味。今回のサンプルではスレッドごとに[0, 0, 0]~[7, 0, 0]の値となる。 -
uint gl_LocalInvocationIndex
現在のスレッドのwork group内のIDを1次元にした値。gl_LocalInvocationIDとgl_WorkGroupSizeからも計算できる。今回のサンプルではスレッドごとに0~7の値となる。
詳しくはOpenGLのWikiを参照してください。
これで現在のスレッドIDがわかりました。それぞれのスレッドでSSBOの配列の担当するインデックスに、自身のスレッドIDを代入してみましょう。このように、Compute shaderでは配列やテクスチャにアクセスするためにスレッドIDが必ず出てきます。自身のローカル(work group内)スレッドIDがなんなのか、グローバルスレッドIDがなんなのかをしっかりとイメージしましょう。SSBOに値を書き込んだのでシェーダーの処理は以上となります。
▼ メイン処理 - SSBOへの書き込み
void main() {
uint threadIndex = gl_GlobalInvocationID.x;
ssbo.data[threadIndex] = float(threadIndex);
}
また、別に自身のスレッドIDの配列にしか書き込んではいけない決まりはありません。隣のスレッドIDのインデックスに書き込むことも、1つのスレッドで同じ配列の複数のインデックスに書き込むことも自由です。これが自身のインデックスにしか書き込みできないTransform Feedbackやテクスチャを使用したGPGPUとの大きな違いです。自由って素晴らしい。
▼ こんなSSBOへの書き込みも可能
void main() {
uint threadIndex = gl_GlobalInvocationID.x;
ssbo.data[threadIndex * 2] = float(threadIndex);
ssbo.data[threadIndex * 2 + 1] = float(threadIndex);
}
JavaScriptの処理に戻り、Compute shaderのシェーダーソースをコンパイルします。この部分はcreateShader()の第一引数にGL_COMPUTE_SHADER (0x91B9)を指定する以外はVertex shaderやFragment shaderのコンパイルと全く同じです。次にWebGLProgramオブジェクトを作成し、linkProgram()を実行しますが、リンク時にattachShader()に指定するのはCompute shaderのWebGLShaderのみです。通常のレンダリングパイプラインの場合はVertex shaderとFragment shaderのペアをリンクしますが、Compute shaderの場合はそれ単体をリンクします。
▼ WebGLProgramの作成
// create WebGLShader for ComputeShader
const computeShader = context.createShader(context.COMPUTE_SHADER);
context.shaderSource(computeShader, computeShaderSource);
context.compileShader(computeShader);
if(!context.getShaderParameter(computeShader, context.COMPILE_STATUS))
{
console.log(context.getShaderInfoLog(computeShader));
return;
}
// create WebGLProgram for ComputeShader
const computeProgram = context.createProgram();
context.attachShader(computeProgram, computeShader);
context.linkProgram(computeProgram);
if(!context.getProgramParameter(computeProgram, context.LINK_STATUS))
{
console.log(context.getProgramInfoLog(computeProgram));
return;
}
次にSSBOを作成します。まずはVertex Bufferなどと同じようにcreateBuffer()でバッファを作成します。WebGL2ComputeRenderingContextでは新しいバッファとしてGL_SHADER_STORAGE_BUFFER(0x90D2)が使用できるようになっているため、これを指定してbindBuffer()でバッファをバインドします。バインドしたSSBOにbufferData()で長さ8のFloat32Array配列を転送します。
作成したSSBOをbindBufferBase()でシェーダーのSSBOに紐づけます。第二引数にはさきほどシェーダー内で定義したSSBOのbindingに指定した0番を指定します。bindBufferBase()に関しても第一引数にGL_SHADER_STORAGE_BUFFERを指定する以外はUBOと同じですね。
▼ SSBOの作成
// input data
const input = new Float32Array(8);
// create ShaderStorageBuffer
const ssbo = context.createBuffer();
context.bindBuffer(context.SHADER_STORAGE_BUFFER, ssbo);
context.bufferData(context.SHADER_STORAGE_BUFFER, input, context.DYNAMIC_COPY);
context.bindBufferBase(context.SHADER_STORAGE_BUFFER, 0, ssbo);
