はじめに
GoogleColabとは、Googleが無償でGPUやTPUまで提供する機械学習向けのプラットホームです。
みんなが大好きなjupyter notebookを利用しているため、とっつきやすく贅沢な環境で実装することが可能です。
もう一度言いますが無料です、すごい!!!
今回やること
- kaggleのTitanicコンペをデータの取得から提出までGoogle Colab上で行う
- 予測モデルはXGboostを利用
やり方
下準備
GoogleColab上でKaggleデータを扱うために必要となるのが、KaggleのAPIを作成する必要があります。
Kaggleサイトの、右上自分のアイコンをクリック -> My Account -> APIの項目の"Create New API Token"をクリックします。
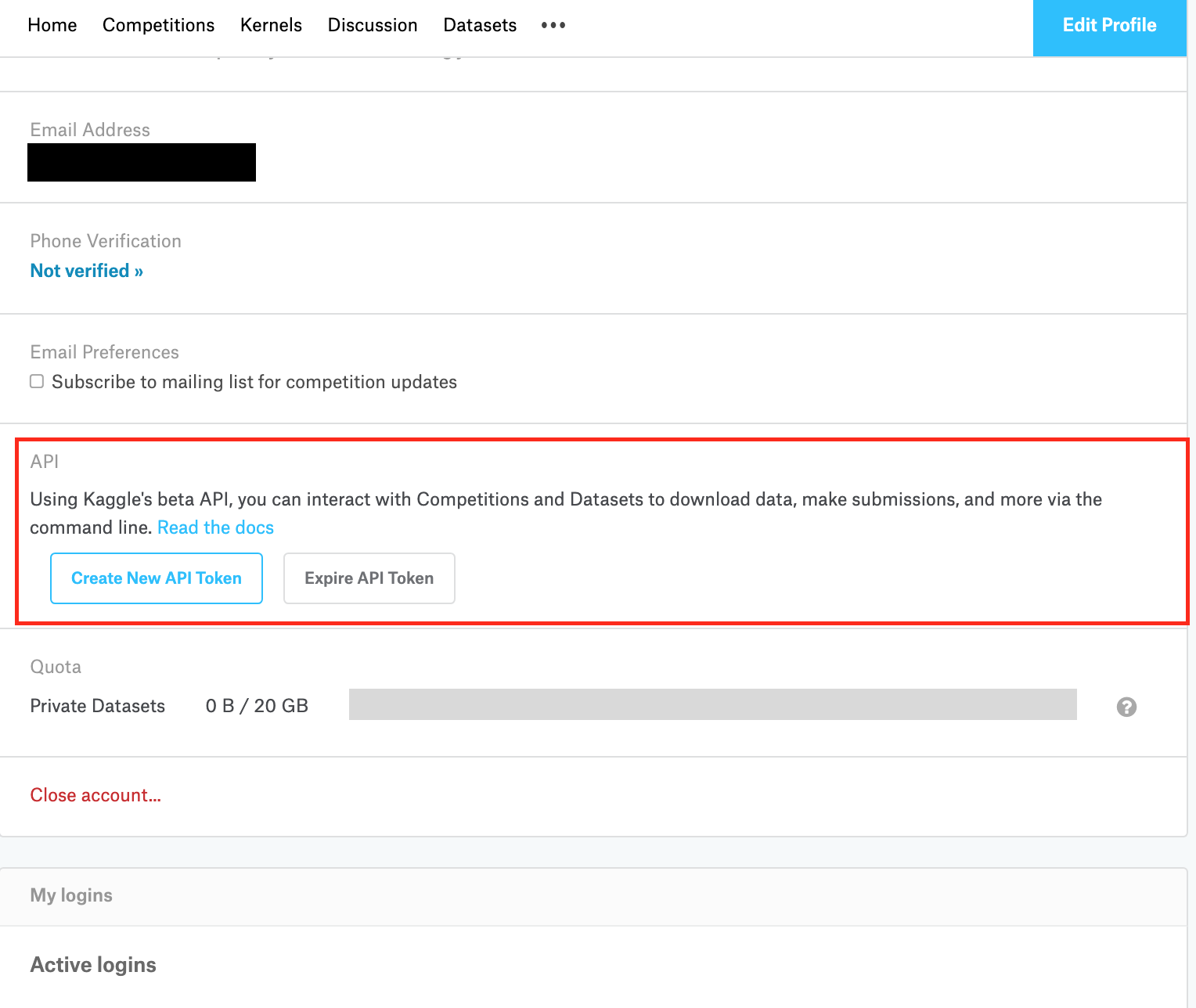
すると、kaggle.jsonというファイルががダウンロードできるので、一旦ダウンロードします。
このファイルを、GoogleColab上/contentへアップロードしておきます。
そして、Colabで新しいノートを開き、編集>ノートブックの設定を開き、GPUを選択しましょう。
これで、Google Colab上でGPUを走らせることができます。
ここからが本番
Google Colabに以下のコードを記述し、実行して下さい。
# ドライブのファイルを読み書きするためのライブラリ
import google.colab
import googleapiclient.discovery
import googleapiclient.http
google.colab.auth.authenticate_user()
drive_service = googleapiclient.discovery.build('drive','v3')
# AUTH認証が必要
# 先程のkaggle.jsonを読み込む
from google.colab import files
!more kaggle.json
# kaggle.jsonをアップロードする
!mkdir -p ~/.kaggle
!cp kaggle.json ~/.kaggle/
!pip install kaggle
!chmod 600 /root/.kaggle/kaggle.json
# kaggle APIキーを打ち込む(コンペごとに異なる)
!kaggle competitions download -c titanic
# ディレクトリinputを作成
!mkdir input
# ファイルの移動
!mv train.csv input
!mv test.csv input
以上でkaggleからGoogleColabへのデータを取得が完了します。
ここからはデータの前処理とモデルの構築を行います。
※今回の記事の目的がGoogleClab上でのsubmitのため、データの可視化や特徴量エンジニアリングなどは割愛します
# 基本ライブラリのインポート
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
train_path = './input/train.csv'
test_path = './input/test.csv'
df_train = pd.read_csv(train_path , encoding = 'utf-8')
df_test = pd.read_csv(test_path , encoding = 'utf-8')
df_source = pd.concat([df_train, df_test])
print('df_train:',df_train.shape)
print('df_test:',df_test.shape)
# 特徴量の絞り込み
df_source = df_source[['Survived', 'Pclass', 'Sex', 'Age', 'SibSp',
'Parch', 'Fare', 'Cabin', 'Embarked']]
# ダミー変数の取得
df_source = pd.get_dummies(df_source,drop_first=True)
# 訓練データと提出用データの分割
df_train = df_source[:len(df_train)]
df_sub = df_source[len(df_train):]
target_column_name = 'Survived'
# 訓練用データの分割
from sklearn.model_selection import train_test_split
## trainとtestデータのデフォルト数が均等に成るように設定
df_train , df_test = train_test_split(df_train ,test_size = 0.2, stratify=df_train[target_column_name],random_state = 0)
