6/19 に開かれた DevOps Guru ハンズオンに参加しました。
AWSの基礎を学ぼう 特別編 最新サービスをみんなで触ってみる DevOps Guru
ハンズオンは、以下にて公開されています。
DevOps Guru について
2020年 re:Invent で アナウンスされ、2021/5/4 に GA になったサービスです。
Amazon DevOps Guru が一般サービス提供開始となり東京リージョンでもお使いいただけます
DevOps Guru は、アプリケーションが平常時と逸脱した動きをしたことを検知してくれます。
例えば、レイテンシー増加、エラー率増加などが「平常時と逸脱」を検知する対象です。
DevOps Guruが評価する対象と金額
1リソースあたり、 0.0028 USD ~ 0.0042 USD/h かかります。
ピックアップすると、以下のようなリソースが対象です。
- Lambda関数
- S3バケット
- API ゲートウェイのパス
- CloudFront
- ALB
- DynamoDB テーブル
- ECS, EKS のサービス
- SNSトピック
対象は、価格表に記載されています。リソースによって値段が違います。
また、この対象リソースは徐々に増えていくと思われます。
「気づいたら監視対象リソースが増えて、月額も跳ね上がっていたということにならないように注意」とのお話もありました。
サービスの所感
いいところ
- パフォーマンス低下やエラー発生時に、「こういう直し方がある」までレコメンデーションを出してくれるのは嬉しい。AWS知識が少ない人でも、調査のとっかかりになる。
- 設定が簡単。
気をつけたいところ
- あくまで機械学習で通常とずれたのを見つけるサービス。学習内容の制御もできないので、「これだけ」で監視を終えるのは乱暴。補助的な使い方が良さそう。
- 監視対象は「リージョン内全部」か「指定したスタック」のいずれか。スタック指定の場合、新規に作ったスタックをここに含めていく管理は悩ましいかも。
- スタックを作って、2時間は学習時間。平常状態を見せて、ベースラインを作らないといけない。登録直後に変なノイズが入らないかは注意してみておかないと、誤検知だらけになりそう。
この記事で話すこと
ハンズオンの途中で教えていただいたナレッジの共有と、所感を話します。
設定手順などは、前述のハンズオンリンク自体をご参照いただくのが良いと思います。
ハンズオンに従うので、今回の対象は「事後的インサイト」(起きてしまった問題) のみです。
「予測的インサイト」(これからアプリケーションに影響を与えそうな問題)は対象外です。
ハンズオンの所要時間
おおよそ 3時間です。
- 初期設定 30分
