はじめに
寝て食べて仕事が終わったら食べて寝るおっさんです。
冬眠前の正月休みにmnistを使って手書き数字認識アプリを作ってみる奮闘記です。
なぜ手書き数字認識
AIやらDXやらRPAやら、「よく分からんが便利そうだがら活用せよ」とおっさんがおっさんに「時代の波に乗り遅れるな」といわれる世の中になりました。
何から手をつけていいか分からない中、手書きの検査結果がデータ化できれば便利という流れになりました。
OCR機能を持ったソフトや装置は多々ありますが、手書き文字をサポートをしてほしいとシステムや業者の方にお願いするとムニャムニャ言いくるめられてしまうことがありました。
ある程度知識を持った人でも、認識率等の問題から自信をもっておすすめとはならないようです。
ならば、数字認識という狭い範囲のAIアプリを作ることでAI作成の基礎を学び、今後につながるヒントが得られるのではと考えました。
mnistを使う理由
Aidemyで丁寧に説明されており、おっさんでもある程度理解できたことです。
また、
MNISTデータベース(英: MNIST database, Modified National Institute of Standards and Technology databaseの略)は、さまざまな画像処理システムの学習に広く使用される手書き数字画像の大規模なデータベース[1][2]。米国商務省配下の研究所が構築したこのデータベースは、機械学習分野での学習や評価に広く用いられている[3][4]。
wikipedia
とのことで、あらかじめデータベースがなにやらすごい研究所によって作られていることで、信頼と実績が他力本願で得られるのが素晴らしいと感じたからです。
やりたいこと








こんな感じでmnistのテストデータを、AIを使って認識させ学習条件を変えたらどうなるか検証してみます。
アプリ作成の流れ
pythonでFlaskの枠組み・ひな形を構築
↓
HTML&CSSで外観を整える
↓
学習データの作成
↓
render.comを使いデプロイ
というフローをAidemyのFlask入門をベースにして作成していきます。
私の環境
Python3
Windows10
Chrome
Google Colaboratory
git
render.com
ベースアプリの公開
アイデミーで学習したデータをサンプルとして公開します。
ファイル構造
C:.
│ main.py
│ mnist.py
│ model_make.py
│ model.h5
│ Procfile
│ README.md
│ requirements.txt
│ runtime.txt
│
├─static
│ stylesheet.css
│
├─templates
│ index.html
│
├─test
│
└─uploads
model_make.py
モデル学習し、model.h5ファイルを生成します。
from keras.datasets import mnist
from keras.layers import Dense, Dropout, Flatten, Activation
from keras.layers import Conv2D, MaxPooling2D
from keras.models import Sequential, load_model
from keras.utils.np_utils import to_categorical
from keras.utils.vis_utils import plot_model
import numpy as np
import matplotlib.pyplot as plt
#モデルの保存
import os
from google.colab import files
# データのロード
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 今回は全データのうち、学習には300、テストには100個のデータを使用します。
# Convレイヤーは4次元配列を受け取ります。(バッチサイズx縦x横xチャンネル数)
# MNISTのデータはRGB画像ではなくもともと3次元のデータとなっているので予め4次元に変換します。
X_train = X_train.reshape(-1, 28, 28, 1)
X_test = X_test.reshape(-1, 28, 28, 1)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# モデルの定義
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3, 3),input_shape=(28,28,1)))
model.add(Activation('relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(10))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adadelta',
metrics=['accuracy'])
model.fit(X_train, y_train,
batch_size=128,
epochs=50,
verbose=1,
validation_data=(X_test, y_test))
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# データの可視化(検証データの先頭の10枚)
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(X_test[i].reshape((28,28)), 'gray')
plt.suptitle("10 images of test data",fontsize=20)
plt.show()
# 予測(検証データの先頭の10枚)
pred = np.argmax(model.predict(X_test[0:10]), axis=1)
print(pred)
model.summary()
#resultsディレクトリを作成
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 重みを保存
model.save(os.path.join(result_dir, 'model.h5'))
files.download( '/content/results/model.h5' )
mnist.py
アプリのアップローダーと外観を作ります。
