2018/11/22にarXivに投稿された論文「Data Augmentation using Random Image Cropping and Patching for Deep CNNs」で、CNNの新しいdata augmentation手法である**RICAP (Random Image Cropping And Patching)**が提案されています。
シンプルな手法ですがCIFAR-10でSOTAなエラー率2.19%を達成したということで試してみました。
PyTorchによる実装はこちら
https://github.com/4uiiurz1/pytorch-ricap
RICAP
RICAPは以下の図のように、4つの異なる学習画像からランダムにクロップした画像を継ぎ合わせて新たな学習画像を生成するdata augmentation手法です。
 [Data Augmentation using Random Image Cropping and Patching for Deep CNNs](https://arxiv.org/abs/1811.09030)
[Data Augmentation using Random Image Cropping and Patching for Deep CNNs](https://arxiv.org/abs/1811.09030)
RICAPによるdata augmentation
まず、学習セットから4つの画像をランダムに選択します。
次に各画像からクロップするサイズを求めるために、以下の式のようにして図中の$(w,h)$をベータ分布$Beta(\beta,\beta)$からランダムに決定します。
w = \text{round}(w^{'}I_x), \hspace{5pt}h = \text{round}(h^{'}I_y), \\
w^{'} \sim Beta(\beta,\beta), \hspace{5pt}h^{'} \sim Beta(\beta,\beta)
$I_x, I_y$はそれぞれオリジナルの学習画像の幅と高さです。
$\beta$はハイパーパラメータです。CIFAR-10では$\beta=0.3$が最適だったようです。
4つの画像のサイズ$(w_k,h_k)$は$(w,h)$から自動的に求まります。
(w_1,h_1)=(w,h),\hspace{5pt} (w_2,h_2)=(I_x-w,h),\hspace{5pt}(w_3,h_3)=(w,I_y-h),\hspace{5pt}(w_4,h_4)=(I_x-w,I_y-h)
そして、各画像のどの部分をクロップするか決定するために、クロップする領域の左上の位置$(x_k,y_k)$を以下の式のように一様分布からランダムに求めます。
x_k \sim U(0,I_x-w_k),\hspace{5pt} y_k \sim U(0,I_y-h_k)
最後に、生成した画像のラベルを求めます。
