自然言語処理を楽しむ
「自然言語処理」って楽しいです!!
もちろんそこそこ難しいこともあるのですが……それ以上に楽しいです、とにかく楽しいです。
そんな楽しさのとっかかりになればと思い書いてみます。
自然言語処理で何がしたいのか?何ができるのか?
普通に会話で使う日本語などのことを「自然言語」と呼んでいます。
そんな「自然言語」をコンピューターで扱いやすい形に「処理」するのが「自然言語・処理」だと思ってください。
例えばコンピューターにわかりやすいものとしては「数値データ」があります。「ECサイトの売り上げ」「温度」「交通量」など数値で表せるものです。「数値データ」は数式やコンピュータで扱うのが簡単なのでこんなことが簡単にできます。
- excelで表にしてグラフを書いたり簡単にできます
- 気温とビールの売り上げの関係が見れたりします
- 温度が10度以下になったらエアコンをつけます
- 今流行りのAI/機械学習なんてことも出来ます。
……もし、これと同じようなことを「自然言語」つまり「会話」や「SNSの文章」や「小説」や「歌詞」という文章に対してで出来たら楽しそうじゃないですか?
例えば、
- 好きなアーティストの歌詞や好きな小説を(どうにかして)データ化してグラフを書いてみる
- 好きなマンガのセリフを比較してみる
- SNSでネガティブなコメントを強制ブロックする
歌詞、新聞、Wikipediaや、自分の好きなアニメの設定資料、なんでもいいので「文章」をネタに色々分析してみると何か面白い発見が得られるかもしれません。
なんとなくワクワクしませんか? しますよね!!
補足 : あらためて自然言語とは?
「自然言語」は日常のコミュニケーションのため自然に発展してきた「自然(発生的な)言語」を指す言葉です。対して「人工言語(形式言語)」というのもあって、馴染み深いものでは「プログラム言語」です。これはある目的のために「人工的」に作られた言語です。
大きな違いとしては「自然言語」が文法や単語の意味が非常に曖昧で多様な表現が許されるのに対して、「人工言語(形式言語)」は意味が明らかで曖昧さがないことです。この「曖昧さ」というのはそれぞれの人の生活スタイルや文化によるものなので解釈がとても広いのですが、そこが自然言語処理の難しさでもあり、楽しさでもあります。
APIに頼って遊んでみよう!
面白そうだとはいっても「自然言語処理」なんてそんなに簡単に出来るものではありませんでした・・・昔は・・・そう、でも今は簡単にできてしまいます。
本当に便利な世の中になったもので外部の API に頼ることで楽しい部分だけショートカットでたどり着いてしまうことが可能です。
自然言語処理を提供してくれるサービスには AWS や Azure やたくさんのクラウドサービスもありますが、今回は日本メーカーで日本語の処理に強い COTOHA API を使わせていただきます。
COTOHA API
https://api.ce-cotoha.com/
とにかく遊んでみよう
前置きが長かったですがとにかく楽しんで遊んでみるのが一番です。 楽しんでもらうのが今回のQiitaで一番メインで伝えたいことです。
今回は細かなプログラミングの話は省略してます。さくっと簡単にできるよう最近流行りのPythonで書いてます。Jupyterとかに張り付けてくれるだけで動きます!
