この記事はTokyo City University Advent Calendar 2019 1日目の記事です。
https://adventar.org/calendars/4282
はじめに
こんにちは!東京都市大学という大学で情報系の勉強をしています、おーじぇい( @920oj )と申します。
この度、都市大のアドベントカレンダーを建てましたので、自分は
「Pythonで大学の100円朝食を知らせてくれるLINEbotを作った話」を書きます!
背景
弊学には朝食を100円で食べることができる非常にお得な制度があります。さらに自分は地方から上京して一人暮らしなので、金欠にはもってこいです。

これが100円なのだ
毎朝このメニューは食堂のWebサイトに掲示されるのですが、このWebサイトが曲者で、アクセスするためにアプリを通したり学校ポータルサイトを通さなければなりません。
そこで、毎朝自動で食堂Webサイトをスクレイピングし、その日の100円朝食をLINEに通知してくれる(LINE Notify)を作ることにしました。
筆者の環境
Python v3.7.1
pip 19.1.1
Windows 10 v1903
できたもの
東京都市大横浜キャンパス学生食堂 100円朝食通知bot
https://github.com/920oj/TCU-YC-Breakfast-Notify-Bot
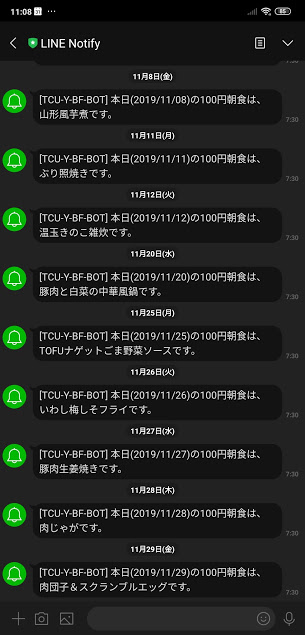
こんな感じに毎日朝7時30分に(100円朝食がある場合だけ)通知が飛んできます!
実装を考えていく
まずは学食のWebサイトをBeautifulSoupで取得します。学食Webサイトを閲覧するにはログインが必要なので、一度POSTを投げて認証してからセッションIDを使ってこねくり回そうという指針を建てていました。
しかし、よく見てみたら認証なんてものは存在せず、CookieにそのままIDとパスワードを平文で書き込んで認証、という感じになってました。(いいのか?)
(本来なら一度認証(POST)して、そのセッションIDに認証が通ったということが紐付かれていて、その後のリクエストが通る、ということだと思うのですが、何故かPOSTせずとも動いてしまってるので良しとします)(本来は良くないです)
セッション関係
とりあえず、ログインページに行くと「セッションキー」と「セッションID」というものが付与されるようなので、まずはこれを取得するところからはじまります。
def get_sessionid():
# 初期Cookieの取得処理
r = requests.get('https://livexnet.jp/local/default.asp')
first_access_cookie = str(r.headers['Set-Cookie'])
# "ASPSESSIONID+任意の8桁の英大文字"(英大文字24文字)の取得
asp_session = str(first_access_cookie[first_access_cookie.find("ASPSESSIONID"):first_access_cookie.find("; secure")])
asp_session_key = str(asp_session[0:asp_session.find("=")])
asp_session_id = str(asp_session[asp_session.find("="):].replace('=',''))
return asp_session_key, asp_session_id
フレームワークはASP.NETのようです。ASPSESSIONIDについては、末尾に8桁の英大文字が追加されるようなので、これも取得します。
この関数の返り値をasp_session_key, asp_session_idとして二種類を返します。
Cookieを設定~スクレイピング
def get_breakfast_info(key,id):
# Cookieを用意(今後情報が変更される可能性あり)
site_cookies = {
key: id,
'KCD': '02320',
'company_id': SITE_ID,
'company_pw': SITE_PASS,
'wrd': 'jp',
'dip': '0',
'ink': 'a',
'bcd': '02320',
'val': 'daily'
}
# メニュー・栄養表ページにアクセス
url = 'https://reporting.livexnet.jp/eiyouka/menu.asp?val=daily&bcd=02320&ink=a&col=&str=' + today_data
r = requests.get(url, cookies=site_cookies)
r.encoding = r.apparent_encoding
