ちょっと今っぽいことをしてみる
Python流行ってるな、Jupyter/Pandasとかよく名前聞くな、データ分析とかすらすらできないとこれからご飯食べていけないな。 でもこれといってネタもないし何から勉強しよう? ということで無料でできそうで、かつ、ちょっとそれっぽいことをやってみる。
使う技術(最初に読まなくてもいいです)
-
IBMさまの Personality Insights
BIG DATAをつかって、テキスト情報やTwitterアカウントをもとに性格診断をするクラウドサービスです。
使うためには IBM Cloud のライトアカウントで十分ですが、試すだけならWebサイト上から試すことも可能です。 -
Jupyter(Pythonとその仲間たち)
Pythonを使ったデータ分析を対話的に行うことができる便利エディタ兼実行環境です。
こちらは自分の環境へのインストールをお願いします。
使う統計的な手法(最初に読まなくてもいいです)
-
K-means
クラスタリングをざっくり行うための手法です。とりあえず精度はおいておいてよくわからないけどクラスタリングできるという強みがあります。 -
PCA
主成分分析といわれるものです。例えば、軸が5つもあるようなデータの場合、グラフにプロットできなくて可視化が難しいです。見ることができないと、あってる・まちがってる、の議論もできないので、5つの軸を2つの軸に無理やり近似させるという次元圧縮という必殺技みたいなことができます。(統計ででてくる名前はいちいち必殺技っぽい名前が多い気がします) 2軸のデータになれば簡単に散布図などのグラフ化が可能になります。
なにをしてみるのか?
今回してみるのは下記です。
- Personality Insights で性格診断をしてみて、性格診断結果を数値にする。
- Jupyter上でK-meansを使って性格診断結果をクラスタリングする。
- Jupyter上でPCAを使って2軸にしてクラスタリング結果を散布図にしてみて眺める。
- ああぁぁ、人ってこういうタイプいるよねー という雑談をする。※ 仕事であれば「タイプ毎にマーケティング施策を打つ」とかになります
やってみる
極力手順だけを端的に書きます。
詳しい説明はしません(できません……)
1. IBM Personality Insights で性格を数値化する
IBM CloudのライトアカウントをとってAPIをたたいてください。
※ここは完全にこの記事外の話なので……いろいろ調べてやってください
もしさくっと試してみたいだけなら下記サイトにアクセスしてみてください。
https://personality-insights-demo.ng.bluemix.net/
例えば、バラク・オバマのスピーチを解析してみたり、任意テキストでの解析ができたりします。
例えばこんなのがでているでしょうか? この値をつかっていきたいと思います。
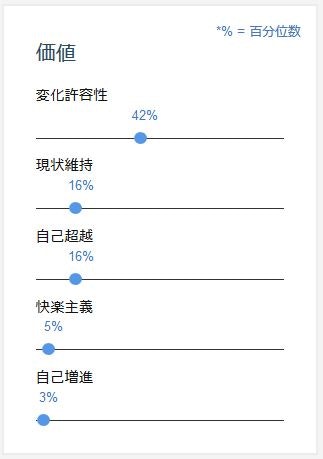
任意テキストでの解析などを駆使して5名分くらいのデータを作ってください。今回は適当に5名分作ってみました。
| name | 変化許容性 | 現状維持 | 自己超越 | 快楽主義 | 自己増進 |
|---|---|---|---|---|---|
| オバマ | 0.42 | 0.16 | 0.16 | 0.05 | 0.03 |
| ガンジー | 0.58 | 0.02 | 0.32 | 0.03 | 0.00 |
| 漱石 | 0.27 | 0.07 | 0.91 | 0.00 | 0.00 |
| キング | 0.19 | 0.02 | 0.95 | 0.01 | 0.15 |
| AKIRA | 0.81 | 0.99 | 0.90 | 0.31 | 0.47 |
※ AKIRAは映画の会話シーンをとりだして分析してみました... なので金田君もてつおも混在 ^^
2. Jupyterを使ってクラスタ分析してみる
Jupyterのセットアップと使い方は略です。
ここも良記事たくさんあるので参考にしてください。
とりあえずコマンドをうって 1+2 [Shift+Enter] とかで 3 と出るくらいまでできたらOKです。
データを作る
Jupyter上で以下のコマンドをいれてShift+Enterなりで実行してください。
import numpy as np
import pandas as pd
## PI(Personal Insights) data
pi_array = np.array([
[ 0.42, 0.16, 0.16, 0.05, 0.03 ],
[ 0.58, 0.02, 0.32, 0.03, 0.00 ],
