パーソンリンク アドベントカレンダー25日目です!🎉
今日で2021アドベントカレンダーも最終日です。
個人的には今年のアドベントカレンダーは結構書いたなーと思っております。(文字量は気にしない!)
何を作ったか
Qiita表彰プログラムのパクリで社内表彰集計ロジックを作りました。
キャプチャ
表紙
順位




内容
技術スタック
python3系
flask
Nuxt
kibelaAPI(GraphQL)
集計API
kibela APIを叩いて集計結果を返すAPI(全記事参照してしまうので取得までに時間かかります。。他にいい方法あれば知りたい。)
import requests
import json
import datetime
import math
import collections
from flask import Flask
from flask_cors import CORS
app = Flask(__name__)
CORS(app)
# kibela上で取得できるtokenを設定(書き込みがないのであればreadのみのtokenをお勧めします)
KIBELA_ACCESS_TOKEN = '****'
# urlを設定
url:str = 'https://*****.kibe.la/api/v1'
# headersを設定
headers:dict = {
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": "Bearer " + KIBELA_ACCESS_TOKEN,
}
# ヘルスチェック用に一応APIを作っておいた
@app.route('/hc')
def hc():
return {"status": "success"}
#
@app.route('/kibela')
def kibela():
# 下準備
# ユーザ一覧取得
# ユーザ名を取得していいが、任意だったりする項目があるので確実なメールアドレスを取得
# 画像も取得はできるがCSPでhtmlからはアクセスできなかったので不要なものは取得せずcost削減ということで取得せず
user_list_query:str = """
{
users(first:1000) {
nodes {
email
}
}
}
"""
user_list_response = requests.post(
url,
json={'query': user_list_query},
headers=headers
)
# 削除済みのユーザも取得できてしまう
user_list:dict = json.loads(user_list_response.text)['data']['users']['nodes']
# グループ一覧取得
# プライベートにしているものは全員が閲覧できるわけではないので貢献ポイントとはさせない
group_list_query:str = """
{
groups(first:1000) {
nodes {
id
isPrivate
}
}
}
"""
group_list_response:requests.models.Response = requests.post(
url,
json={'query': group_list_query},
headers=headers
)
# プライベートではないもののみを抽出
group_list:list = [group_dict.get('id') for group_dict in list(filter(lambda x: x['isPrivate'] == False, json.loads(group_list_response.text)['data']['groups']['nodes']))]
