やりたいこと
定期的にあるサイトをスクレイピングし、その結果をGoogleDriveに保存させ続けたいです。
pythonスクリプトの定期実行はschedule等のモジュールでも可能ですが、PCを立ち上げておかないと定期実行できないため、自分的には都合がよくありません。
なので、PCを開かなくてもスクレイピング+データ保存を自動で実行してくれる環境を構築しようと思います。
出来たもの
以下のように、Google Cloud Platformの各種サービスを使ってスクレイピングの定期実行から結果の保存までを自動でやってくれるシステムを構築しました。
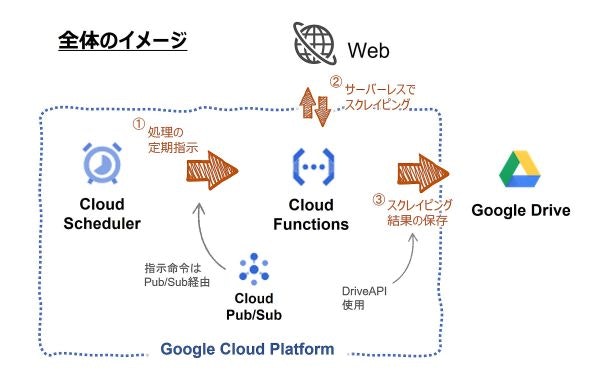
サーバーレスでのスクリプト関数にGoogle Cloud Functions、定期的なスクリプト実行にGoogle Cloud Scheduler、スクレイピング結果の保存にGoogle Drive(Drive API)を使用しています。
解説 (目次)
実際に作成する手順を踏まえ、以下の流れで説明していきます。
1. スクレイピング用コードの作成
2. Google Driveでスクレイピング結果を保存するフォルダを作成
3. Google Cloud Platformを始める
4. Cloud Functionsで関数を作成
4-1. 関数の基本設定
4-2. トリガーの指定
4-3. Cloud Functions用にコードを再編集
4-4. 関数のデプロイ
4-5. Google Driveへのアクセス設定
4-6. 関数の動作確認
5. Cloud Schedulerによる関数定期実行の設定
1. スクレイピング用コードの作成
とりあえず、対象サイトをスクレイピングし、DataFrameに変換するコードを作ります。
今回は天気予報サイト(日本気象協会 tenki.jp)を対象としたスクレイピングを行なうようにします。
コード自体は後ほど移植するので、動作確認さえできれば特に何で書いても大丈夫です。
自分はGoogle Colaboratory上で書きました。
# ライブラリのインポート
import requests, bs4
import pandas as pd
import datetime
# スクレイピング対象のURL
url = r"https://tenki.jp/week/"
# URLからHTML取得
res = requests.get(url)
soup = bs4.BeautifulSoup(res.text, "html.parser")
# データベース用変数定義
database_telop, database_precip = [], []
# 2週間予報の全テーブルを格納
week_tb_lst = soup.find_all("table", class_="week-thisweek-table")
# テーブルごとに処理
for week_tb in week_tb_lst:
# ヘッダー行を除いた全行を取得
data_tb = week_tb.find_all("tr")[1:]
# 一行ごとに処理
for tr in data_tb:
tmp_dic_telop, tmp_dic_precip = {}, {}
# 地点のスクレイピング
tmp_dic_telop["地点"] = tmp_dic_precip["地点"] = tr.find("span", class_="point-name").text
# 1セルごとに処理
for i, fw in enumerate(tr.find_all("td", class_="forecast-wrap")):
# 予測対象の日付
forecasted_day = datetime.date.today() + datetime.timedelta(days=i)
# 天気・降水確率の取得
tmp_dic_telop[str(forecasted_day)] = fw.find("span", class_="forecast-telop").text
