背景
以前投稿した記事でPythonでSubscanAPIを使用してDOTのStakingRewardsからCryptactのカスタムファイルを保存する方法を紹介しました。
作成したコードはターミナルから実行してcsvファイルを指定のパスに保存する形式でしたが、保存内容の確認には都度csvファイルを開く必要があり手間でした。
そこで今回は以前作成したコードをベースに以下に対応したWindows/Mac向けのGUIアプリを作成しました。
- 取引履歴データはUI上で指定し、表(テーブル)形式で表示
- 対象とする取引履歴データは下記に対応
- Reward&Slashの取引履歴(Download all data)
- Cryptactカスタムファイル(ステーキング報酬)
- CSVファイル保存(Save as指定)
作成したもの
PythonでGUIを作成できるPySimpleGUIとSubscan APIを使用して、HTTPのPOSTリクエストで受信したJSONデータをpandas.DataFrameに変換してテーブル形式で表示します。
テーブル上のデータはセルを選択すると「選択したテーブルの値」に表示します。
GUIアプリではReward&Slashの取引履歴(Download all data)とCryptactカスタムファイル(ステーキング報酬)の取引履歴を取得対象(トークン)、履歴タイプ、件数、ソートタイプをUIで設定して履歴取得ボタンを実行することで表示します。
取引履歴データの情報(列名、API情報など)は取得対象(トークン)と履歴タイプで異なるため、それぞれtomlファイル(config.toml)で管理する形式にしました。
取得対象のTokenとSubscan API情報について
取引履歴データ(StakingRewards)はAPI Endpointの仕様に合わせてトークン毎に下記Request URLを指定して取得します。
| Token | API | Request URL | module_id | event_id |
|---|---|---|---|---|
