はじめに
メルケプストラムの取得方法をまとめました。
1. pysptk.sp2mc(powerspec, order, alpha)
1-1. 概要
pysptk.sp2mcはpyworldで求めたスペクトル包絡からメルケプストラムに変換する関数です。フレーム処理も自動で行ってくれます。代表的な引数について以下にまとめます。
- powerspec
pyworldで取得した声道スペクトル(スペクトル包絡)。何も考えずにそのまま入力してOKだけど、API的にはパワースペクトルだから、振幅スペクトルでないことに注意したい。 - order
メルケプストラムの次数。しかし、出力はorder+1のメルケプストラムが出力されるからその点には注意したい。 - alpha
all-pass constantというものらしいです。SPTKのREFERENCE MANUALによると以下のように記載されています。
The phase characteristic is given by the variable α. For a sampling rate of 16 kHz, α is
set to 0.42. For a sampling rate 10 kHz, α is set to 0.35. For a sampling rate 8 kHz, α is
set to 0.31.
つまり、16kHz:0.42、10kHz:0.35、8kHz:0.31に設定するといいらしいです。
また、all-pass constantについては、同じモジュール内のpysptk.util.mcepalpha(fs)を使って算出することもできます。
返り値は以下です。
- mel-cepstrum(フレーム数, メルケプストラム次数)
1-2. サンプルコード
import wave
import librosa
import pyworld as pw
import pysptk as sptk
import numpy as np
import matplotlib.pyplot as plt
# 音声ファイル
audio_path = "./a.wav"
# 読み込みモードでWAVファイルを開く
with wave.open(audio_path, 'rb') as wr:
# 情報取得
ch = wr.getnchannels()
width = wr.getsampwidth()
fr = wr.getframerate()
fn = wr.getnframes()
# 表示
print("チャンネル: ", ch)
print("サンプルサイズ: ", width)
print("サンプリングレート: ", fr)
print("フレームレート: ", fn)
print("再生時間: ", 1.0 * fn / fr)
# librosaで音声ファイルを読み込み
y, sr = librosa.load(audio_path, sr=fr)
# pyworldでスペクトル包絡を取得
y = y.astype(np.float)
_f0, t = pw.dio(y, sr)
f0 = pw.stonemask(y, _f0, t, sr)
sp = pw.cheaptrick(y, f0, t, sr)
ap = pw.d4c(y, f0, t, sr)
# 元の音声のスペクトル包絡
center_sp = int(len(sp)/2) # 定常部分を求める
# メルケプストラムの算出
mcep = sptk.sp2mc(sp, order=19, alpha=0.42)
center_mcep = int(len(mcep)/2) # 定常部分を求める
# メルケプストラムからスペクトル包絡に変換
sp_from_mcep = sptk.mc2sp(mcep, alpha = 0.42, fftlen = 1024)
# グラフの表示
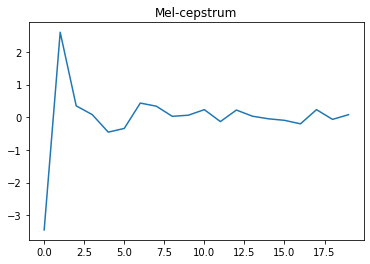
# メルケプストラム
plt.figure()
plt.plot(mcep[center_sp])
plt.title('Mel-cepstrum')
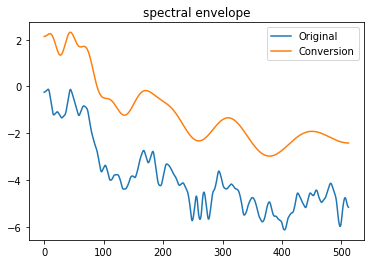
# "元のスペクトル包絡"と"メルケプストラムから再合成したスペクトル包絡"
plt.figure()
plt.plot(np.log10(sp[center_sp]), label="Original")