tmp_dic_precip[str(forecasted_day)] = fw.find("p", class_="precip").text
# データベースに追加
database_telop.append(tmp_dic_telop)
database_precip.append(tmp_dic_precip)
# DataFrameに変換し辞書型で格納
dfs = {}
dfs["telop"] = pd.DataFrame(database_telop)
dfs["precip"] = pd.DataFrame(database_precip)
こんな感じのコードを作りました。スクレイピングに関する説明は割愛。
作成したら動作確認も行なっておきます。
2. Google Driveでスクレイピング結果を保存するフォルダを作成
GoogleDriveでスクレイピングした結果を保存するフォルダを作成しておきます。
新規でなく、既存のフォルダでもOK。
アクセス権などの設定が必要となりますが、後ほど説明します。
3. Google Cloud Platformを始める
Google Cloud Platformに移動すると、初回のみ利用規約の確認が入ります。
内容を確認し、問題なければ「同意して続行」をクリックします。
3-1. プロジェクトの作成
まず最初にプロジェクトというものを作成します。プロジェクトとは、Google Cloud Function やGGoogle Cloud Schedulerといった各種サービスで作成するリソースを管理する単位です。
なんのこっちゃ、と思われるかもしれませんが、大丈夫。私もよく分かっていません。
とにかく一つのフォルダのようなものをつくり、その中でジョブをつくったり、コードを作るんだと理解してもらえればOKかと思います。
Google Cloud Platformでは基本的に左上のナビゲーションメニューから各種サービスをスタートできます。
ナビゲーションメニュー → IAMと管理 → プロジェクトの作成 でプロジェクトの作成が開始されます。
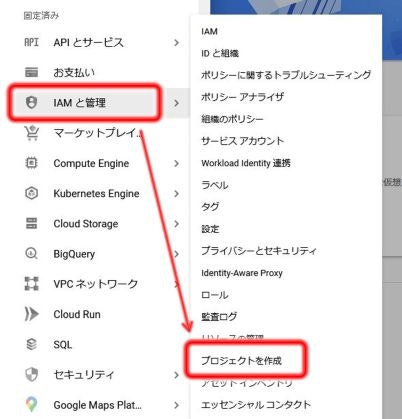
プロジェクト作成画面
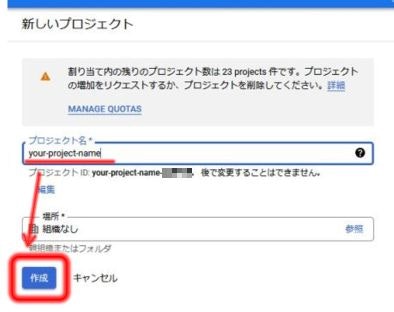
プロジェクト名は分かりやすいものをつけておけばOK。
他のユーザーとプロジェクト名が競合している場合、プロジェクトIDにはプロジェクト名にランダムな番号が付加されます。
場所はそのまま「組織なし」で。
「作成」をクリックするとプロジェクトが作成されます。
一応、Cloud Platformの画面上部で先ほど作成したプロジェクトが選択されていることを確認します。
(すでにプロジェクトが作成されていた場合は切り替える必要があります)
3-2. 課金設定(無料枠での使用でもクレジット登録が必要)
プロジェクトができたら、次にGCP内の各種サービスを使うための課金設定をします。
基本永久無料枠の範囲内で使用する予定ですが、課金設定自体は、ロボットではない等GCPを利用する人の身元をあらたかにするために必須となっているようです。
無料枠についても今後サービス内容が変わる可能性もあるため、料金は自分でしっかり確認し自己責任で使用しましょう。
(課金設定時に付与される$300分のクレジットの使用期限が登録から90日と定められているため、このクレジットを無駄にしたくない人は事前にサービス活用の計画を練ったほうが吉です)
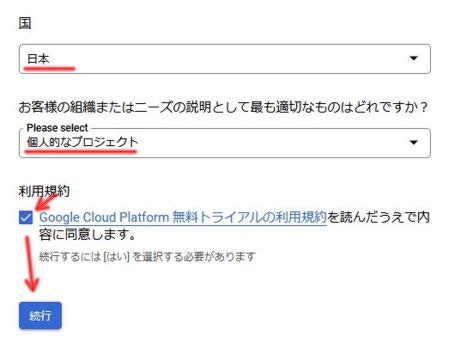
まだ課金設定が完了していなければ画面上の「無料トライアルに登録」から課金設定を開始できます。
クリックしたら最初の画面で国と目的(ニーズの説明)が求められます。私はニーズに「個人的なプロジェクト」を選択しました。
その後、利用規約を確認した上で内容の同意にチェックを入れ、「続行」を押します。
次に連絡先情報を入力します。
左側で「日本」を選ぶと、電話番号の欄に日本の国際番号の「+81」が入ります。
その後ろに自分の携帯番号を入れるのですが、このとき頭の0を除いた番号を入れる必要があります。