[ 0.27, 0.07, 0.91, 0.00, 0.00 ],
[ 0.19, 0.02, 0.95, 0.01, 0.15 ],
[ 0.81, 0.99, 0.90, 0.31, 0.47 ],
])
row_names = ['O','G','S','K','AKIRA']
column_names = ['変化許容性','現状維持','自己超越','快楽主義','自己増進']
pi_df = pd.DataFrame( pi_array, columns=column_names, index=row_names )
pi_df
こんな結果がでてたら正解です。
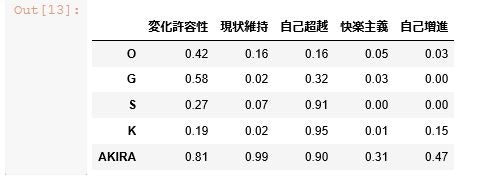
DataFrameという表の形式でデータの作成が完了しました。
クラスタリングをしてみる
sklearn.clusterというパッケージを使って K-means でのクラスタリングをしてみます。
まずパッケージを import し、今回は 3 つのクラスタに分類(n_clusters=3) さらに、列名を加えて DataFrame を作ってみます。
from sklearn.cluster import KMeans
pred = KMeans(n_clusters=3).fit_predict(pi_array)
pred_df = pd.DataFrame( pred, columns=['clustor'], index=row_names )
pred_df
こんな結果がでたでしょうか。
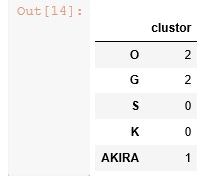
オバマさんとガンジーは同じタイプで、漱石さんとキングさんは同じタイプ、AKIRAは特別です。
と、K-means では言ってます。
散布図にプロットしてみる
PCAを使って 2次元 に落とし込んでみます。 PCA(n_components=2) で2軸を定義して pca.fit_transform(pi_df) で変換、その結果を decomposition_pi 配列にし保存します。
2軸に落とし込んだ decomposition_pi に、先ほど算出したクラスタリングの結果の列 pred_df を np.concatenate を使って追加します。
その後 matplotlib を使ってプロットしてみます。
from sklearn.decomposition import PCA
from matplotlib import pyplot
# PCA
pca = PCA(n_components=2)
decomposition_pi = pca.fit_transform(pi_df)
# clustor結果の追加
decomposition_pi = np.concatenate( (decomposition_pi,pred_df), axis=1 )
# グラフ化
fig = pyplot.figure(figsize=(8,4),dpi=100)
ax = fig.add_subplot(1,1,1)
ax.scatter( decomposition_pi[:,0], decomposition_pi[:,1], c=decomposition_pi[:,2] )
for k,v in pd.DataFrame(decomposition_pi).iterrows():
ax.annotate( row_names[k], xy=(v[0],v[1]), size=13 )
decomposition_pi
実行してみると、何もエラーがなければグラフがでます。
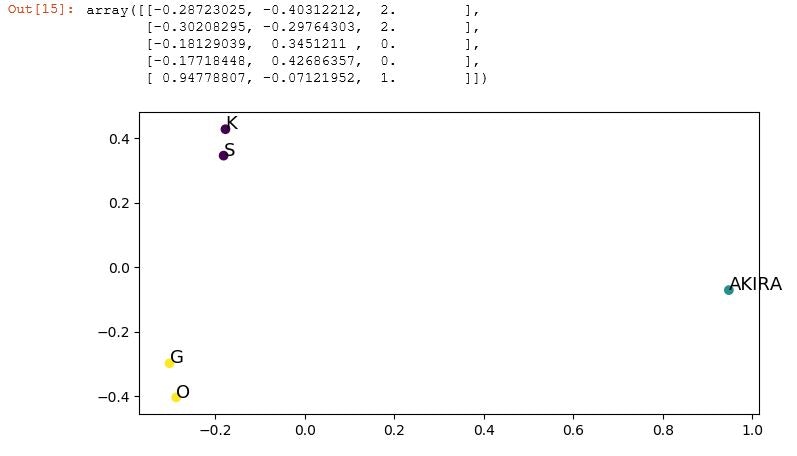
この縦・横の軸は何でしょう。 実はわからないです。 PCAがなんとなくうまい具合にだしてくれたものです。
(いや、本当は係数などがわかるのですが。)
ここの縦・横の軸に想像力を働かせて、意味を見出して薄目でみつつ、なんだかうまい具合に3つにわけられてるのが確認できますね。ちなみにここで綺麗に3つになってなかったら、K-meansの n_clusters=3 などの数値をいじって変えてみたりもします。
ということで、一通りDone.
まとめ
なんとなくそれっぽいことが出来ました。
これをうまく使えば、例えば学校の先生なら小論文的なものをまとめて分析してクラスタリングして可視化してみるとか。(そんな雑な方法でクラスタリングがいいかという倫理的な話はおいておいて) 好きな小説を分析してクラスタリングして、読んだことのない作品が好みかどうかを事前に調べるとか(青空文庫とかで公開されてるものに限るかもですが。GoogleやAmazonの試し読みみたいなのでもできるかな?)