以下の式のように、各画像のラベルをそれぞれが生成画像に対して占める面積の割合で混ぜ合わせたものが生成画像のラベルになります。
c = \sum_{k\in\{1,2,3,4\}} W_k c_k \hspace{5pt} \text{for} \hspace{5pt} W_k = \frac{w_k h_k}{I_x I_y}
実装
RICAPの実装例が論文のAppendixに載っているため、それを参考に書きました。
for i, (input, target) in tqdm(enumerate(train_loader), total=len(train_loader)):
# from original paper's appendix
if args.ricap:
I_x, I_y = input.size()[2:]
w = int(np.round(I_x * np.random.beta(args.beta, args.beta)))
h = int(np.round(I_y * np.random.beta(args.beta, args.beta)))
w_ = [w, I_x - w, w, I_x - w]
h_ = [h, h, I_y - h, I_y - h]
cropped_images = {}
c_ = {}
W_ = {}
for k in range(4):
idx = torch.randperm(input.size(0))
x_k = np.random.randint(0, I_x - w_[k] + 1)
y_k = np.random.randint(0, I_y - h_[k] + 1)
cropped_images[k] = input[idx][:, :, x_k:x_k + w_[k], y_k:y_k + h_[k]]
c_[k] = target[idx].cuda()
W_[k] = w_[k] * h_[k] / (I_x * I_y)
patched_images = torch.cat(
(torch.cat((cropped_images[0], cropped_images[1]), 2),
torch.cat((cropped_images[2], cropped_images[3]), 2)),
3)
patched_images = patched_images.cuda()
output = model(patched_images)
loss = sum([W_[k] * criterion(output, c_[k]) for k in range(4)])
acc1 = sum([W_[k] * accuracy(output, c_[k])[0] for k in range(4)])
このコードを用いると以下のような画像が生成されます。

実験
論文と同じ設定でCIFAR-10について性能評価を行います。
使用するモデルはWideResNet 28-10です。