なので、例えば携帯番号が「080-1234-5678」だったら「+81 80-1234-5678」となるように入力します。

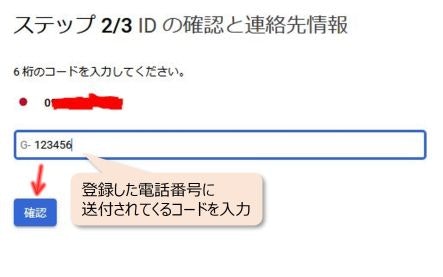
「続行」を押すと登録した電話番号にショートメッセージが届くので、そこに記載されている6桁のコードを入力します。
そして次の支払い方法でカード等の支払情報を追加します。
試していませんが通常のクレジットカードの他、paypalも使えるようです。
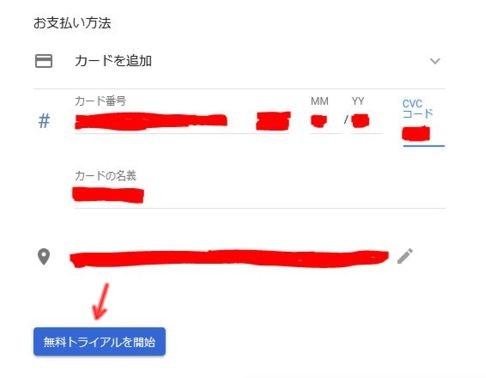
以上で課金設定は完了です。
4. Cloud Functionsで関数を作成
次にCloud Functionsの利用に移ります。
ナビゲーションメニュー → 「Cloud Functions」でFunctionsを起動します。
(見つからなければ、「その他のプロダクション」をクリックしてすべてのサービスを表示させる必要があります)
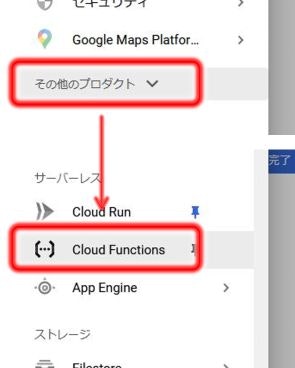
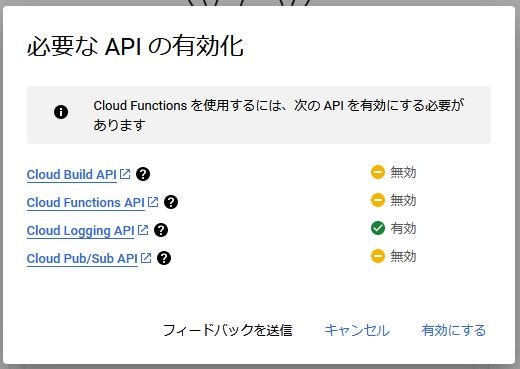
初回のみ、「Cloud Build API」、「Cloud Functions API」、「Cloud Logging API」、「Cloud Pub/Sub API」4つのAPIの有効化を求められるので、「有効にする」をクリックします。
4-1. 関数の基本設定
いよいよ、定期的に実行させる関数を作成していきます。
APIを有効にすると、自動的に関数の作成画面へ遷移しますが、初回以外は
「関数の作成」をクリックすると、関数作成画面に遷移できます。
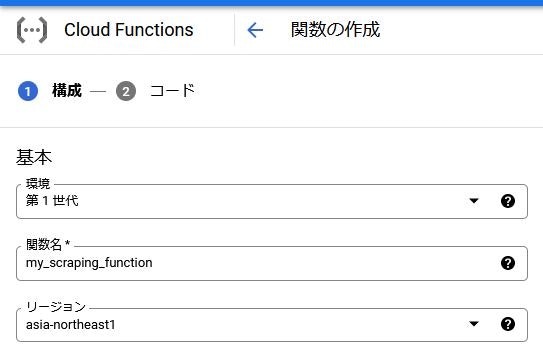
関数の作成では、まず関数の基本設定から行ないます。
環境はデフォルト設定の「第一世代」で問題ありません。(将来的には第二世代がデフォルトになってくるかもしれません)
関数名は任意の名前をつけられるので、分かりやすい名前でOK。
リージョンは特段理由がなければ、Tokyo(asia-northeast1)にしておけば大丈夫でしょう。
4-2. トリガーの指定
次に、この関数を実行するきっかけ=トリガーの設定をします。
今回はPub/Subという仕組みを使って関数を実行させます。
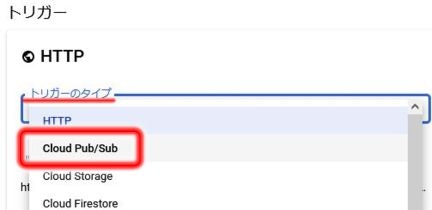
Pub/Subの他にHTTPなどがあり、例えば特定のURLにアクセスすると関数が実行される、みたいなトリガーも指定できます。
トリガーでCloud Pub/Subを選択すると、Pub/Subのトピックの指定が求められます。
今回、新規にトピックを作成するので、「トピックを作成」をクリックします。トピックIDに任意の名前を入力してトピックを作成します。
すると自動で作成したトピックが選択されるので、他の項目が問題なければ「保存」をクリックします。
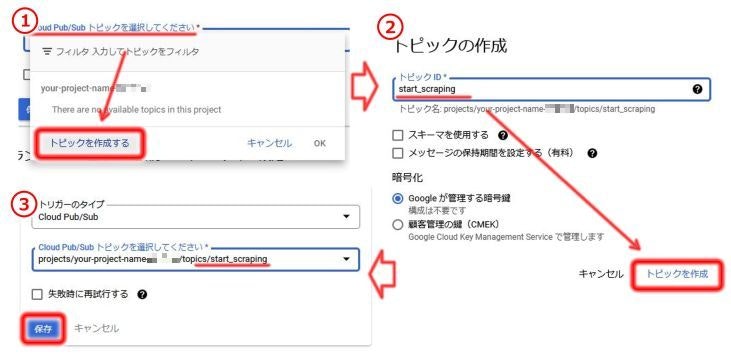
下に表示されている「Runtime,build,connections and security settings」からメモリの割り当てやタイムアウト時間等の設定ができますが、今回はデフォルト設定のままいきます。
4-3. Cloud Functions用にコードを再編集
4-3-1. ランタイムとソースコードの選択
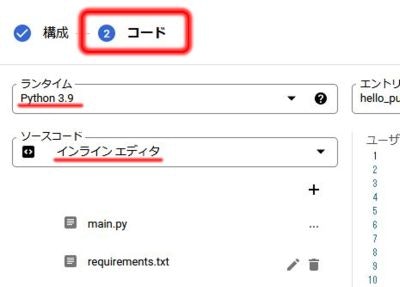
そしたら次に「②コード」を選択してコードの編集を行なっていきます。
コードの編集では、まずランタイム=記述する言語を指定します。
今回は「Python3.9」を使用しますが、他にもJavaScriptやPHP、Go、Rubyなど使用できるようです。
ソースコードは直接ブラウザ上で記述するため「インライン エディタ」を指定します。
4-3-2. インライン エディタでのコード編集
ランタイムをPythonに指定すると、自動で「main.py」と「requirements.txt」が作成されます。
requirements.txtへ使用する外部ライブラリを指定する
