はじめに
この数年で非常に多くのニューラルボコーダーが提案され、現在でもその流れは続いている。しかしニューラルボコーダーに関するまとまった情報は見かけない。この記事では自分の勉強用やニューラルボコーダーのこれまでの発展や課題を考える一助になればと思い、いくつかの論文をピックアップした。
ニューラルボコーダーはすでにメルスペクトログラム等からCPUで高速、高品質な合成が行えるようになったが、未だに「決定版」は現れていない。速度の改善がまだ続いているということもあるが、必ずしも手軽に試せる実装が公開されておらず比較実験が難しいことや、完全に想定する波形が定義されているわけではなく、音声の品質の客観的な評価が難しいことも一因であると思う。評価指標としてはMOS値が一般的に採用されるが、生成させる音声の性質(話し声か、歌声か、感情がついているか、広い音域や話者に対応するか等)も考慮すべきであり、目的に適しているかどうかは論文の内容や実験の手法を確認する必要がある。
現在は多くのニューラルボコーダーで入力にはメルスペクトログラム(大抵80次元)が使われる。現在の音声合成ではほぼ標準規格のように使われており、TTSモデルは高品質なメルスペクトログラムを生成するモデルとしてニューラルボコーダーと別の軸で研究が進められている。
音高の安定性を得るためにはさらにF0を用いるのが重要とされる。近年ではF0に応じた励起信号を波形に変換していくボコーダーが高い品質を示している。Neural Source Filterがそのタイプのニューラルボコーダーとして古くからあるが、速度や品質はより向上している。特に歌声合成では、知覚的な品質と音高の安定性の関連度が高い。リアルなF0の生成方法はオープンソースで十分に広まっていないため、その重要性を認識しづらい状況と思われる。
モデルの構造が同じなら所定の品質が出るというわけではなく、学習方法が大きく品質を左右する。入力(メルスペクトログラムやF0)では波形は一定に決まらず、人間の聴覚は位相飛びに敏感なため、人間らしい位相を学習させる必要がある。それらしい位相を持つ波形を生成するために、多重解像度STFT損失や敵対的学習が用いられる。F0に基づいた励起信号を使うモデルは、正確な音高の制御とネットワークの単純化を実現した。現在では高周波数帯の再現度も重視されるが、TTSモデルが高精細なメルスペクトログラムを生成できるようになってきたこととも連動しているのだろう。
arxiv.orgに公開された時期を参照して、大まかに時系列的に並べているが、必ずしも世に出た順ではないと思われる。初期の著名なニューラルボコーダーに関してはより詳しく解説された他の記事を参照するのがいいだろうと思う。
2016年
WaveNet: A Generative Model for Raw Audio
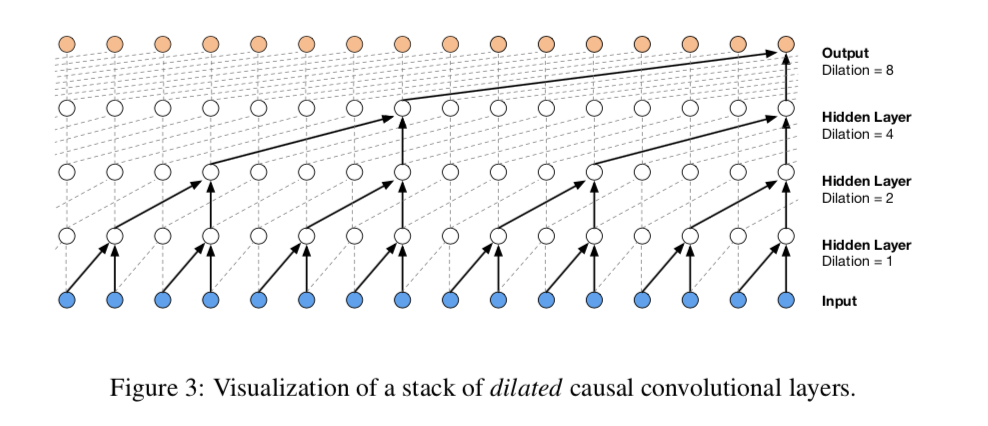
自己回帰ネットワークによってパラメトリック音声合成や素片選択より遥かに自然な音声を実現した革命的なモデル。生成速度は実用的なレベルではなかったが、当時の音声合成の世界に衝撃を与えた。
WaveNetはCNNであるためRNNより学習時は高速(それでも今のニューラルボコーダーに比べると相当な時間を使うようだ)だが、生成時は最後の出力を入力に加える自己回帰的な手法を使う。