# 集計用のリストを用意
send_note_user_list:list = []
note_like_user_list:list = []
like_user_list:list = []
comment_user_list:list = []
comment_get_like_user_list:list = []
comment_put_like_user_list:list = []
# 本処理
note_list:list = []
# 一気に全ての投稿を取得したいがcostの関係上不可なので5件ずつ取得を試みるために一旦全部で何件あるか把握させる
note_length_query:str = """
{
notes {
totalCount
}
}
"""
note_length_response:requests.models.Response = requests.post(
url,
json={'query': note_length_query},
headers=headers
)
# endCursorを指定することで5件取得後の次の5件のスタート位置を指定できる
end_cursor:str = ""
# 全件/5を切り上げした数を繰り返して投稿を取得しlistに追加していく
for i in range(math.ceil(int(json.loads(note_length_response.text)['data']['notes']['totalCount'])/5)):
note_list_query:str = """
{
notes(first:5, after:"%s") {
pageInfo {
endCursor
}
nodes {
id
author {
email
}
createdAt
content
groups {
id
}
comments(first:25) {
totalCount
nodes {
author {
email
}
likers(first:35) {
totalCount
nodes {
email
}
}
}
}
likers(first:50) {
totalCount
nodes {
email
}
}
}
}
}
""" % end_cursor
note_list_response:requests.models.Response = requests.post(
url,
json={'query': note_list_query},
headers=headers
)
# 2021年中の作成でプライベートではないグループ所属分を抽出
note_list.extend(list(filter(lambda x: datetime.datetime.strptime(x['createdAt'], '%Y-%m-%dT%H:%M:%S.%f%z').year > 2020 and list(set(group_list) & set([note_group_dict.get('id') for note_group_dict in x['groups']])), json.loads(note_list_response.text)['data']['notes']['nodes'])))
end_cursor:str = str(json.loads(note_list_response.text)['data']['notes']['pageInfo']['endCursor'])
