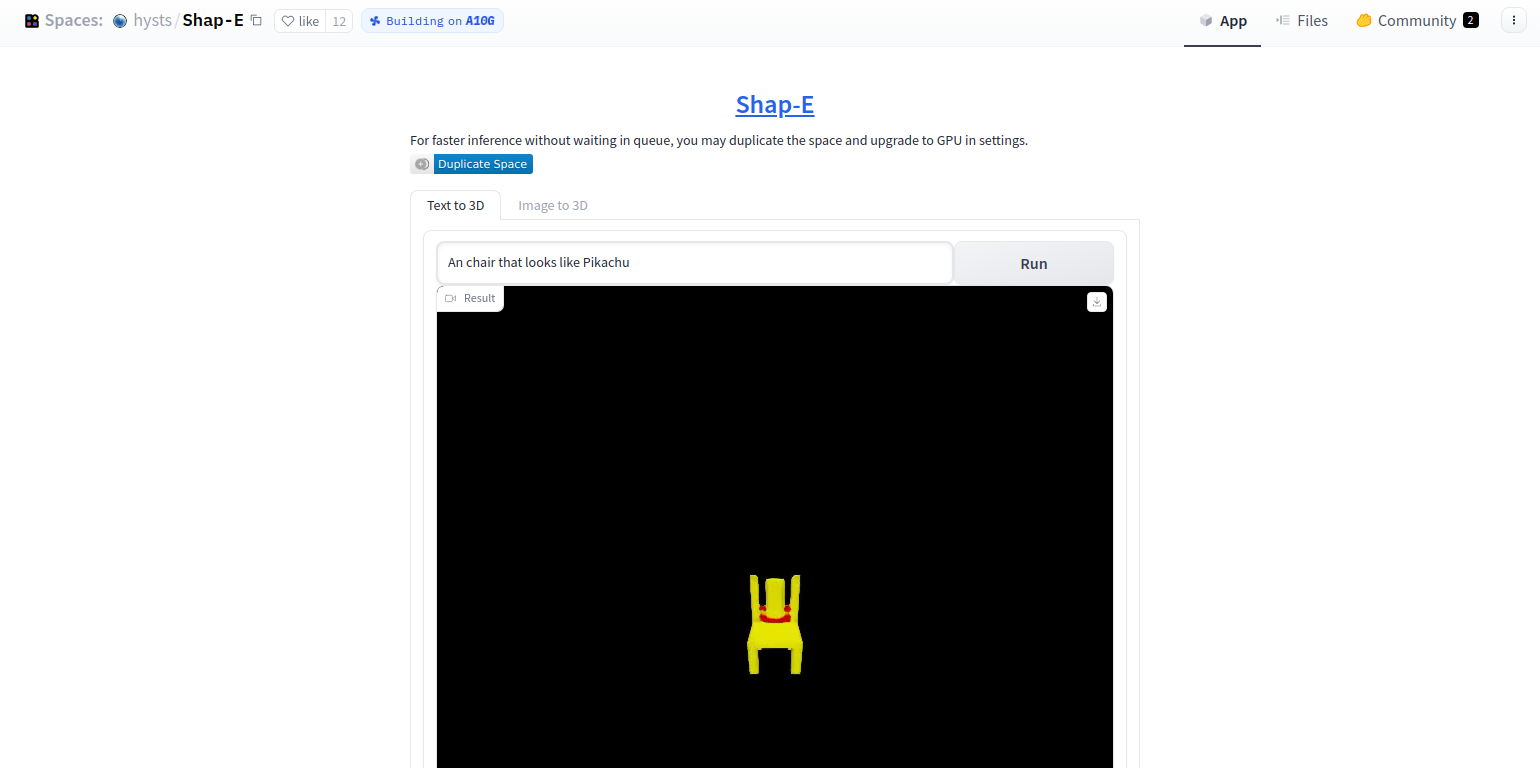
Shap-Eを簡単に使えるWebサイトを作成しております。ご活用ください
ピカチュウみたいな椅子

