モデルのパフォーマンスにはデータだけではなく、ハイパーパラメータも影響します。
XGBoostやLightGBM,CatBoostなどの複雑なモデルは、その性能を最大限に活用するために、ハイパーパラメータを正しく調整する必要があります。
昨今ではVARISTAでもサポートしているOptunaやHyperoptなどの最適化ツールやAutoMLの登場により、自動でパラメータチューニングを行う事も可能になりました。
*Optunaを使った自動チューニングはこちらの記事を参考にしてください。
VARISTAでのハイパーパラメータの最適化と実験管理 Optuna編
しかし、AutoMLなどが生成したモデルはパラメータを探索しきれていないケースもあり、データサイエンティストが手動で微調整すると更に優れたモデルになることもあります。
そこで、今回は過学習したモデルを例に、ハイパーパラメターのチューニングをVARISTAで行う方法を解説します。
今回利用するデータセットには、7000行、21の説明変数、および目的変数が含まれています。

ターゲットは数値のため、回帰タスクになります。
この記事の目的はハイパーパラメータチューニングですので、データの前処理などは割愛します。
まずは、VARISTAに用意されているデフォルトのテンプレートをXGBoostからLightGBMに変更し、そのままのハイパーパラメータで学習します。
学習は20秒程度で完了しますので、結果を確認してみます。
複数のメトリクスが表示されていますが、今回はRMSEを基準にして進めます。
以下に表示されているのは、教師データをFold=3でクロスバリデーションを行った際の、学習時と検証時のRMSEです。
- train_neg_root_mean_squared_error: 学習時のRMSE
