QualiArts Advent Calendar 2022 11日目担当の8kkaです。
本記事では、最近ログフロー構築で使えないかなぁ...と模索している Apache Beam Go SDK について書こうと思います。
Apache Beam Go SDK
Apache Beam は、バッチやストリーミングでデータ処理を行うための統合プログラミングモデルです。
Apache Beam モデルでは、分散処理の細かい設定が抽象化されているため、ユーザーはジョブの実行ロジックに焦点を絞る事ができます。
実行環境もいくつかあり、 直接コンソールから実行する Direct Runner や Apache Spark、Google Cloud Dataflow など、様々な環境で実行できます。
Apahce Beam を利用する際の言語は Java と Python が有名ですが、近年 Go の SDK も充実してきています。
2年ほど前も Apache Beam Go SDK を利用したいと考えましたが、その時はまだ実験的なリリースしかされておらず、結局 Java の SDK を利用しました。
しかし、v2.32.0 を最後に実験的なリリースは終了したとの事でなので、今回は Apache Beam を使って Cloud Pub/Sub に送ったデータを Logging に出力する Cloud Dataflow のジョブを構築してみようと思います。
トピックとサブスクリプションを構築する
まずは Cloud Pub/Sub でデータを送信するためのトピックとサブスクリプションを構築します。今回利用するリソースの Terraform はこちらです。
resource "google_pubsub_topic" "beam" {
name = "beam"
}
resource "google_pubsub_subscription" "beam" {
name = "beam"
topic = google_pubsub_topic.beam.name
}
データの取得/出力処理を記述する
トピックとサブスクリプションが作成できたら、 Apache Beam Go SDK を使って処理を記述していきます。
先ほど作成したトピックとサブスクリプションの ID は定数で定義しておきましょう。
(コマンドラインフラグに設定する方が便利ですが、今回は特に可変にするつもりはないので定数にしておきます。)
const (
topicID = "beam"
subID = "beam"
)
次に、 main 関数を実装していきます。
Apache Beam Go SDK で書かれたコードを実行して Cloud Dataflow に反映させる場合、実行時に Runner や Region を指定する必要があります。
そのため、 flag.Parse() を呼び出しておきましょう。
flag.Parse()
GCPのプロジェクトIDやリソースを構築するリージョン情報は、 gcpopts.GetProject(ctx) を利用することで、実行時のフラグから取得できます。
ctx := context.Background()
project := gcpopts.GetProject(ctx)
ここから Apache Beam を使った処理を記述していきます。
Apache Beam は、データの入出力や変換処理を Pipeline というオブジェクトでカプセル化します。
Pipeline 上のデータは PCollection というデータセットオブジェクトで管理します。Pipeline の各ステップでは、この PCollection を入出力として利用します。
データ変換には ParDo という Apache Beam SDK のコア並列処理オペレーションを利用します。 ParDo では、入力された PCollection の各要素に対してユーザー指定の関数を呼び出してデータ変換を行い、0個以上の出力要素を PCollection として出力します。
まずは Pipeline を初期化しましょう。
beam.Init() は Apache Beam モデルを利用するための初期化です。
beam.NewPipelineWithRoot() は、初期化された Pipeline と ルートスコープを取得できます。
スコープは、各処理の命名やグルーピングに使用できるオブジェクトです。
beam.Init()
p, s := beam.NewPipelineWithRoot()
Pub/Subのサブスクリプションからデータを取得するには、pubsubio.Read() メソッドを利用します。
pubsubio.ReadOptions には、Subscription の他に Attribute の情報なども指定できます。
pubsubio.Read() の戻り値は PCollection であり、取得作業は Pipeline を実行したタイミングで処理されます。
col1 := pubsubio.Read(s, project, topicID, &pubsubio.ReadOptions{
