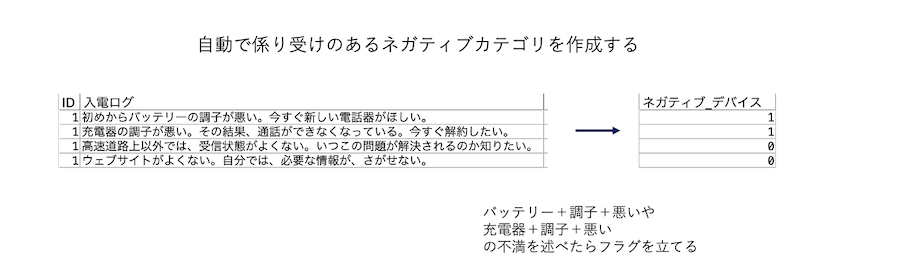
自動で係り受けのあるネガティブカテゴリを作成する
この記事はSPSS Modeler Premium Ver18.6から追加された日本語テキスト機能を利用して書かれています。SPSS Modeler Professionalをお使いの方はアップグレードするかPython連携を用いて実現します。
Python連携を紹介する記事はこちら
1.想定される利用目的
・文章に含まれるポジティブ/ネガティブの要素を係り受けと組み合わせてフラグ化します。
2.ストリームとデータのダウンロード
ストリーム
3.サンプルストリームの説明