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["0","1","2","3","4","5","6","7","8","9"]
image_size = 28
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./model.h5')#学習済みモデルをロード
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, grayscale=True, target_size=(image_size,image_size))
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "これは " + classes[predicted] + " です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
#if __name__ == "__main__":
# app.run()
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
main.py
ウェブページからアップロードした画像を受け取り、学習済みモデルで識別し、その結果を表示するコードです。
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["0","1","2","3","4","5","6","7","8","9"]
image_size = 28
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./model.h5')#学習済みモデルをロード
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, grayscale=True, target_size=(image_size,image_size))
img = image.img_to_array(img)
data = np.array([img])
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "これは " + classes[predicted] + " です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
学習データの認識精度をみてみる。
先ほど作成したmodel_make.pyを以下の条件で学習させてみる。
model.fit(X_train, y_train,
batch_size=256,
epochs=5,
verbose=1,
validation_data=(X_test, y_test))
Test loss: 0.3733743727207184
Test accuracy: 0.9085000157356262
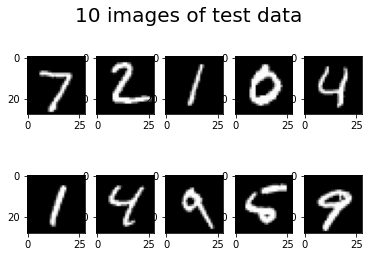
1/1 [==============================] - 0s 55ms/step
[7 2 1 0 4 1 4 9 5 9]
Model: "sequential_3"
認識率9割越え。優秀。
もっと精度を上げてみる。
精度を上げるために
model_make.pyを強化します。
以下のモデルを触って向上をめざします。
・batch_size → 下げる
一度に複数のデータを渡した場合、モデルはデータごとに損失関数の値と損失関数の 勾配 を計算し、それぞれのデータの勾配の平均値をもとに1度だけ重みの更新をするものです。
大きな重みの更新が発生しにくくなり、一部のデータに最適化されてしまい、全体のデータへの最適化が行われなくなる状態(局所解)から抜け出せなくなる可能性もあります。
それを回避するためには、イレギュラーなデータが多い時には バッチサイズを大きくする、少ないときには バッチサイズを小さくする といったように、バッチサイズを調整します。
今回はtestファイルを使用するので、イレギュラーが少ないと判断し、値を下げる方向性でトライします。
・epochs → 上げる
学習の回数をエポック数といいます。増やしすぎると過学習の恐れがあります。
今回は回数を過学習が起こらない程度に徐々に増やします。
・Dense → 上げる
カーネル(畳み込みに使用する重み行列)の大きさを指定します。
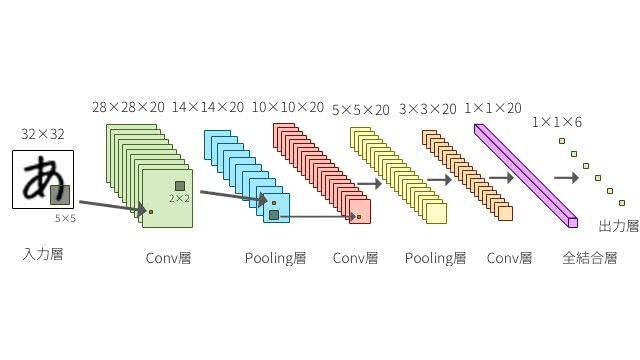
DeepAge
今回はアラビア数字で余白部分が多く、上げることで精度が上がると推測しました。
# モデルの定義
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(3, 3),input_shape=(28,28,1)))
model.add(Activation('relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256)) #128→256
model.add(Activation('relu'))
model.add(Dropout(0.2)) #0.5→0.2
model.add(Dense(10))
model.add(Activation('softmax'))
model.fit(X_train, y_train,
batch_size=64, #128→64
epochs=100, #50→100
verbose=1,
validation_data=(X_test, y_test))
Test loss: 0.06637744605541229
Test accuracy: 0.9796000123023987
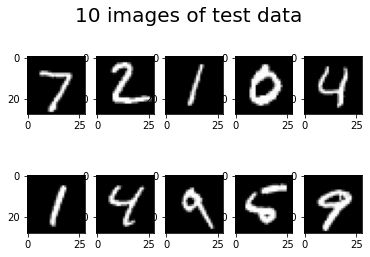
1/1 [==============================] - 0s 116ms/step
[7 2 1 0 4 1 4 9 5 9]
Model: "sequential"
dense (Dense) (None, 256) 2359552
精度アップに成功しました![]()
ひっそりと公開
まとめと課題
- 手書き数字の認識アプリをrender.comにデプロイできました。
- 学習回数等のパラメーターを変えることで、結果に変化がみられました。
- 今回はmnistのテストデータを使って判別させましたが、自分で書いた文字でも良く判別できるものを作成すればより実践的なアプリになるので、挑戦したいです。