| DOT | V2 API | reward-slash-v2 | Staking | Reward |
| KSM | V2 API | reward-slash-v2 | Staking | Reward |
| ASTR | Staking API | reward-slash | dappsstaking | Reward |
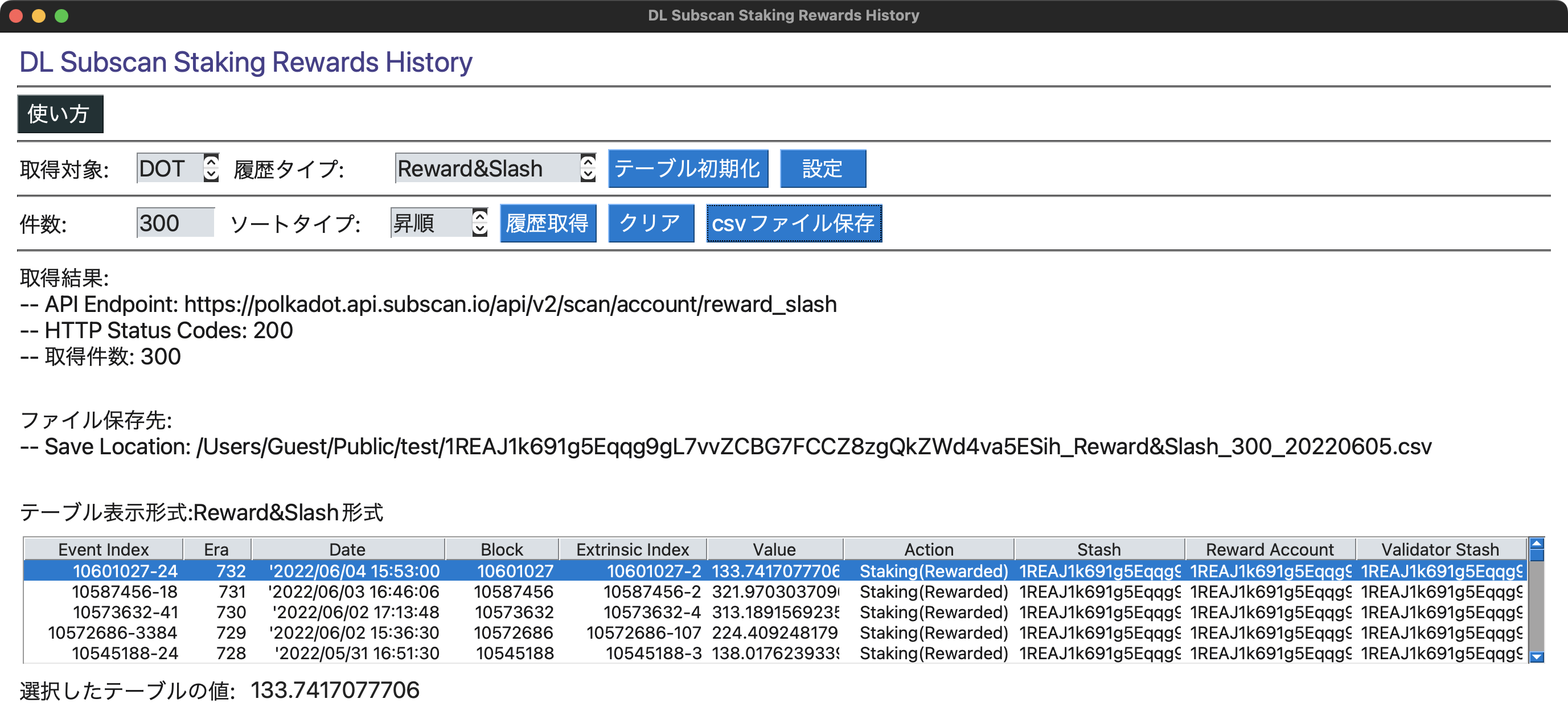
取得結果例
注意
以下はSubscan APIのDocsに記載されたアカウントのReward&Slash
(2022/06/05時点)の取引履歴になります。
Reward&Slashの取引履歴(Download all data)の取得結果
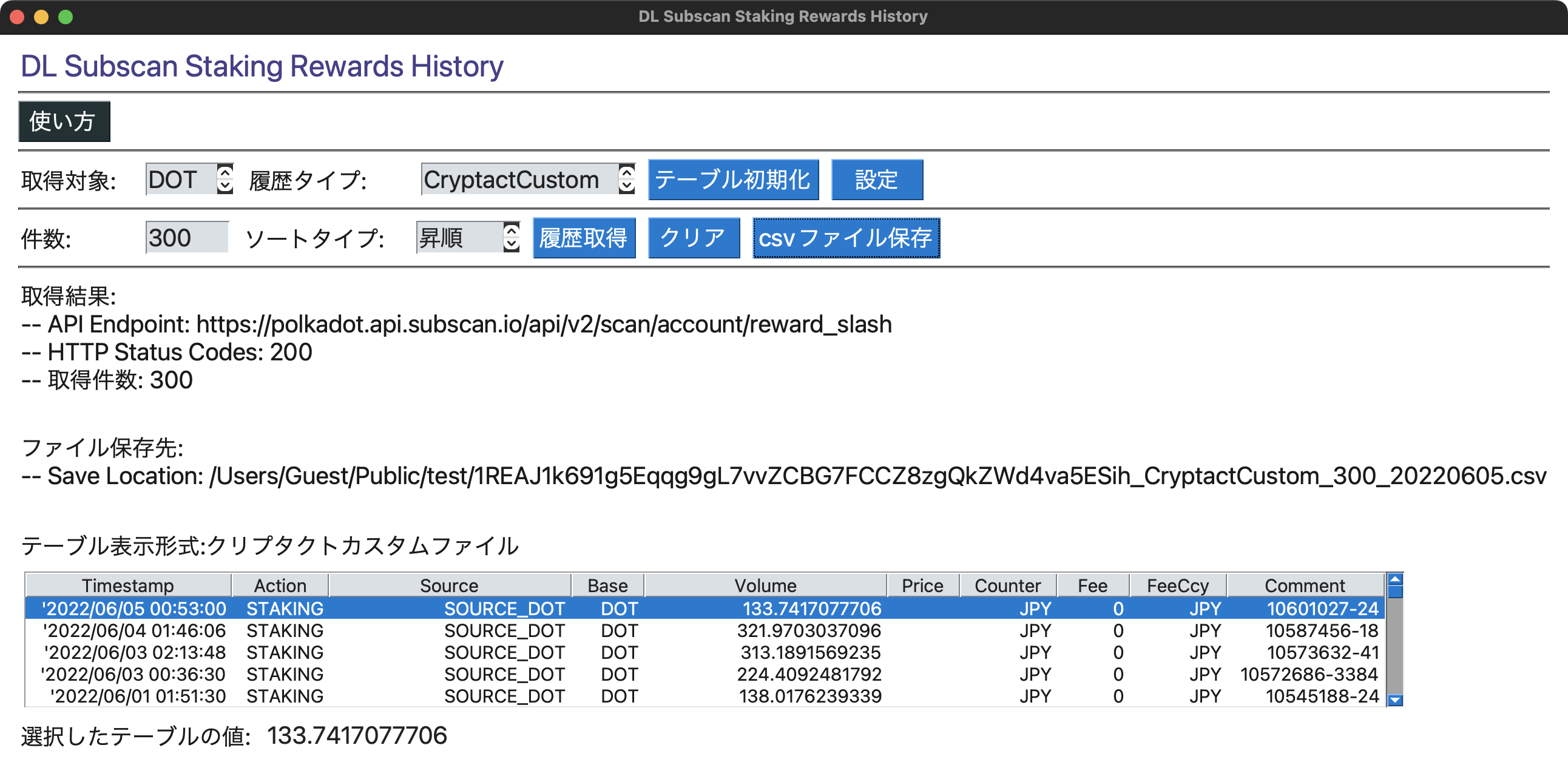
Cryptactカスタムファイル([ステーキング報酬]の取得結果
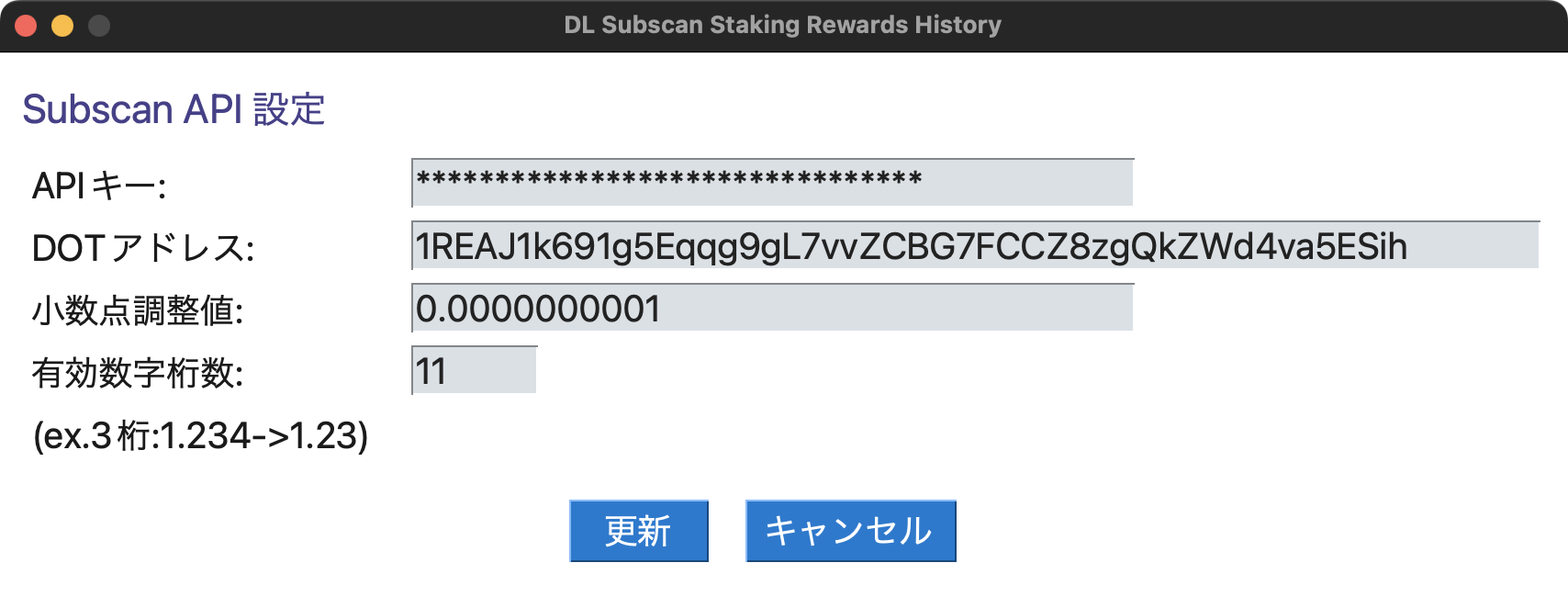
Subscan API情報設定画面
PySimpleGUIを使用した理由
PythonでGUIを作成する方法を調べていたところこちらの動画を見つけて、
・1行でGUIを作成できるシンプルさ
・matplotlibやOpenCVなどのモジュールをレイアウトに組み込むことができる点
が使いやすそうで、やりたいことが実現できそうだったのと実際にコードを書いて動かしてみたいと思ったためです。
また、PySimpleGUIのGitHubには実際に動かせるDemoProgramsがあります。
本アプリでもいくつか参考にしたコードがあります。
PySimpleGUIを使用するときにはプログラムを実行してみることをおすすめします。
使い方
GithubのREADME.mdをご確認ください。
追加情報(2023/08/19)
上記コードをベースにDashとPlotlyを使用したWebアプリを作成しました。
詳細は割愛しますが、仕様はデータの取得処理は同じですが、Webアプリではステーキング報酬の積算値のグラフも表示しています。(Demo参照)