# 記事投稿についたコメントやいいねをかくlistにemailとして追加
for note in note_list:
send_note_user_list.extend([note['author']['email']])
for noteLike in note['likers']['nodes']:
note_like_user_list.extend([note['author']['email']])
like_user_list.extend([noteLike['email']])
for noteComment in note['comments']['nodes']:
comment_user_list.extend([noteComment['author']['email']])
for commentLike in noteComment['likers']['nodes']:
comment_get_like_user_list.extend([noteComment['author']['email']])
comment_put_like_user_list.extend([commentLike['email']])
# emailにてユーザの数をカウントし、重み付により数値を出す
# 記事投稿 3 sendNote
# 投稿記事についたいいね 1 noteLike
# 他人の記事へのいいね 1 like
# 他人の記事へのコメント 2 comment
# 自分のコメントについたいいね 1 commentGetLike
# 他人のコメントへのいいね 1 commentPutLike
send_note_user_dict:dict = dict(collections.Counter(send_note_user_list))
note_like_user_dict:dict = dict(collections.Counter(note_like_user_list))
like_user_dict:dict = dict(collections.Counter(like_user_list))
comment_user_dict:dict = dict(collections.Counter(comment_user_list))
comment_get_like_user_dict:dict = dict(collections.Counter(comment_get_like_user_list))
comment_put_like_user_dict:dict = dict(collections.Counter(comment_put_like_user_list))
for key, value in send_note_user_dict.items():
send_note_user_dict[key] = value * 3
for key, value in comment_user_dict.items():
comment_user_dict[key] = value * 2
# keyがemailなのでkeyを元にvalueを計算(下記URLを参考にした)
# https://www.think-self.com/programming/python/double-dict-key-value/
rate_dict:dict = {}
