タイトルについて、日本語の情報があまりなかったので書いてみました。
知っておくと、BIツールとの連携が広がるのかな..と思いました。
と言いながら、すべてローカル環境で完結する手順になってます。
HDFSは利用していません。ですが、Sparkクラスタ環境の場合でも大きく手順は変わらないと思います。
私の動作環境は、以下の通りですが、古くても動くと思います。
- Mac Mojave
- jdk 1.8
- spark 2.4.0
- PostgreSQL 11.2
事前準備
すでに準備ができていれば不要です。
Spark 2.4.0ダウンロード
cd ~
# ダウンロード
curl -O http://ftp.kddilabs.jp/infosystems/apache/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
# 解凍
tar xvfz spark-2.4.0-bin-hadoop2.7.tgz
# シンボリックリンクの作成
ln -s $HOME/spark-2.4.0-bin-hadoop2.7 $HOME/spark
環境変数の設定
echo 'export SPARK_HOME=$HOME/spark' >> ~/.bash_profile
echo 'export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin' >> ~/.bash_profile
source ~/.bash_profile
PostgresSQLドライバのダウンロード
メタストアのデータベースに今回PostgreSQLを使いたいので、ドライバをダウンロードしておきます。
curl -LO https://jdbc.postgresql.org/download/postgresql-42.2.5.jar
# ここは色々な方法がありますが、今回はめんどくさいためjars配下に直接コピーします。
cp postgresql-42.2.5.jar $SPARK_HOME/jars/
メタストア用の設定
PostgreSQLにメタストア用のデータベースを作成
メタストア用のデータベースをPostgresに作成します。
データベース名は何でも大丈夫ですが、今回metastore_dbという名前で作成します。
psql -d postgres
psql (11.2)
Type "help" for help.
postgres=# create database metastore_db
CREATE DATABASE
hive-site.xmlの設定
$SPARK_HOME/conf/hive-site.xmlを以下のように作成します。
valueの部分は読み替えてください。
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:postgresql://localhost:5432/metastore_db</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.postgresql.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>usename</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
</property>
</configuration>
spark-defaults.confの設定
$SPARK_HOME/conf/spark-defaults.confに以下の設定を足しておくと、
後のspark-sqlコマンドを実行した時にPostgreSQLに接続できるようになるので、入れておきます。
spark.jars /path/to/me/postgresql-42.2.5.jar
spark.driver.extraClassPath /path/to/me/postgresql-42.2.5.jar
ここまでで準備が終わったと思うので、
次は、実際にThriftServerを起動して、接続してみます。
Spark Thrift Server(STS)の起動
今回はローカルモードで起動します。
中身的には、spark-submitをしているっぽいです。
start-thriftserver.sh --master local
これで完了です。STSのプロセスが10000番ポートで起動していると思います。
Spark Thrift Server(STS)に接続してみる
以下の3通りの方法で接続確認してみました。
- データベースのクライアントツール(DBeaver)
- beeline
- spark-sql
以下、それぞれの手順について記載しています。
データベースのクライアントツールから接続してみる
今回は、データベースのクライアントツールとして、DBeaverから繋いでみることにしました。
(TeamSQLを前々から使っていたのですが、サポートが終わってしまっていたので、DBeaverを使っています。非常に便利でおすすめです。)
[DBeaver]
https://dbeaver.io/
接続手順については、画面キャプチャを参考にしてください。
接続タイプに"Apache Spark"を選択します。