- test_neg_root_mean_squared_error: 検証時のRMSE
*VARISTAではscikit-learnのクロスバリデーションを利用するため、RMSEはNegativeの値となります。
3.3. Metrics and scoring: quantifying the quality of predictions
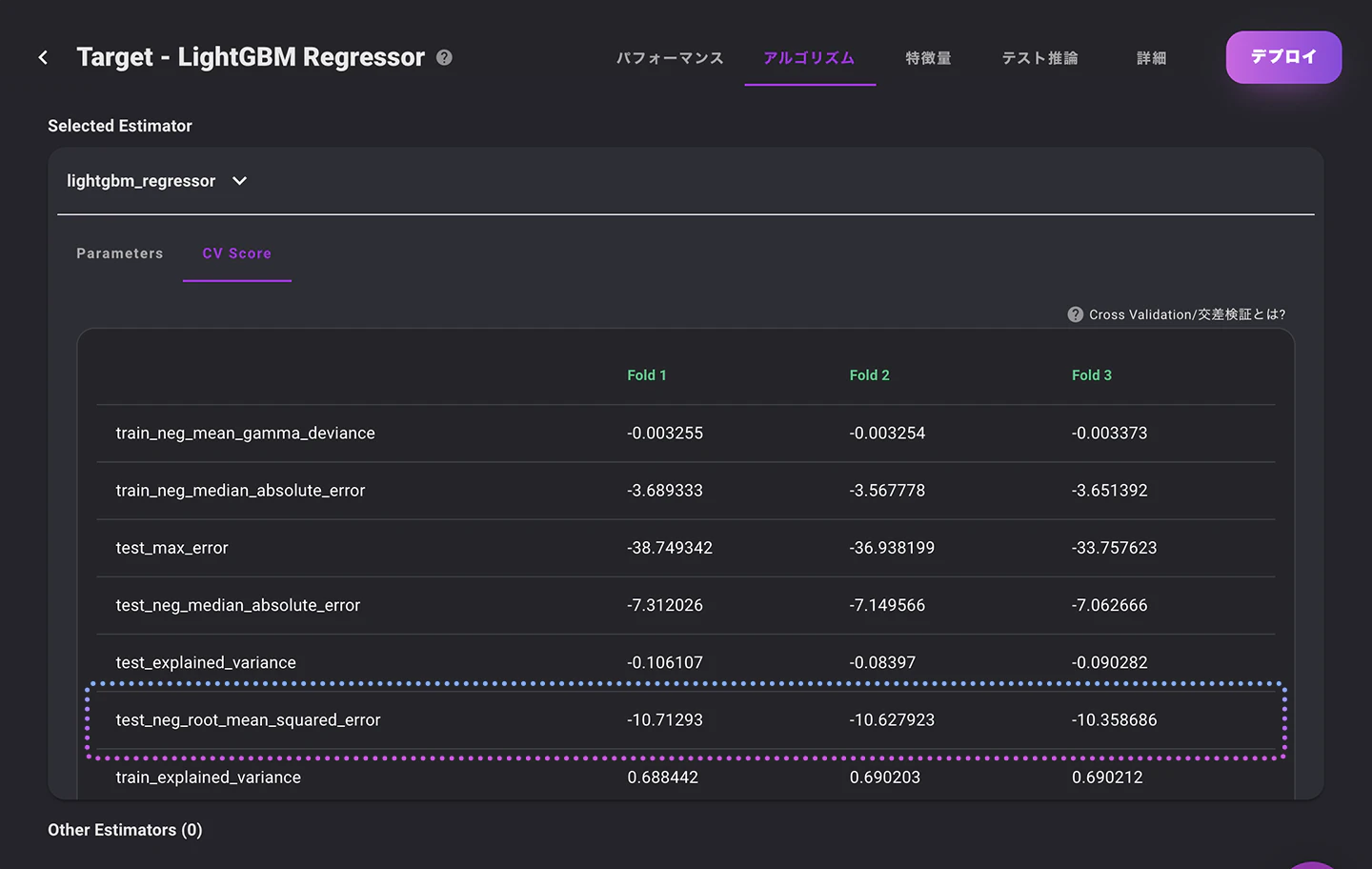
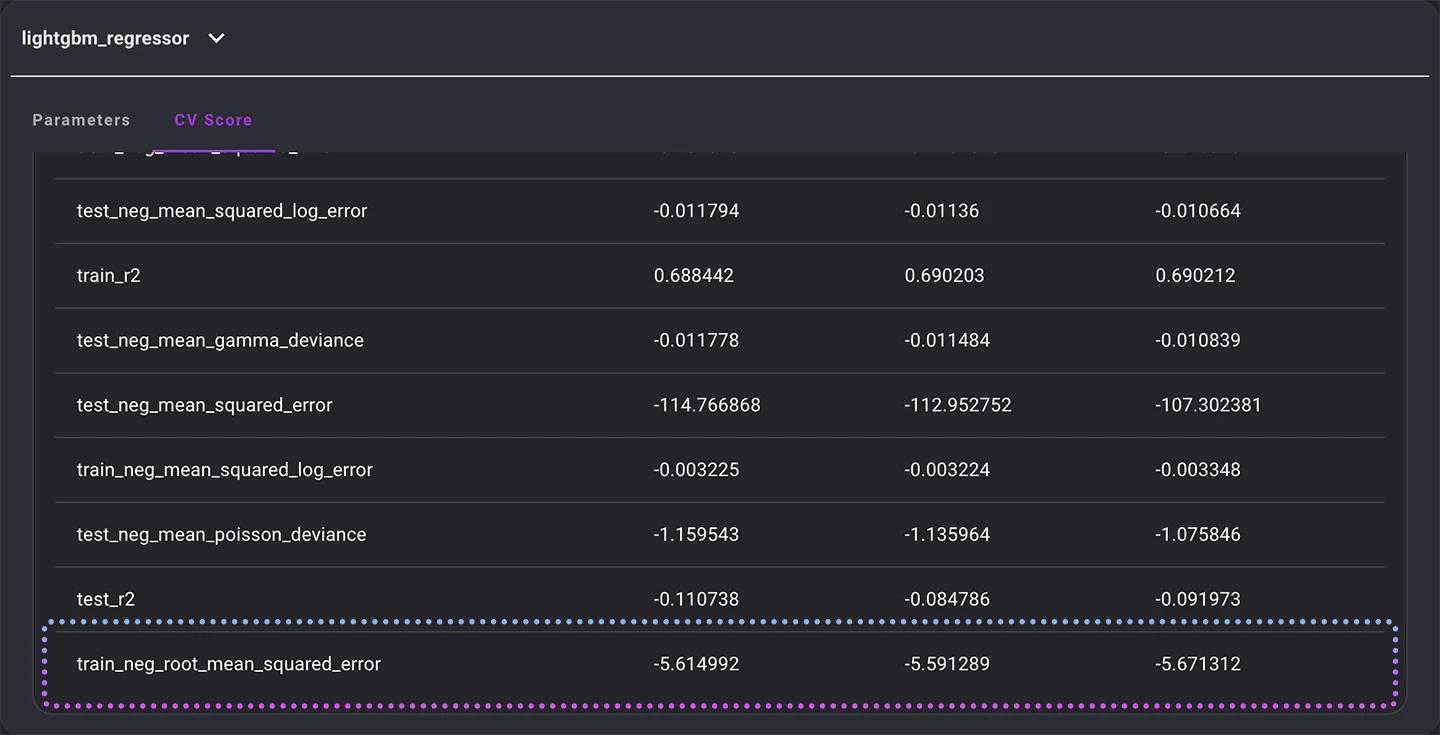
比較しやすいように今回着目するメトリクスを以下に抽出しました。


学習時と検証時のRMSEはおよそ-5の差がありますので、出来上がったモデルは学習データに適合してしまっています。つまり過学習の状態です。
それでは、この状態からハイパーパラメータを調整してモデルの性能を改善していきます。