まず COTOHA API のサイトから登録を行って各種情報をゲットしてください。
ここだけはググって頑張ってもらうか、https://api.ce-cotoha.com/contents/gettingStarted.html あたりのスタートガイド見て頑張ってください。ちょっと簡単に使ってみるにはぜんぜん無料で試せますし、他のクラウドサービスみたいに最初からクレジットカード入力も不要なので安心して遊んでみることができます。
無事に登録できたら下記のようなアカウントホーム画面で実行に必要な情報を入手できます。

あとはもう簡単です下記のコード中の★部分を上でゲットした値に書き換えてPythonを実行してください。
##############################
# ★ COTOHA API のダッシュボードの文字列で書き換えてください
##############################
api_base_url = 'https://api.ce-cotoha.com/api/dev/'
client_id = '************'
client_secret = '************'
access_token_url = 'https://api.ce-cotoha.com/v1/oauth/accesstokens'
##############################
# ★ 解析したいテキストを入れてください
##############################
text = '生まれて、すみません。'
##############################
import requests
import json
# Token取得
headers = { "Content-Type" : "application/json" }
data = { "grantType":"client_credentials", "clientId":client_id, "clientSecret":client_secret }
r = requests.post(access_token_url, data=json.dumps(data), headers=headers)
bearer_token = r.json()["access_token"]
# ユーザー属性取得
headers = { "Content-Type" : "application/json;charset=UTF-8", "Authorization":"Bearer "+bearer_token }
data = { "sentence":text }
url = api_base_url + "nlp/v1/sentiment"
r = requests.post(url, data=json.dumps(data), headers=headers)
r.json()
実行してみるとこんな結果が得られます。
{'message': 'OK',
'result': {'emotional_phrase': [{'emotion': '悲しい', 'form': 'すみません'}],
'score': 0.21369802583055023,
'sentiment': 'Negative'},
'status': 0}
これは COTOHA の 感情分析API というものを使ったサンプルです。
感情分析
文章作成時の書き手の感情をポジティブまたはネガティブで判定します。
さらに文章に含まれる「喜ぶ」や「驚く」といった特定の感情も認識します。
「生まれて、すみません。」という有名な一文を分析してみた結果をまとめるとこう分析されたことになります。
emotion : '悲しい'
sentiment: 'Negative'
この1文は 悲しい という**emotion(感情)**を表していて、文章全体としては Negative だという結果が得られました。
「生まれて、すみません」という何とも言えない自然な文章に対して「自然言語処理」することで扱いやすいデータに変換することができました。
これが「自然言語処理」というものの一歩です。
ぜひ色んな文章をいれてみて試してみてください。けっこう面白い結果になると思います……。
もう少し遊んでみよう
では今度は次のコードを動かしてみてください。
今度は冒頭の texts に配列の形で複数のテキストをいれることで複数のテキストを一気に解析してみます。
さっきのサンプルと同じように実行してみてください。
##############################
# ★ COTOHA API のダッシュボードの文字列で書き換えてください
##############################
api_base_url = 'https://api.ce-cotoha.com/api/dev/'
client_id = '************'
client_secret = '************'
access_token_url = 'https://api.ce-cotoha.com/v1/oauth/accesstokens'
##############################
# ★ 解析したいテキストを入れてください
##############################
texts = [
'吾輩は猫である。',
'名前はまだ無い。',
'どこで生れたかとんと見当がつかぬ。',
'何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。',
'吾輩はここで始めて人間というものを見た。',
'しかもあとで聞くとそれは書生という人間中で一番獰悪な種族であったそうだ。',
'この書生というのは時々我々を捕えて煮て食うという話である。',
'しかしその当時は何という考もなかったから別段恐しいとも思わなかった。',