for k in (send_note_user_dict.keys() | note_like_user_dict.keys() | like_user_dict.keys() | comment_user_dict.keys() | comment_get_like_user_dict.keys() | comment_put_like_user_dict.keys()):
send_note_user_dict_num = int(send_note_user_dict.get(k) or 0)
note_like_user_dict_num = int(note_like_user_dict.get(k) or 0)
like_user_dict_num = int(like_user_dict.get(k) or 0)
comment_user_dict_num = int(comment_user_dict.get(k) or 0)
comment_get_like_user_dict_num = int(comment_get_like_user_dict.get(k) or 0)
comment_put_like_user_dict_num = int(comment_put_like_user_dict.get(k) or 0)
rate = send_note_user_dict_num + note_like_user_dict_num + like_user_dict_num + comment_user_dict_num + comment_get_like_user_dict_num + comment_put_like_user_dict_num
rate_dict.setdefault(k, rate)
# ランキングにしたいのでソート
rank_result:dict = dict(sorted(rate_dict.items(), key=lambda x:x[1], reverse=True))
rank:int = 1
rate_result:dict = {}
# メールアドレスのドメインを削除しユーザ名っぽくする
for k, v in {k:rank_result[k] for k in list(rank_result)[:10]}.items():
child_result:dict = {
"user": k.replace('@****.co.jp', ''),
"icon": list(filter(lambda x: x['email'] == k, user_list))[0]['avatarImage']['url'],
"point": {
"all": v,
"send": send_note_user_dict.get(k) / 3 if send_note_user_dict.get(k) else 0,
"comment": comment_user_dict.get(k) / 2 if comment_user_dict.get(k) else 0,
"like": like_user_dict.get(k) if like_user_dict.get(k) else 0
}
}
rate_result["rank%s" % rank] = child_result
rank+=1
# おまけ1 いいねが一番多かったリストを上記のリストを使って取得
like_list:dict = {}
for note in note_list:
like_list[note['id']] = note['likers']['totalCount']