まず、min_data_in_leafを変更して、過学習を抑制する方法を試してみます。
min_data_in_leafは、決定木の葉の最小データ数を指定します。
値を大きくすると、決定木が深く育つのを抑えるため過学習を防ぐことができますが、逆に未学習となる場合もあります。
モデルが適合しすぎないように、各リーフのデータ数を調整します。
今回は、この値を100に変更して学習してみます。
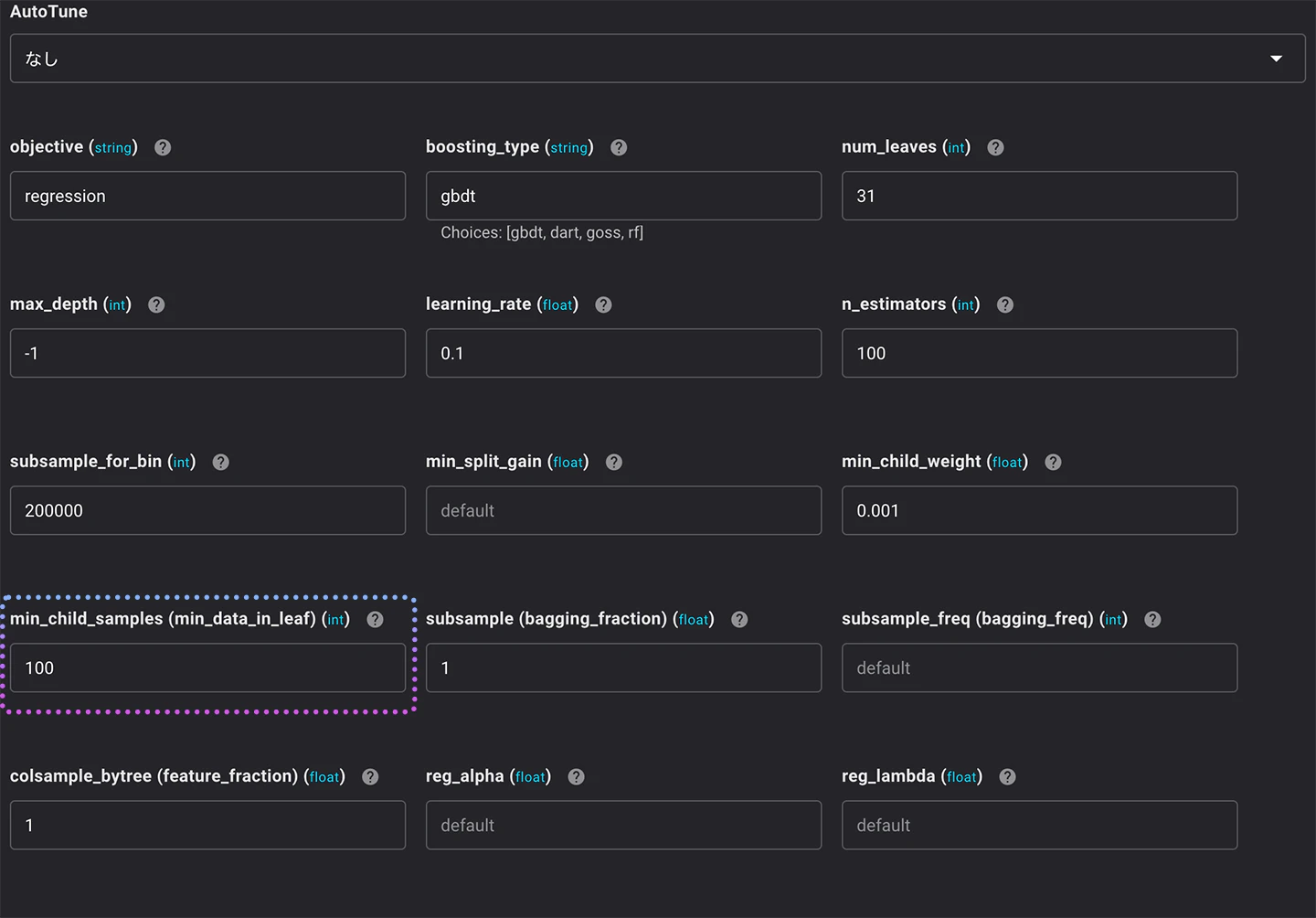
この状態で出来上がったモデルを確認してみます。


検証のRMSEは同じですが、学習のRMSE値が下がり検証の値に近くなりました。
これは、先程の結果よりも過学習を抑制できたことを意味します。
モデルが適合しすぎないようにするもう1つのパラメーターは、イテレーションごとにランダムに選択される特徴量の比率を調整するfeature_fractionです。
