概要
機械学習モデルを作成するときに欠かせないの手順の一つがハイパーパラメータの最適化です。
ハイパーパラメータの最適化は、モデル作成時に設定したパラメータやその時のスコア、データセットは何を使ったのか、などの実験を管理するコストが発生します。
Excelなどで管理する場合もありますが、Hydra, MLFlow, Optuna, Gitなどを組み合わせて行うケースが多いと思います。
しかし、それぞれのツールのセットアップやバージョン管理、コードのメンテナンスが発生して、本来の目的の課題を解決するためのモデルを開発することではなく、管理に工数を取られてしまうと時間が無駄になってしまいます。
そこで、VARISTAを使ったハイパーパラメータのチューニング方法と、機械学習モデル作成の実験管理をご紹介します。
VARISTAはSaaS型のノーコード機械学習プラットフォームです。VARISTAはこちら
無料でも多くの機能を使うことができます。
本記事の流れ
- データの用意
- モデル作成(固定値のハイパーパラメータで学習)
- モデル作成(OptunaでHyperParameterを探索してモデル作成)
- モデル作成(OptunaでHyperParameterの探索範囲を広めてモデル作成)
- 作成したモデル比較
データの用意
今回使うデータセットはKaggleにて公開されている「IBM HR Analytics Employee Attrition & Performance」で、社員の離職につながる要因を探ることを目的に作られたデータです。
(IBMのデータサイエンティストが作成した架空のデータセットです。)
IBM HR Analytics Employee Attrition & Performance
なお、本記事はパラメータチューニングの手順紹介にフォーカスするため、特徴量エンジニアリングなどは行わずオリジナルのデータセットでモデルを作成します。
初めてVARISTAを使う方は、以下を参考にプロジェクトを作成後、データアップロードまで終えてください。
ドキュメント › プロジェクトの作成
データセットは、1470インスタンス、34の説明変数で構成されています。
目的変数は Attrition (退職)です。

モデルの作成
まずは、パラメータチューニングをしないでLightGBMを使いモデルを作成してみましょう。
VARISTAではモデルを作成するときにテンプレートを使用しますので、以下の手順で学習テンプレートを作成して編集します。
学習テンプレートの複製と編集
今回は、LightGBMを使いパラメータチューニングを行いますので、LightGBMを使用するテンプレートを作成します。
モデリング › テンプレート(タブ)へと移動し、XGBoost Classifierを 複製 します。