まずrequirements.txtから編集していきます。
requirements.txtには使用する外部ライブラリを記述します。
requirements.txtをクリックすると右側のエディタでソースを直接編集できます。
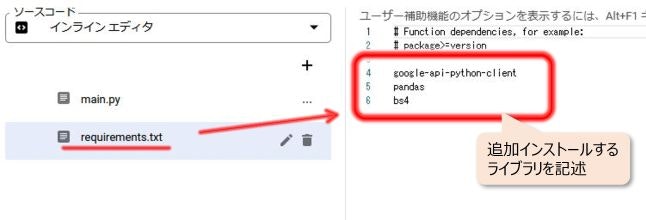
こんな感じで使用する外部ライブラリ名を記述するだけです。(バージョンの指定も可能とのこと)
google-api-python-client
pandas
bs4
main.pyにコードを記述する
main.pyに実際に定期実行させる関数をコードで記述していきます。
先ほど同様main.pyをクリックすると右側のエディタでコードを記述できます。
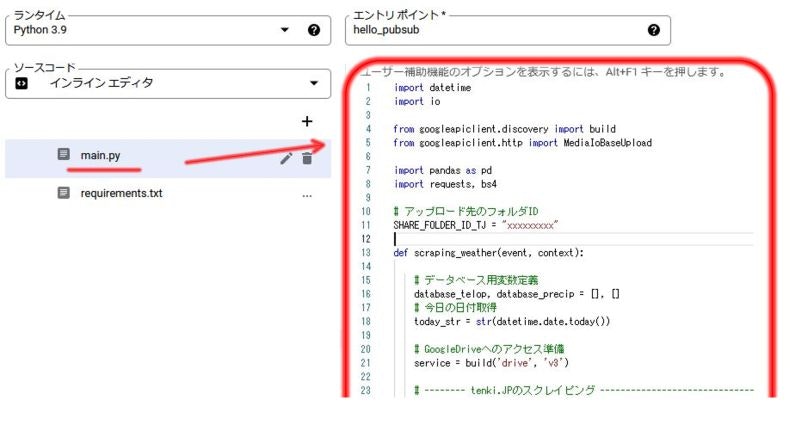
このインラインエディタはあまり使用感が良くないので、別の場所で書いたコードを移植し、必要な箇所だけ編集することをオススメします。
4-3-3. コード
実際に移植・編集したコードがこちら。
(ハイライト部分が冒頭のコードから追加した内容です。
Diffのハイライト表示するため行頭に+ を追加していますが、コピペする際は削除してください)
import datetime
+ import io
+ from googleapiclient.discovery import build
+ from googleapiclient.http import MediaIoBaseUpload
import pandas as pd
import requests, bs4
+ # アップロード先のフォルダID
+ SHARE_FOLDER_ID = "xxxxxxxxx"
+ def scraping_weather(event, context):
# データベース用変数定義
database_telop, database_precip = [], []
# 今日の日付取得
+ today_str = str(datetime.date.today())
+ # GoogleDriveへのアクセス準備
+ service = build("drive", "v3")
# -------- tenki.JPのスクレイピング ------------------------------
# スクレイピング対象のURL
url = r"https://tenki.jp/week/"
# URLからHTML取得
res = requests.get(url)
soup = bs4.BeautifulSoup(res.text, "html.parser")
# 2週間予報の全テーブルを格納
week_tb_lst = soup.find_all("table", class_="week-thisweek-table")
# テーブルごとに処理
for week_tb in week_tb_lst:
# ヘッダー行を除いた全行を取得
data_tb = week_tb.find_all("tr")[1:]
# 一行ごとに処理
for tr in data_tb:
tmp_dic_telop, tmp_dic_precip = {}, {}
# 地点のスクレイピング
tmp_dic_telop["地点"] = tmp_dic_precip["地点"] = tr.find("span", class_="point-name").text
# 1セルごとに処理
for i, fw in enumerate(tr.find_all("td", class_="forecast-wrap")):
# 予測対象の日付
forecasted_day = datetime.date.today() + datetime.timedelta(days=i)
# 天気・降水確率の取得
tmp_dic_telop[str(forecasted_day)] = fw.find("span", class_="forecast-telop").text
tmp_dic_precip[str(forecasted_day)] = fw.find("p", class_="precip").text