このfeature_fractionの値を0.8に変更してモデルを作成してみます。
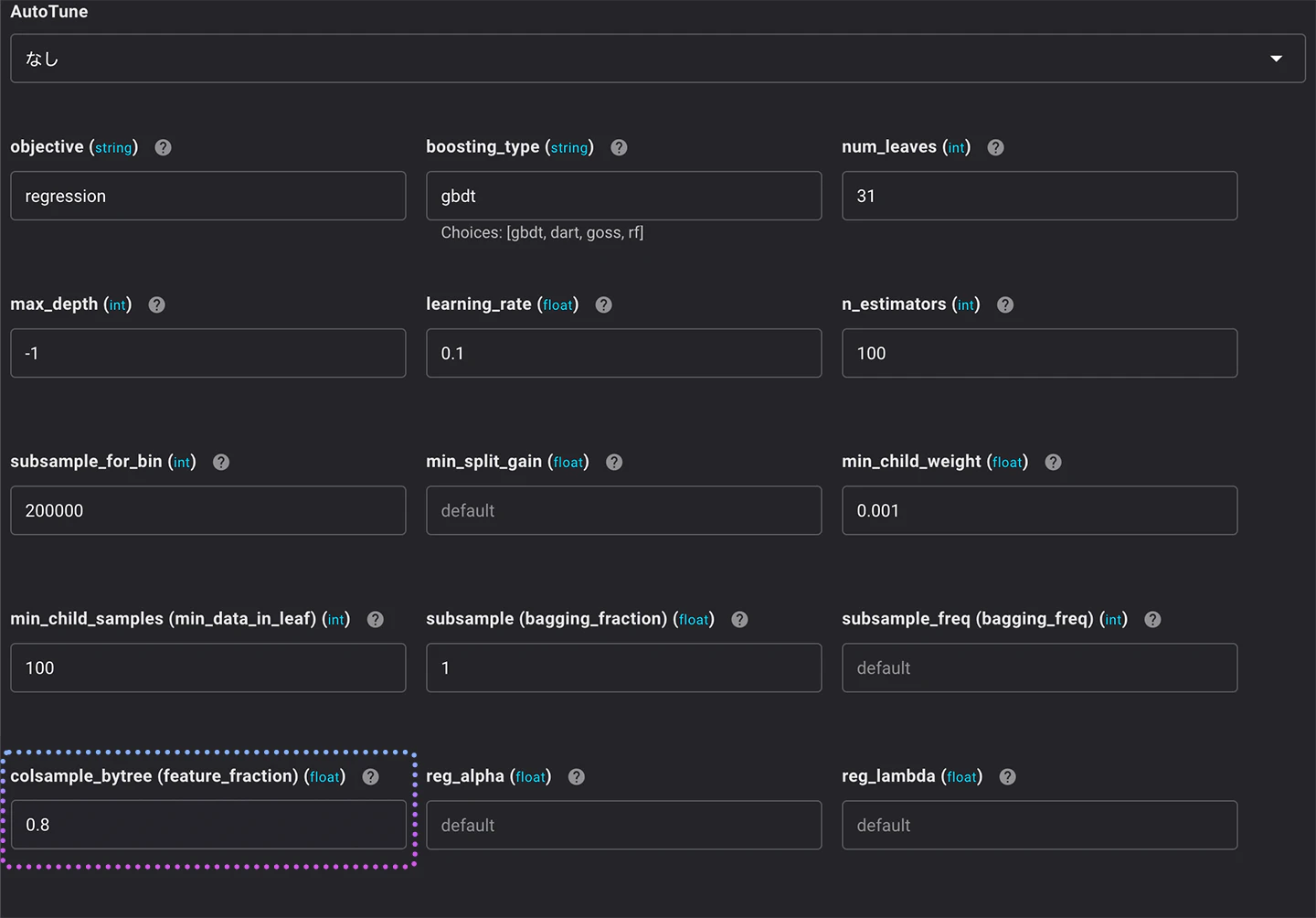
この値にパラメータを設定すると、モデルは各イテレーションで特徴量を80%ほど使用します。
結果は以下のとおりです。


学習のRMSE値が更に改善されました。
次は、bagging_fractionとbagging_freqの値を調整します。
bagging_fractionは、学習データからランダムに行をサンプリングして、各イテレーションで使用する割合を指定します。feature_fractionに似ていますが、bagging_fractionは行に対して行います。bagging_freqは、サンプリングした行を更新する頻度を調整する際に設定するパラメータです。
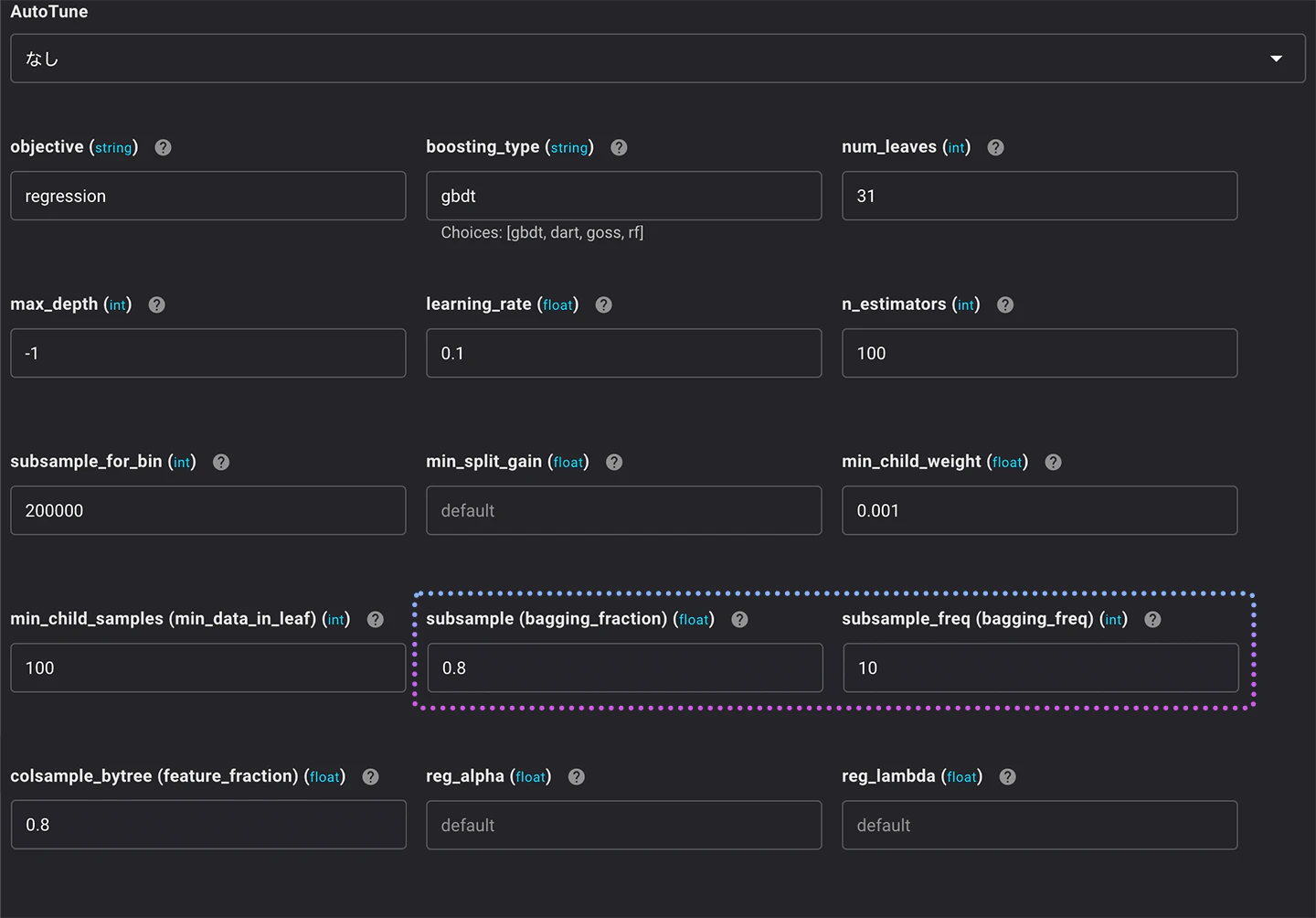