興味があれば合わせてご確認ください。
注意事項
以下の記載を確認ください。
- 特定のアカウントに対する受信データの確認は実施していますが、必ずしも期待されたデータを取得することは保証しません。
- 本コードを実行したこと、参考にしたことによって被るあらゆる損害について責任を負いかねますのでご注意ください。
- Subscanの仕様やクリプタクトのデータフォーマットは変わることがありますので、最新の情報を確認してください。
- 取引履歴は取引状況に依存します。アプリを使用時はSubscan API情報を設定し、取得したデータについて目的のデータを作成できていること、トランザクションデータを参照して誤りがないことを必ず確認してください。
- 対象とするNetworkはPolkadot,Kusama,Astarです。他のNetworkは未サポートです。(参考:API Endpoints)
- ソースコードはMacBookPro 13inchに合わせて作成しています。Windows他、スペックが毎なるケースではレイアウトが上記の取得結果例と異なる可能性があります。データの取得処理に影響がないことは確認していますがご注意ください。
ソースコードについて
以下ではアプリのディレクトリ構成と各ファイルの役割と処理について説明します。
アプリのディレクトリ構成
-
poetry.lockとpyproject.tomlにはPoetryで管理するパッケージファイル情報が記載されています。 -
requirements.txtには必要なパッケージファイル情報が記載されています。 - srcにはアプリで使用するpythonファイルとtomlファイルが格納されています。
- testsにはPythonのテストコードが格納されていますが、プログラムでは使用しません。(Poetryの開発環境でのみ使用します。)
- umlには
.svgと.pumlファイルが格納されていますが、プログラムでは使用しません。
# 一部フォルダの表示結果を省略しています。
dlSubscanStakingRewardsHistory$ tree -a -L 2
.