開祖と捉えられるモデルだが、RTFを重視するニューラルボコーダーは、フレーム毎の音響特徴量を入力とし、非自己回帰的にひとまとまりの波形(所定のウィンドウサイズの波形や1周期分の波形)を生成するものが主流になっており、サンプル点毎の生成と自己回帰というアイデアに戻ってくるとは考えにくい。低遅延重視の逐次生成型ボコーダーで自己回帰の手法には発展が見られる。
SampleRNN: An Unconditional End-to-End Neural Audio Generation Model
CNNを用いたWaveNetよりも、RNNを用いた方が長期的な依存を捉えられるのではないかという意図からRNNでの音声の生成を試みたもの。論文では条件付けのない生成についての評価が主である。
現在のボコーダーは「長期的な依存」についての情報自体をあまり必要としなくなっているが、長時間のそれらしい音声の無条件生成ができることを示した点で特色がある。
2018年
Efficient Neural Audio Synthesis

WaveRNNと呼ばれる。単一の自己回帰ネットワークで音声を合成する。GPUでリアルタイムの合成が可能であり、モバイルのCPUでも使用できる、当時としては効率的な手法だった。WaveNetではRNNを使わずCNNにすることで使えるレベルにできたとしていたが、RNNでもうまく使えばこうなったということである。論文では入力に音素とF0を与えており、ニューラルボコーダーではなく音声合成システムそのものだが、Tacotronと組み合わせてニューラルボコーダーとして使う手法が有名。
この時代はニューラルボコーダーと音声合成システムの区切りが曖昧だったが、2017年にTacotronが登場したためか、音響モデルとボコーダーの役割分担が進んでいくことになる。
以降、しばらくの間WaveNetを手本とした効率的な生成方法の開発が続いていく。
LPCNet: Improving Neural Speech Synthesis Through Linear Prediction
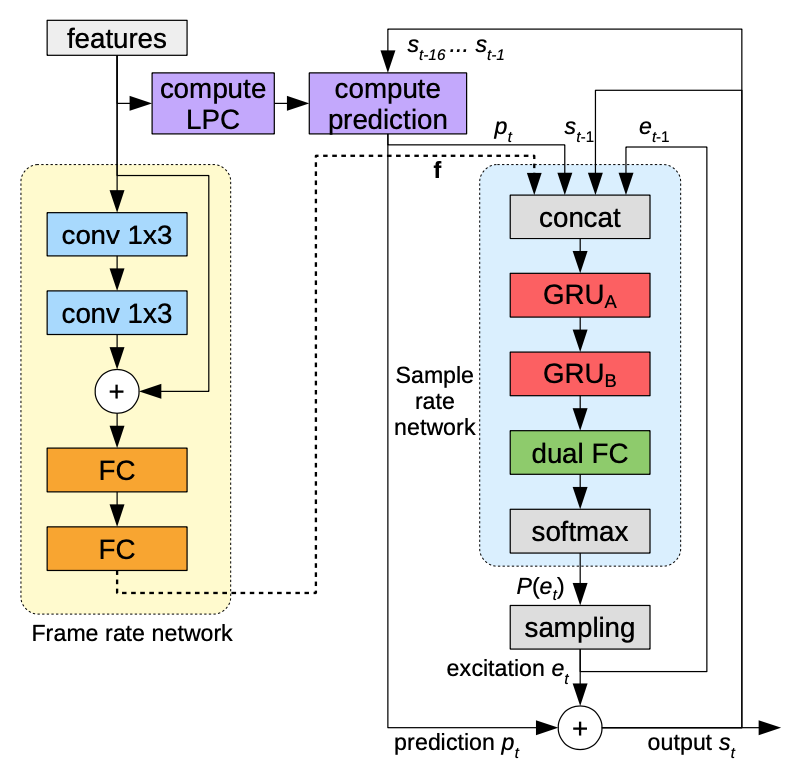
線形予測と残差接続を用いてWaveRNNのアイデアを発展させ、さらなる高速化と高品質化を達成した。
Fftnet: A Real-Time Speaker-Dependent Neural Vocoder
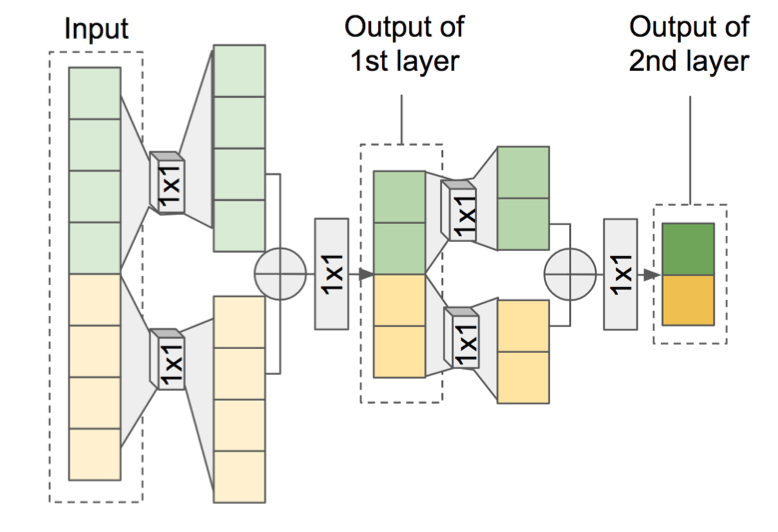
通常のWaveNetの計算の代わりに、高速フーリエ変換(FFT)のように、入力を2分割してConv1Dに適用して加算する操作を繰り返すことでWaveNetを高速化しつつより自然な音声を実現した。
WaveGlow: A Flow-based Generative Network for Speech Synthesis

FlowベースのGlowと呼ばれるモデルを音声合成用に変更したもの。高速化のためには自己回帰をなくすのが重要だが、従来の非自己回帰型のモデルは学習が難しかった。複合的な損失関数ではなく負の対数尤度のみから学習でき、学習が安定しており、かつWaveNetより高品質な結果を得た。
2019年
Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram

