GitHub にあるリポジトリの Issues を Markdown に変換して、NotebookLM で調査します。
トラブルが発生したとき、大量の Issue から類似の問題が報告されているか確認するのに威力を発揮します。
GitHub CLI
Issues のダウンロードは GitHub CLI を使用します。
認証
GitHub CLI は GitHub API を使用します。GitHub API は、認証の有無でレート制限が変わります。
1 時間あたり、未認証では 60 リクエスト、認証済なら 5,000 リクエストです。大量の Issues の取得には複数回のリクエストが必要となるため、認証を済ませておくことを推奨します。
認証は gh auth login として、指示に従ってください。ブラウザ経由での方法と、トークンを貼り付ける方法の 2 種類が選択できます。
Issues の取得
以下のコマンドで、指定したリポジトリの open なすべての Issue が取得できます。
gh api repos/OWNER/REPO/issues --paginate | python -m json.tool > issues.json
OWNER/REPO は適宜書き換えてください。
取得した JSON には各 Issue にぶら下がっているコメントは含まれないため、必要な場合は別途取得する必要があります。(後述)
gh のサブコマンドとして用意されている gh issue list を使う方が素直だとは思いますが、試行錯誤の結果、ざっとすべての情報を取得するには gh api の方が手軽だと判断しました。
Markdown への変換
jq コマンドで情報を絞り込んで Markdown に変換します。
jq -r '(.[0].repository_url | split("/")[-2:] | join("/")) + " Issues" + ([.[] | "\n\n# \(.number). \(.title)\n\n\(.body)" | gsub("\r"; "")] | add)' issues.json > issues.md
gh コマンドでも直接 jq 互換の整形が可能です。今回は必要に応じて情報が取り出せるように、JSON の取得と整形を分離しました。
参考: Python
jq で何をやっているかは、参考までに Python で同じ処理を書いておくので、比較してみてください。
import json
with open('issues.json', 'r', encoding='utf-8') as f:
issues = json.load(f)
with open('issues.md', 'w', encoding='utf-8') as f:
# jq: (.[0].repository_url | split("/")[-2:] | join("/")) + " Issues"
f.write('/'.join(issues[0]['repository_url'].split('/')[-2:]) + " Issues")
# jq: [.[] | "\n\n# \(.number). \(.title)\n\n\(.body)" | gsub("\r"; "")] | add
f.write("".join(
f"\n\n# {i['number']}. {i['title']}\n\n{i['body'] or 'null'}".replace('\r', '')
for i in issues
))
f.write("\n")
このようなコードを書かなくても、jq ならワンライナーで処理できるということです。
NotebookLM
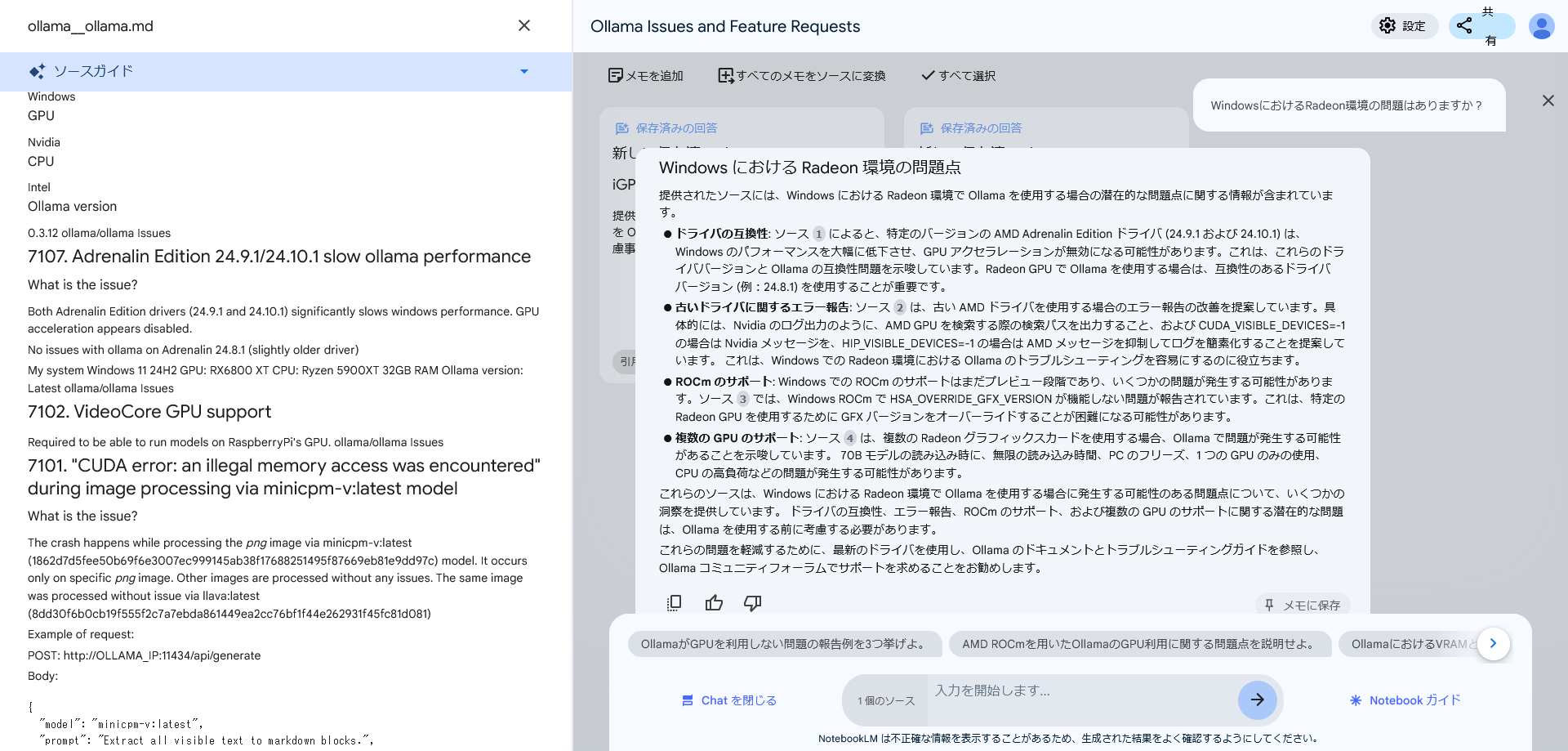
変換した issues.md を NotebookLM に読み込ませれば、ピンポイントで内容について質問できます。
使用例: Ollama
コメント
コメントは Issue ごとに個別に取得する必要があります。リクエスト回数が増大して、ログのサイズも巨大になります。
gh issue view 番号 --repo OWNER/REPO --json number,title,body,comments | python -m json.tool > issues/番号.json
番号 や OWNER/REPO は適宜書き換えてください。
既に取得した issues.json を基にコメント付きで取得する例です。
TARGET=OWNER/REPO
mkdir -p $TARGET
