2018/11/21にarXivに投稿された論文「Rethinking ImageNet Pre-training」を読みました。
著者:
Kaiming He (Facebook AI Research), Ross Girshick (Facebook AI Research), Piotr Dollar (Facebook AI Research)
Abstract
- スクラッチから学習したMask R-CNNを使用して、COCOデータセットのオブジェクト検出とインスタンスセグメンテーションを行う。
- スクラッチモデルはほとんどの場合に、pre-trainedモデルと同等の精度を示した。
- スクラッチからの学習は驚くほどロバスト。
- ImageNetによる事前学習は学習の収束を早めるが、必ずしも正則化効果を与えたり精度を向上させるわけではない。
- 外部データを使用せずにCOCOオブジェクト検出で50.9 APを達成。これは事前学習済みモデルを使用したCOCO 2017 competitionのトップの結果と同等。
4. Experimental Settings
- 基本的にベースラインとハイパーパラメータは、公開されているMask R-CNNの実装コードに従う。
- 変更するのはNormalization手法と学習の際の反復回数。
Architecture.
- Batch Normalization(BN)の代わりにGroup Normalization(GN)もしくはSynchronized Batch Normalization(SyncBN)を使う。
Learning rate scheduling.
- learning rateのスケジューリングを色々と変えて試す。
- 基準となる反復回数は90k反復。
- 学習の最後から60k反復と20k反復でlearning rateを下げる。
5. Results and Analysis
5.1. Training from scratch to match accuracy
- スクラッチモデルがpre-trainingモデルと同等の精度を出した。
- 学習には約118kの画像を持つCOCO train2017、 評価には5kの画像を持つCOCO val2017を用いる。
- 物体検出の評価指標としてbounding box (bbox) Average Precision (AP)、セグメンテーションの評価指標としてmask APを用いる。
