前回まで
ペンギンデータセットを使って、最小二乗法とRidge回帰の2種類の方法で線形回帰を実行するコードを書きました。
今回は確率的勾配降下法による線形回帰を実践していきます。
確率的勾配降下法
確率的勾配降下法(Stochastic Gradient Descent; SGD)は線形回帰①で学んだ通り、パラメータを一度に求めるのではなく勾配を計算し繰り返しパラメータを更新していく方法でした。scikit-learnでは確率的勾配降下法で線形回帰を行うためのモジュールとしてsklearn.linear_model.SGDRegressorがあります。前回同様ペンギンデータセットを用いて実際のコードを書いていきます。
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import SGDRegressor
from sklearn.preprocessing import StandardScaler
# データセットのロード
penguins = sns.load_dataset('penguins')
# NaN値を除去
penguins = penguins.dropna(subset=['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g'])
# Gentooペンギンのデータのみを抽出
gentoo = penguins[penguins.species == 'Gentoo']
# くちばしの長さと体重データを取得
X = gentoo[['bill_length_mm']].values
y = gentoo['body_mass_g'].values
# データのスケーリング
scaler_X = StandardScaler()
scaler_y = StandardScaler()
X_scaled = scaler_X.fit_transform(X)
y_scaled = scaler_y.fit_transform(y.reshape(-1, 1)).ravel()
# SGDRegressorモデルの作成と訓練
sgd_model = SGDRegressor()
sgd_model.fit(X_scaled, y_scaled)
# モデルの予測値を算出
y_scaled_pred = sgd_model.predict(X_scaled)
# 元のデータと予測のプロット
plt.figure(figsize=(10, 6))
plt.scatter(scaler_X.inverse_transform(X_scaled), scaler_y.inverse_transform(y_scaled.reshape(1, -1)), color='blue')
plt.plot(scaler_X.inverse_transform(X_scaled), scaler_y.inverse_transform(y_scaled_pred.reshape(-1, 1)), color='green')
plt.xlabel('Bill Length (mm)')
plt.ylabel('Body Mass (g)')
plt.title('SGD Regressor Prediction')
# 図を保存
plt.savefig('scatter_sgd.png')
# グラフを表示
plt.show()
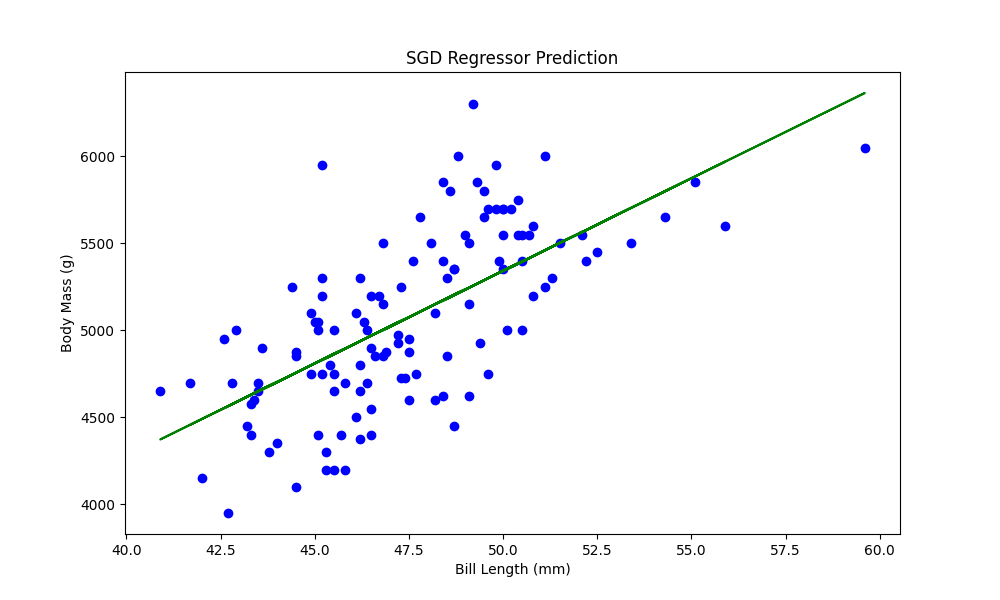
データの取得までは前回と同様ですが、確率的勾配降下法ではデータのスケーリングが効果的になってくるためsklearn.preprocessing.StandardScalerを使用しています。fit_transform()メソッドにより、平均が0、標準偏差が1となるような変換を行ってから線形回帰を行っています。
確率的勾配降下法にはsklearn.linear_model.SGDRegressorを使います。インスタンス生成時の主なパラメタは下記の通りです。
- loss : 損失関数の種類を指定します。デフォルトは'squared_loss'で最小二乗誤差を評価する線形回帰になります。