複製されたテンプレートは、カスタムテンプレートセクションにありますので、選択して詳細を確認します。

続いて、設定を以下の通りに変更します。
- 基本設定 › 検証データの分割設定 › 分割サイズ : 0.2
- モデル設定 › 交差検証設定 › n_splits : 5
- アルゴリズム: LightGBM Classifier
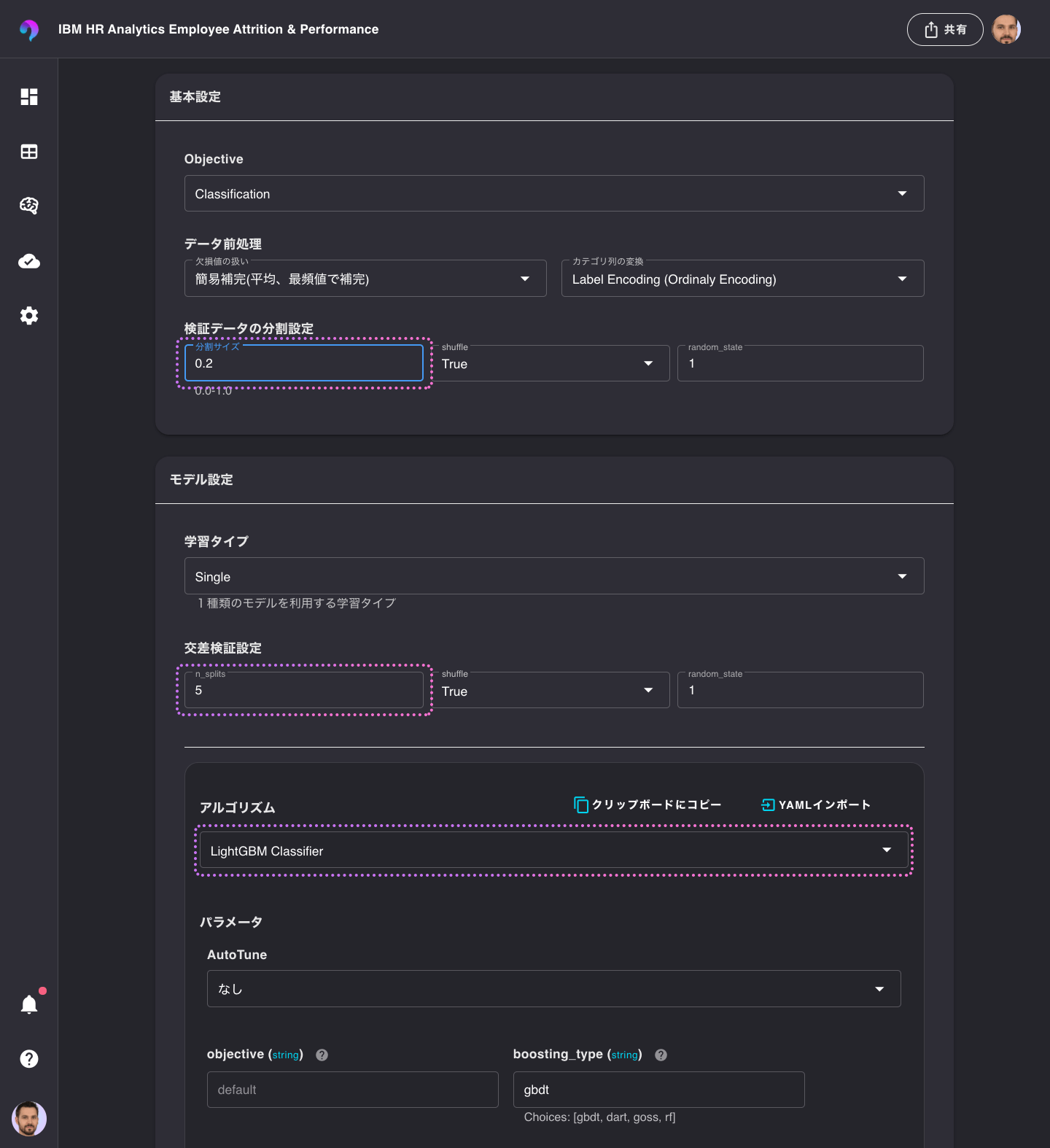
最後にテンプレートを保存します。名前は__LightGBM Classifier__にします。

モデルの作成
先ほど作成したLightGBM Classifierを使いモデルを作成してみましょう。
モデリング › モデル(タブ)へと移動し、新規モデルを選択します。

続いて、アップロードしたデータを選択し、ターゲットがAttritionに、テンプレートにLightGBM Classifierを選択して、作成を選択します。

学習は10秒程度で完了し、モデルリストに作成されたモデルが表示されています。

モデルをクリックしてメトリクスを確認します。

今回は、F1スコアを基準にしてパラメータチューニングを行ってみます。
Optunaを使用したハイパーパラメータの最適化
では、ここからOptunaを使いハイパーパラメータの最適化を行ってみます。
以下の手順で、Optuna用の学習テンプレートを作成します。
Optuna用に学習テンプレートの複製と編集
先ほどと同様の操作で、LightGBM Classifierのテンプレートを複製します。
複製されたテンプレートを選択して編集します。
変更するテンプレートの値は以下の通りとし、その他の設定はデフォルトのまま行います。
- パラメータ › AutoTune: TPE Optimization with Optuna
パラメータチューニングにOptunaを使用します。 - パラメータ › AutoTune Round: 10
パラメータチューニングの試行回数を10回に設定します。 - パラメータ › AutoTune Scoring: f1
各試行において、クロスバリデーションを行う際のメトリクスを指定します。 - パラメータ › AutoTune CV Settings n_splits: 5
各試行において、クロスバリデーションを行う際の分割数を指定します - パラメータ › num_leaves: 256, 512
LightGBMのLeavesの探索範囲を設定します。