├── .git
├── .gitignore
├── LICENSE
├── README.md
├── csv_sample
├── png
├── poetry.lock
├── pyproject.toml
├── requirements.txt
├── src
│ ├── __init__.py
│ ├── config.toml
│ ├── cryptact.py
│ ├── gui.py
│ ├── main.py
│ └── subscan.py
├── tests
│ ├── __init__.py
│ └── test_cryptact.py
└── uml
├── classes_dlSubscanStakingRewardsHistory
└── packages_dlSubscanStakingRewardsHistory
クラス図
UMLファイルをPyreverseとPlantUMLから作成しました。
packages_dlSubscanStakingRewardsHistory.uml
モジュールの依存関係は下記の通りです。
Pyreverseではファイル出力でPackage DiagramとClass Diagramを出力できますが、本コードの場合はモジュール同士の依存関係を示すものとなります。

classes_dlSubscanStakingRewardsHistory.uml
クラス図と各ファイルの役割と処理は下記の通りです。
-
main.pyではconfig情報の読み込み、GUI作成、およびデータの表示処理 -
gui.pyではGUIのレイアウト管理(設定、更新) -
subscan.pyではデータの送受信処理、加工処理 -
cryptact.pyではCryptactカスタムファイル形式のヘッダーデータ作成
トークン毎の処理はconfig.tomlに応じて切り替えます。
また、CryptactカスタムファイルのクラスおよびメソッドはReward&Slash用のクラスを継承します。

APIの仕様(制限)と取得処理ついて
以前投稿した記事で取得件数はrow,データの開始要素数(listオブジェクト)はrow * pageで決まることを説明しましたが、1pageで取得できる件数は100件までという上限が設定されていることがわかりました。
そのため、100件より多い履歴を持つ場合、単純に件数分POSTリクエストするとエラーになります。
そこで今回は件数に対して100件/ページとなるように調整し、件数に対するページ数分POSTリクエストを送信する形式にしました。
受信データ(JSON)はRequest URLを指定することで取得できますがトークン毎に異なります。本アプリではトークン毎の情報をtomlファイルで定義し、
JSONデータ(list型)->ページ単位データ(dataframeオブジェクト)->Responseデータ(list型) に変換してテーブルに表示するデータを作成します。
100件より大きい件数を取得する場合はページ単位でデータを結合するためsetterメソッドを使用して作成します。
テーブルの作成と表示について
受信したデータはUI上で表形式で表示するため以下の仕様で実装します。
①アプリ起動時はテーブルを表示せず、取引履歴表示ボタン押下でテーブルを表示する
②テーブルの値は取得対象(トークン)、件数、履歴パターン、ソートタイプの指定に従い表示する
③テーブルの値は選択表示する
④クリアボタン押下でテーブルの値を空にして非表示にする
仕様①: アプリ起動時はテーブルを表示せず、取引履歴表示ボタン押下でテーブルを表示する
PySimpleGUIでTableを使用するためにはTableクラスのインスタンスを作成することで表示することができます。また、表示、非表示は引数を指定することで対応可能ですが、対象の引数visibleをFalse(非表示)にするとスクロールバーのみ表示されます。そこでコンテナの形式でインスタンスをまとめるColumn ElementのvisibleをFalseにすることで非表示にします。
def main_window(self):
# テーブル要素(cURLで受信した値を表示するレイアウト)
# Tableでvisible=Falseにするとスクロールバーのみ表示されるためColumnの指定で非表示にする(culumn_layout参照)
# Tableの値を更新するためベースのTableを作成する(ヘッダーはconfig.iniで定義した値,表の値はvaluesで指定する)
# valuesは10行15列のテーブル指定で初期化する(テーブルはこの値に依存するためnum_rowsの指定と合わせる)
data = [[0 for j in range(10)] for i in range(15)]
# 初期値で生成したTableを表示するためvisible_columnsをTrue(リスト指定)にする
vclum = True
font_info = "游ゴシック Medium"
if self.__history_type == "Reward&Slash":
# 列数と列幅をトークン毎に設定する
if self.__token_data == "DOT":
visible_columns = [vclum for x in range(10)]
col_widths_token = [14, 6, 17, 10, 13, 12, 15, 15, 15, 15]
elif self.__token_data == "KSM":
visible_columns = [vclum for x in range(9)]
col_widths_token = [14, 6, 17, 10, 13, 12, 15, 15, 15]
elif self.__token_data == "ASTR":
visible_columns = [vclum for x in range(6)]
col_widths_token = [11, 17, 8, 15, 20, 20]
table_layout = sg.Table(
values=data,
headings=self.__reward_slash_data_header_token,
font=(font_info, 15),
visible_column_map=visible_columns,
# 各列が占める文字数指定
col_widths=col_widths_token,
# Trueにすると列幅が固定になるためFalseとする
# https://github.com/PySimpleGUI/PySimpleGUI/issues/4375
auto_size_columns=False,
# 一度に表示するテーブルの行数を指定(表示するテーブルの行数<初期化したテーブルの行数)
num_rows=min(5, len(data)),
enable_events=True,
key="-TABLE-",
)
elif self.__history_type == "CryptactCustom":
visible_columns = [vclum for x in range(10)]
table_layout = sg.Table(
values=data,
headings=self.__cryptact_header_data,
font=(font_info, 15),
visible_column_map=visible_columns,
# 各列が占める文字数指定(トークン共通)
col_widths=[17, 8, 20, 6, 20, 6, 8, 6, 8, 13],
# Trueにすると列幅が固定になるためFalseとする
# https://github.com/PySimpleGUI/PySimpleGUI/issues/4375
auto_size_columns=False,
# 一度に表示するテーブルの行数を指定(表示するテーブルの行数<初期化したテーブルの行数)
num_rows=min(5, len(data)),
enable_events=True,
key="-TABLE-",
)
# コンテナ要素(culumn_layoutではTable要素を指定するレイアウト)
# Tableでvisible=Falseにするとスクロールバーのみ表示されるため
# Column上にTableを埋め込みColumnのvisible=Falseに指定してTableを非表示にする
# Columnのscrollableは表示しないためFalseに指定する
# https://github.com/PySimpleGUI/PySimpleGUI/issues/2102
culumn_layout = sg.Column(
[[table_layout]], scrollable=False, visible=False, key="-COL-"
)
PySimpleGUIでは値を変更する方法として、各クラスの要素(Elementクラスのtext情報)を更新するメソッドとしてupdateメソッドが定義されており、それを任意のeventで呼び出すことで値を変更することができます。しかしTableクラスではupdateメソッドがないため、PySimpleGUIのラッパーであるtkinterのメソッドを使用して変更します。
# 受信データエラー判定
# codeエラーの場合
if response_code != 0:
text = f"code: {response_code}\n\nError Details: Invalid Account Address.\nPlease Check Account Address:\n"
sg.popup_scrolled(
"error", text, size=(40, 6), font=(self.__font_info, 20)