like_result:dict = dict(sorted(like_list.items(), key=lambda x:x[1], reverse=True))
note_like_query:str = """
{
note(id: "%s") {
author {
email
}
title
url
}
}
""" % list(dict({k:like_result[k] for k in list(like_result)[:1]}.items()).keys())[0]
note_like_response:requests.models.Response = requests.post(
url,
json={'query': note_like_query},
headers=headers
)
# おまけ2 コメントが一番多かったリストを上記のリストを使って取得
comment_list:dict = {}
for note in note_list:
comment_list[note['id']] = note['comments']['totalCount']
comment_result:dict = dict(sorted(comment_list.items(), key=lambda x:x[1], reverse=True))
note_comment_query:str = """
{
note(id: "%s") {
author {
email
}
title
url
}
}
""" % list(dict({k:comment_result[k] for k in list(comment_result)[:1]}.items()).keys())[0]
note_comment_response:requests.models.Response = requests.post(
url,
json={'query': note_comment_query},
headers=headers
)
result:dict = {
"contribution": rate_result,
"like": {
"user": json.loads(note_like_response.text)['data']['note']['author']['email'].replace('@****.co.jp', ''),
"icon": list(filter(lambda x: x['email'] == json.loads(note_like_response.text)['data']['note']['author']['email'], user_list))[0]['avatarImage']['url'],
"title": json.loads(note_like_response.text)['data']['note']['title'],
"url": json.loads(note_like_response.text)['data']['note']['url'],
"count": list(dict({k:like_result[k] for k in list(like_result)[:1]}.items()).values())[0]
},
"comment": {
"user": json.loads(note_comment_response.text)['data']['note']['author']['email'].replace('@****.co.jp', ''),