'ただ彼の掌に載せられてスーと持ち上げられた時何だかフワフワした感じがあったばかりである。',
'掌の上で少し落ちついて書生の顔を見たのがいわゆる人間というものの見始であろう。',
'この時妙なものだと思った感じが今でも残っている。第一毛をもって装飾されべきはずの顔がつるつるしてまるで薬缶だ。',
'その後猫にもだいぶ逢ったがこんな片輪には一度も出会わした事がない。',
'のみならず顔の真中があまりに突起している。',
'そうしてその穴の中から時々ぷうぷうと煙を吹く。',
'どうも咽せぽくて実に弱った。',
'これが人間の飲む煙草というものである事はようやくこの頃知った。'
]
##############################
print("sentiment,score")
import requests
import json
# Token取得
headers = { "Content-Type" : "application/json" }
data = { "grantType":"client_credentials", "clientId":client_id, "clientSecret":client_secret }
r = requests.post(access_token_url, data=json.dumps(data), headers=headers)
bearer_token = r.json()["access_token"]
# ユーザー属性取得
headers = { "Content-Type" : "application/json;charset=UTF-8", "Authorization":"Bearer "+bearer_token }
for text in texts:
data = { "sentence":text }
url = api_base_url + "nlp/v1/sentiment"
r = requests.post(url, data=json.dumps(data), headers=headers)
r_json = r.json()
print( "{},{}".format( r_json['result']['sentiment'], r_json['result']['score'] ) )
実行してみると次のような結果が得られます。
sentiment,score
Neutral,0.3753601806177662
Neutral,0.28184469062696865
Neutral,0.3836848869293042
Negative,0.39071316583764915
Neutral,0.3702709760069095
Negative,0.513838361667319
Neutral,0.47572556634191593
Negative,0.6752951176068892
Neutral,0.42154746899352424
Positive,0.14142126089599155
Neutral,0.4397035866256947
Neutral,0.3335122613499773
Neutral,0.36874320529074195
Neutral,0.3721780539113525
Negative,0.19851456636071463
Neutral,0.4334376882848198
コードを見てもらえばなんとなく想像できると思いますが、これは、夏目漱石の「吾輩は猫である」の冒頭を1文ずつ解析していってその結果を並べたものです。
これで出てきた結果を Excel で読み込んでガチャガチャしてみるといろいろとグラフが書けます。
例えばこんな感じです。 1つだと面白くないので 太宰治 「人間失格」 も並べてみました。
上が「吾輩は猫である」で下が「人間失格」です。
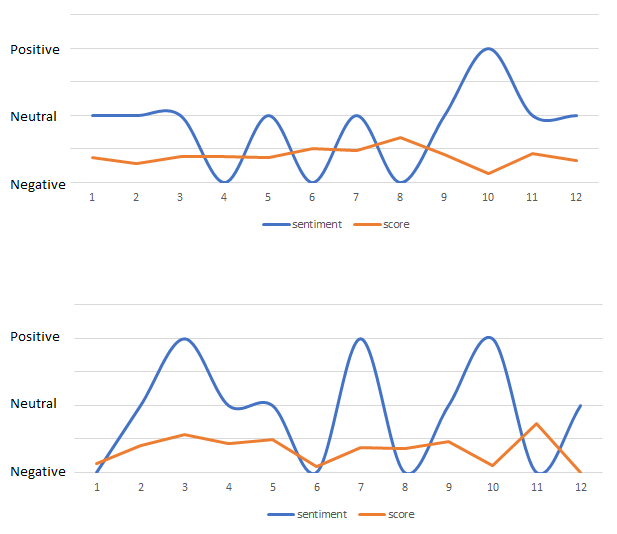
こうやって並べてみると面白いですね…。
「吾輩は猫である」の方が Negative と Neutral をたんたんと行き来する感じで続くのに対して、「人間失格」のバタつき。 Negative と Positive を行き来している感情の振れ幅がすごいですね。
冒頭の10文章くらいしかやっていませんが、これを全文でやってみたり章ごとにしたり、作品ごと・作家ごとで比較してみたりとさらに色々と見えてきそうな気がします。
ここまでデータ化できれば「平均」を見て見たり「分散」を見て見たり、と、いろいろな統計的なデータ分析が可能になるという仕掛けです。
さいごに
どうでしたか? おもったより簡単に楽しそうなことができそうですよね。
例えば COTOHA API には他にも「文章から年齢や性別を推定する」「品詞(動詞や名詞や)を取り出す」などたくさんのAPIがあります。もちろん Azure や AWS や IBM Cloud やと言ったものでも様々なデータ化が可能です。 IBM Cloud の Personality Insights なんてのも面白いです。文章から性格診断ができます。
このように「自然言語処理」を使う事で様々な文章がコンピューターで扱いやすい形に出来ます。
扱いやすい形に出来てしまえば様々な応用が可能になります。
Webサイトの文章を分析して改善してCVRを上げたり、SNSを分析してマーケティングに活かしたり、小論文や読書感想文や採点結果を分析してどういう文章が採点が高いかを分析したり……。
小論文や読書感想文からさまざまなデータを抽出して「説明変数」にして、採点を「目的変数」にして、回帰分析をかけたり、です。もしキレイなディシジョンツリーが書ければ高得点狙えるかもしれません……!
難しいことは抜きにしても(難しいことはサービス提供してくれる専門家がやってくれます!)普段慣れ親しんでいる「自然言語」で色々遊ぶこと出来るのは楽しいことです。 このQiitaが自然言語処理の第一歩になってくれればと思います!!