# HTML解析
all_html = r.text.replace('<br>','')
souped_html = BeautifulSoup(all_html, 'lxml')
try:
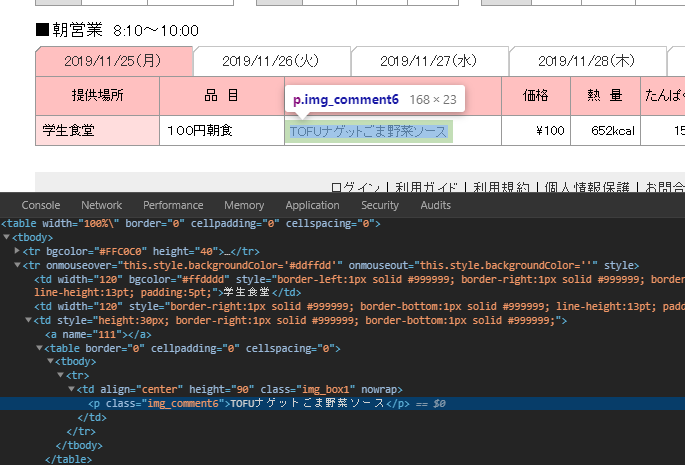
breakfast = souped_html.find('p', class_="img_comment6").string
return breakfast
except:
return False
Chromeの開発者ツールを使って、どんなCookieが設定されるかを確認します。
確認したら、それに沿ってcookieを用意してあげてbeautifulsoupに読み込ませるので、辞書を用意します。
keyはさっき取得したセッションキーと、idはセッションIDを読み込ませてます。(これは変数の名前がダメです。もっとわかりやすいものにしましょう)
先程も述べたとおり、SITE_IDとSITE_PASSで認証IDとパスワードを平文で読み込ませているようなので(?)この通りに指定します。
(これセッションIDを取得した意味無いのでは……?詳しい方いたら教えて下さい)
あとはHTML解析をしてくれるlxmlに読み込ませて、その中で「img_comment6」というクラス要素を抜き出してやればOKです!
LINEに飛ばす(LINE Notify)
def post_line(result):
post_data = '本日(' + today_data + ')の100円朝食は、' + result + 'です。'
line_api_headers = {"Authorization" : "Bearer "+ LINE_TOKEN}
line_payload = {"message" : post_data}
r = requests.post(LINE_API_URL ,headers = line_api_headers ,params=line_payload)
return r.status_code
あとはLINE Notifyに飛ばすだけです。LINE Notifyではヘッダーに認証情報とメッセージ内容を乗っけて、APIのエンドポイントにPOSTを投げてやると予め設定しておいたトークに情報を流すことができます。
メイン処理を書く
def main():
print('東京都市大学100円朝食メニュー表示プログラム by 920OJ')
print('今日は' + today_data + 'です。')
session = get_sessionid()
session_key = session[0]
session_id = session[1]
print('初期認証情報を取得しました。' + session_key + 'は' + session_id + 'です。3秒間待機します……')
sleep(3)
result = get_breakfast_info(session_key,session_id)
if not result:
print('情報を取得できませんでした。100円朝食が実施されていない可能性があります。')
sys.exit()
print('今日の100円朝食は、' + result + 'です。LINEに通知を送信します。')
post_status = post_line(result)
if post_status == 200:
print('LINE通知に成功しました。プログラムを終了します。')
else:
print('LINE通知に失敗しました。レスポンスは' + str(post_status) + 'です。プログラムを終了します。')
if __name__ == "__main__":
main()
あとは先程作った関数を組み立てていく要領でメインとなる処理を書いていきます。
最後に if __name__ == "__main__": と書くのは、もしこのプログラムがどこかでimportされたときに処理が勝手に実行されるのを防ぐためです。実行中のファイルの名前が一致していたらmain()関数を呼び出す、という仕組みにするのは初めて知りました。
運用する
借りているLightsail(VPS)にホストして、cronで定期実行しています。
実行すると即時にその日の朝食を取得しに行くので、毎朝7時30分にcron実行することで定期実行を実現しています。
最後に
実を言うとこのコードは4月に作ったものなので、今みると変数名がよろしくなかったり実装があやふやなところがあります。もう少し暇になったらコードをリライトしてみたいです。
明日はケーさん( @ke_odakyu9000 )の記事です!よろしくおねがいします!
https://adventar.org/calendars/4282