Baselines with GN and SyncBN.
- backbone: ResNet-50, Normalization: GN
 - backbone: ResNet-101, Normalization: GN
- backbone: ResNet-101, Normalization: GN
 - backbone: ResNet-50, Normalization: SyncBN
- backbone: ResNet-50, Normalization: SyncBN
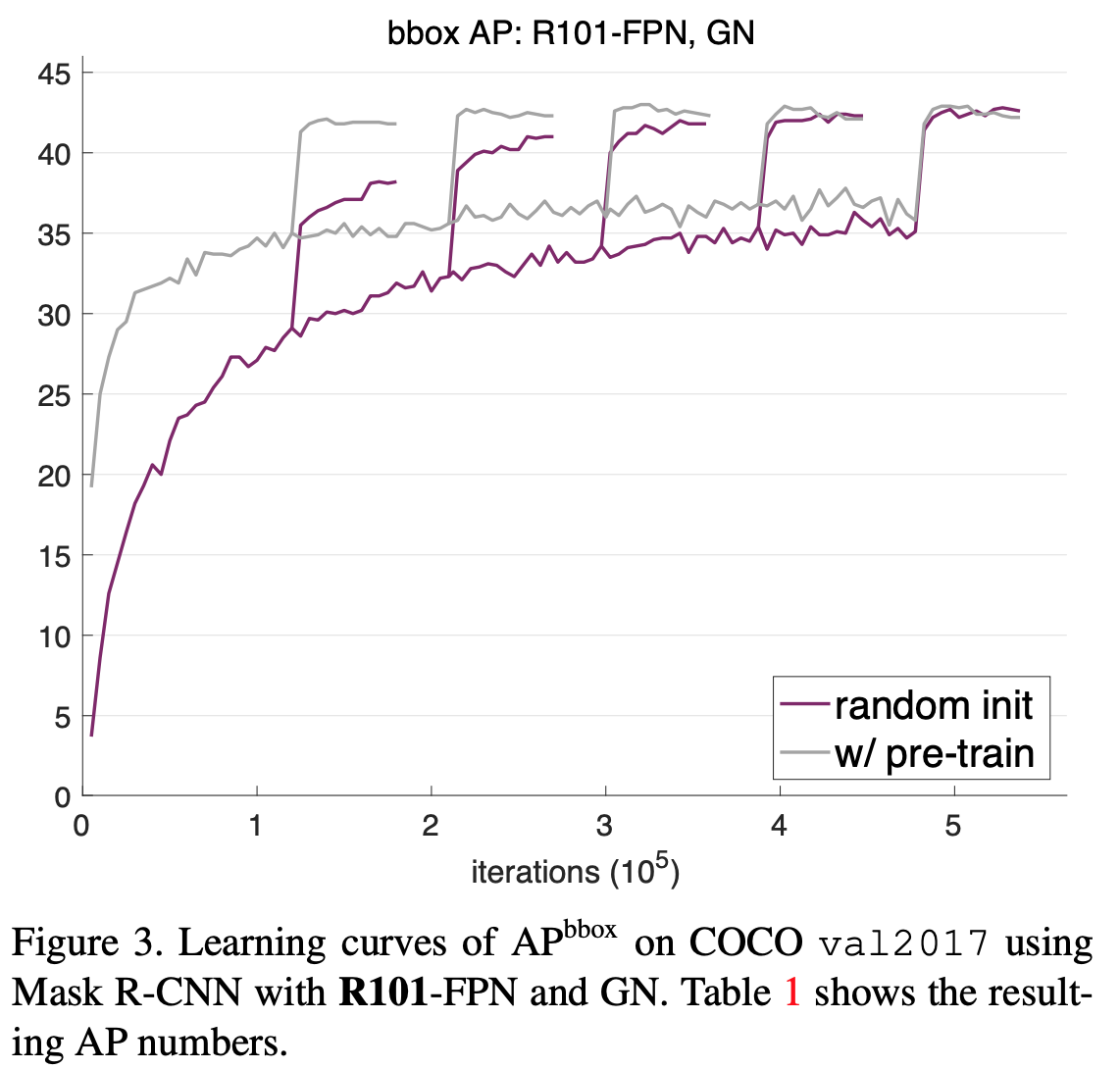
 - それぞれについて2×90~6×90反復の5つの異なるスケジューリングを試す。
- 各図は1つのモデルの5つのスケジューリングを一つの図にプロットしたもの。
- それぞれについて2×90~6×90反復の5つの異なるスケジューリングを試す。
- 各図は1つのモデルの5つのスケジューリングを一つの図にプロットしたもの。
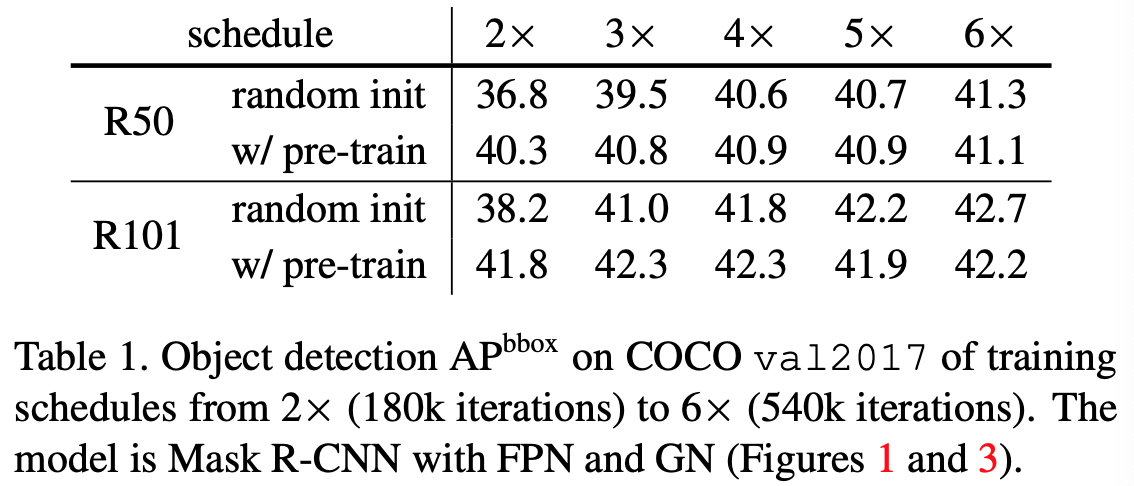
- 2×90反復のスケジューラを用いた場合、pre-trainingモデルは最適な値に収束しているが、スクラッチモデルは十分に収束していない。
- 5×90または6×90反復のスケジューラを用いた場合スクラッチモデルは最適な値に収束しており、精度もpre-trainingモデルに匹敵する。
- この結果から、ImageNetによる事前学習済みモデルは学習の収束を早めることがわかる。
Multiple detection metrics.
- 別の評価指標による比較。

Enhanced baselines.
- data augmentationなどによってベースラインを改良した場合について検証。

Large models trained from scratch.
- より大きなモデルをスクラッチから学習した場合について検証。
- backboneにResNeXt-152 8×32dを用いる。
 - **興味深いことにpre-trainingモデルを用いた場合は精度が改善しなかった**。
- **興味深いことにpre-trainingモデルを用いた場合は精度が改善しなかった**。
vs. previous from-scratch results.
- 本論文のスクラッチモデル全てが、他の論文で報告されているスクラッチからの学習結果よりも高い精度を示している。
Keypoint detection.