テンプレート名はLightGBM Optuna Classifierとします。

Optunaを使ったモデルの作成
先ほどのモデル作成の手順と同様に、モデルタブから新規モデルを選択します。
今度はテンプレートをLightGBM Optuna Classifierに設定して学習を開始します。
モデルの確認
パラメータ探索の試行回数を少なく設定したので、十数秒で学習が完了してモデルが生成されます。
F1スコアを確認するとスコアが改善されていることがみて取れます。

パラメータチューニング履歴の確認
実際に、試行したハイパーパラメータを確認してみたいと思います。
モデルをクリックして、アルゴリズムタブを選択します。

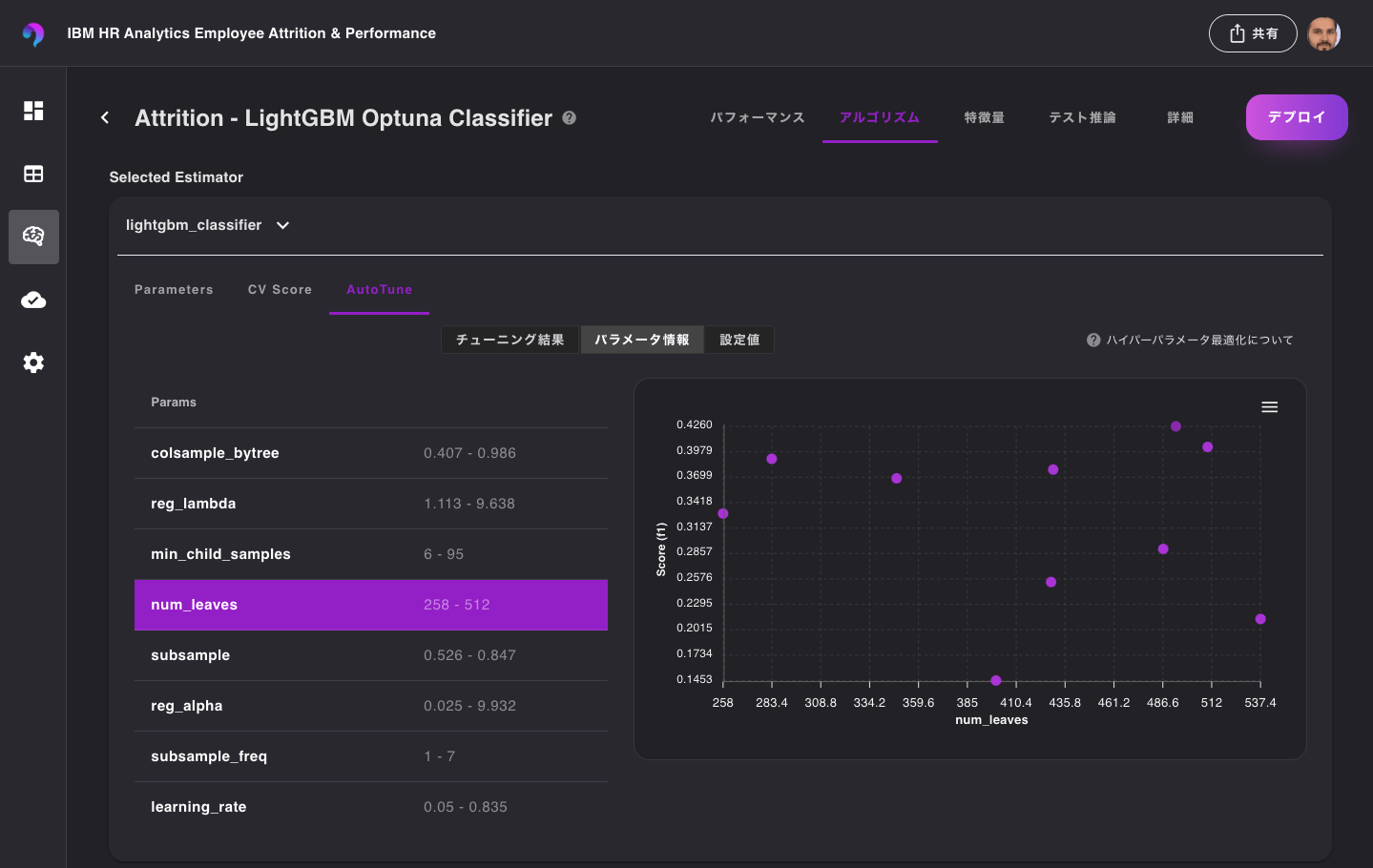
Selected Estimatorセクションにある、lightgbm_classifierを選択すると、学習の履歴を確認することができますので、さらにAutoTuneタブを選択します。