WaveNetベースの生成器と多重解像度STFT損失と敵対的生成を用い、知識蒸留なしに少ないパラメータで高い品質を得ることができた。当時としては学習しやすく高速に動作するモデルだった。複数のSTFTのパラメータでSTFT損失を取る多重解像度STFT損失は現在一般的に用いられている。
林智樹氏のPyTorch実装の(他にも複数のニューラルボコーダーを含んだ)リポジトリは有名。各種論文の比較実験で頻繁に登場する。
MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
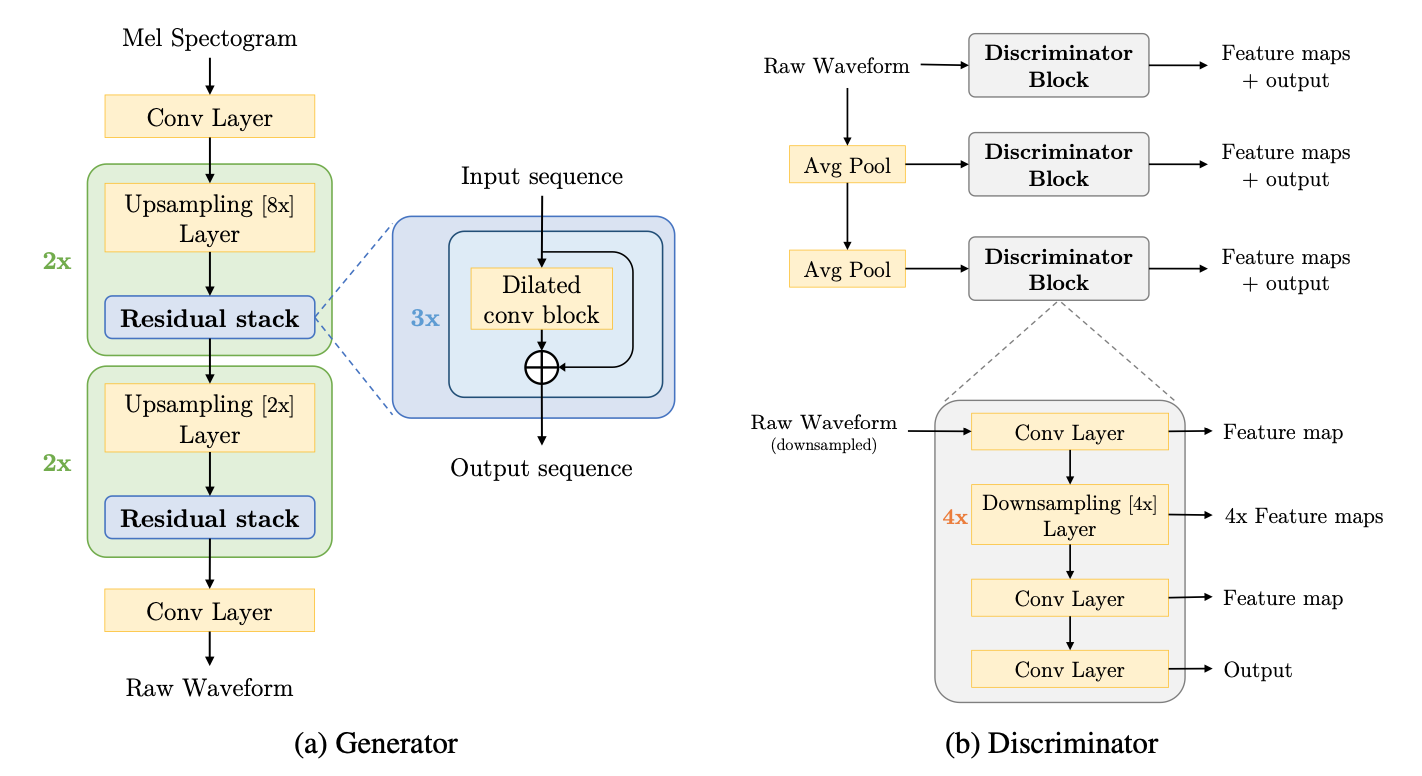
自己回帰のない完全な畳み込みで波形を合成し、従来のボコーダーより遥かに高速な合成が可能になり、CPUでリアルタイムの音声合成ができることを示した。敵対的損失としてmulti-scale discriminatorを採用した。
長区間の波形をConv1D等で生成しようというアイデアは現在でも使われており、サンプル点ごとに生成する手法は主流からは外れていった。今では目新しいことではないが、WaveNetからここにたどり着くまで多くの研鑽があったのだろう。MelGANは多数の派生系が生まれる。
Neural source-filter-based waveform model for statistical parametric speech synthesis
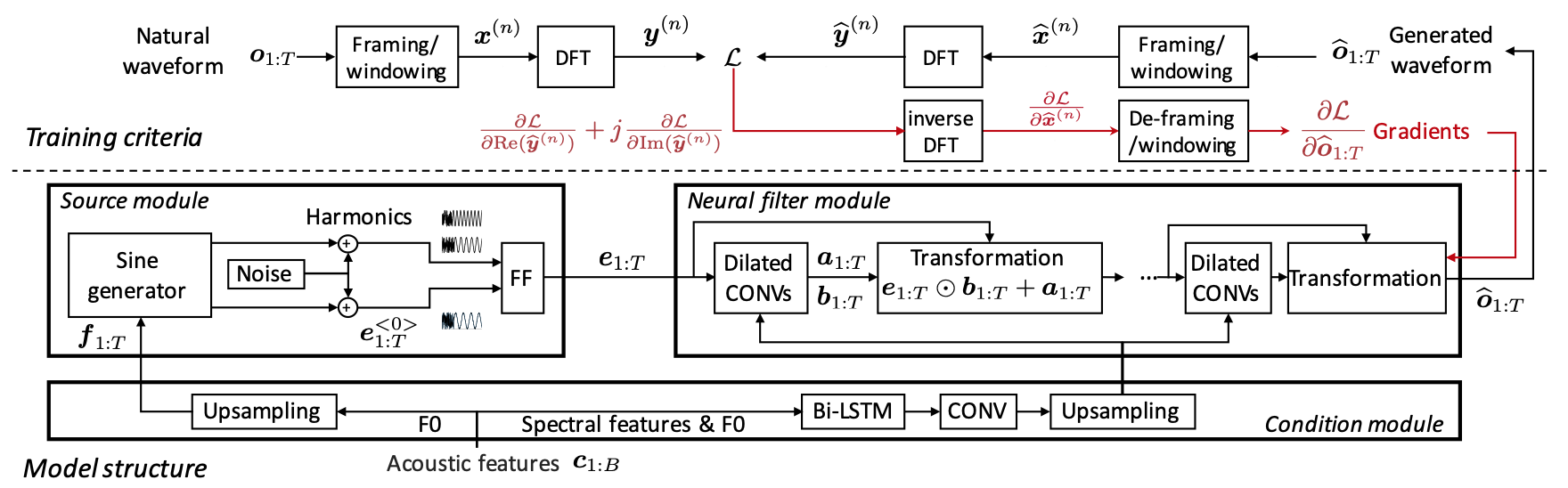
正弦波をベースとしたソースフィルターモデルとニューラルネットワークを統合したもの。自己回帰がなく、WaveNetより100倍以上高速で、知識蒸留を必要とせず、完全にF0が安定している。
この時点で位相の整合性が品質に重要であることは指摘されていたが、損失関数に位相距離を与えても品質は向上しなかったとされる。敵対的生成も使っておらず、学習方法やネットワークの構成には古さが感じられるが、当時歌声合成に実用的な(F0が安定した)ニューラルボコーダーはおそらく希少であり、NEUTRINOに採用されて話題になった。後のニューラルボコーダーの研究では位相の整合性を得るための訓練方法や敵対的生成による品質の向上手段が発見されていくことになる。
以降、一般的なニューラルネットワークを素のまま使うのではなく、音声合成の技術を応用して実用的なニューラルボコーダーを作るという流れが生まれていく。歌声合成では音高の安定性が重要なため、ソース信号を励起させる手法は主流となっている。
2020年
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
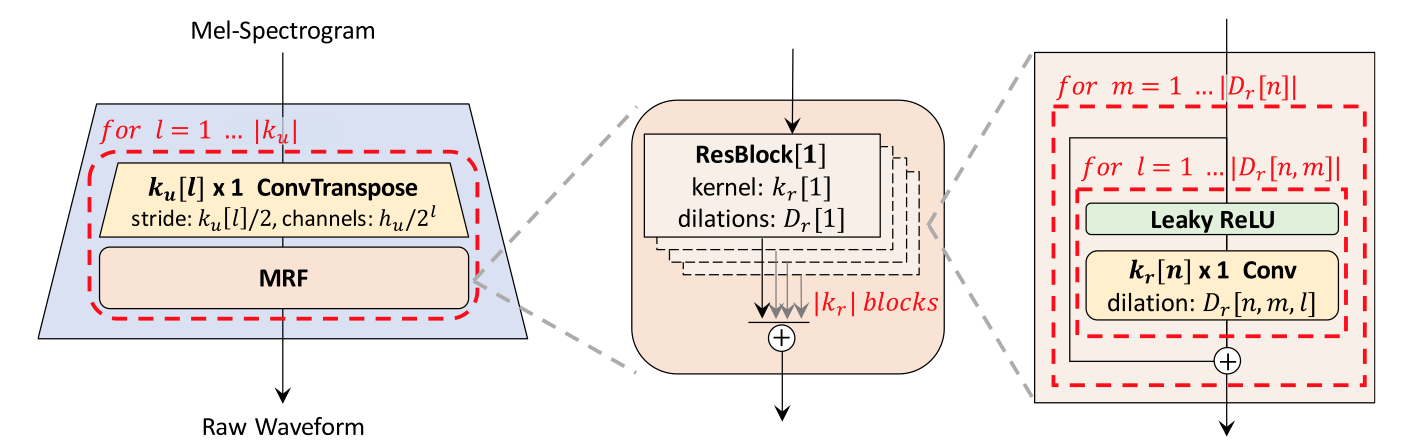
自己回帰を使わず、残差接続されたConv1Dでメルスペクトログラムをアップサンプリングしていき波形を生成する。CPUでも実用的な速度で合成できるようになった。
構造は非常にシンプルで、学習方法が品質の向上に重要であると示唆されている。周期的なパターンをきちんと生成できるようにするために、多重解像度STFT損失とmulti-scale discriminatorとmulti-period discriminatorの2つの判別器を使う。高い汎化能力があり、未知の話者でもWaveNet、WaveGlow、MelGANより品質が高い。実装が単純かつ高品質なためか、非常に多くの論文や音声合成のリポジトリで見かける。