データベース/スキーマ、ユーザ名/パスワードは入力しなくても接続できます。

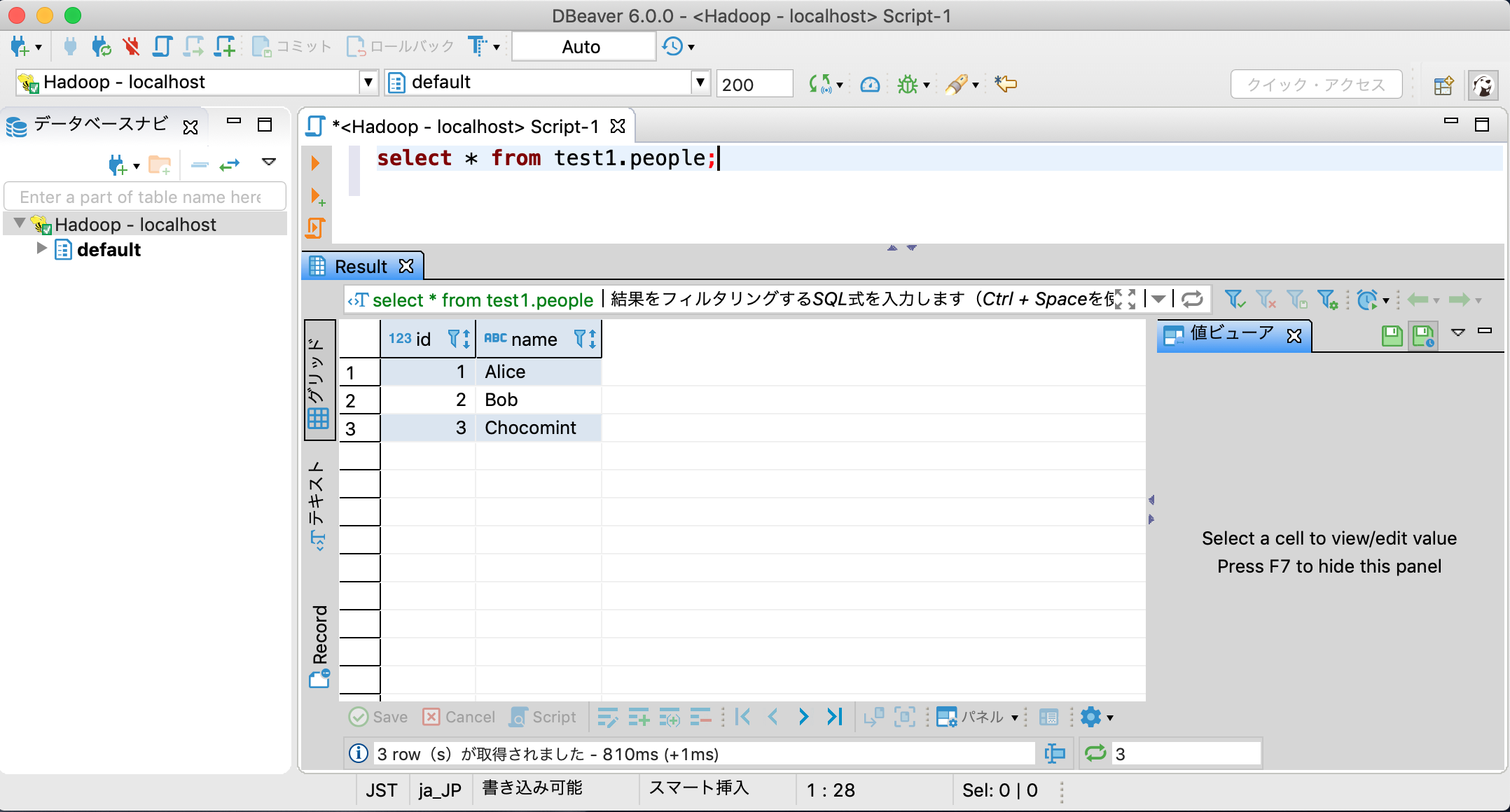
クエリを書いて実行してみます。

クエリが実行できれば目標達成です。
beelineから接続してみる
同梱のbeelineからも接続できます。
# 起動
beeline
Beeline version 1.2.1.spark2 by Apache Hive
# 接続
beeline> !connect jdbc:hive2://localhost:10000
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000:
Enter password for jdbc:hive2://localhost:10000:
...
Connected to: Spark SQL (version 2.4.0)
Driver: Hive JDBC (version 1.2.1.spark2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000>
0: jdbc:hive2://localhost:10000> create database test2;
0: jdbc:hive2://localhost:10000> create table test2.test(id int, name varchar(20));
0: jdbc:hive2://localhost:10000> insert into test2.test values (1, 'chocomint'), (2, 'kusoyaro');
0: jdbc:hive2://localhost:10000> select * from test2.test;
spark-sqlから接続してみる
同梱のspark-sqlからも接続できます。
# 起動
spark-sql
# spark-defaults.confに設定を追加していない場合は、以下のように起動します。
spark-sql --jars /path/to/me/postgresql-42.2.5.jar --driver-class-path /path/to/me/postgresql-42.2.5.jar
spark-sql> create database test3;
spark-sql> create table test3.test(id int, name varchar(20));
spark-sql> insert into test3.test values (1, 'chocomint'), (2, 'kusoyaro');
spark-sql> select * from test3.test;
spark-shellでデータを作ってSTSに連携する
アプリを作ってもよかったのですが、spark-shellでデータを作ってSTSに連携してみます。
spark-shell --master local
Spark context available as 'sc' (master = local, app id = local-1552720348693).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_201)
Type in expressions to have them evaluated.
Type :help for more information.
:pasteモードに切り替えてコードを貼り付けます。
貼り付けたらCtrl+Dで実行されます。
scala> :paste
// Entering paste mode (ctrl-D to finish)
import org.apache.spark.sql.SaveMode
import spark.implicits._
case class Person(id: Int, name: String)
val people = Seq(Person(1, "Alice"), Person(2, "Bob"), Person(3, "Chocomint"))
val peopleDS = people.toDS
// データベースtest1にpeopleテーブルとして作成する
peopleDS.write.mode(SaveMode.Overwrite).saveAsTable("test1.people")
// Exiting paste mode, now interpreting.
書き込みが完了したら、データベースtest1にpeopleテーブルが作成できているはずです。
まとめ
簡単なローカル環境での手順について記載しましたが、クラスタ環境でも応用が効くと思います。
知っておくと、Sparkの活用の幅が広がるのではと思いました。
参考) Configuring the Hive Metastore
https://www.cloudera.com/documentation/enterprise/5-6-x/topics/cdh_ig_hive_metastore_configure.html