# データベースに追加
database_telop.append(tmp_dic_telop)
database_precip.append(tmp_dic_precip)
# データフレーム化・格納
dfs = {}
dfs["telop"] = pd.DataFrame(database_telop)
dfs["precip"] = pd.DataFrame(database_precip)
# 各データフレーム処理
+ for key in dfs.keys():
+ # データフレームをメモリ上に格納
+ buffer = io.BytesIO() # ここはBytesIOじゃないとエラーになる(StringIOは使えない)
+ dfs[key].to_csv(buffer)
+ # メタデータ作成(Driveへのアップロードに必要)
+ file_metadata = {
+ "name": today_str + "_" + key + ".csv",
+ "parents": [SHARE_FOLDER_ID]
+ }
+ # データ本体作成(Driveへのアップロードに必要)
+ media = MediaIoBaseUpload(buffer,
+ mimetype="text/csv",
+ resumable=True)
+ # Driveへのアップロード(データ生成)
+ file = service.files().create(body=file_metadata,
+ media_body=media,
+ fields="id").execute()
以下に、追記部分の解説をします。
4-3-4. コード解説(冒頭のコードからの追加部分のみ)
インポートするライブラリの追加
Google Driveへのアップロードに必要なライブラリをいくつか追加します。
# ライブラリのインポート
import datetime
import io
from googleapiclient.discovery import build
from googleapiclient.http import MediaIoBaseUpload
import pandas as pd
import requests, bs4
GoogleDriveにアクセスするためのgoogleapiclient.discovery.buildと、バイナリデータをGoogleDriveに書き込むためのgoogleapiclient.http.MediaIoBaseUploadをインポートします。
また、スクレイピングしたデータを一度バイナリで扱う必要があるので、標準ライブラリのioもインポートしています。
GoogleDriveにアクセスする準備
GoogleDriveにアクセスするためのインスタンスを生成します。
# GoogleDriveへのアクセス準備
service = build("drive", "v3")
googleapiclient.discoveryからインポートしたbuildメソッドを使用し、第一引数に"drive"、第二引数にGoogleDriveAPIのバージョンを示す"v3"を指定すればOK。
使い方によっては、ここで認証キーなどの設定を指定する必要がありますが、今回は別方法で認証するので指定不要です。
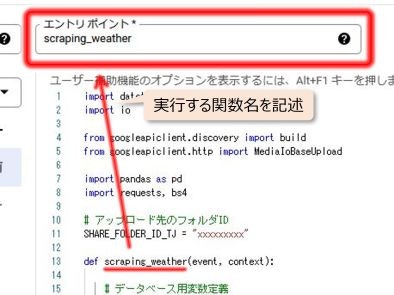
エントリポイントとして関数を作成し、処理を記述
defで任意の名前の関数を作成し、その中に処理を記述していきます。
def scraping_weather(event, context):
エントリポイントは、そのプログラムの中で処理が開始されるポイントとのこと。
引数にはeventとcontextを指定しておきます。
(ここの詳細はまだ理解不足で説明できません。。eventは何となくわかるんですが、contextはまだ?です)
関数を書いたら、エディタの上部でエントリポイントを指定できるので、作成した関数名を入力しておきます。
GoogleDriveへのアップロード