Multi-band MelGAN: Faster Waveform Generation for High-Quality Text-to-Speech
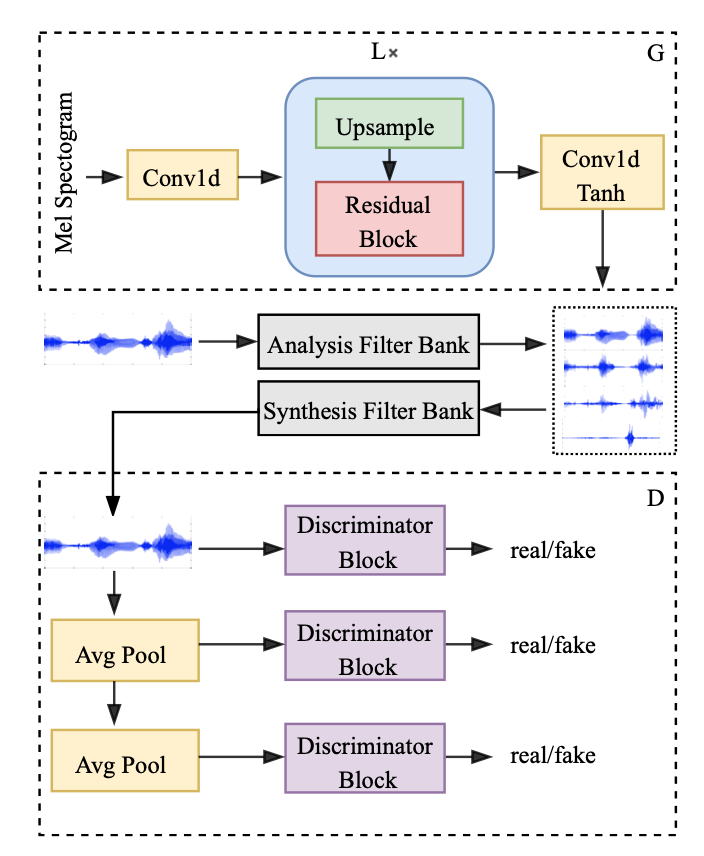
MelGANを、生成器の受容野の増強、多重解像度STFT損失の採用、サブバンド信号の加算による効率化で改善したもの。品質が大幅に改善したにも関わらず、計算量が大幅に少なくなり、CPUで0.03のRTFを達成した。
教師データの波形をFIRで複数のバンド(論文では4つ)に弁別し、それぞれのサブバンド信号を生成できるよう、サブバンドとフルバンドの両方で多重解像度STFT損失を取る。
DDSP: Differentiable Digital Signal Processing
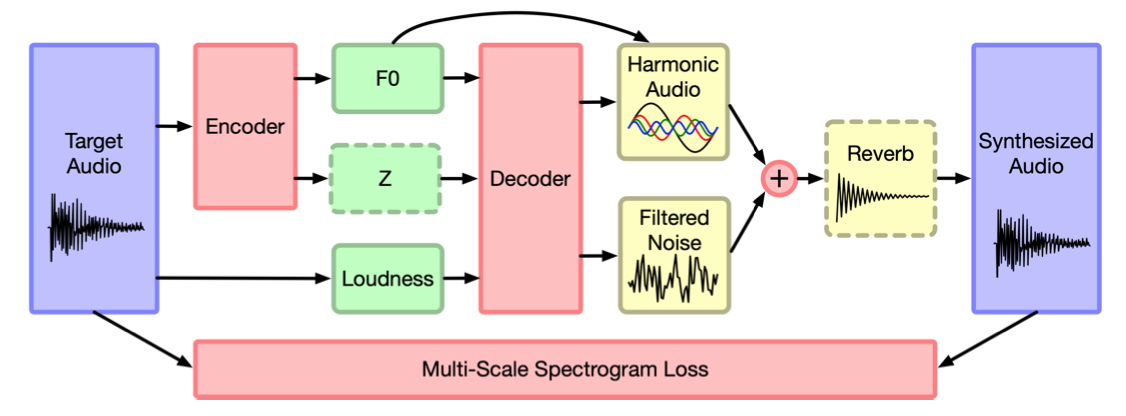
HiFI-GANやMelGANによってCPUでの実用的な速度での生成が達成された。ニューラルボコーダーはその後、音声波形の性質を利用した品質の安定化や効率化が確立されていくことになる。
従来の一定長のフレームごとの波形を生成するモデルは位相の位置合わせの問題があり、フーリエ変換をベースとしたモデルもスペクトル漏れを起こし、回帰的なモデルも学習に効率性がない。そこで、波形やフーリエ係数ではなくDSPの入力をニューラルネットワークに推定させることでこれらの問題を解決する。
コントリビューターを歓迎しており、Tensorflowで実装された公式のリポジトリでは使用者に柔軟な選択肢が与えられている。ニューラルネットワークの入力に多くのオプションがあり、オートエンコーダーとして用いることができる。DDSPを用いたプラグインなどの開発も行われている。
WaveNetやWaveRNNより遥かにモデルが小さく高速であり、CPUや組み込みデバイスでも有望である。
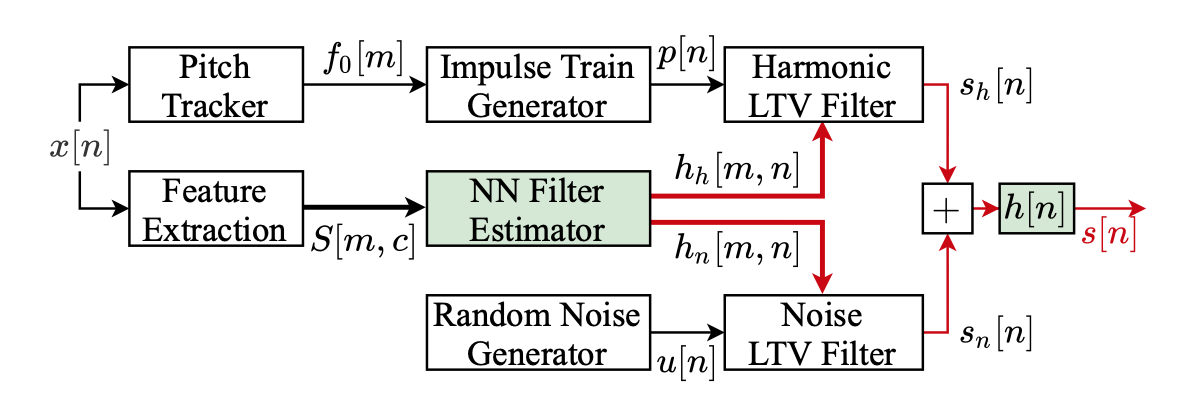
F0の入力は必須であり、オシレーターは正弦波を倍音で加算することで波形を生成する。DDSPモデルの一例として周期性成分と非周期性成分を加算して音声を生成するモデルが示され、周期性成分は正弦波の加算で、ノイズはLTVフィルターでガウシアンノイズをフィルタリングする。
Neural Homomorphic Vocoder
メルスペクトログラムから複素ケプストラムを推定し、iDTFTによって周期性成分の1周期分の波形と非周期性成分を得る。周期性成分は、F0から生成したパルスと複素ケプストラムから生成した波形を畳み込むことで生成される。非常に低い計算コストで、Parallel WaveGANを超えうる品質が得られた。
原理的に入力されるF0に完全に従う。推定する複素ケプストラムの次元は多すぎるとかえって有害とされる。入力に帯域を制限した特殊なメルスペクトログラムが使われているが、このアイデアは一般的にはならなかったようだ。
StyleMelGAN: An Efficient High-Fidelity Adversarial Vocoder with Temporal Adaptive Normalization