- 待ち時間(学習時間) 2時間
- 事後確認 30分
ハンズオンの内容
以下のステップで行います。
- 評価対象の環境を作る
- DevOps Guru で学習開始する。
- 評価対象の環境で異常動作を起こし、観測させる。
ハンズオンが終わると、以下のような 異常が検知を確認することができます。
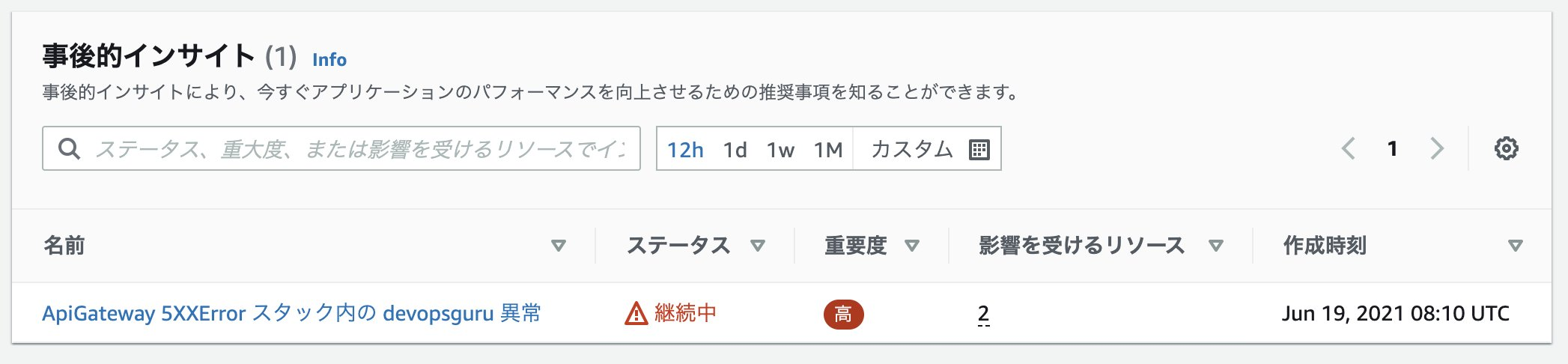
評価対象の環境を作る
github上の CFnテンプレートを使って、以下のような構成を作ります。

ファイルをダウンロードするのが面倒だったので、デザイナーの画面に yaml を貼り付けて S3 にアップロードするという手順を取りました。

スタックが完成したら、DynamoDB にデータを登録します。
今回作った環境はURLを叩くと DynamoDB 内のjsonを表示してくれるものです。表示して差し支えない Key/Value を登録していきます。
DevOps Guru で学習開始する。
作業は簡単。
- DevOps Guru を有効化する。
- 対象のスタックを選ぶ。
以上!
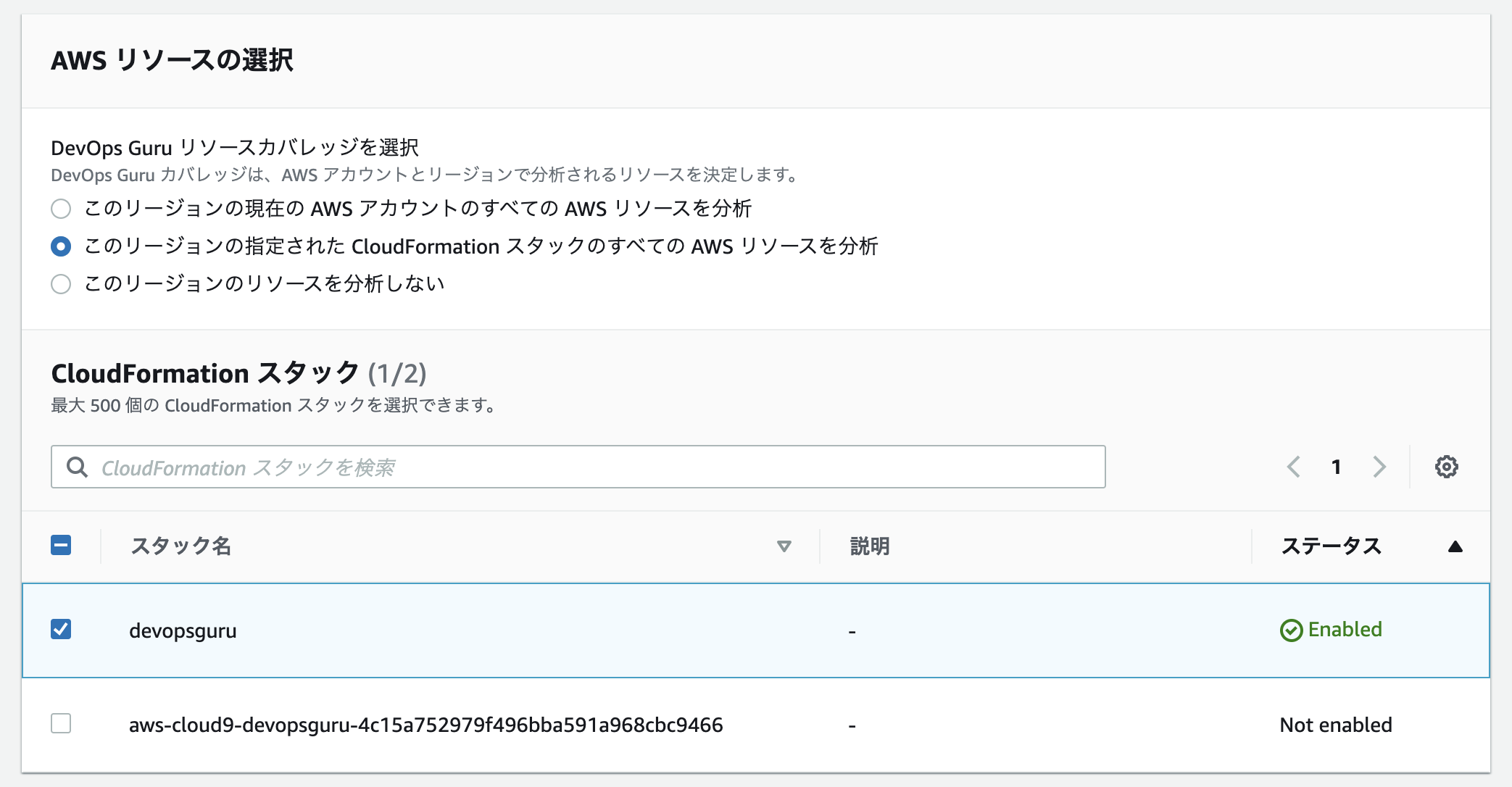
画面にはどのくらいのリソースが入っているかは表示されないので、そこは事前に確認しましょう。