スクレイピング結果をGoogleDriveへアップロードしていきます。
通常pythonで行なうようなファイル保存とは異なり、いくつか手順を踏む必要があります。
尚、ここからは保存が必要なデータごとに処理を行なっていきます(今回の場合、天気(telop)と降水確率(precip))。
スクレイピング結果をバイナリ形式で保存
クラウド上でスクレイピング結果(pandas形式)をいきなりファイルとしては保存できないため、まずメモリ上にスクレイピング結果を格納します。
# データフレームをメモリ上に格納
buffer = io.BytesIO() # ここはBytesIOじゃないとエラーになる(StringIOは使えない)
dfs[key].to_csv(buffer)
csvをバイナリとして扱ったことがある人は、BytesIOではなくStringIOを使用したくなるかもしてませんが、この後Driveにアップロードするところでエラーになってしまうので、ここではBytesIOを使用します。
これで疑似的にbufferをファイルとして扱えるようになりました。
メタデータの作成
GoogleDriveにおけるファイルの取り扱いは、データの中身そのものとはまた別に、メタデータと呼ばれるファイル名や属性などを示すデータのためのデータを定義する必要があります。
とりあえずここでは必要な情報を辞書形式で作成しておきます。
# メタデータ作成(Driveへのアップロードに必要)
file_metadata = {
"name": today_str + "_" + key + ".csv",
"parents": [SHARE_FOLDER_ID]
}
nameにはファイル名を拡張子付きで指定。今回の場合、ファイル名に日付と保存したいデータの種類を示すキーワードを入れるようにしました。
parentsには、データ格納先のフォルダIDをリスト形式で指定します。フォルダIDは次の方法で確認します
データ保存先のフォルダID取得
フォルダIDはGoogleDriveの各フォルダに紐づけられた規則性のない文字列です。
保存先のフォルダ(先ほどGoogleDriveで作成したフォルダ)にアクセスし、URLの末尾を参照すればOK。
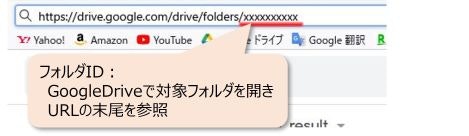
上記の場合はxxxxxxxxxxxがフォルダIDになります。
今回のコードでは、最初の方でフォルダIDを変数に格納し、
# アップロード先のフォルダID
SHARE_FOLDER_ID = "xxxxxxxxxxx"
メタデータとなる辞書の"parents"に上記変数を渡しています。
:
"parents": [SHARE_FOLDER_ID]
}
保存するデータの中身の定義
続いて、データの本体となるmediaデータを定義していきます。
今回、バイナリからデータを作成するので、googleapiclient.httpからインポートしたMediaIoBaseUploadを使用してデータを生成します。
# データ本体作成(Driveへのアップロードに必要)
media = MediaIoBaseUpload(buffer,
mimetype="text/csv",
resumable=True)
第一引数に対象データをバイナリ形式で格納したメモリ(buffer)を指定。
mimetypeはこのデータがどんなファイルなのかを示すための情報です。ここは保存するファイルの種類によって変更する必要がありますが、今回は"text/csv"を指定します。
resumableは再開可能を意味します。おそらくですが、中断しても途中からアップロードが再開可能かを指定すると予想しています。GoogleDriveAPIのリファレンスでTrueされているケースが多かったため、Trueにしています。
データ保存の実行
後は作成したメタデータとデータ本体を使用して保存するだけです。
先ほどgoogleapiclient.discoveryのbuildメソッドで作成したGoogleサービスへアクセスするためのインスタンス(ここではインスタンス名servis)から、files().createメソッドでファイルを指定し、それをexecute()で実行します。