この情報から、10回試行をし7回目でf1スコアが最も高くなるようなハイパーパラメータを見つけることができたことがわかります。
また、それぞれのハイパーパラメータを探索した範囲ごとのスコアも パラメータ情報 から確認することができます。
試行回数と探索範囲を変更
次に、テンプレートの値を変更して再度モデルを作成してみましょう。
今回もテンプレートを複製してから変更します。
以下のように、試行回数と探索範囲を変更してみます。
- AutoTune rounds: 700
- num_leaves: 32, 1024
- n_estimators: 256
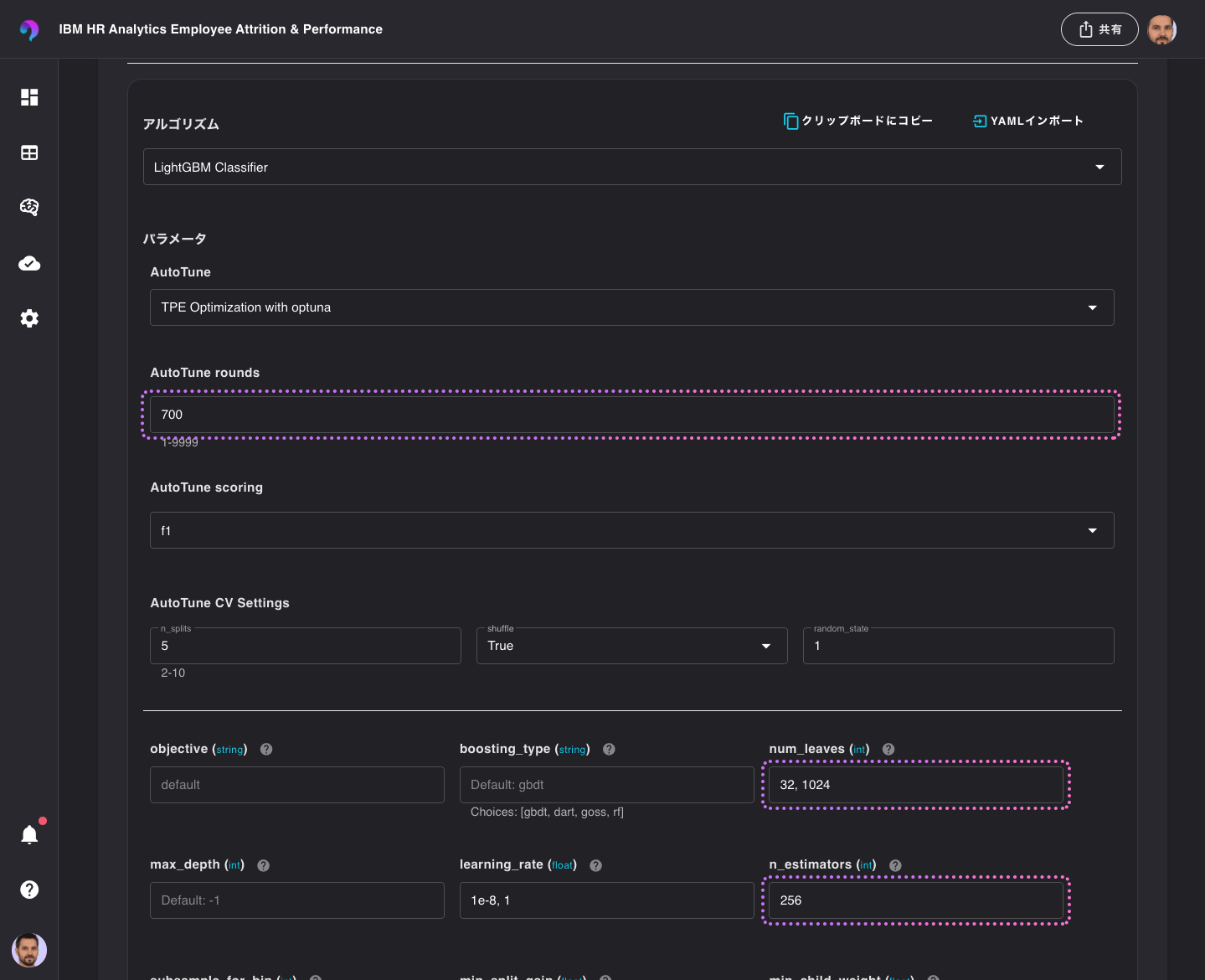
テンプレート名は、LightGBM Optuna Classifier Rev2などと名前をつけて保存し、このテンプレートを使い、モデルを作成します。
モデルの確認
出来上がったモデルを確認すると、F1スコアが改善されていることが確認できます。
これは、先程の探索範囲では見つけることができなかったより良いパラメータを見つることができたためです。