軽量なGANモデルはWaveNetやWaveGlowに品質の点で劣っており、軽量なままさらなる高品質化を目指した。各層でメルスペクトログラムと前段の出力を入力するTADE(Temporal Adaptive DE-normalization)ResBlockでノイズを波形に変換していく。
WaveGrad: Estimating Gradients for Waveform Generation
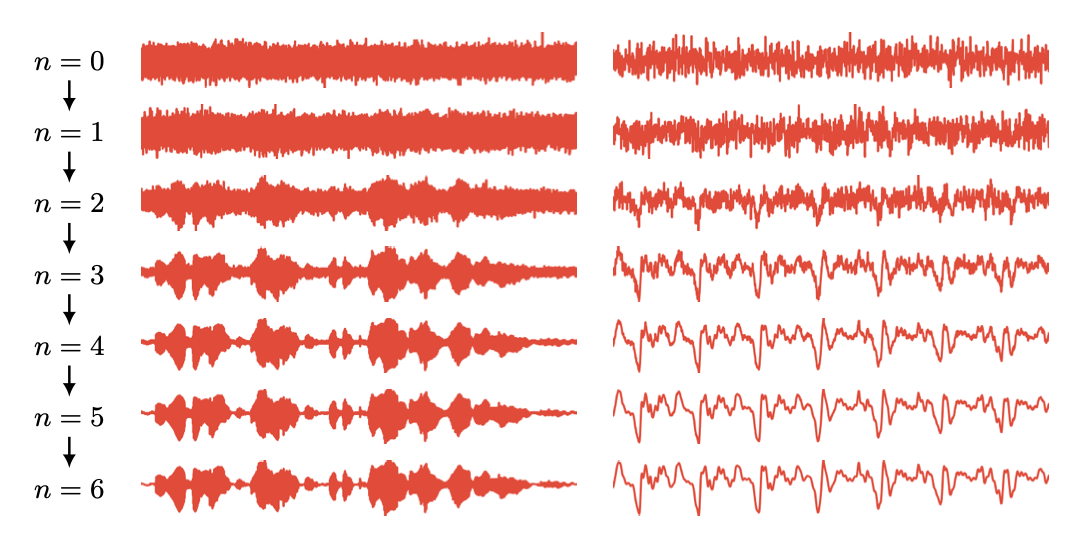
Diffusionを使った生成モデル。わずか6ステップで高品質な音声が生成可能であることを示し、CPUでも1.5のRTFに達した。
Diffusionの発展に従って、ニューラルボコーダーにこの技術が導入されるのは自然な流れだろう。実装されたソースコードを見ると驚くほど短い。将来的には、より高速で実用的なDiffusionのニューラルボコーダーが生まれていくと思う。
後のWaveGrad2では、ボコーダーとしてのみでなくTTSシステムとして進化を遂げている。
VocGAN: A High-Fidelity Real-time Vocoder with a Hierarchically-nested Adversarial Network
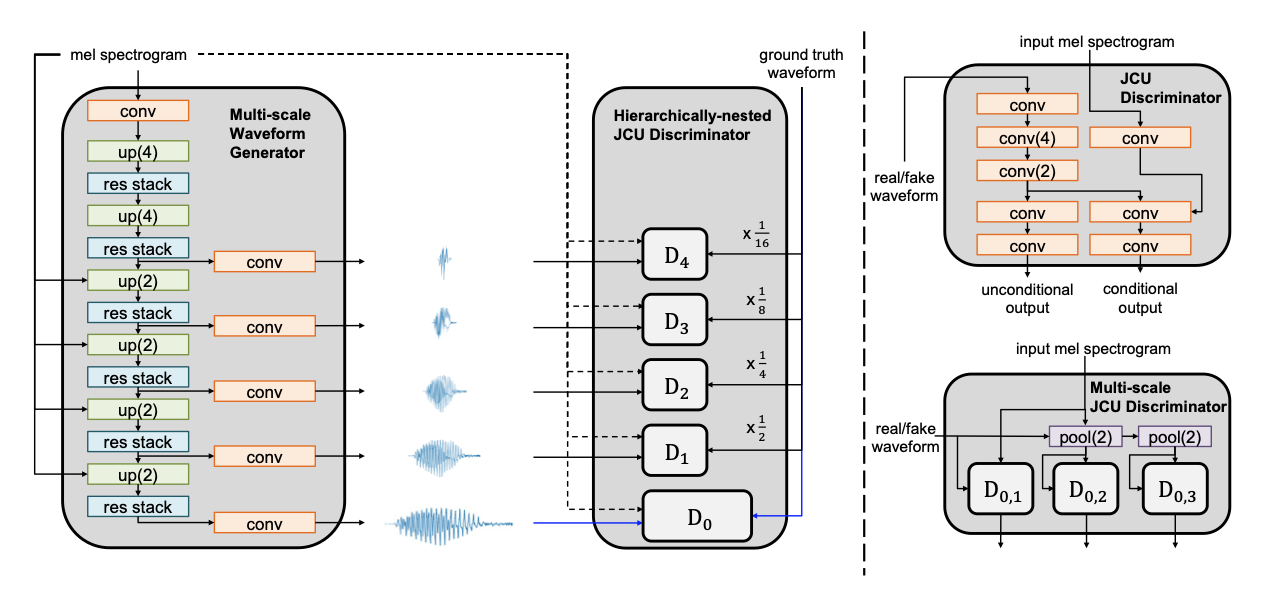
MelGANをベースにしつつ、アップサンプリングの過程毎に波形やメルスペクトログラムをdiscriminatorにかけるという手法で、MelGANの計算量をほぼ増やさず品質を向上させた。アップサンプリングを行っていく手法ならではの学習方法だろう。
2021年
PeriodNet: A non-autoregressive waveform generation model with a structure separating periodic and aperiodic components
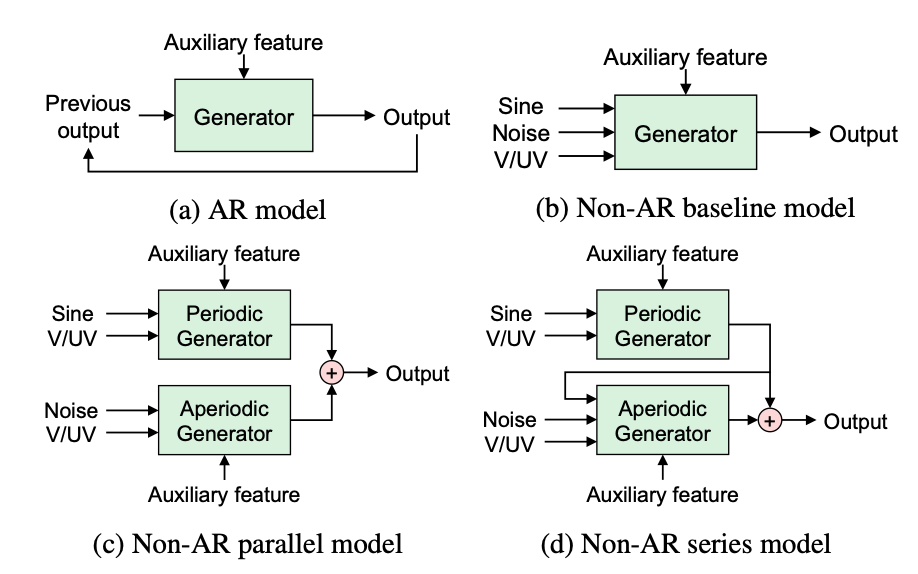
Parallel WaveGANのgeneratorをベースに、周期的成分と非周期的成分についての情報が明示的に入力する形での歌声合成向けの非自己回帰型のニューラルボコーダーを検討した。(訓練時に周期的成分と非周期的成分に分解することはない)。前述の前提で、generatorに正弦波の励起信号とパルスを同時に入れる場合、周期的成分と非周期的成分を別々に生成して加算する場合、周期的成分を生成してからその結果を入力に非周期的成分を加えた波形をgeneratorなど、様々な構成を検討しているが、教師データの範囲外のF0の対応力を考慮すると、周期的成分と非周期的成分を別々に生成して加算する場合がよい結果を得た。
UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
ほとんどのニューラルボコーダーはフルバンドに最適化されておらず、過度な平滑化が見られる。multi-period discriminatorと多重解像度STFTをdiscriminatorに駆ける方法を併用し、品質を向上させた。
ごく近年まで、音声合成で使う周波数はフルバンドより小さいことが多かったが、品質や速度が高くなるにつれ、フルバンドを前提としたボコーダーが多くなっている。
DiffWave: A Versatile Diffusion Model for Audio Synthesis