for i in `jq -r '.[].number' issues.json`; do
echo $TARGET/$i;
(gh issue view $i --repo $TARGET --json number,title,body,comments | python -m json.tool > $TARGET/$i.json);
done
試しにコメント付きで Markdown に変換して NotebookLM に読み込ませてみたのですが、情報量が増えすぎたためか肝心な情報が薄まって、既出チェックにはあまり向かないようでした。
個別の事例を探すのではなく、開発コミュニティの雰囲気を知るなどの目的であれば、コメント付きのデータを読み込ませるのも面白いと思います。
変換コード例: Python
取得した個別の Issue を 1 つの JSON にマージして、Markdown に変換するコード例を示します。
import json
from pathlib import Path
def merge_issues(owner_repo):
"""ダウンロードした issue の JSON ファイルをマージして出力し、データを返す"""
dir_path = Path(owner_repo)
if not dir_path.is_dir():
print(f"Directory not found: {dir_path}", file=sys.stderr)
return
# 数字のみのファイル名を取得
json_files = sorted(
(f for f in dir_path.glob("*.json") if f.stem.isdigit()),
key=lambda p: int(p.stem)
)
# JSON ファイルを読み込んでマージ
issues = []
for json_file in json_files:
try:
with open(json_file, "r", encoding="utf-8") as f:
issues.append(json.load(f))
except (json.JSONDecodeError, ValueError) as e:
print(f"Error reading {json_file}: {e}", file=sys.stderr)
continue
# マージしたデータを保存
output_file = Path(owner_repo) / "merge.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(issues, f, indent=2, ensure_ascii=False)
print(f"Merged {len(issues)} issues into {output_file}")
return issues
def convert_issues_to_markdown(owner_repo, issues):
"""issues を Markdown に変換して保存する"""
output_file = Path(owner_repo) / "merge.md"
with open(output_file, "w", encoding="utf-8") as f:
print(f"{owner_repo} Issues", file=f)
for issue in issues:
print(file=f)
print(f"# {issue['number']}. {issue['title']}", file=f)
print(file=f)
print(issue['body'].replace("\r\n", "\n").rstrip(), file=f)
for comment in issue['comments']:
print(file=f)
print(f"## {comment['author']['login']}", file=f)
print(file=f)
print(comment['body'].replace("\r\n", "\n").rstrip(), file=f)
print(f"Converted {len(issues)} issues into {output_file}")
target = "OWNER/REPO"
issues = merge_issues(target)
convert_issues_to_markdown(target, issues)
関連記事
この手法を実際に問題解決に使用した記事です。