# 不必要なcolumnを削除
X_train = df_train.drop(df_train.select_dtypes(include = object),axis = 1)
X_train = df_train.drop(target_column_name,axis = 1)
y_train = df_train[target_column_name]
X_test = df_test.drop(df_test.select_dtypes(include = object),axis = 1)
X_test = df_test.drop(target_column_name,axis = 1)
y_test = df_test[target_column_name]
# 提出用ファイルも同様に処理
df_sub = df_sub.drop(df_sub.select_dtypes(include = object),axis = 1)
df_sub = df_sub.drop(target_column_name,axis = 1)
"""# XGBoost"""
import xgboost as xgb
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
from sklearn.metrics import (roc_curve, auc, accuracy_score)
print('\n# Survived rate')
print('train: size:{} ,default {} , rate {:f}'.format(
y_train.size,
np.count_nonzero(y_train),
np.count_nonzero(y_train) / y_train.size))
print('test : size: {} , default {}, rate {:f}'.format(
y_test.size,
np.count_nonzero(y_test),
np.count_nonzero(y_test) / y_test.size))
weight = df_source.shape[0] / np.count_nonzero(df_source[target_column_name])
# Grid Search
parameters = {'max_depth': [3, 4, 5, 6,7],
'min_child_weight': [0.5, 0.8, 1, 2, 3],
'n_estimators': [50, 100, 200, 300, 500],
'subsample': [0.8, 0.95, 1],
'colsample_bytree': [1.0],
}
clf_xgb = GridSearchCV(xgb.XGBClassifier(random_state = 0), parameters,scoring ='accuracy',cv =2 ,n_jobs = -1)
clf_xgb = clf_xgb.fit(X_train ,y_train)
pred_xgb = clf_xgb.predict(X_test)
fpr_xgb, tpr_xgb, thresholds_xgb = roc_curve(y_test, pred_xgb, pos_label=1)
print('AUC:',auc(fpr_xgb, tpr_xgb))
print('正解率:',accuracy_score(pred_xgb, y_test))
print("Best Parameter: {}".format(clf_xgb.best_params_))
# 提出用データを予測
pred_xgb = clf_xgb.predict(df_sub)
# 提出用csvファイルを作成
sub = pd.DataFrame(pd.read_csv("input/test.csv")['PassengerId'])
sub['Survived'] = list(map(int, pred_xgb))
sub.to_csv("submission.csv", index = False)
# kaggleAPIを利用して提出
!kaggle competitions submit -c titanic -f submission.csv -m test

このように表示されたらsubmit成功です!

最後に
Google colabのおかげで、poorなマシンでもGPU/TPUを無料で利用して、kaggleコンペに参加できるのは大変素晴らしいことだなぁと思います。まさに、AI for Everyone、ありがとうGoogle。
誤りや修正したほうがいい点などあれば、お気軽にコメントを頂けますと嬉しいです。