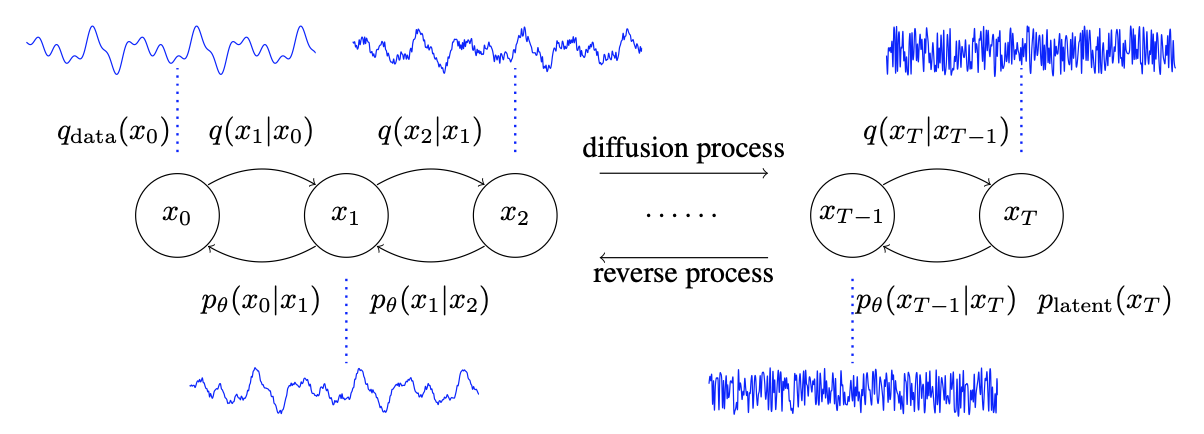
Diffusionの手法を用い、ホワイトノイズを波形に変換していく。GANを使う手法と違いモード崩壊の危険性がなく、最高品質の音声合成を行うことができる。CPUでのリアルタイムの合成には向かない。
メルスペクトログラムを入力とした音声合成だけでなく、ノイズ除去やクラス条件付きの生成タスクを行うこともでき、汎用的な生成ができる最初のモデルであるとされる。
Full-band LPCNet: A real-time neural vocoder for 48 kHz audio with a CPU
LPCNetにいくつかの変更を加え、48kHzの波形をCPUでリアルタイムに合成できるようにした。モデルの変更点はGRUのパラメータ数のみとし、入力(BFCC)の次元を増やした。
2022年
iSTFTNet: Fast and Lightweight Mel-Spectrogram Vocoder Incorporating Inverse Short-Time Fourier Transform
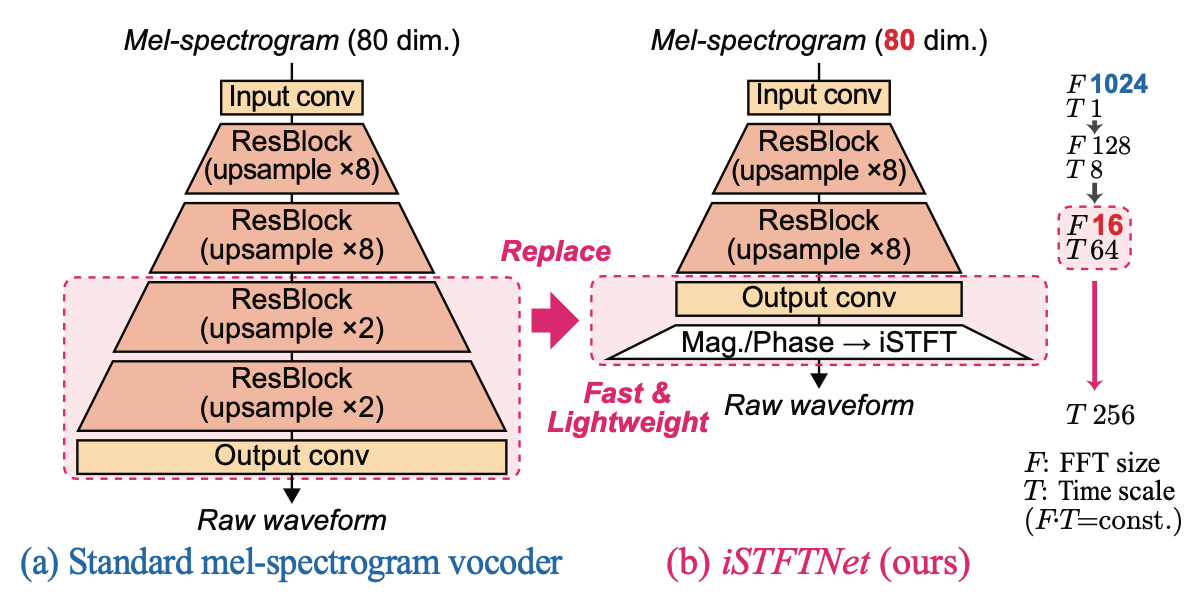
メルスペクトログラムをアップサンプリングして波形に変換していくボコーダーの出力部分をiSTFT(逆短時間フーリエ変換)に置き換えたもの。Multiband MelGANよりさらに高速、高品質な合成ができる。アップサンプリングのみでの変換は冗長な計算が含まれている。著者によると、22.05kHzの波形の生成時は二回の8倍のアップサンプリングで得られたものをiSTFTするのがバランスがよいだろうとのこと。
RefineGAN: Universally Generating Waveform Better than Ground Truth with Highly Accurate Pitch and Intensity Responses
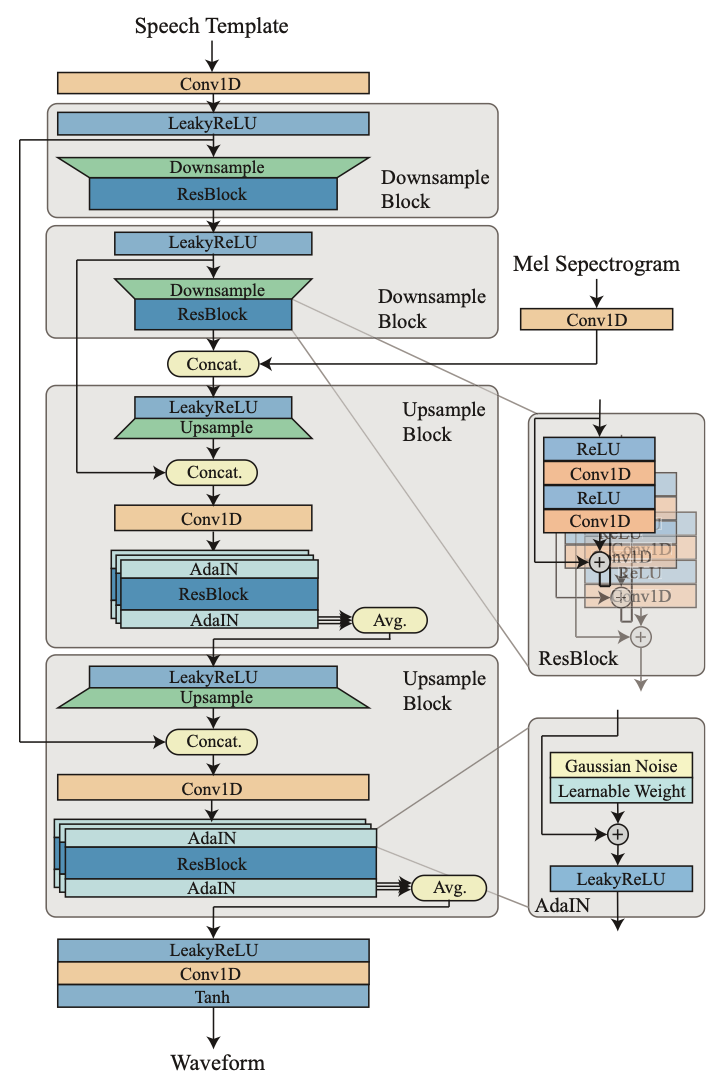
MOS評価で元音声を超えた品質が得られたとされ、RefineGANと名付けられている。歌声合成を目的として作られており、ピッチと音量に高い制御性を持ち、様々な話者の声を再現する汎化性能がある。ACE Studioで用いられており、品質の高さは実証済みであるといえる。
speech templateという仕組みを用いており、F0の有声区間ではF0に応じたパルスが、無声区間ではホワイトノイズがまず生成される。これをメルスペクトログラムを条件としたニューラルネットワークで波形に変換していく。これは、F0推定器の性能の限界によって、音声を有声区間と無声区間に分けなければいけないという状況下で、可能な限り品質を向上させるための施作だろう。
構成そのものよりも学習方法に重要性があるように思う。訓練中、教師データをランダムに伸長させる。教師データのF0の推定方法に多くの模索が行われている。損失関数に波形の包絡線の差を与える手法が使われている。
SingGAN: Generative Adversarial Network For High-Fidelity Singing Voice Generation
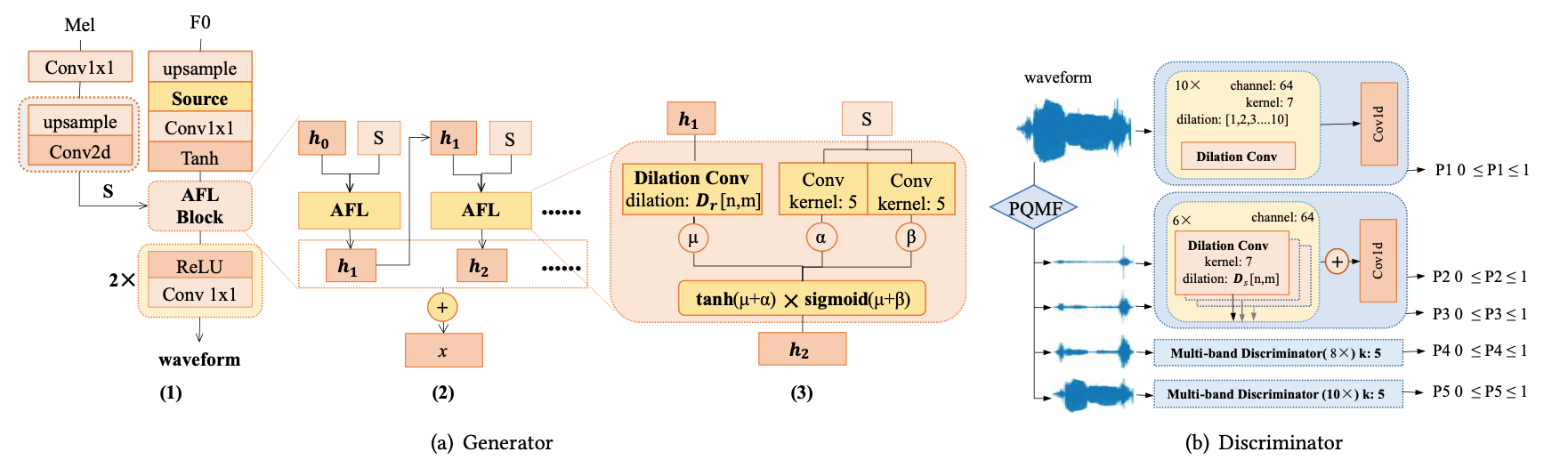