plt.plot(np.log10(sp_from_mcep[center_sp]), label="Conversion")
plt.title('spectral envelope')
plt.legend()
メルケプストラム(30フレーム目)
"元のスペクトル包絡"と"メルケプストラムから再合成したスペクトル包絡"
2. pysptk.sptk.mcep(windowed, order, alpha)
2-1. 概要
pysptk.mcepは時間波形(振幅スペクトルや対数振幅スペクトルなども引数を調整すれば対応可能)から入力したフレームだけをメルケプストラムに変換する関数です。時間波形がデフォルトなので、その他の入力を試す場合には、Input data typeを変更する必要があります。代表的な引数について以下にまとめます。
- windowed
通常、時間波形。切り出す範囲を自分で決める必要があります。FFTの都合上、2の累乗内で設定する必要があることに注意したい。 - order
pysptk.sp2mcと同じなので割愛 - alpha
pysptk.sp2mcと同じなので割愛
返り値は以下です。
- mel-cepstrum(メルケプストラム次数, )
2-2. サンプルコード
import wave
import librosa
import pyworld as pw
import pysptk as sptk
import numpy as np
import matplotlib.pyplot as plt
# 音声ファイル
audio_path = "./a.wav"
# 読み込みモードでWAVファイルを開く
with wave.open(audio_path, 'rb') as wr:
# 情報取得
ch = wr.getnchannels()
width = wr.getsampwidth()
fr = wr.getframerate()
fn = wr.getnframes()
# 表示
print("チャンネル: ", ch)
print("サンプルサイズ: ", width)
print("サンプリングレート: ", fr)
print("フレームレート: ", fn)
print("再生時間: ", 1.0 * fn / fr)
# librosaで音声ファイルを読み込み
y, sr = librosa.load(audio_path, sr=fr)
# pyworldでスペクトル包絡を取得
y = y.astype(np.float)
_f0, t = pw.dio(y, sr)
f0 = pw.stonemask(y, _f0, t, sr)
sp = pw.cheaptrick(y, f0, t, sr)
ap = pw.d4c(y, f0, t, sr)
# 元の音声のスペクトル包絡
center_sp = int(len(sp)/2) # 定常部分を求める
# フレーム処理 → 定常部分を切り出す
nfft = 512 # FFTのサンプル数
center = int(len(y)/2) # 中心のサンプル番号
y = y[center - int(nfft/2) : center + int(nfft/2)] # 2の累乗である必要がある
# メルケプストラムの算出
mcep = sptk.mcep(y, order=19, alpha=0.42)
# メルケプストラムからスペクトル包絡に変換
sp_from_mcep = sptk.mc2sp(mcep, alpha = 0.42, fftlen = 1024)
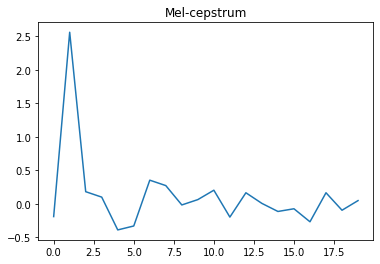
# グラフの表示
# メルケプストラム
plt.figure()
plt.plot(mcep.T)
plt.title('Mel-cepstrum')
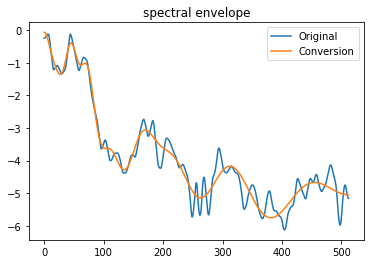
# "元のスペクトル包絡"と"メルケプストラムから再合成したスペクトル包絡"
plt.figure()
plt.plot(np.log10(sp[center_sp]), label="Original")
plt.plot(np.log10(sp_from_mcep), label="Conversion")
plt.title('spectral envelope')
plt.legend()
メルケプストラム(定常部分)
"元のスペクトル包絡"と"メルケプストラムから再合成したスペクトル包絡"