一応コスト見積もりツールを使うと、スタックごとの予想金額を出してくれます。
結構時間かかりました。(数分では終わらず、放置していたうちに終わったのでどのくらいかよくわかりません)

スタックを選択したら、そのまま2時間待ちます。
ちなみに再学習は、「一度AWSリソースの選択で "このリージョンのリソースを分析しない" に変えてから、もう一度選び直す」ことで対応できるそうです。
監視対象のスタックを追加する場合は、一覧のチェックを増やして保存するだけなので、既存スタックの学習状況には影響ありません。
評価対象の環境で異常動作を起こし、観測させる。
2時間経ったら、問題を起こしてみます。
なお、画面上は特に「学習が終わった」という表示は見当たりませんでした。
「2時間経ったからそろそろいいだろう」ぐらいの感覚で始めました。
github上に用意したスクリプトを 6並列くらいで動かし、評価対象サイトにアクセスさせます。
Cloud9 かローカルから、複数ターミナルから実行するのが推奨です。
動作が見えなくなりますが、以下を実行すれば CloudShell からでもできます。
(python3 sendAPIRequest.py > /dev/null 2>&1) &
私は実施した時、 > /dev/null 2>&1 をつけ忘れたので画面が大変なことになりました。(標準出力が出続けて、自分が打ってるコマンドが見えない状態)