概要
3D アセットの条件付き生成モデルである Shap-E を紹介します。単一の出力表現を生成する 3D 生成モデルに関する最近の作業とは異なり、Shap-E は、テクスチャ メッシュとニューラル ラディアンス フィールドの両方としてレンダリングできる陰関数のパラメーターを直接生成します。Shap-E を 2 段階でトレーニングします。最初に、3D アセットを暗黙関数のパラメーターに決定論的にマッピングするエンコーダーをトレーニングします。次に、エンコーダーの出力で条件付き拡散モデルをトレーニングします。3D とテキスト データのペアの大規模なデータセットでトレーニングすると、結果として得られるモデルは、複雑で多様な 3D アセットを数秒で生成できます。点群上の明示的な生成モデルである Point-E と比較すると、Shap-E はより高速に収束し、より高次元のモデル化にもかかわらず、同等以上のサンプル品質に達します。多表現出力スペース。モデルの重み、推論コード、およびサンプルを でリリースします。
例

|

|

|
| アボカドみたいな椅子 |
ピカチュウみたいな飛行機 |
宇宙船 |

|

|

|
| お誕生日ケーキ |
木のように見える椅子 |
緑の靴 |

|

|

|
| ペンギン |
うんちソフトクリーム |
サイゼの野菜 |
使い方
pip install -e . でインストール
上記のようなモデルを生成するには、次のノートブックを参照してください。:
テキストから3Dモデルを生成する
import torch
from shap_e.diffusion.sample import sample_latents
from shap_e.diffusion.gaussian_diffusion import diffusion_from_config
from shap_e.models.download import load_model, load_config
from shap_e.util.notebooks import create_pan_cameras, decode_latent_images, gif_widget
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
xm = load_model('transmitter', device=device)
model = load_model('text300M', device=device)
diffusion = diffusion_from_config(load_config('diffusion'))
batch_size = 4
guidance_scale = 15.0
prompt = "a shark"
latents = sample_latents(
batch_size=batch_size,
model=model,
diffusion=diffusion,
guidance_scale=guidance_scale,
model_kwargs=dict(texts=[prompt] * batch_size),
progress=True,
clip_denoised=True,
use_fp16=True,
use_karras=True,
karras_steps=64,
sigma_min=1e-3,
sigma_max=160,
s_churn=0,
)
render_mode = 'nerf' # you can change this to 'stf'
size = 64 # this is the size of the renders; higher values take longer to render.
cameras = create_pan_cameras(size, device)
for i, latent in enumerate(latents):
images = decode_latent_images(xm, latent, cameras, rendering_mode=render_mode)
display(gif_widget(images))
画像から3Dモデルを生成する
import torch
from shap_e.diffusion.sample import sample_latents
from shap_e.diffusion.gaussian_diffusion import diffusion_from_config
from shap_e.models.download import load_model, load_config
from shap_e.util.notebooks import create_pan_cameras, decode_latent_images, gif_widget
from shap_e.util.image_util import load_image
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
xm = load_model('transmitter', device=device)
model = load_model('image300M', device=device)
diffusion = diffusion_from_config(load_config('diffusion'))
batch_size = 4
guidance_scale = 3.0
image = load_image("example_data/corgi.png")
latents = sample_latents(
batch_size=batch_size,
model=model,
diffusion=diffusion,
guidance_scale=guidance_scale,
model_kwargs=dict(images=[image] * batch_size),
progress=True,
clip_denoised=True,
use_fp16=True,
use_karras=True,
karras_steps=64,
sigma_min=1e-3,
sigma_max=160,
s_churn=0,
)
render_mode = 'nerf' # you can change this to 'stf' for mesh rendering
size = 64 # this is the size of the renders; higher values take longer to render.
cameras = create_pan_cameras(size, device)
for i, latent in enumerate(latents):
images = decode_latent_images(xm, latent, cameras, rendering_mode=render_mode)
display(gif_widget(images))
3Dモデルをエンコード
import torch
from shap_e.models.download import load_model
from shap_e.util.data_util import load_or_create_multimodal_batch
from shap_e.util.notebooks import create_pan_cameras, decode_latent_images, gif_widget
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
xm = load_model('transmitter', device=device)
model_path = "example_data/cactus/object.obj"
# This may take a few minutes, since it requires rendering the model twice
# in two different modes.
batch = load_or_create_multimodal_batch(
device,
model_path=model_path,
mv_light_mode="basic",
mv_image_size=256,
cache_dir="example_data/cactus/cached",
verbose=True, # this will show Blender output during renders
)
with torch.no_grad():
latent = xm.encoder.encode_to_bottleneck(batch)
render_mode = 'stf' # you can change this to 'nerf'
size = 128 # recommended that you lower resolution when using nerf
cameras = create_pan_cameras(size, device)
images = decode_latent_images(xm, latent, cameras, rendering_mode=render_mode)
display(gif_widget(images))
まとめ
時代は画像生成から3Dモデル生成になりました。ChatGPTが3Dモデルを生成する日も近いでしょう