MelGAN、Parallel WaveGAN、WaveRNNなどではロングトーンで不連続な波形が生成されやすく、連続性を学習するのに大きな受容野が必要とされる。また、高いサンプリングレートで高周波数の再現性を得難い。
これに対応するため、正弦波(有声区間)とノイズ(無声区間)の励起信号を波形に変換し、解析的な損失としては、多重解像度STFT損失と多重解像度メルスペクトログラム損失を足した補助スペクトログラム損失を用いる。高周波数での再現度を得るために補助スペクトログラム損失が有効であることを示している。
無声区間と有声区間で動作を変えるのではなく、ニューラルネットワークに入力する励起信号を変えるという点でRefineGANと似ている。
HiFi-WaveGAN: Generative Adversarial Network with Auxiliary Spectrogram-Phase Loss for High-Fidelity Singing Voice Generation
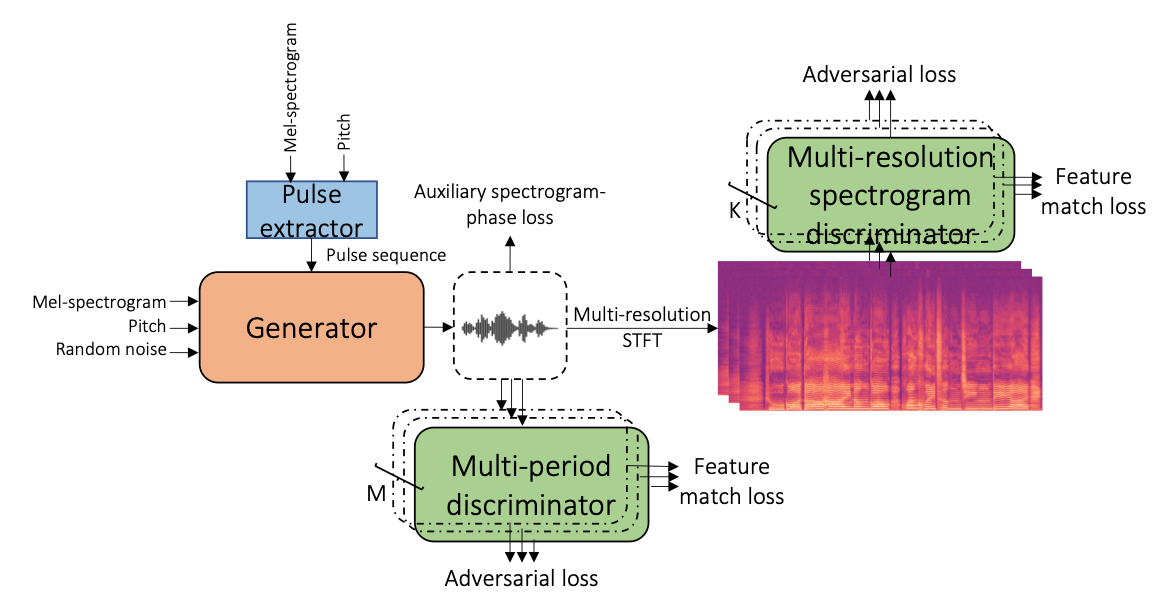
歌声合成に特化したニューラルボコーダー。メルスペクトログラムとF0からパルス列を生成し、これとメルスペクトログラム・F0・ランダムノイズを生成器に与える。学習可能なパルス列の励起が波形のアーティファクトを改善したとしている。Neural Homomorphic Vocoder、RefineGAN、SingGANは機械的に励起信号を生成するが、このパルス列の励起がさらなる柔軟性を与えていると思われる。新しい損失関数として補助スペクトログラム位相損失を使うことで、使わない場合より遥かに速くモデルが収束する。
DSPGAN: a GAN-based universal vocoder for high-fidelity TTS by time-frequency domain supervision from DSP (arxiv.org)
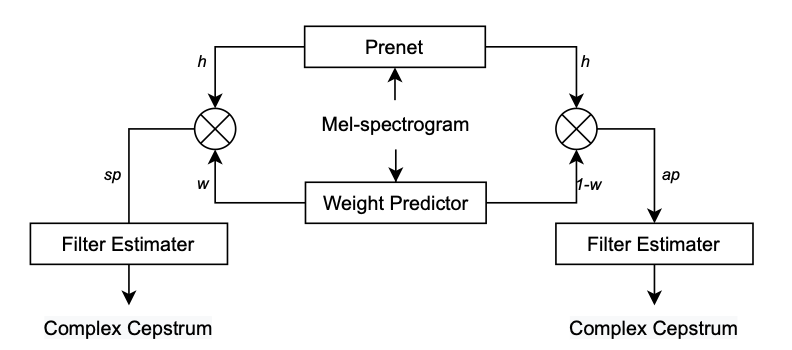
Neural Homomorphic Vocoderと似ているが、周期的成分と非周期的成分のウェイトを予測する機構が足され、パルス列ではなく正弦波励起によって周期的成分が合成される。正弦波励起によって機械的な響きを避けられるとしている。
『Quasi-Periodic』な一連のニューラルボコーダーについて
戸田研究室はQuasi-Periodic(音高に応じてニューラルネットワークの受容野を変更する)なニューラルボコーダーをいくつか発表しており、PyTorch実装も公開されているので試せる状態になっている。しかし、それらの論文の内容は難解でコンセプトもあまり理解することができなかった。uSFGANやSiFi-GANはNNSVSに採用され、品質の向上に一役買っているのだろう。下にそれらの論文を列挙するので、真価の分かる方の目に触れればと思う。
Quasi-Periodic Parallel WaveGAN: A Non-autoregressive Raw Waveform Generative Model with Pitch-dependent Dilated Convolution Neural Network
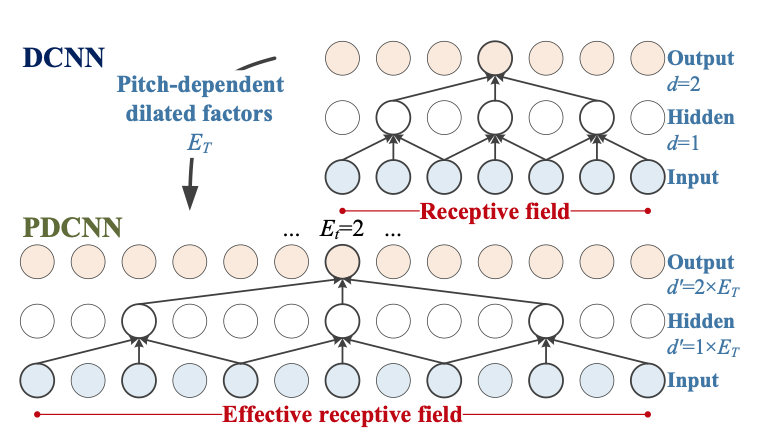