10分ほど待つと、異常がダッシュボードに表示されます。
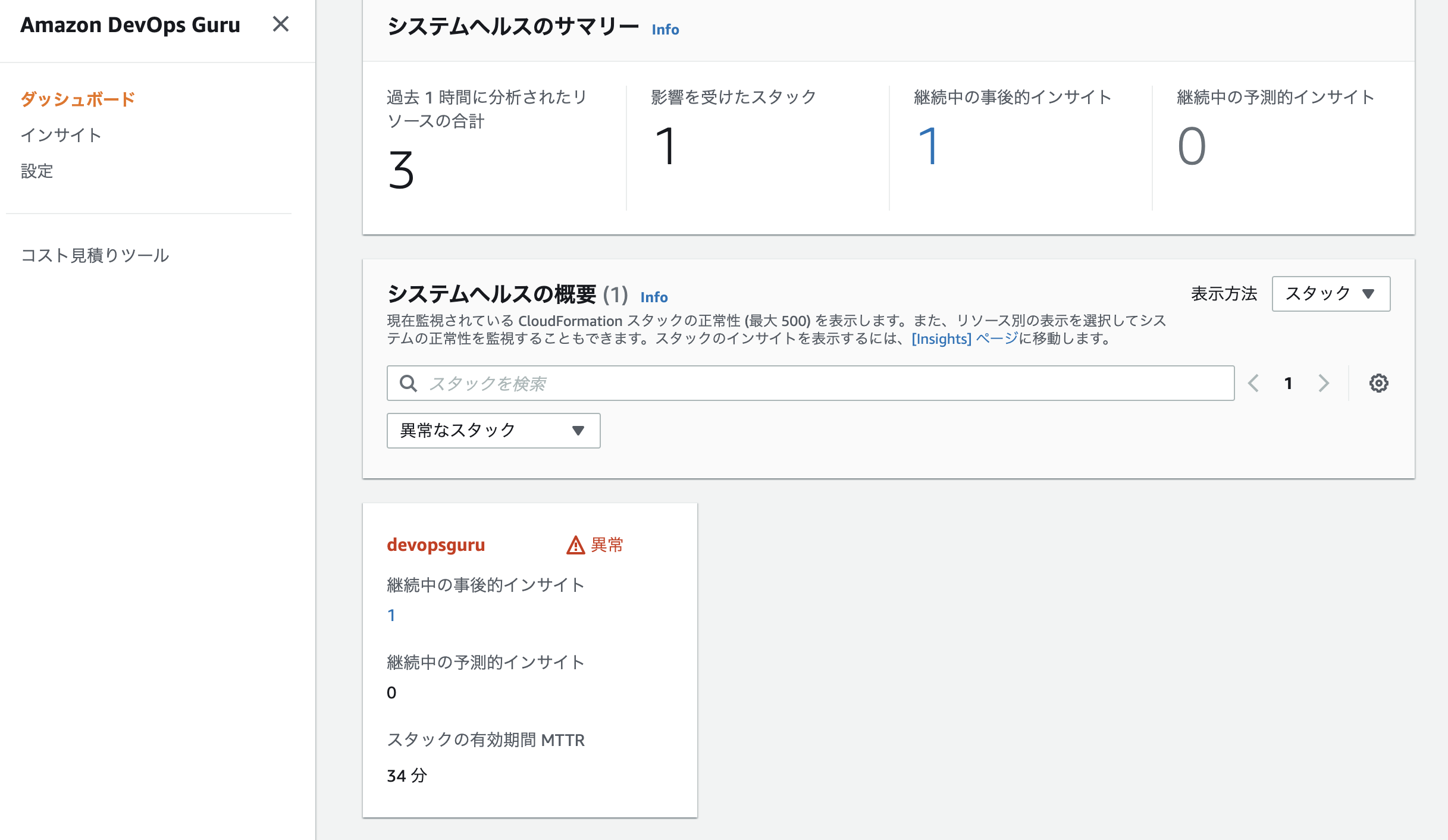
数値を押すと、インサイト画面に移動します。
異常の情報は、以下のパーツで構成されていました。
- インサイトの概要
- 集約されたメトリクス/グラフ化された異常
- 関連するイベント
- レコメンデーション
インサイトの概要
問題が継続しているか、いつ発生したかが見れます。一覧と情報は変わらないですね。

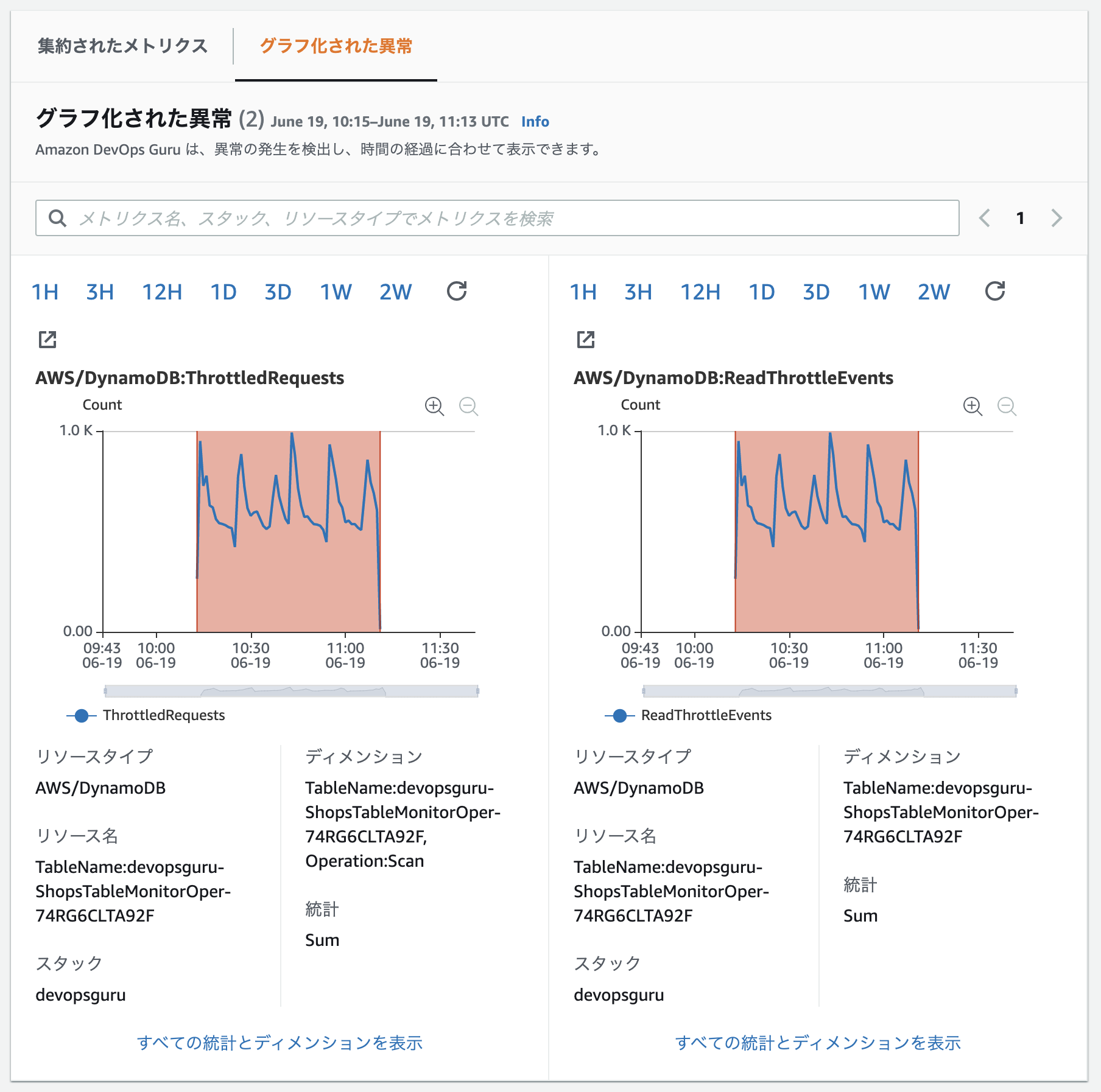
集約されたメトリクス/グラフ化された異常
集約されたメトリクスで、発生した問題の時系列が見れます。

API Gatewayのケースなど、アクセスが増え、エラーが増え。。。が順番に起きてるのが見えますね。

グラフ化された異常タブでは、異常時のメトリクス推移が見れます。
関連するイベント
問題前後の、関連ありそうなイベントが表示されます。
今回表示されてるのは Cloud9 のスタック再作成。
実際は関係ないのですが、容疑者として挙げられています。
確かに、このCloud9は悪さをしようと思ったけれど使わなかったインスタンス。

レコメンデーション
どんな対応がおすすめか、を教えてくれます。