# Driveへのアップロード(データ生成)
file = service.files().create(body=file_metadata,
media_body=media,
fields="id").execute()
4-4. 関数のデプロイ
ここまでで一通りのコード作成は完了です。
あとは下部の「デプロイ」をクリックしてデプロイするだけなのですが、
コードにミスがあってデプロイ失敗してしまった場合、せっかく記述してきたコードがまっさらになってしまいます。
(デプロイ前のコードは保存されません)
なので、デプロイ実行する前にコード全文をメモ帳などに貼り付けて避難させておくことをオススメします。
心の準備ができたら「デプロイ」をクリックしましょう。

デプロイには結構時間がかかります。コード内容にもよりますが5分近くかかるケースもありました。
完了すると、作成した関数のステータス欄に緑のチェックマークがつきます。
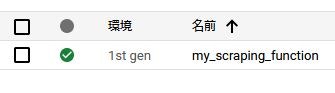
赤や黄色のマークがついてしまった場合、コードにミスなどがあり、デプロイ失敗しています。
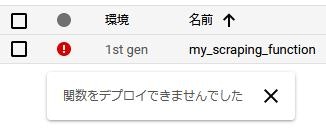
エラー(デプロイ失敗)が発生してしまったら
デプロイ時に発生したエラーは、関数の詳細から確認できます。
Cloud Functions → 関数名をクリック → 詳細をクリック
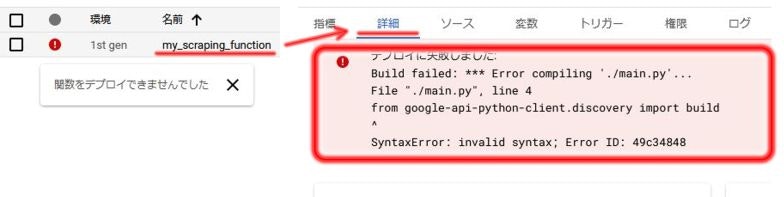
コードの修正は、関数名をクリックすることで表示される各関数の詳細画面の上部、「編集」をクリックし、②コードをクリックすれば再び記述することができます。
また、エラーの種類によってはErorr Reporting(ナビゲーションメニュー → Error Reporting)や関数の指標画面(Cloud Functions → 関数名をクリック → 指標(最初の画面)の下部)
に表示されている場合もありますので、こちらも確認しましょう。
4-5. Google Driveへのアクセス設定
Google Drive API の有効化
まず最初に、先ほどのプロジェクト内でGoogle Drive APIを有効にしていきます。
ナビゲーションメニュー → APIとサービス → ライブラリ
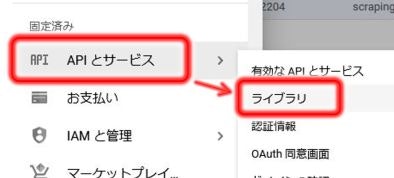
→ Google Drive API を選択後、「有効にする」 をクリックすればAPIが有効になります。
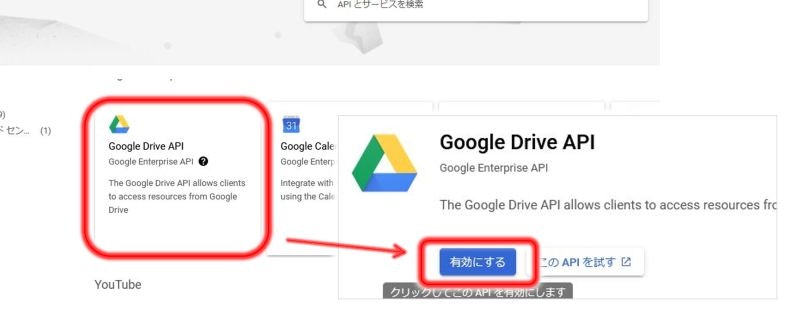
Drive上のフォルダへのアクセス権追加
GoogleDrive上のフォルダに対し、Cloud Functionsからアクセスできるように設定していきます。
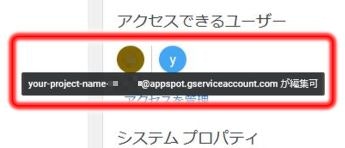
まず、GoogleCloudPlatformの自分のサービスアカウントのメールアドレスを確認します。
ナビゲーションメニュー → IAMと管理 → サービスアカウント
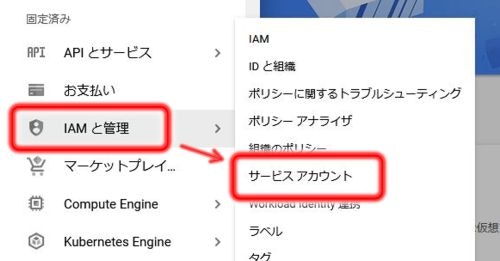
でアカウント一覧が表示されます。おそらくここまでの手順であれば作成されているアカウントは一つのはずです。
そのアカウントのメールアドレス(プロジェクトID@appspot.gserviceaccount.comになっているはず)を
コピーします。
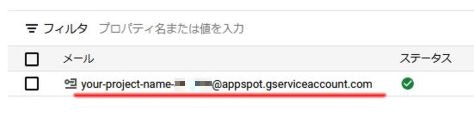
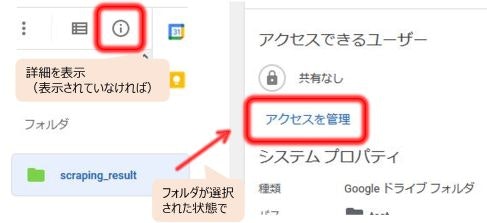
自分のアカウントサービスのメールアドレスが取得出来たら、GoogleDriveに移動します。
保存先のフォルダを選択し、右側の詳細情報から「アクセスを管理」をクリックします。
するとメールアドレスが追加できるので、先ほどコピーしたGoogleCloudPlatformサービスアカウントのメールアドレスを貼り付け、「共有」をクリックします。