- penalty : 正則化の種類を指定します。デフォルトは'l2'で、これはL2正則化(リッジ回帰)を指します。他にも'l1'(L1正則化、ラッソ回帰)、'elasticnet'(Elastic Net、L1とL2の組み合わせ)が選択可能です。Noneにすると正則化項がなくなります。
- alpha:正則化の強さを制御します。デフォルトは0.0001です。値が大きいほど強く正則化し、過学習を抑制しますが、過度に大きいと未学習(underfitting)になります。
- max_iter:繰り返し計算回数(エポック数)を指定します。デフォルトは1000です。
- tol:許容誤差を指定します。繰り返し計算中に、損失関数がこの許容誤差以下の改善を見せない場合、アルゴリズムは収束したと判断され、停止します。デフォルトは1e-3です。
- learning_rate:学習率のスケジューリングを設定します。デフォルトは'invscaling'であり、エポック$t$における学習率$\eta(t)$は$\eta(t)=\frac{\eta_0}{t^{P}}$で表されます。ここで$\eta_0$は学習率の初期値であり、デフォルトでは0.01です。$P$はスケーリングを決める定数でデフォルトでは0.25です。
インスタンス作成後、SGDRegressor.fitというメソッドにスケーリングした学習データを渡して確率的勾配降下法の学習を行います。
学習後、predictメソッドにより予測値を計算できます。
学習データと予測値を、inverse_transformメソッドで元のスケールの戻して2次元プロットすると、最小二乗法の時と同様に回帰直線が引けていることが確認できます。
大量データでの実行時間の違い
前々回でも説明した通り、最小二乗法と勾配法では計算コストに差があります。実際に同じデータに対し2種類の方法で線形回帰を行い計算時間の測定を行います。
import time
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.datasets import make_regression
# 1000個の特徴量を持つ擬似データを10000サンプル作成
X, y = make_regression(n_samples=10000, n_features=1000, noise=0.1)
# 最小二乗法と確率的勾配降下法のモデルを作成
model_ols = LinearRegression()
model_sgd = SGDRegressor(max_iter=1000, tol=1e-3)
# 最小二乗法での学習時間の測定
start = time.time()
model_ols.fit(X, y)
end = time.time()
print("OLS fitting time: ", end - start)
# 確率的勾配降下法での学習時間の測定
start = time.time()
model_sgd.fit(X, y)
end = time.time()
print("SGD fitting time: ", end - start)
OLS fitting time: 1.1456398963928223
SGD fitting time: 0.2912015914916992
まずsklearn.datasets.make_regressionを使って線形回帰用の擬似データを作成します。主なパラメタは下記の通りです。
- n_samples:作成するサンプル数。デフォルト値は100です。
- n_features:特徴量の数。デフォルト値は10です。
- n_informative:実際に目的変数と関係がある特徴量の数。デフォルト値は10です。
- n_targets:目的変数の数。デフォルト値は1です。
- noise:目的変数に加える正規乱数ノイズの標準偏差。デフォルト値は1です。
1000個の特徴量をもつ10000サンプルの擬似データで2種類の方法で線形回帰を行うと、最小二乗法では約1.14秒、確率的勾配降下法では約0.29秒という結果になりました。この条件では確率的勾配降下法の方が学習が速いという結果が出ましたが、データのサイズや学習時のパラメタで比較結果は変わってくるのであくまでも参考の一つとして捉えてください。