最後に通常のレンダリングと同じようにuseProgram()で使用するWebGLProgramを指定します。これでCompute shaderを実行する準備がすべて整いました。dispatchCompute()で計算を実行しましょう。
dispatchCompute()は通常のレンダリングパイプラインでいうドローコールのようなものです。引数には実行するwork groupの数をこれまた3次元で指定します。シェーダー内で指定したwork groupのサイズ * dispatchCompute()で指定したwork groupの数ぶんのスレッドが起動し、計算が実行されます。今回はwork groupは1つなので(1, 1, 1)を指定しています。
▼ Compute shaderの実行
// execute ComputeShader
context.useProgram(computeProgram);
context.dispatchCompute(1, 1, 1);
実行が終わったら計算結果をSSBOから受け取ります。getBufferSubData()でバインドしているSSBOの値をVRAMから転送します。うまく実行されていれば[0, 1, 2, 3, 4 ,5, 6, 7]が出力されます。
▼ 計算結果の読み出し
// get result
const result = new Float32Array(8);
context.getBufferSubData(context.SHADER_STORAGE_BUFFER, 0, result);
console.log(result);
WebGL 2.0 Computeの詳しい仕様は下記の提案資料を参照してください。
(2019/3/20 追記)Draft版の仕様がリリースされました。
TIPS
いくつか開発でハマりそうな(ハマった)点を共有します。
SSBOのbindingはUBOと共有される
SSBOの宣言でbindingを指定しますが、この番号はUBOと同じ空間が使用されるため、同じ番号を指定するとコンフリクトして意図しない結果となります。SSBOをUBOと併用する場合は別の番号をつけましょう。
(2019/3/22 追記)勘違いでした。UNIFORM_BUFFERとSHADER_STORAGE_BUFFERは別空間のインデックスを持っています。
SSBOのメモリレイアウトに注意
今回はstd430を指定していますが、このあたり気をつけないとJavaScriptで宣言した配列とシェーダー内で各スレッドが配列インデックスから参照できるデータがズレることがあります。以下の記事が参考になりました。
よくわからないけどなんかズレてるなって場合は16バイトアライメントを意識して適当にパディングすればだいたい動きます。てへ。
work groupのサイズに注意
work groupのサイズは最大1024と書きましたが、必ずしも1024にするのが最速というわけではありません。合計スレッド数が同じでも、work group数を増やしてwork groupサイズを小さくした方が早くなる場合もあります。最適なバランスはプログラムによるので、いろいろ試して計測して探ってみましょう。おおむね128、256、512あたりにするのが最もパフォーマンスが出ることが多いように思います。
このあたりはシェーダー内で使用するレジスタ数やShared memoryサイズによって、同時実行できるスレッド数が変わってくることが関係しているように思います。現代GPUの計算効率はメモリアクセスとの戦いです。ひとつのGPUコアのグループで同時実行できるスレッド数が多ければ、あるスレッドがメモリにアクセスするのを待っている間に別のスレッドに切り替えて処理を実行することでメモリアクセスのレイテンシを隠蔽できます。なるべく多くのスレッドを同時実行できるようシェーダーで使用するリソースを節約し、work groupのサイズを調整しましょう。CUDAでいうoccupancyというやつですね。
WebGLの今後
2018年8月に開催されたSIGGRAPH 2018のKhronos Groupの発表によると、年内にはCompute shaderの機能の実装が完了する予定とのことでしたが、現時点でD3DバックエンドでSSBOが正しく機能していないところをみると、少し遅れているのかもしれません。
WebGL 2.0 Compute拡張はOpenGL ES 3.1のWebGL実装です。OpenGL ES 3.1の大きな新機能として、Compute shaderの他にIndirect Drawingがあります。Indirect Drawingについては詳しくありませんが、描画APIで使用するパラメータをGPUのバッファで指定できる機能とのことです。Compute shaderとの相性が良さそう。Compute shaderの実装が完了したらこちらの実装が始まると思われます。楽しみですね。
他にはGeometry shaderが来るようです。Geometry shaderはVertex shaderとFragment shaderの間に位置するステージで、シェーダーで頂点を増減できます。Compute shaderと並んでむちゃくちゃ楽しみな機能です。
まとめ
以上、WebGLのCompute shaderの現状及び実装方法についてでした。まだまだ開発段階で実装されているブラウザもなく、使用するにはVery Earlyですが、Compute shaderは大きな可能性を秘めた機能です。来るWebGPUのためにもCompute shader、並びにGPUの並列プログラミングに慣れておくのは悪くない選択肢ではないでしょうか。
今回は解説できませんでしたが、SSBOをVertex Buffer Objectとしてバインドすることで、Compute shaderの計算結果をCPUを経由せずにそのままVertex shaderで使用できます。また、Shared memoryは高速なオンチップメモリを使用してwork group内でデータを共有できます。冒頭のデモではそのへんの機能も使っているのでこれらのお話もそのうちしようと思います。