)
window.close()
quit()
# HTTP Status Codesエラー
if response_status_code != 200:
text = f"HTTP Status Codes: {response_status_code}\n\nPlease Check Subscan API Documents:\n{self.__config_subscan_api_doc}\n"
sg.popup_scrolled(
"error", text, size=(40, 6), font=(self.__font_info, 20)
)
window.close()
quit()
if list_num == 0:
text = "値を取得できませんでした。\nアカウントアドレス、または、取得した値を確認してください。\nアプリを終了します。"
sg.popup_scrolled(
"error", text, size=(40, 5), font=(self.__font_info, 20)
)
window.close()
quit()
# テーブル要素取得
table = window["-TABLE-"]
# response_data_layoutでTableの値(pandas.DataFrame)を表示するために
# tkinterのイベントを追加(クリック時にeventが-TABLE-CLICK-で通知される)
# https://stackoverflow.com/questions/68173962/how-to-obtain-the-row-and-column-of-selected-cell-in-pysimplegui
table.bind("<Button-1>", "CLICK-")
# Table Elementにテーブル属性はあるが、updateメソッドが存在しないためheading情報を指定して更新する
# windowsインスタンスではAttributeError: 'NoneType'となるため見出しを取得するためWidgetプロパティを指定する
# https://github.com/PySimpleGUI/PySimpleGUI/issues/1307
sg_gui.update_title(table.Widget, header_list)
# cURLで受信した値で更新する
window["-TABLE-"].update(response_data)
# ColumnとTableを表示するためvisibleをTrueにする
# https://github.com/PySimpleGUI/PySimpleGUI/issues/2102
window["-COL-"].update(visible=True)
# csvファイル保存ボタンを有効化
window["-SAVE-"].update(disabled=False)
if int(input_num) > int(len(df_csv)):
supplement = " ( ※存在する履歴の上限値まで取得しました )"
else:
supplement = ""
output_string = f"取得結果:\n-- API Endpoint: {api_endpoint}\n-- HTTP Status Codes: {response_status_code}\n-- 取得件数: {len(df_csv)}{supplement}\n"
window["-OUTPUT1-"].update(output_string)
if values["-HISTORY-"] == "Reward&Slash":
table_title_string = "テーブル表示形式:Reward&Slash形式"
elif values["-HISTORY-"] == "CryptactCustom":
table_title_string = "テーブル表示形式:クリプタクトカスタムファイル"
window["-SHOW_TABLE-"].update(table_title_string)
def update_title(self,table, headings):
if self.__history_type == 'Reward&Slash':
header_data = self.__reward_slash_data_header_token
elif self.__history_type == 'CryptactCustom':
header_data = self.__cryptact_heder_data
# テーブルのヘッダー更新
for cid, text in zip(header_data, headings):
table.heading(cid, text=text)
仕様②: テーブルの値は取得対象(トークン)、件数、履歴パターン、ソートタイプの指定に従い表示する
データ処理はsubscan.pyで行います。データはクラスのコンストラクタ、インスタンスメソッドからPOST Request、エラー情報作成、テーブルに表示するデータの作成(結合)を行います。main.pyではメソッドの戻り値として取得した変数からエラー可否を判断し、エラーの場合はエラー用のPopUpを表示します。
Reward&Slashの取引履歴(Download all data)の受信処理
class SubscanStakingRewardDataProcess:
def __init__(self, input_num, config_subscan_api_info, token, sort):
# インスタンス作成
self.subscan_stkrwd_df = SubscanStakingRewardsDataFrame(
config_subscan_api_info, token
)
self.subscan_api_data = SubscanApiInfo(config_subscan_api_info, token)
# get_stkrwd_header_dfメソッドでdataframe初期化
self.df_header = self.subscan_stkrwd_df.df_stkrwd_header_data
# get_stkrwd_header_dfでヘッダー作成
self.header_list = self.subscan_stkrwd_df.df_stkrwd_header_data
# API情報取得
(
self.api_endpoint,
self.headers_dict,
self.data_dict,
self.adjust_value,
) = self.subscan_api_data.subscan_api_info
# 取得件数入力
self.input_num = int(input_num)
# API情報更新(件数で上書き)
self.data_dict["row"] = self.input_num
self.token = token
# ソート情報生成
if sort == "昇順":
self.sort_type = True
else:
self.sort_type = False
# 受信データ初期化
self.response_data = []
data_list = [["data1", 1], ["data2", 2]]
self.sort_df_retrieve = pd.DataFrame(data_list, columns=["culumn1", "culumn2"])
# Config情報取得
display_digit_config = f"display_digit_{token.lower()}"
# 有効桁数はformatメソッドで処理するため-1する
self.digit = str(int(config_subscan_api_info[display_digit_config]) - 1)
def get_subscan_stakerewards(self):
# list要素数初期化
list_num = 0
# list要素の合計値初期化
list_num_sum = 0
# input_numが100より大きい場合、rowは上限値100のため、分割処理するため件数から処理回数を計算する
if self.input_num > 100:
# 取得するページ数の最大値を計算
# ex)120->1.2->1,1+1で2となる
page_renge = math.floor(self.input_num / 100) + 1
# rowを更新(rowの上限値は100のため100row/pageとする)
self.data_dict["row"] = 100
for page in range(page_renge):
# API rate limit exceededを考慮して0.2秒sleep
time.sleep(0.2)
# pegeを更新
self.data_dict["page"] = page
# Staking API / rewards-slash指定 / row:100, page:pageで送信
response = requests.post(
self.api_endpoint,
headers=self.headers_dict,
data=json.dumps(self.data_dict),
)
# HTTP Status Codes
response_status_code = response.status_code
# レスポンスデータ(JSON形式)
response_json = response.json()
# エラーチェック
try:
response_code = response_json["code"]