ここが機械学習活用ポイントで、AWS内でどのような対応があるか記事を都度確認し、自動的におすすめがアップデートされていっているそうです。
ここでは、DynamoDBのスロットリング問題が指摘されています。
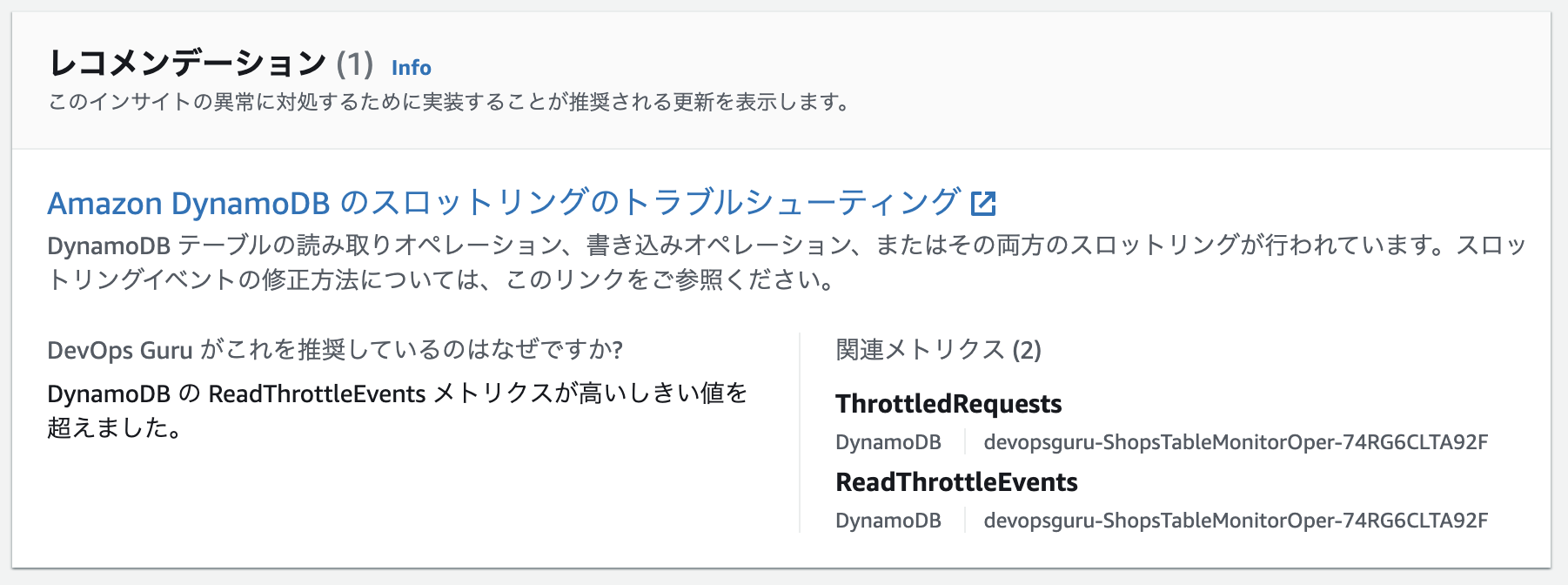
トラブルシュートサイトが案内されます。
Amazon DynamoDB のスロットリングのトラブルシューティング
API Gateway側だと、以下のようなサイトの案内がありました。
闇雲に調べず、とりあえずこの辺。。。がわかるのは本当にありがたい。
最後に
DevOps Guru のハンズオンの結果、会の途中のお話や感想も交えながらかいてみました。
簡単にセットアップできるので、興味ある方はぜひハンズオンやってみましょう。終わったら削除を忘れずに。
金額面は気になりつつ、チームのスキル状況によってはこのサービスのアシストはありがたいものになると思います。
今後成長していくサービスだとも思いますので、今後にも期待ですね!
最後にもう一つ。
今回記事を書くにあたり、3回に分けてエラースクリプトを実行しました。
やるたびに、「異常」の理由が減っていきました。
徐々に、「異常」がベースラインに組み込まれていった結果ですかね。ある程度安定したサービスで実行しないと、すぐにベースラインがおかしくなるのかもしれないと思いました。