また、最適化の履歴を参照すると、510回目の試行でスコアが高くなるハイパーパラメータの組み合わせを発見したことを確認することができます。
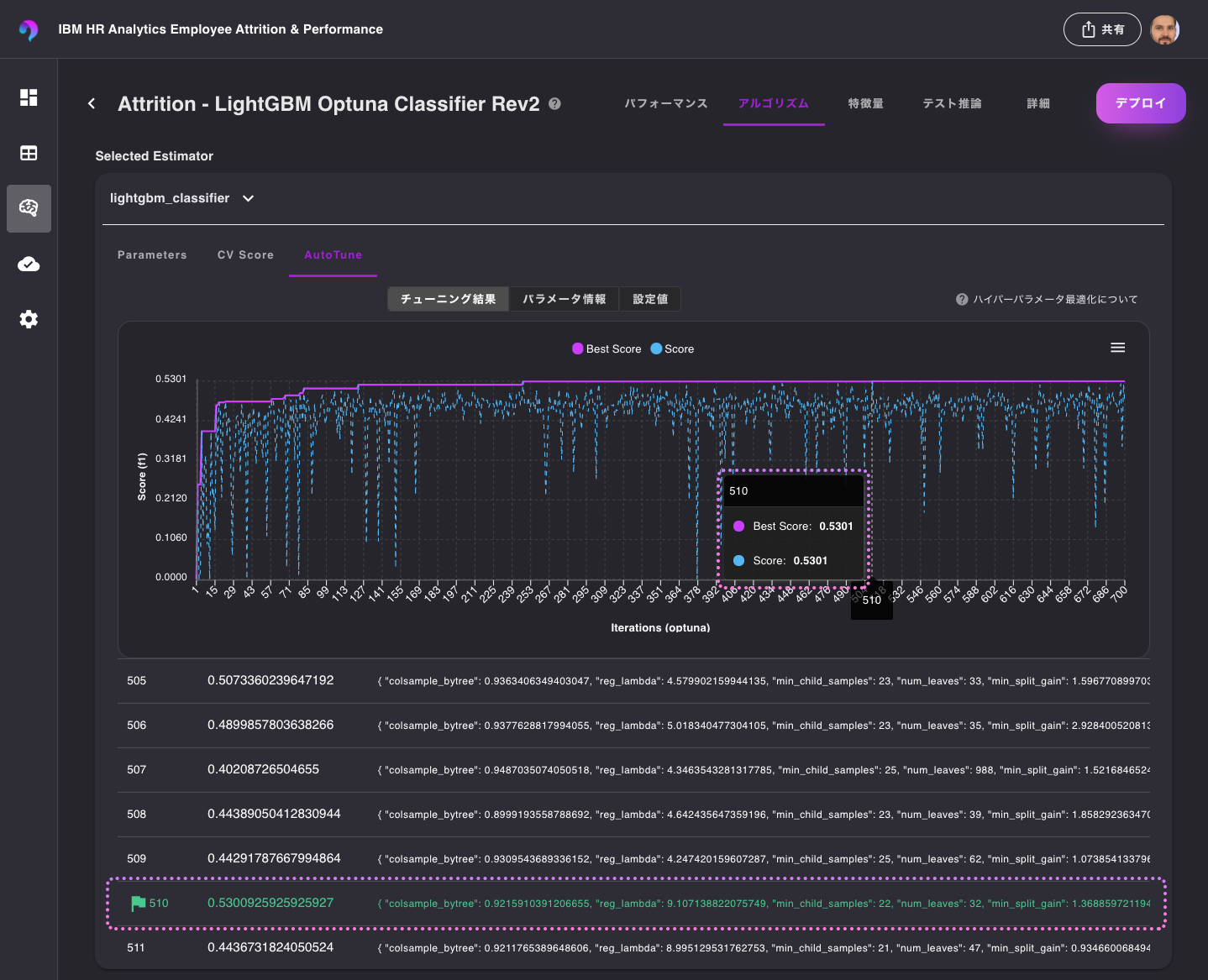
モデル比較
ここまで作成した複数モデルを比較してみたいと思います。
作成したモデルを選択し、モデル比較 をクリックします。
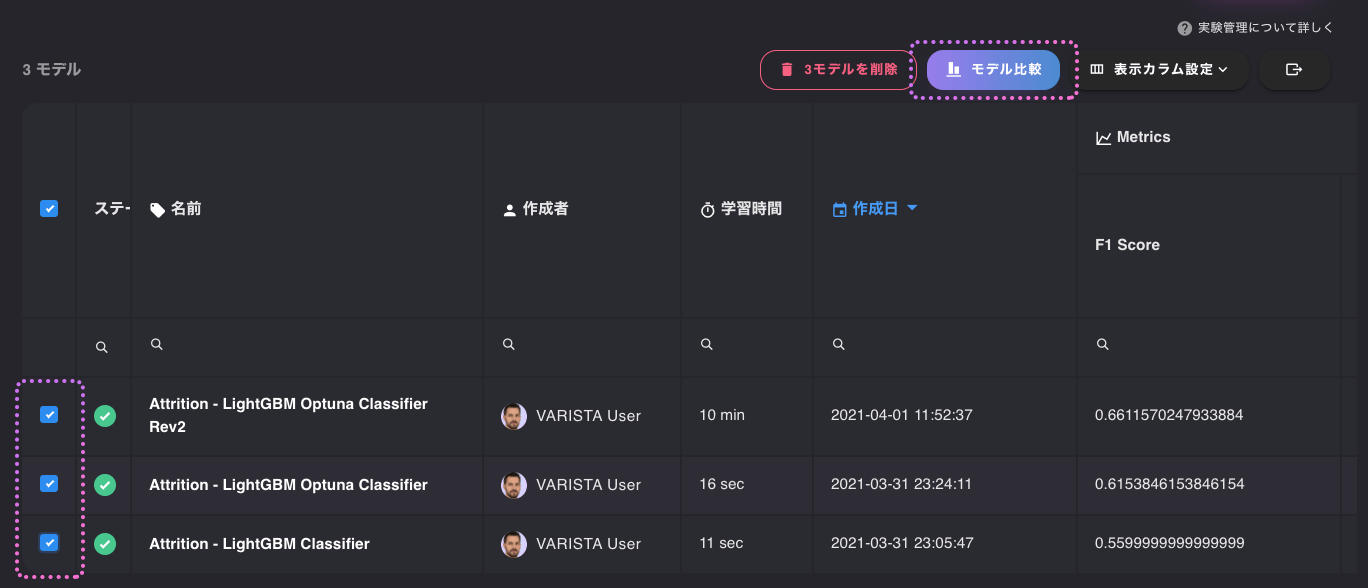
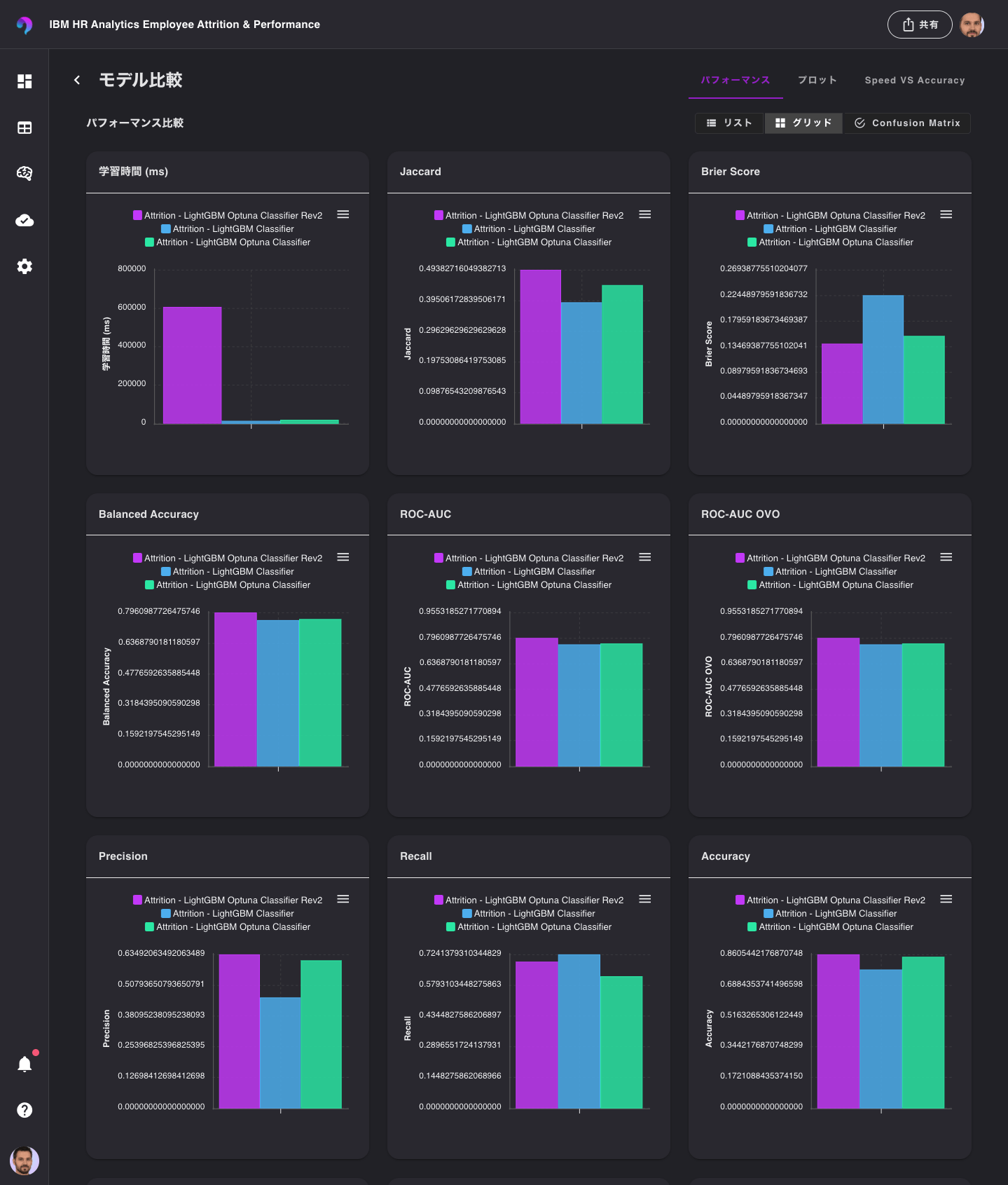
続いて、「グリッド」を選択します。
この表示では、比較対象のモデルの各指標を俯瞰して確認することができます。
F1, Balanced Accuracy, ROC-AUC, Accuracyなどを確認してみると、Rev2モデルは他のモデルよりもスコアがいいようです。
次に、混同行列を確認するために、Confusion Matrixを選択します。
クロスバリデーションの結果をモデルごとに比較することができます。

プロットタブを選択すると、それぞれのモデルのPR曲線や、ROC曲線を確認することができます。

Speed VS Accuracyタブは、推論速度と精度を比較することができますので、性能よりも速度を優先したい場合、またはその逆を優先したい場合など、ビジネス要件に応じてモデルを選択したい場合に役立ちます。

まとめ
VARISTAでOptunaとLightGBMを組み合わせてハイパーパラメータの最適化を行い、モデルを比較する流れをご紹介しました。
通常であれば複数のツールのセットアップや環境のメンテナンスが必要ですが、VARISTAを使うことでこれらの工数を削減することができます。
VARISTAはこちらから試せます。