"icon": list(filter(lambda x: x['email'] == json.loads(note_comment_response.text)['data']['note']['author']['email'], user_list))[0]['avatarImage']['url'],
"title": json.loads(note_comment_response.text)['data']['note']['title'],
"url": json.loads(note_comment_response.text)['data']['note']['url'],
"count": list(dict({k:comment_result[k] for k in list(comment_result)[:1]}.items()).values())[0]
}
}
return result
if __name__ == "__main__":
app.run(host='localhost', port=8000, debug=True)
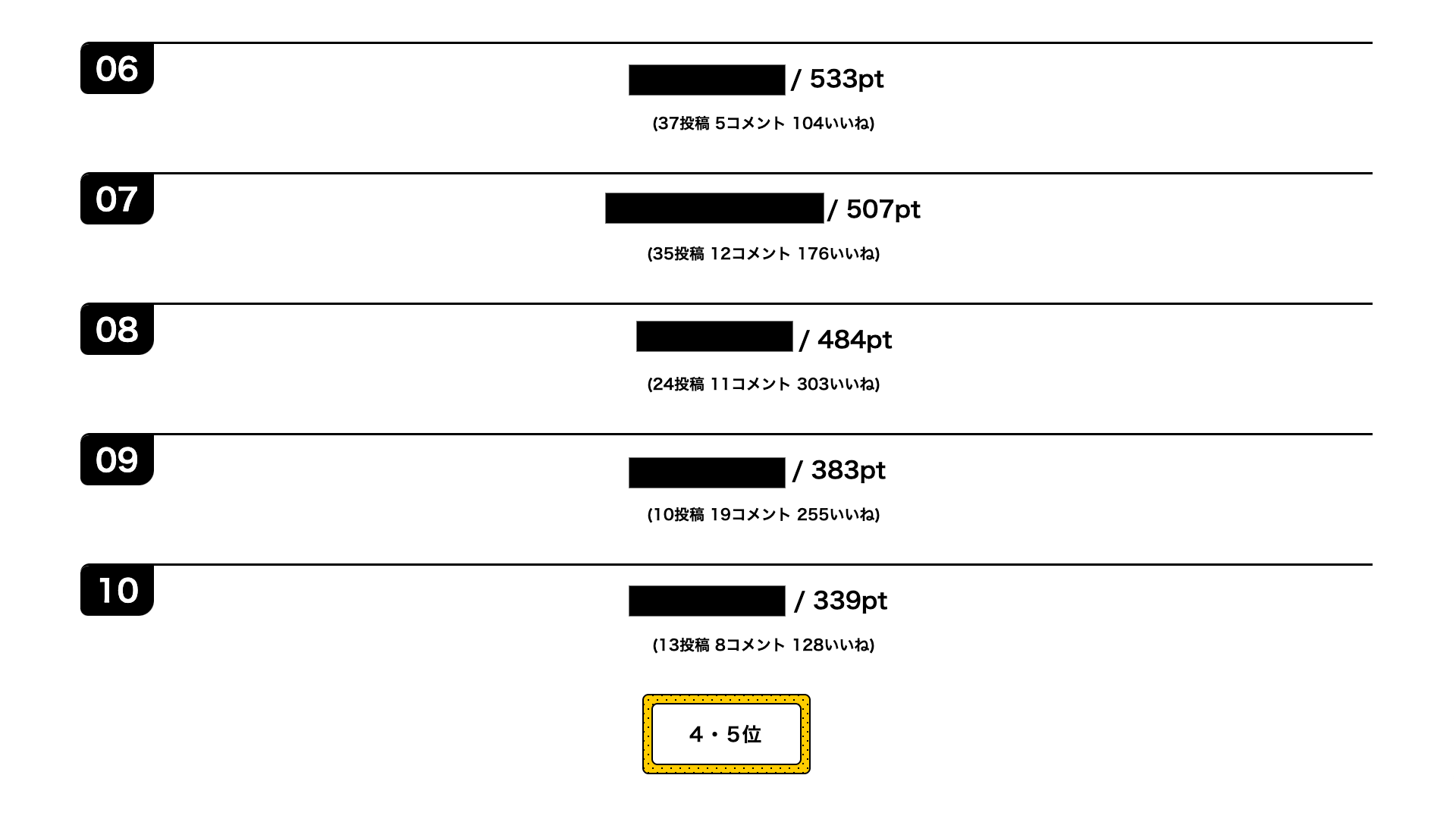
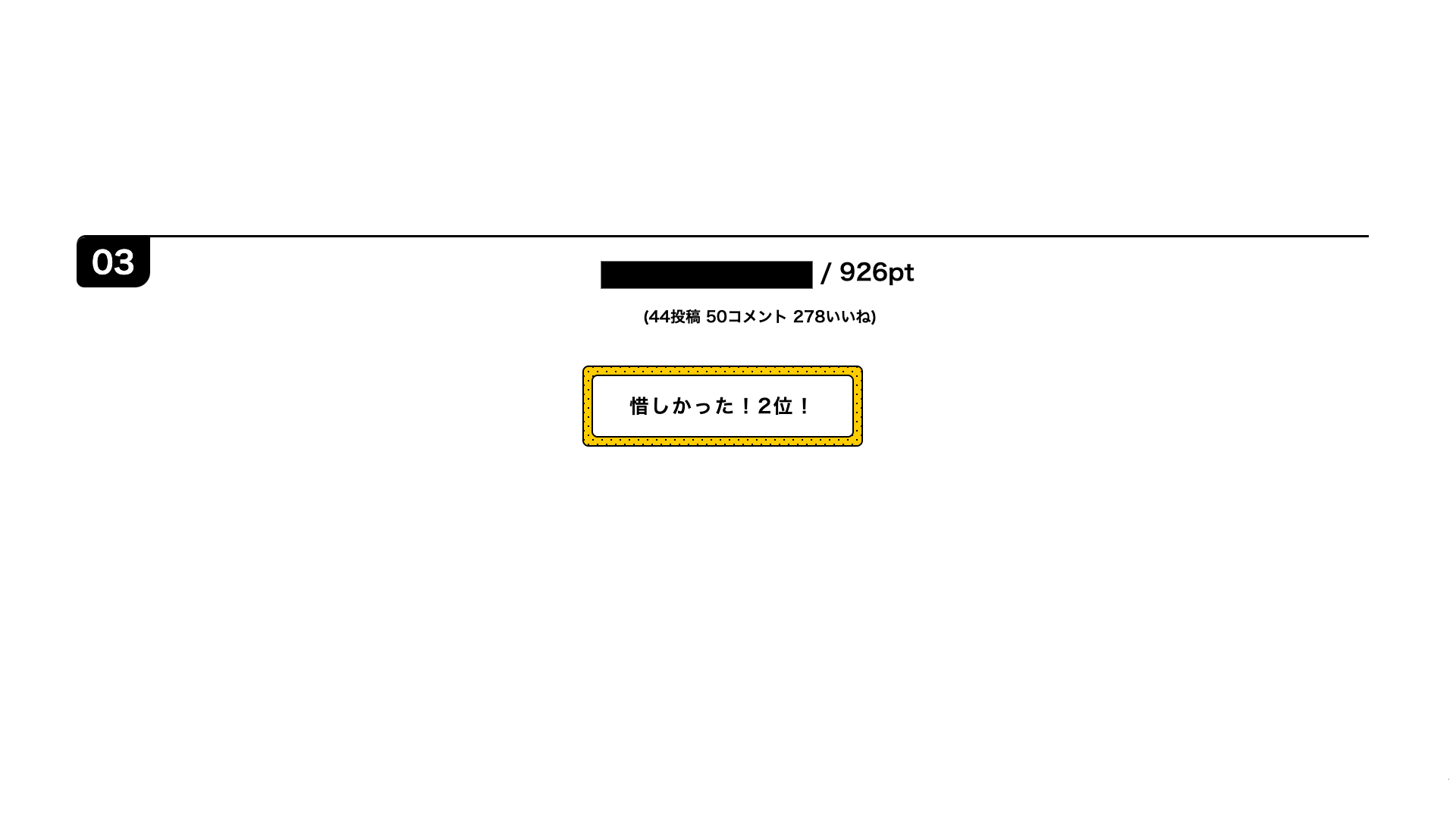
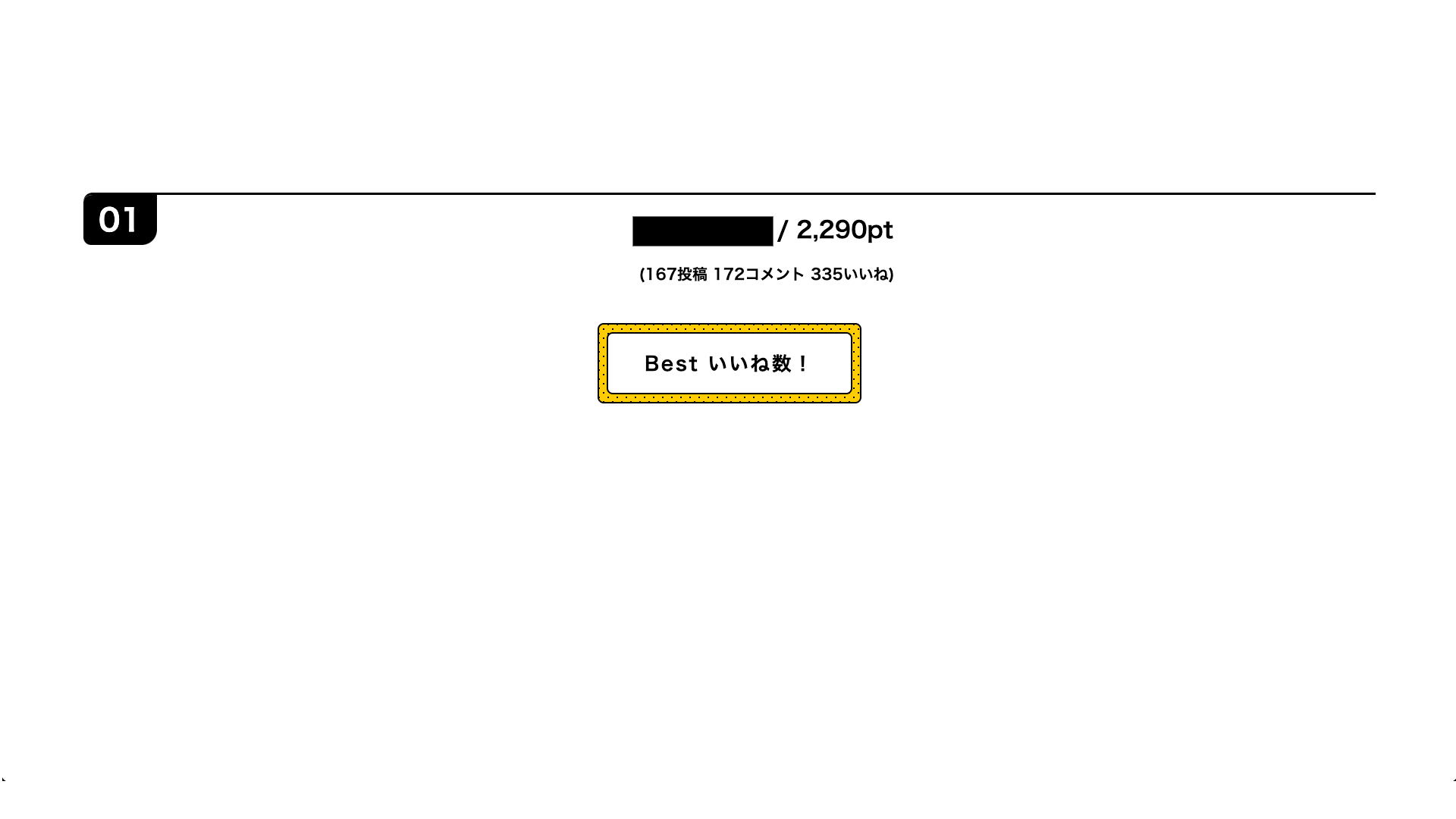
集計ポイント内訳
記事投稿 3pt
投稿記事についたいいね 1pt
他人の記事へのいいね 1pt
他人の記事へのコメント 2pt
自分のコメントについたいいね 1pt
他人のコメントへのいいね 1pt
社員にバレると来年以降の集計でおおよそ誰がどのくらいかバレてしまう気がしますが公開します。
それぞれの重み付はいろいろ考えましたが、記事投稿は大切にしたいという思いで3ptをつけています。
他人の記事へのコメントも盛り上げるという観点から弊社では大切にしたいなと考えて2ptにしています。
kibela APIの集計で気をつけたこと
- kibela APIにはcostという考えがあるので1クエリで10000を超えないようにしました。
(kibela APIのリファレンスページでは実際に叩いてcostがどんなもんか確認できます。) - 自分の叩き方が悪いのかもしれませんが記事の検索で期間指定ができませんでした。
(過去分全部引っ張ってきて、記事投稿年が2021のもののみを集計するようにしました。) - 処理が大変になるので不要なデータ取得しないようにしました。
(GraphQLの良い点で、レスポンスとして欲しいものだけを指定可能です。costも削減できます。)
なぜ作ったか
株式会社パーソンリンクにも情報共有ツールが存在します。
弊社では、kibela を利用しています。
自分がこの会社にJoinした時には情報共有ツールがありませんでした。
アドテクやビッグデータ処理が強みと謳っていたのに入社したら0ベースでのスタートでした。
ただ一人一人がやってる内容はかなりレベルの高いものだと思いましたので、情報共有をして組織として強くなりたいと考え、当初はknowledgeをEC2にインストールして使い始めました。
そしてkibelaに変更され今では弊社広報チームのメンバーの頑張りもあり、かなり社内では利用者が多いです。
情報共有の重要さを伝えていきたいと考えていた時に、ふとQiita表彰プログラムのことを思い出し、kibelaでもできないか考えた結果、kibelaの提供しているGraphQLがあることを知り実際にやってみました。
kibela側でも実装してくれたら結構簡単に毎月とかで表彰できるのなぁと思っていたりします。
さようなら〜!