同じ著者による『Quasi-Periodic WaveNet: An Autoregressive Raw Waveform Generative Model with Pitch-dependent Dilated Convolution Neural Network』で提案された、音高に依存してCNNの受容野の長さを変える(dilationのサイズを変えるようにして変更する)というQuasi-Periodic構造のアイデアをParallel WaveGANに適用したもの。これによって音高の正確さと未知の入力への堅牢さが向上する。
損失関数やdiscriminatorは変更せず、generatorのみをQP構造を持つものに置き換える。論文では音声の情報としてF0、V/UV、35次元のメルケプストラム、非周期性指標を与えた。
Unified Source-Filter GAN with Harmonic-plus-Noise Source Excitation Generation

同著者によって『Unified Source-Filter GAN: Unified Source-filter Network Based On Factorization of Quasi-Periodic Parallel WaveGAN』(図上)が書かれ、そこではQuasi-Periodic Parallel WaveGANをソースネットワークとフィルターネットワークの2段階にし、ソース・フィルターモデルとして使う手法が示されていた。その後、非周期性成分の品質向上のため、ハーモニックプラスノイズモデルへの改造を行い、さらに大幅に品質が向上することを示した。
Source-Filter HiFi-GAN: Fast and Pitch Controllable High-Fidelity Neural Vocoder

入力されたF0に忠実になるよう、HiFi-GANとソース・フィルターモデルの考え方を融合させ、CPUでの歌声合成でuSFGANよりさらに優れた品質と合成速度を得た。
ソースネットワークの励起信号を普通にダウンサンプリングするのではなく、ダウンサンプリングCNNを通してフィルターネットワークの各層に与えることで高周波成分も明瞭になりやすかった。ダウンサンプリングCNNが、各時間分解能に対してより扱いやすい高調波情報を提供しているとしている。
まとめ
他の生成モデルと同様、ニューラルボコーダーは瞬く間に刷新が行われ、栄枯盛衰のように感じる。最近は音声の音高や位相を正確に得る手法も提案され、さらなる革新が起こっていくと思われる。
文献上では一般的に平坦に読み上げられた音声のMOS値で評価されるものの、人の感受性に訴え、感動を与えることが真の主観的評価であり、裁定が難しいものだと思わずにはいられない。Diffusionによる音響特徴量の生成が進むことで、音声合成は不気味の谷を越え、より人に深くプリミティブな感動や愛着を与えるものになるだろう。
合成音声を学び始めて以来、その奥深さや声を生成することへの研究者達の情熱に驚かされていた。多くの人は、合成技術そのものではなく、コンテンツを作成する人の想いに感動するのだと思われるが、合成技術自体にも人間の魂がこもっているように私には感じられた。初学者の意見ではあるが、共感してもらえる方がいれば幸いである。