except Exception as e:
# ex)API rate limit exceeded
print(e)
break
try:
# アドレス不正でなければlistの要素数を取得
if response_code != 400:
try:
list_num = len(response_json["data"]["list"])
except TypeError as e:
print(e)
list_num = 0
except TypeError as e:
count = response_json["data"]["count"]
print(
f"TypeError, but at this point, the data reading process has been executed up to the upper limit, so the iterative process is terminated. / count: {count}\n"
)
print(e)
break
# 1ページ毎にlist要素数を加算する
list_num_sum += list_num
# Response結果にエラーがなく、リストが存在すれば受信データを作成する
if (
response_status_code == 200
and response_code == 0
and list_num_sum != 0
):
for item in range(list_num):
one_line_headerdata_list = (
self.subscan_stkrwd_df.get_reward_slash_data(
item, response_json
)
)
if self.token == "DOT" or self.token == "KSM":
one_line_data_list = self.subscan_stkrwd_df.get_reward_slash_data_var_dot_ksm(
one_line_headerdata_list, self.adjust_value, self.digit
)
elif self.token == "ASTR":
one_line_data_list = (
self.subscan_stkrwd_df.get_reward_slash_data_var_astr(
one_line_headerdata_list,
self.adjust_value,
self.digit,
)
)
df_page = self.subscan_stkrwd_df.json_to_df(
self.df_header, item, one_line_data_list
)
# setterでlistからDataFrame作成(結合)
self.subscan_stkrwd_df.df_stkrwd_header_data = df_page
# getterで作成(結合)されたDataFrameを取得
concat_df = self.subscan_stkrwd_df.df_stkrwd_header_data
# 重複行削除
concat_df_duplicates = concat_df.drop_duplicates()
# page_renge分取得したデータから件数分抽出する
df_retrieve = concat_df_duplicates.iloc[: self.input_num, :]
# ソート
self.sort_df_retrieve = self.sort_dataframe(
df_retrieve, self.sort_type
)
# 抽出後のデータをリスト化
self.response_data = self.sort_df_retrieve.values.tolist()
# list要素の合計値で上書き
list_num = list_num_sum
else:
# self.input_num <= 100
# Staking API / rewards-slash指定
response = requests.post(
self.api_endpoint,
headers=self.headers_dict,
data=json.dumps(self.data_dict),
)
# HTTP Status Codes
response_status_code = response.status_code
# レスポンスデータ(JSON形式)
response_json = response.json()
response_code = response_json["code"]
# listの要素数を取得
if response_code != 400:
try:
list_num = len(response_json["data"]["list"])
except TypeError as e:
print(e)
list_num = 0
# Response結果にエラーがなく、リストが存在すれば受信データを作成する
if response_status_code == 200 and response_code == 0 and list_num != 0:
# 受信データ数分処理する
for item in range(list_num):
one_line_headerdata_list = (
self.subscan_stkrwd_df.get_reward_slash_data(
item, response_json
)
)
if self.token == "DOT" or self.token == "KSM":
one_line_data_list = (
self.subscan_stkrwd_df.get_reward_slash_data_var_dot_ksm(
one_line_headerdata_list, self.adjust_value, self.digit
)
)
elif self.token == "ASTR":
one_line_data_list = (
self.subscan_stkrwd_df.get_reward_slash_data_var_astr(
one_line_headerdata_list, self.adjust_value, self.digit
)
)
df_page = self.subscan_stkrwd_df.json_to_df(
self.df_header, item, one_line_data_list
)
# ソート
self.sort_df_retrieve = self.sort_dataframe(df_page, self.sort_type)
# 抽出後のデータをリスト化
self.response_data = self.sort_df_retrieve.values.tolist()
return (
response_code,
self.api_endpoint,
response_status_code,
self.header_list,
self.response_data,
self.sort_df_retrieve,
list_num,
)
def sort_dataframe(self, df, sort_type):
num = len(df)
sort_Column = list(range(num))
df_s1 = df.assign(SortColumn=sort_Column)
df_s2 = df_s1.sort_values("SortColumn", ascending=sort_type)
df_s3 = df_s2.drop("SortColumn", axis=1)
return df_s3
Cryptactカスタムファイル(ステーキング報酬)用データ作成処理
class SubscanStakingRewardsDataProcessForCryptact(SubscanStakingRewardDataProcess):
def __init__(
self, input_num, config_subscan_api_info, config_cryptact_info, token, sort
):
# インスタンス作成
self.subscan_stkrwd_df_for_cryptact = SubscanStakingRewardsDataFrameForCryptact(
config_subscan_api_info, config_cryptact_info, token
)
self.subscan_api_data = SubscanApiInfo(config_subscan_api_info, token)
self.cryptact_info_data = CryptactInfo(config_cryptact_info, token)
# get_cryptact_header_dfメソッドでdataframe初期化
self.df_header = self.subscan_stkrwd_df_for_cryptact.df_cryptact_header_data
# get_cryptact_header_dfメソッドでヘッダー作成
self.header_list = self.subscan_stkrwd_df_for_cryptact.df_cryptact_header_data
# API情報取得
(
self.api_endpoint,
self.headers_dict,
self.data_dict,
self.adjust_value,
) = self.subscan_api_data.subscan_api_info