Subscription: subID,
})
サブスクリプションから取得したデータはバイナリの状態なので、文字列に変換します。
文字列変換を Pipeline に組み込むには、beam.ParDo() メソッドに文字列変換の関数と、先ほど作成した PCollection (col1) を入力値として渡します。
こちらも戻り値は PCollection となります。
col2 := beam.ParDo(s, func(b []byte) string {
return (string)(b)
}, col)
debug.Print() メソッドに先ほど作成した PCollection (col2) を入力値として渡すことで、文字列がログとして出力されます。
debug.Print(s, col2)
構築した Pipeline を実行するには、 beamx.Run() メソッドを利用します。
Pipeline を実行することで、これまでに設定した col1 -> col2 -> debug.Print の処理が実行されます。
if err := beamx.Run(ctx, p); err != nil {
log.Exitf(ctx, "Failed to execute job: %v", err)
}
これで Apache Beam を利用した処理の記述が完了しました。
プログラムの全体像は以下のようになります。
package main
import (
"context"
"flag"
"strings"
"github.com/apache/beam/sdks/v2/go/pkg/beam"
"github.com/apache/beam/sdks/v2/go/pkg/beam/io/pubsubio"
"github.com/apache/beam/sdks/v2/go/pkg/beam/log"
"github.com/apache/beam/sdks/v2/go/pkg/beam/options/gcpopts"
"github.com/apache/beam/sdks/v2/go/pkg/beam/x/beamx"
"github.com/apache/beam/sdks/v2/go/pkg/beam/x/debug"
)
const (
topicID = "beam"
subID = "beam"
)
func main() {
flag.Parse()
ctx := context.Background()
project := gcpopts.GetProject(ctx)
beam.Init()
p, s := beam.NewPipelineWithRoot()
col1 := pubsubio.Read(s, project, topicID, &pubsubio.ReadOptions{
Subscription: subID,
})
col2 := beam.ParDo(s, func(b []byte) string {
return (string)(b)
}, col1)
debug.Print(s, col2)
if err := beamx.Run(ctx, p); err != nil {
log.Exitf(ctx, "Failed to execute job: %v", err)
}
}
ジョブを作成する
それでは、完成したコードを実行してみましょう。
今回は Google Cloud Dataflow で実行するため、runnerフラグに dataflow を指定します。
staging_locationフラグは、バイナリと一時ファイルをステージングするパスの指定フラグです。任意の Cloud Storage URL を指定しておきましょう。
go run main.go \
--runner dataflow \
--project {project_name} \
--region {region_name}
--staging_location gs://{storage_name}/{storage_pass}
実行に成功すると、Google Cloud Dataflow にジョブが作成されます。
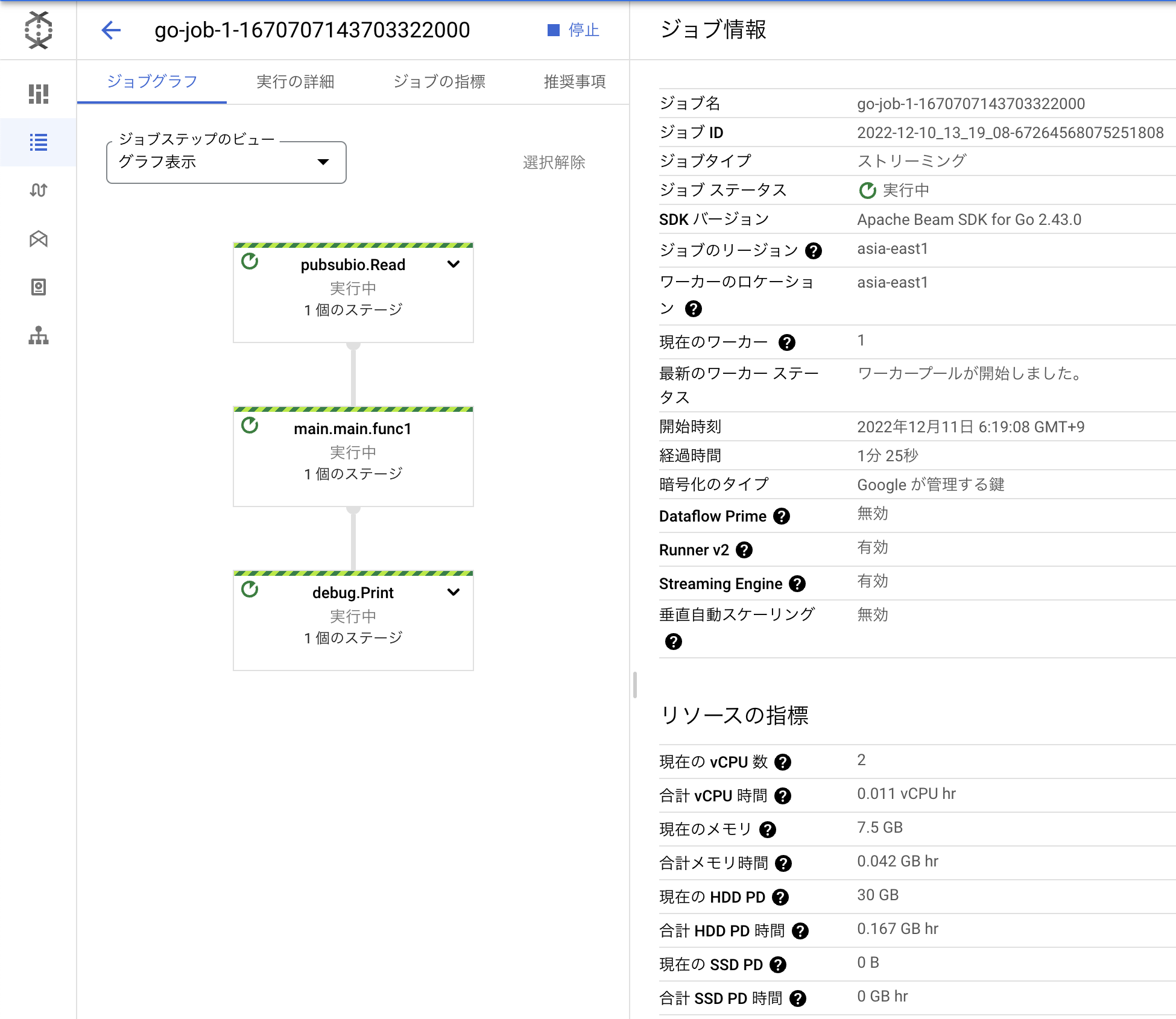
ジョブが作成されたら対象のトピックにメッセージを送信してみましょう。
正しくジョブが動いていれば、Google Cloud の Logging から送信されたメッセージを確認する事ができます。

まとめ
本記事では Apache Beam Go SDK を利用して、Pub/Sub のデータをログ出力するコードを実装しました。
Go SDK は Java や Python と比較するとまだ利用できる機能は少ないですが、普段から Go を利用しているエンジニアは採用を検討してみても良いかと思います。
個人的には Pub/Sub から BigQuery へ送る際の要件を Go SDK で実現できるか検証しているので、また機会があればそちらについても記事を書こうかなと思ってます。