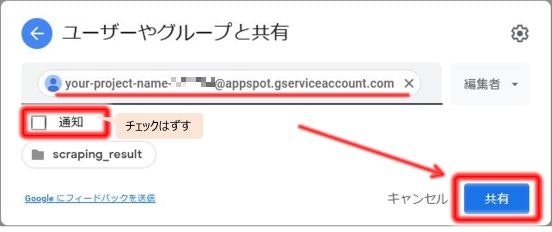
その後、アカウントが追加されているのを確認できればOKです。
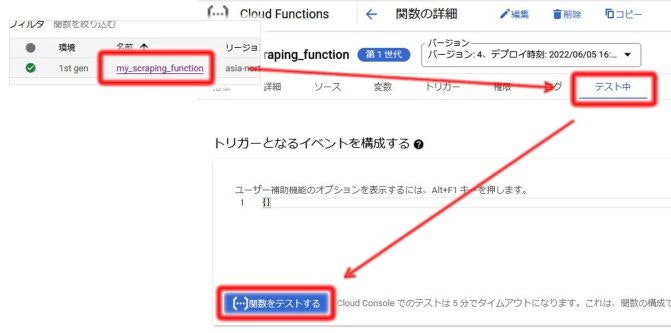
4-6. 関数の動作確認
ここまでで作成した関数の動作確認をします。
CloudFunctionsの画面から、作成した関数をクリックし、関数の詳細画面へ移動します。
そして、メニューの右端の「テスト中」をクリックします。すると、テスト画面へ移動するので、
下部の「[…]をテストする」で関数をテスト動作させることができます。
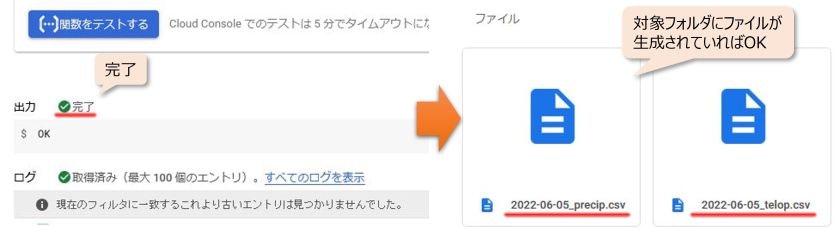
実行した後、GoogleDriveの指定フォルダにcsvが作成されていれば、ここまでの動作確認はOKです。
5. Cloud Schedulerによる関数定期実行の設定
ここまで来たらあと少しです。
上記で作成した関数を定期的実行させるジョブを作成していきます。
まずナビゲーションメニューからGoogleCloudSchedulerを起動します。
上部に「ジョブの作成」があるので、クリックしてジョブの作成を開始します。
ジョブというのは、どのような関数を実行させる時間ルールのことで、無料枠で3つまで設定することができます。
5-1. スケジュールの定義
名前は任意の名前をつけてOKです。リージョンも任意でOKだと思いますが、私は関数と同じ東京(asia-northeast1)を選択しました。
説明を入力することができます(任意です)。
頻度が最も重要で、いつ実行させるかをunix-cronという表記ルールで記入します。詳細はunix-cronで検索。
今回の場合、毎日決まった時間(6時)にスクレイピング実行させたいので、 「0 6 * * *」と入力しました。
このほか「3時間おきに実行(0 */3 * * *)」や「毎週月曜日の9時に実行(0 9 * * mon)」等のルールを設定することも可能です。
タイムゾーンはどのタイムゾーンを使用するかを指定できます。
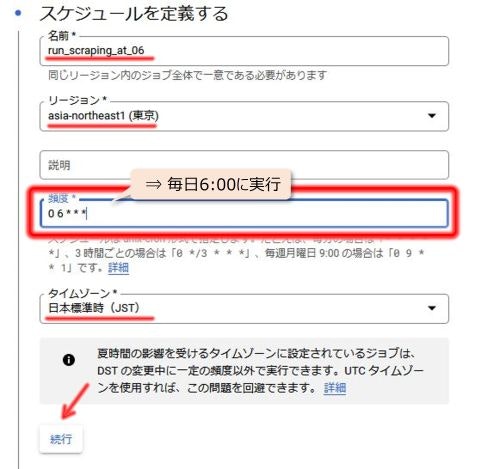
上記を入力したら「続行」をクリックします。
5-2. 実行内容の構成
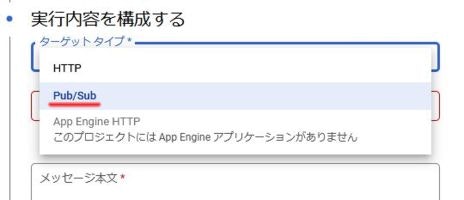
ターゲットタイプはHTTPかPub/Subかを選べます。
最初の方で関数のトリガーにPub/Subを採用しているので、そちらを選択します。
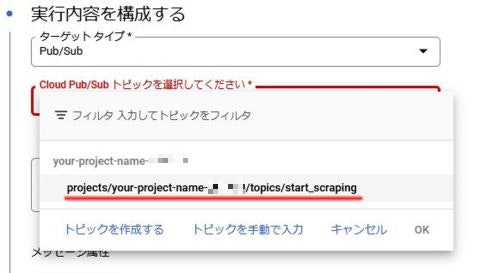
Cloud Pub/Sub トピックを選択してください でCloud Functionsの関数作成時につくったトピックを選択します。
メッセージは今回の内容には何も影響してこないので、テキトーに入力しておきます。
ここまで入力出来たら再び「続行」。
5-3. オプション設定
万が一のことを考えて、最大再試行回数をある程度増やしておく以外はあまり必要性を感じません。
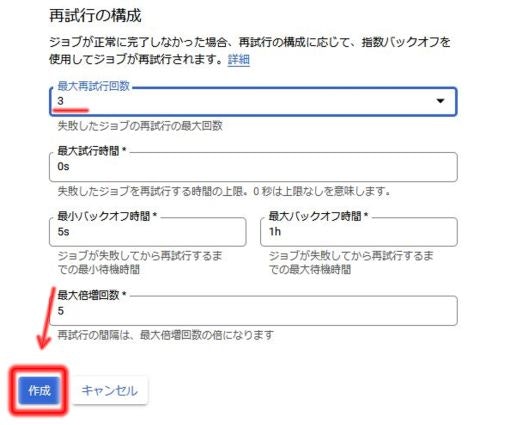
5-4. ジョブ作成完了と確認
上記ジョブの各項目が入力出来たら、「作成」をクリック。これでジョブの作成ができました。
ジョブの動作確認は指定した時間にならないとできません。
編集も何度もできるので、気になるようだったら、とりあえずすぐ動作するようにスケジュールを設定して動作確認を行なったのち、所望の時間に指定し直せばOK。
完成!
所感とか
-
とりあえず、今年の5月ぐらいから毎日定期実行させています。
おおよそは問題ないのですが、サイトによってはスクレイピング失敗してブランクのデータが生成されてしまっている時があります。。 -
課金額ですが、今回のケースより複数サイトをスクレイピングするようにし、かつ、
割り当てメモリなどを増加させた関数を毎日1回実行していたところ、12円の請求がきました。
どうやら無料枠をわずかにオーバーしてしまった模様。
今回のケースなら無料枠を超えることはないと思いますが、カスタムする際はご注意ください。 -
最近、第一子が誕生しました。可愛すぎる。