# 取得件数入力
self.input_num = int(input_num)
# API情報更新(件数で上書き)
self.data_dict["row"] = self.input_num
# ソート情報生成
if sort == "昇順":
self.sort_type = True
else:
self.sort_type = False
# 受信データ初期化
self.response_data = []
data_list = [["data1", 1], ["data2", 2]]
self.sort_df_retrieve = pd.DataFrame(data_list, columns=["culumn1", "culumn2"])
# Config情報取得
display_digit_config = f"display_digit_{token.lower()}"
# 有効桁数はformatメソッドで処理するため-1する
self.digit = str(int(config_subscan_api_info[display_digit_config]) - 1)
def create_stakerewards_cryptact_cutom_df(self):
# listの要素数初期化
list_num = 0
# list要素の合計値初期化
list_num_sum = 0
# input_numが100より大きい場合、rowは上限値100のため、分割処理するため件数から処理回数を計算する
if self.input_num > 100:
# 取得するページ数の最大値を計算
# ex)120->1.2->1,1+1で2となる
page_renge = math.floor(self.input_num / 100) + 1
# rowを更新(rowの上限値は100のため100row/pageとする)
self.data_dict["row"] = 100
for page in range(page_renge):
# API rate limit exceededを考慮して0.2秒sleep
time.sleep(0.2)
# pegeを更新
self.data_dict["page"] = page
# Staking API / rewards-slash指定 / row:100, page:pageで送信
response = requests.post(
self.api_endpoint,
headers=self.headers_dict,
data=json.dumps(self.data_dict),
)
# HTTP Status Codes
response_status_code = response.status_code
# レスポンスデータ(JSON形式)
response_json = response.json()
# エラーチェック
try:
response_code = response_json["code"]
except Exception as e:
# ex)API rate limit exceeded
print(e)
break
try:
# アドレス不正でなければlistの要素数を取得
if response_code != 400:
try:
list_num = len(response_json["data"]["list"])
except TypeError as e:
print(e)
list_num = 0
except TypeError as e:
count = response_json["data"]["count"]
print(
f"TypeError, but at this point, the data reading process has been executed up to the upper limit, so the iterative process is terminated. / count: {count}\n"
)
print(e)
break
# 1ページ毎にlist要素数を加算する
list_num_sum += list_num
# Response結果にエラーがなく、リストが存在すれば受信データを作成する
if (
response_status_code == 200
and response_code == 0
and list_num_sum != 0
):
for item in range(list_num):
one_line_headerdata_list = (
self.subscan_stkrwd_df_for_cryptact.get_reward_slash_data(
item, response_json
)
)
one_line_data_list = self.subscan_stkrwd_df_for_cryptact.get_reward_slash_data_var_cryptact(
one_line_headerdata_list,
self.cryptact_info_data,
self.adjust_value,
self.digit,
)
df_page = self.subscan_stkrwd_df_for_cryptact.json_to_df(
self.df_header, item, one_line_data_list
)
# setterでlistからDataFrame作成(結合)
self.subscan_stkrwd_df_for_cryptact.df_cryptact_header_data = (
df_page
)
# getterで作成(結合)されたDataFrameを取得
concat_df = (
self.subscan_stkrwd_df_for_cryptact.df_cryptact_header_data
)
# 重複行削除
concat_df_duplicates = concat_df.drop_duplicates()
# page_renge分取得したデータから件数分抽出する
df_retrieve = concat_df_duplicates.iloc[: self.input_num, :]
# ソート
self.sort_df_retrieve = self.sort_dataframe(
df_retrieve, self.sort_type
)
# 抽出後のデータをリスト化
self.response_data = self.sort_df_retrieve.values.tolist()
# list要素の合計値で上書き
list_num = list_num_sum
else:
# self.input_num <= 100
# Staking API / rewards-slash指定
response = requests.post(
self.api_endpoint,
headers=self.headers_dict,
data=json.dumps(self.data_dict),
)
# HTTP Status Codes
response_status_code = response.status_code
# レスポンスデータ(JSON形式)
response_json = response.json()
response_code = response_json["code"]
# listの要素数を取得
if response_code != 400:
try:
list_num = len(response_json["data"]["list"])
except TypeError as e:
print(e)
list_num = 0
# Response結果にエラーがなく、リストが存在すれば受信データを作成する
if response_status_code == 200 and response_code == 0 and list_num != 0:
# 受信データ数分処理する
for item in range(list_num):
one_line_headerdata_list = (
self.subscan_stkrwd_df_for_cryptact.get_reward_slash_data(
item, response_json
)
)
one_line_data_list = self.subscan_stkrwd_df_for_cryptact.get_reward_slash_data_var_cryptact(
one_line_headerdata_list,
self.cryptact_info_data,
self.adjust_value,
self.digit,
)
df_page = self.subscan_stkrwd_df_for_cryptact.json_to_df(
self.df_header, item, one_line_data_list
)
# ソート
self.sort_df_retrieve = self.sort_dataframe(df_page, self.sort_type)
# 抽出後のデータをリスト化
self.response_data = self.sort_df_retrieve.values.tolist()
return (
response_code,
self.api_endpoint,
response_status_code,
self.header_list,
self.response_data,
self.sort_df_retrieve,
list_num,
)
※ソート処理は継承元のsort_dataframe()を実行します。
if event == "-SHOW-":
window["-OUTPUT2-"].update("")