- bagging_fraction:0.8
- bagging_freq:10


学習のRMSEと検証のRMSEの差はさらに減少しました。
次に調整するパラメータは、max_depth, num_leaves, learning_lateです。
LightGBMは、ブースティング手法を用いて決定木を組み合わせ、アンサンブル学習を使うアルゴリズムです。ですので、個々のツリーの複雑さも過学習の原因になります。
ツリーの複雑さは、max_depthとnum_leavesで調整します。max_depthはツリーの最大深度を調整し、num_leavesはツリーが持つことができるリーフの最大数を調整します。
LightGBMでは、このmax_depthとnum_leavesの2つのパラメーターは一緒に調整します。
最後に、learning_rateです。一般的に、学習率は小さいほどパフォーマンスはよくなりますが、モデルの学習が遅くなりますので、データ量やマシンスペックを考慮して設定します。
今回の場合は、データ数もあまり多くないので0.001に設定しています。
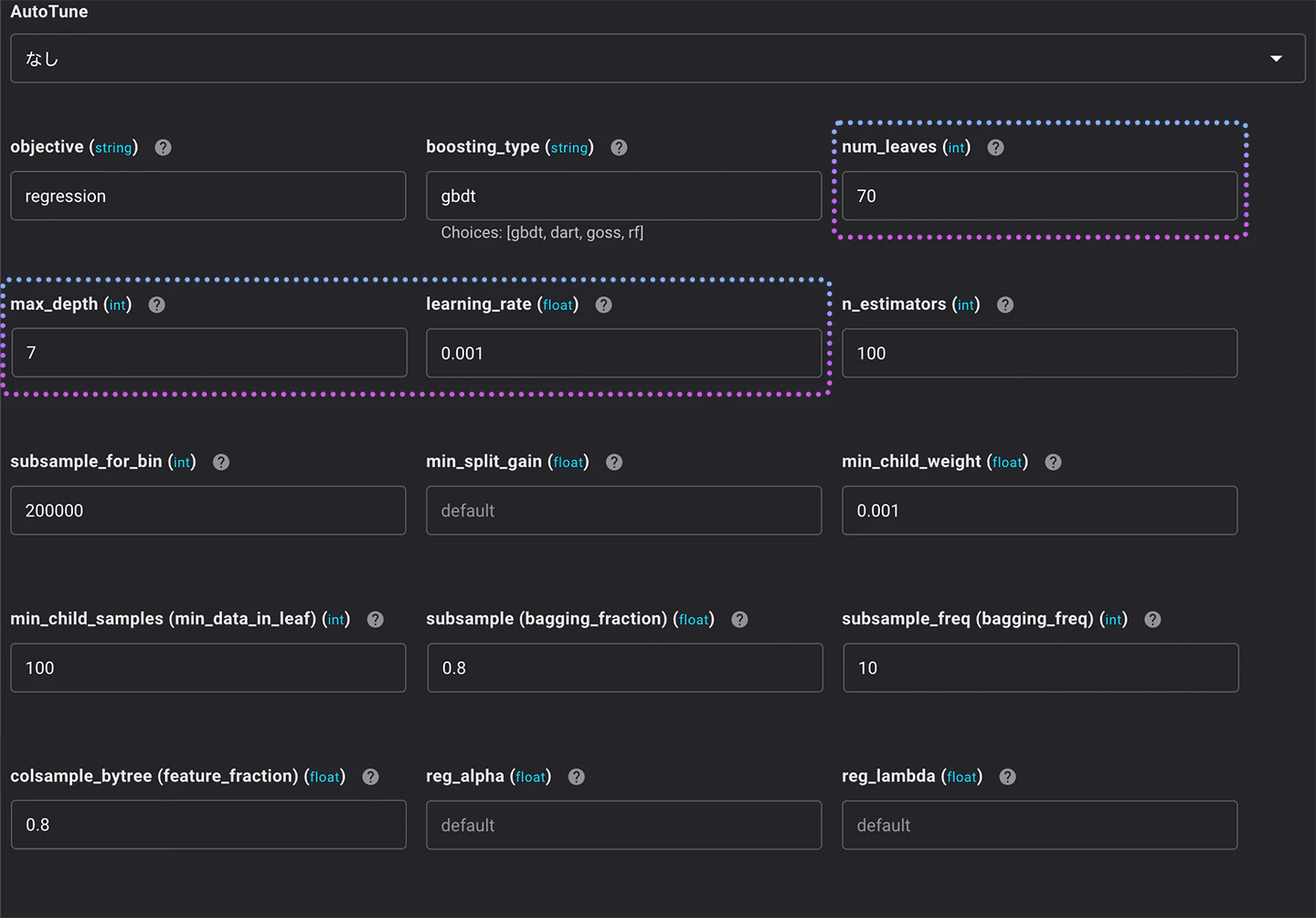
- max_depth:7
- num_leaves:70
- learning_rate:0.001


学習のRMSEと検証のRMSEの差はさらに減少しました。
このように、ハイパーパラメータを調整することで、モデルの過学習を防ぐことができます。
しかし、そもそものモデルのパフォーマンスが目標とする値に全く達していない場合は、ハイパーパラメータの調整では限界があります。
そのような場合は、まずはデータの量や質を見直して特徴量エンジニアリングなどを行い、モデルのパフォーマンスが目標値に近くなってきたらハイパーパラメータのチューニングを行う方が効果的です。