こんにちは。
最近、NVIDIA-Certified Associate: Generative AI and LLMs (NCA-GENL)を習得しました。
その際に知っておいた方が良い基礎知識とコードの書き方を共有したいと思います。
生成AIのチュートリアル:
Mixture of Experts(MoE)とは? (アーキテクチャ)
一つの大きなタスクを、それぞれ特定のサブタスクに特化した複数の「専門家」(エキスパート)と呼ばれる小さなネットワークに分割し、どの専門家を使うべきかを決定する「ゲート」(ゲイティングネットワーク/ルーティングメカニズム)を組み合わせたモデル・アーキテクチャの事。
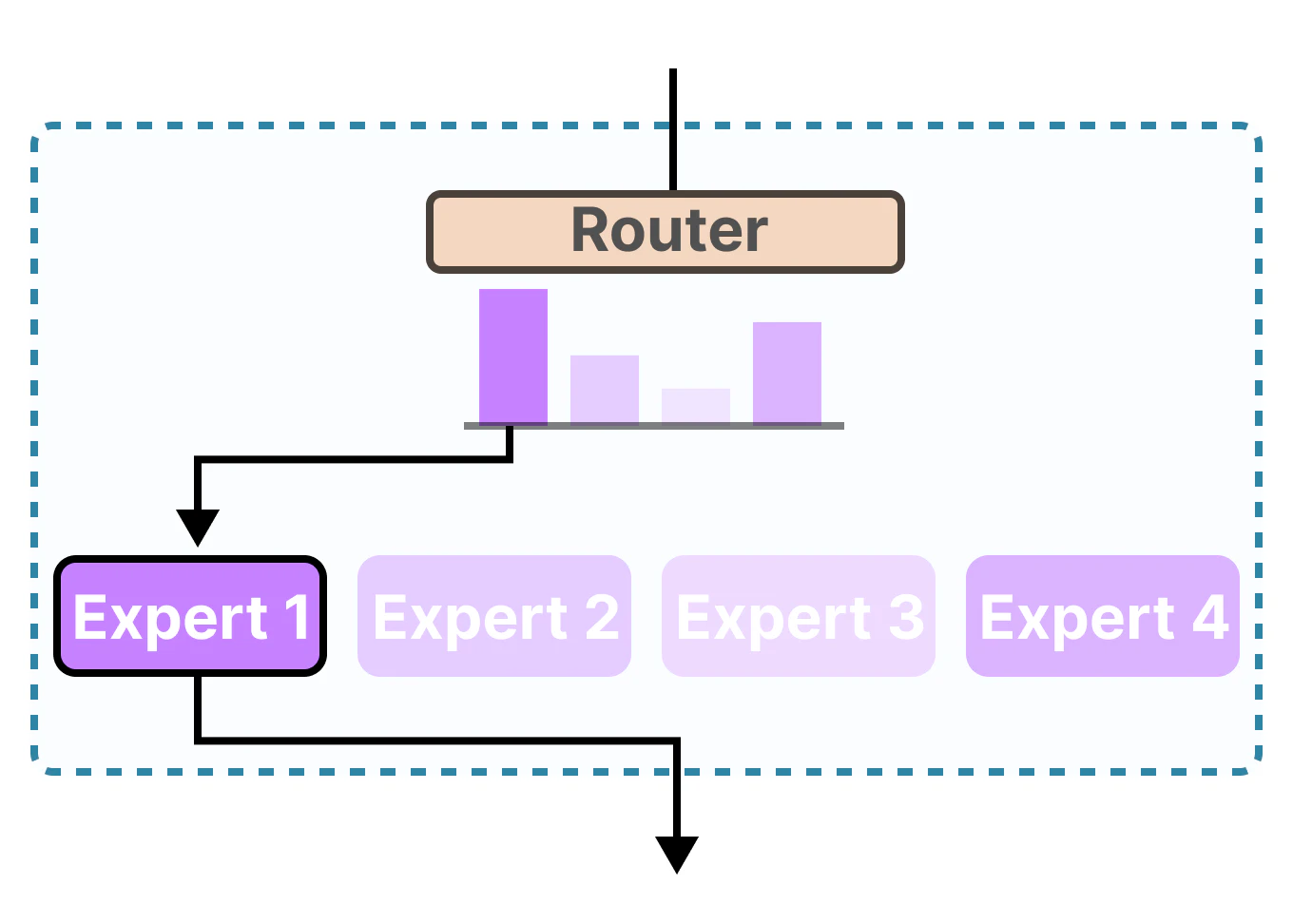
有名なモデルはMixtral-8x7B
8x7Bの意味は70億個のニューロンモデルが8個という意味。
Mixtral-8x7BはLlama 2 70Bより性能が良く速い。
元のアイデアは1991年のAdaptive Mixture of Local Experts: https://www.cs.toronto.edu/~fritz/absps/jjnh91.pdf
2.トレーニングの仕方
- データ: モデルは、幅広いタスクやドメインを網羅する多様なデータセットで訓練され各エキスパートを異なる種類のデータに触れさせるのが重要。
- ルーティングメカニズム: MoEモデルには、入力データのどの部分をどの専門家が処理するかを決定するルーティングメカニズム(多くの場合、学習可能なゲート)がある。トレーニング中に、このゲートは、それぞれのエキスパートの持ち上がりつつある専門性に基づいて、異なる種類のデータを異なるエキスパートへとルーティングすることを学習する。
- エキスパートの特化: トレーニングが進むにつれて、各トレーニングは特定の種類のデータやタスクの処理に徐々に熟達していき、ルーティングメカニズムによって指示された、最も効果的に処理できる種類のデータを受け取り、そこから学習する。
- フィードバックループ: フィードバックループがあり、あるエキスパートが特定の種類のデータの処理に長けてくると、ルーター(ルーティングメカニズム)は同様のデータをそのエキスパートに送る可能性が高まる。これにより、各エキスパートの特化が強化される。
- 正則化と損失関数: トレーニングには、効率的な学習を促進し、一つのエキスパートが「何でも屋」になるシナリオを回避するための正則化手法や特殊な損失関数が含まれる。
- 容量制約: エキスパートに容量制約を課すことにより、モデルは単一の専門家がタスクで過負荷になることを防ぎ、すべての専門家間での学習のバランスの取れた分散をする。
3.MoE(Mixtral-8x7B)の働き方
- ルーティングの決定: 各トークンはルーターネットワークによって決定され、ルーターは、この特定のトークンを処理すべき8つの利用可能なエキスパート(フィードフォワードブロック)のうち、どの2つを選択すべきかを決定。この決定は、トークンの特性とエキスパートの専門機能に基づいて行われる。
- エキスパートによる処理: 選択されたエキスパートは、トークンを処理。各エキスパートは、特定の種類のデータやタスクに特化した独自のニューラルネットワーク層を適用。
- アウトプットの結合: 処理後、選択された2つのエキスパートからのアウトプットは結合され、アウトプットの平均化、結合、または各エキスパートが収集した情報を統合するための他の方法が適用されたりする。
- レイヤーを越えての継続: このプロセスは、モデルの各レイヤーで繰り返されます。すべてのレイヤーで、ルーターネットワークはトークンの現在の状態に基づいて異なる専門家のペアを選択。
- 最終アウトプットの生成: トークンがすべてのレイヤーを通過した後、最終アウトプットが生成される。