input_num = values["-INPUT-"]
address_token = f"address_{(sg_gui.token_data).lower()}"
address_token_value = self.__config_subscan_api_info[address_token]
decimal_point_adjust_token = (
f"adjust_value_{(sg_gui.token_data).lower()}"
)
decimal_point_adjust_token_value = self.__config_subscan_api_info[
decimal_point_adjust_token
]
display_digit_token = f"display_digit_{(sg_gui.token_data).lower()}"
display_digit_token_value = self.__config_subscan_api_info[
display_digit_token
]
# Subscan API設定値の確認
if (
address_token_value == ""
or decimal_point_adjust_token_value == ""
or display_digit_token_value == ""
):
sg.popup_ok(
"ERROR\nSubscan API設定を確認してください。\nアプリを終了します。",
font=(self.__font_info, 20),
button_color="red",
)
window.close()
quit()
# 入力値の異常値判定
if (
(input_num.isnumeric()) is False
or input_num == ""
or int(input_num) <= 0
):
sg.popup_ok(
"ERROR\n件数は1以上の整数で入力してください。アプリを終了します。",
font=(self.__font_info, 20),
button_color="red",
)
window.close()
quit()
# 件数(文字列)が数を表す文字か判定(1以上が真)
if input_num.isnumeric():
if values["-HISTORY-"] == "Reward&Slash":
stkrwd = SubscanStakingRewardDataProcess(
input_num,
self.__config_subscan_api_info,
values["-TOKEN-"],
values["-SORT-"],
)
(
response_code,
api_endpoint,
response_status_code,
header_list,
response_data,
df_csv,
list_num,
) = stkrwd.get_subscan_stakerewards()
elif values["-HISTORY-"] == "CryptactCustom":
cyrptactcustom = SubscanStakingRewardsDataProcessForCryptact(
input_num,
self.__config_subscan_api_info,
self.__config_cryptact_info,
values["-TOKEN-"],
values["-SORT-"],
)
(
response_code,
api_endpoint,
response_status_code,
header_list,
response_data,
df_csv,
list_num,
) = cyrptactcustom.create_stakerewards_cryptact_cutom_df()
# 受信データエラー判定
# codeエラーの場合
if response_code != 0:
text = f"code: {response_code}\n\nError Details: Invalid Account Address.\nPlease Check Account Address:\n"
sg.popup_scrolled(
"error", text, size=(40, 6), font=(self.__font_info, 20)
)
window.close()
quit()
# HTTP Status Codesエラー
if response_status_code != 200:
text = f"HTTP Status Codes: {response_status_code}\n\nPlease Check Subscan API Documents:\n{self.__config_subscan_api_doc}\n"
sg.popup_scrolled(
"error", text, size=(40, 6), font=(self.__font_info, 20)
)
window.close()
quit()
if list_num == 0:
text = "値を取得できませんでした。\nアカウントアドレス、または、取得した値を確認してください。\nアプリを終了します。"
sg.popup_scrolled(
"error", text, size=(40, 5), font=(self.__font_info, 20)
)
window.close()
quit()
仕様③: テーブルの値は選択表示する
テーブルの値を選択表示するため前述した'-TABLE-CLICK-'キーのイベントでテーブルの要素情報を取得し、pandas.DataFrameに対して.iat[]で値を抽出して表示します。
'-TABLE_DATA-'キーのレイアウトは初期値としてbackground_color = 'white'でsg.theme('Reddit')のテーマに合わせて白色で指定しますが、tkinterのWidget指定ではグレーになるため、白色の指定readonlybackground=sg.theme_background_color('white')で更新します。
if event == "-TABLE-CLICK-":
e = table.user_bind_event
region = table.Widget.identify("region", e.x, e.y)
# 選択する領域を識別(cellのみ値を取得する)
if region == "heading":
continue
elif region == "cell":
row = int(table.Widget.identify_row(e.y))
elif region == "separator":
continue
else:
continue
column = int(table.Widget.identify_column(e.x)[1:])
table_data = df_csv.iat[row - 1, column - 1]
table_data_string = table_data
# テーブル上で選択した値でresponse_data_layoutを更新
window["-TABLE_DATA_TITLE-"].update("選択したテーブルの値:")
window["-TABLE_DATA-"].update(table_data_string)
window["-TABLE_DATA-"].Widget.config(
readonlybackground=sg.theme_background_color("white")
)
window["-TABLE_DATA-"].Widget.config(borderwidth=0)
仕様④: クリアボタン押下でテーブルの値を空にして非表示にする
クリア処理は.update('')でテーブルの要素情報を空にします。
if event == '-UNSHOW-':
window['-COL-'].update(visible=False)
# テーブルクリア後はcsvファイル保存のボタンを無効化する
window['-SAVE-'].update(disabled=True)
window['-OUTPUT1-'].update('')
window['-OUTPUT2-'].update('')
window['-TABLE_DATA-'].update('')
window['-TABLE_DATA_TITLE-'].update('')
window['-SHOW_TABLE-'].update('')
まとめ
今回Subscan APIとPySimpleGUIを使用して以下に対応したWindows/Mac向けのGUIアプリを作成しました。
- Reward&Slashの取引履歴(Download all data)
- Cryptactカスタムファイル(ステーキング報酬)
ソースコードは前回と比較するとUI部分とデータ処理が増えたことでコード量が多くなるためオブジェクト指向で設計/実装しました。
処理が長いメソッドや重複処理もあるためリファクタリング要素はありますが、最低限モジュール単位でまとまりのある実装はできたのではないかと思います。
また、データの受信処理についてはトークン毎に情報をtomlファイルとメソッドで切り替えられるようにしたため、追加や変更がしやすい作りにできたと思います。個人的にはSubscan以外にも応用できると良いかと考えています。
PySimpleGUIについては行単位で定義するシンプルな形式で少ないコード量でGUIを作成できるのは良い印象でした。紹介した動画やデモプログラムも参考になりました。今後も他のライブラリや言語とセットで活用していこうと思います。