デフォルトのdata augmentationとして、RandomCropとRandomHorizontalFlipを使います。
結果
テストデータに対するエラー率は以下のようになりました。
| Method | Error rate (%) |
|---|---|
| baseline | 4.70 |
| +RICAP | 3.94 |
| baseline (original paper) | 3.89 |
| +RICAP (original paper) | 2.85 |
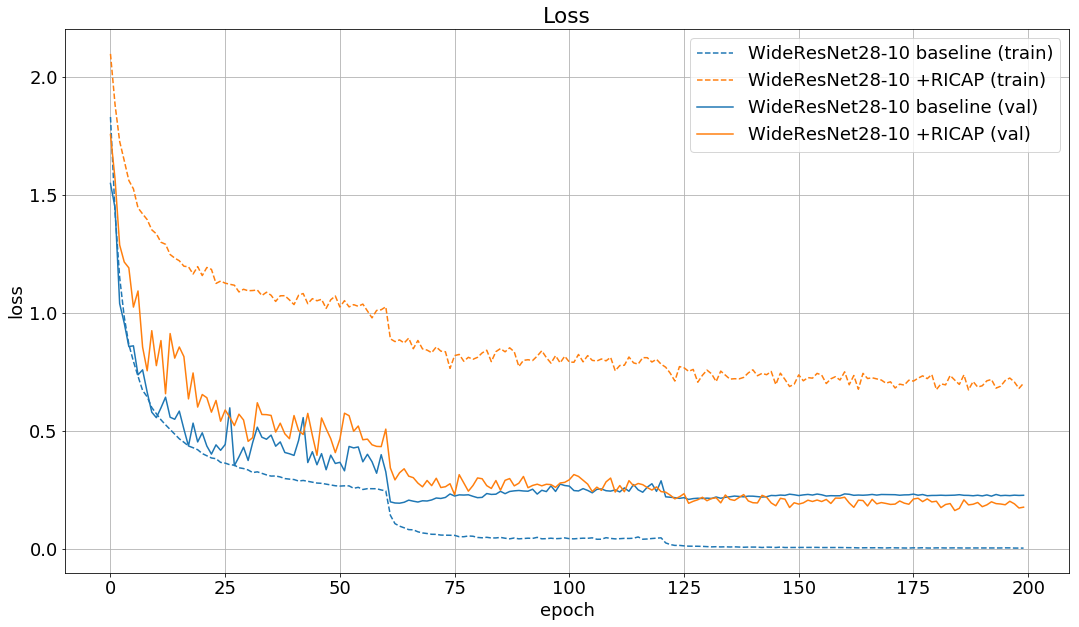
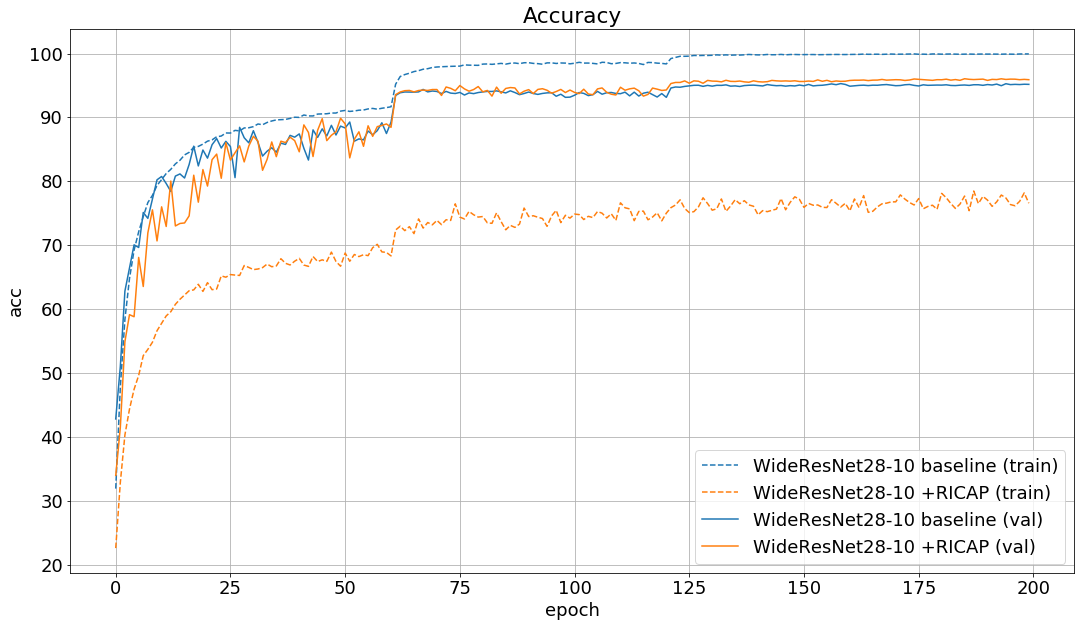
論文の結果と同じようにbaselineから約1%改善しました。
論文ではさらに、Shake-Shake reguralizationを使ったモデルにRICAPを用いることで2.19%を達成したそうです。
学習時のlossとaccuracyの推移は以下の通りです。
まとめ
今回の実験では一回のみの試行でしたが、RICAPは精度向上に効果がありそうです。
論文ではCIFAR-10以外のデータセットや分類以外のタスクでも良い結果が出たみたいなので、モデルの学習を行う際にはとりあえず試してみると良いかもしれません。
追記 (2018/11/30)
Random ErasingとMixupについても論文と同じ設定で試してみました。
テストデータに対するエラー率とlossは以下のようになりました。
| Model | Error rate (%) | Loss |
|---|---|---|
| WideResNet28-10 baseline | 4.70 | 0.193 |
| WideResNet28-10 +RICAP | 3.94 | 0.162 |
| WideResNet28-10 +Random Erasing | 4.36 | 0.163 |
| WideResNet28-10 +Mixup | 4.09 | 0.232 |
| WideResNet28-10 baseline (original paper) | 3.89 | - |
| WideResNet28-10 +RICAP (original paper) | 2.85 | - |
| WideResNet28-10 +Random Erasing (original paper) | 4.65 | - |
| WideResNet28-10 +Mixup (original paper) | 3.02 | - |
論文の結果と同じように、RICAPを使用したモデルが最も良いエラー率とlossを出しました。
学習時のlossとaccuracyの推移は以下の通りです。
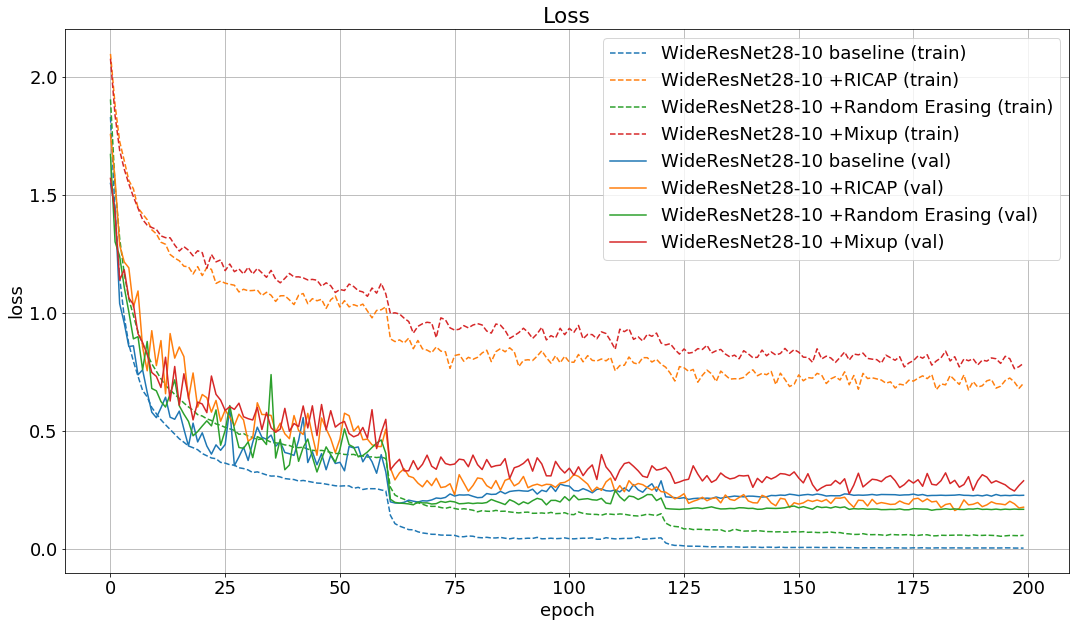
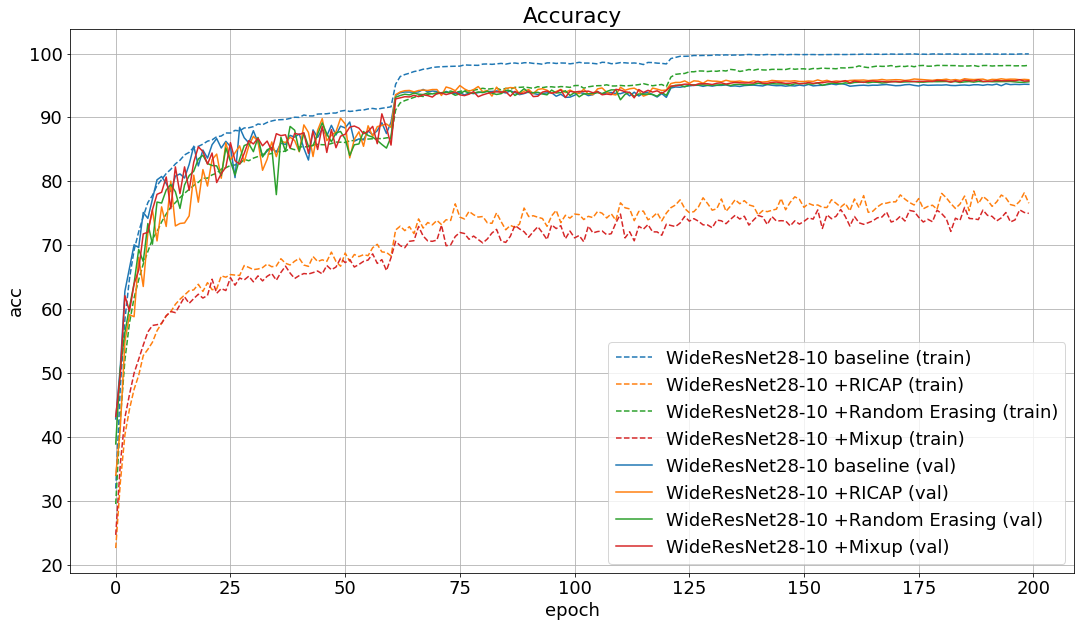
RICAPとMixupは手法が似ているためかlossとaccuracyの推移も似ていますね。