- キーポイント検出用に学習した場合を検証。
 - スクラッチモデルの精度が他の結果よりも早くpre-trainedモデルに追いついている。
- キーポイント検出では位置推定が重要。
- **この結果から、ImageNetによる事前学習済みモデルは位置推定に関する情報をはっきりと持っているわけではないので、キーポイント検出の助けにはならないことがわかる。**
- スクラッチモデルの精度が他の結果よりも早くpre-trainedモデルに追いついている。
- キーポイント検出では位置推定が重要。
- **この結果から、ImageNetによる事前学習済みモデルは位置推定に関する情報をはっきりと持っているわけではないので、キーポイント検出の助けにはならないことがわかる。**
Models without BN/GN — VGG nets.
- VGG-16のようなもっと浅いモデル、かつ適切なNormalizationやInitializationを行わない場合について検証。
- pre-trainedモデルの精度に追いつくまでより長い反復回数(11×90k反復)が必要。
5.2. Training from scratch with less data
- 大幅に少ないデータ(全体の1/10)を用いた場合でもスクラッチモデルはpre-trainedモデルと同等の精度を示した。

35k COCO training images.
- 全体の1/3にあたる35kの画像のみを用いた場合について検証。
- 全てのデータセットを使った場合と同じハイパーパラメータで学習を行うと、過学習を起こした。(Figure 7 左)
- pre-trainedモデルにとって最適なハイパーパラメータをグリッドサーチで探索し、それをスクラッチモデルにも用いる。
- 明らかにpre-trainedモデルに有利な条件だが、スクラッチモデルの精度は6×90k反復でpre-trainedモデルに追いついた。(Figure 7 中央)
10k COCO training images.
- 全体の1/10にあたる10kの画像のみを用いた場合についても同様に検証。
- スクラッチモデルの精度は220k反復でpre-trainedモデルに追いついた。(Figure 7 右)
Breakdown regime: 1k COCO training images.
- さらに少ない1kの画像のみを用いた場合についても同様に検証。
- lossについてはこれまでと同様にpre-trainedモデルの方が収束は早いが、反復を重ねることでスクラッチモデルも追いつく。
- しかし、lossは下がってもvalidation APは良くならず、pre-trainedモデルの9.9APに対してスクラッチモデルは3.5AP。
- スクラッチモデルにとって最適なハイパーパラメータを使うことで5.4APに改善したが、それでも全く追いつかなかった。
- 3.5kの画像のみを用いた場合についても同様に検証したが、pre-trainedモデルの16.0APに対してスクラッチモデルは9.3AP。
- COCOデータセットのbreakdown point(統計量が無意味になるデータの割合)は3.5kと10kの間のどこかにある。
Breakdown regime: PASCAL VOC.
- 別の物体検出用のデータセットとしてPASCAL VOCを使った場合について検証。
- pre-trainedモデルの82.7mAPに対してスクラッチモデルは77.6mAPとなり、同等の精度にはならなかった。
- VOCの学習データは15kあるため、これまでの実験結果を考えると十分に思える。しかし、画像一枚あたりの平均インスタンス数は2.3(COCOは7)、カテゴリ数は20(COCOは80)であるため、COCOと同じデータ数では比較できない。
- この結果から、少ないインスタンス数やカテゴリ数は十分な量ではないデータセットに対して悪影響を与えると推測できる。
6. Discussions
- スクラッチからの学習は構造的な変更をしなくても可能である。
- スクラッチからの学習は収束のためにより多くの反復回数を必要とする。
- スクラッチモデルは色々な条件においてpre-trainedモデルと同等の精度を示す。
- ImageNetによる事前学習は収束を早めることができる。
- ImageNetによる事前学習は非常に小さなデータセットである場合を除けば、過学習を防ぐために必ずしも役立つわけではない。
- 目的とするタスクにおいて分類よりも位置推定が重要である場合は、ImageNetによる事前学習はそんなに役に立たない。
ImageNetによる事前学習は必要不可欠? -- いいえ
- 論文の実験はImageNetが収束を早めることができるが、学習データが少なすぎる場合を除いて必ずしも精度を向上させるとは限らないことを示している。
- 十分な量の学習データ(および計算)があればいい。データセットが十分に大きい場合は、学習データを直接使うだけで十分。
- 学習データのannotationを収集するのに注力することの方が、目的のタスクのパフォーマンスを向上させる上でより効果的であることを示唆している。
ImageNetは有益? -- はい
- ImageNetによる事前学習は、コンピュータビジョンコミュニティが進展するための重要なタスク。
- 大規模なデータが利用可能ではないタスクにおいても大きな改善が見られるようになった。
- 学習における問題(有用な初期化手法や正規化手法がないなど)を回避するのにも大いに役立った。
- ImageNetによる事前学習により研究サイクルが短縮され、訓練されたモデルは今日広く自由に利用可能であり、訓練前のコストは繰り返し支払う必要はなく、事前学習済みモデルを使ったfine-tuningはスクラッチ学習よりも早く収束する。
- これらの利点により、ImageNetは間違いなくコンピュータビジョンの研究に役立つ。