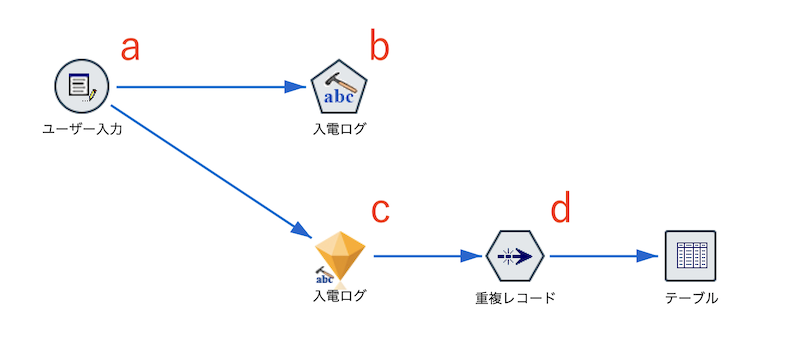
a.入力データは以下の通りです。

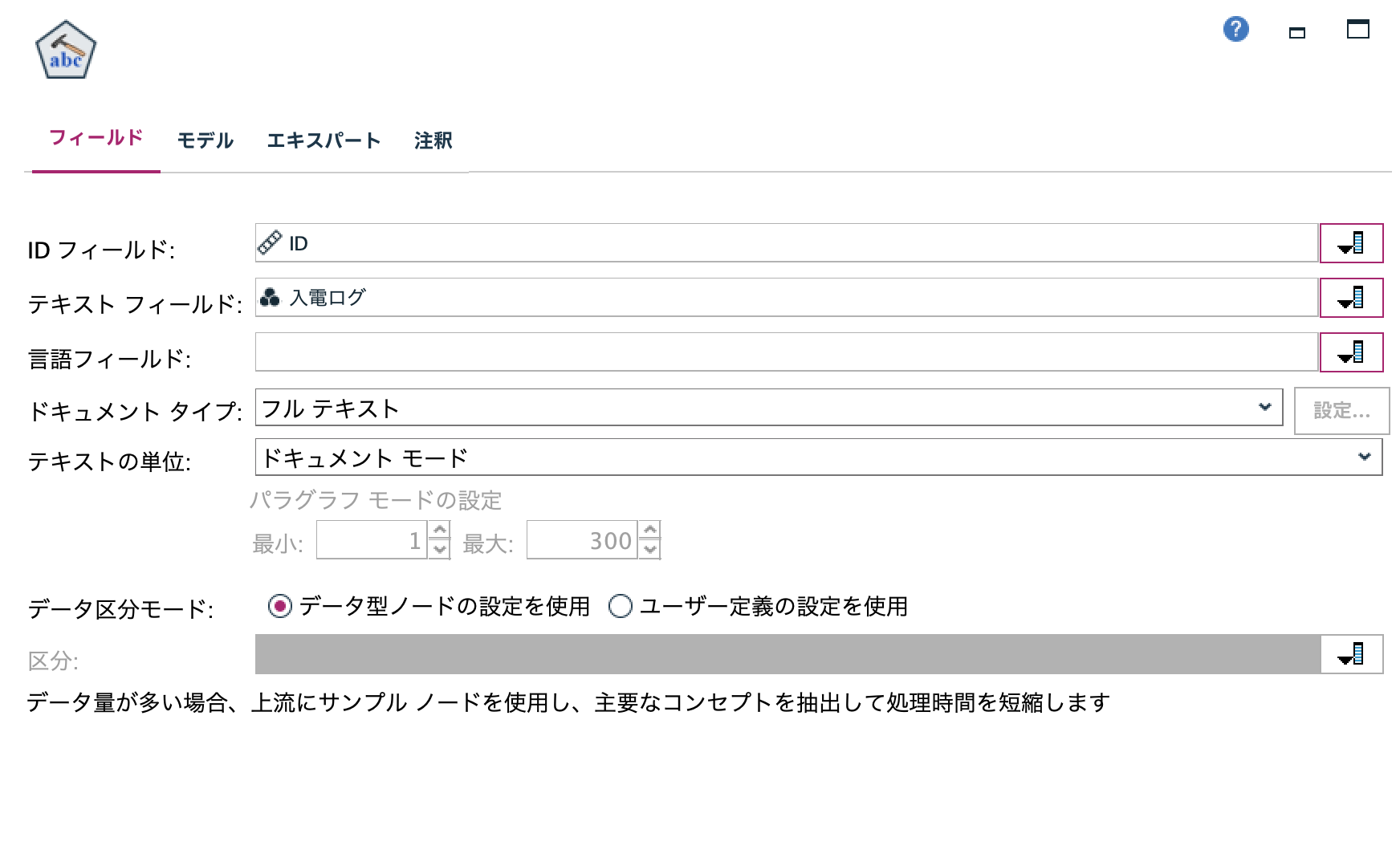
b.[テキストマイニング]ノードを編集します。[IDフィールド]と[テキストフィールド]を以下の通り選択します。
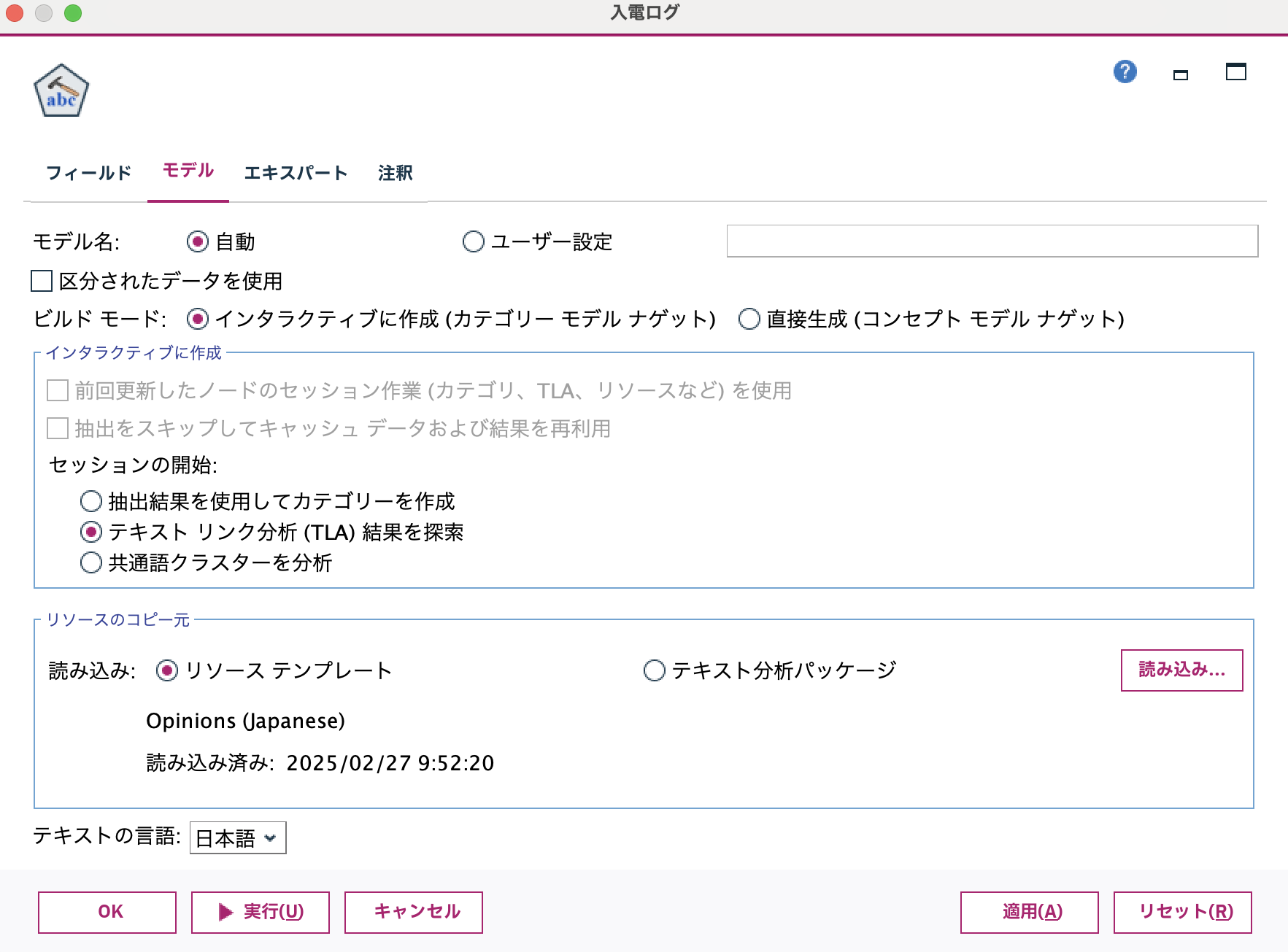
[モデル]タブを編集します。[テキストリンク分析...]を選択します。感情を識別するために[リソーステンプレート]を[読み込み]ボタンを押して[Opinions(Japanese)]を選択します。
[実行]します。右上のドロップダウンリストから[カテゴリーとコンセプト]を選択します。
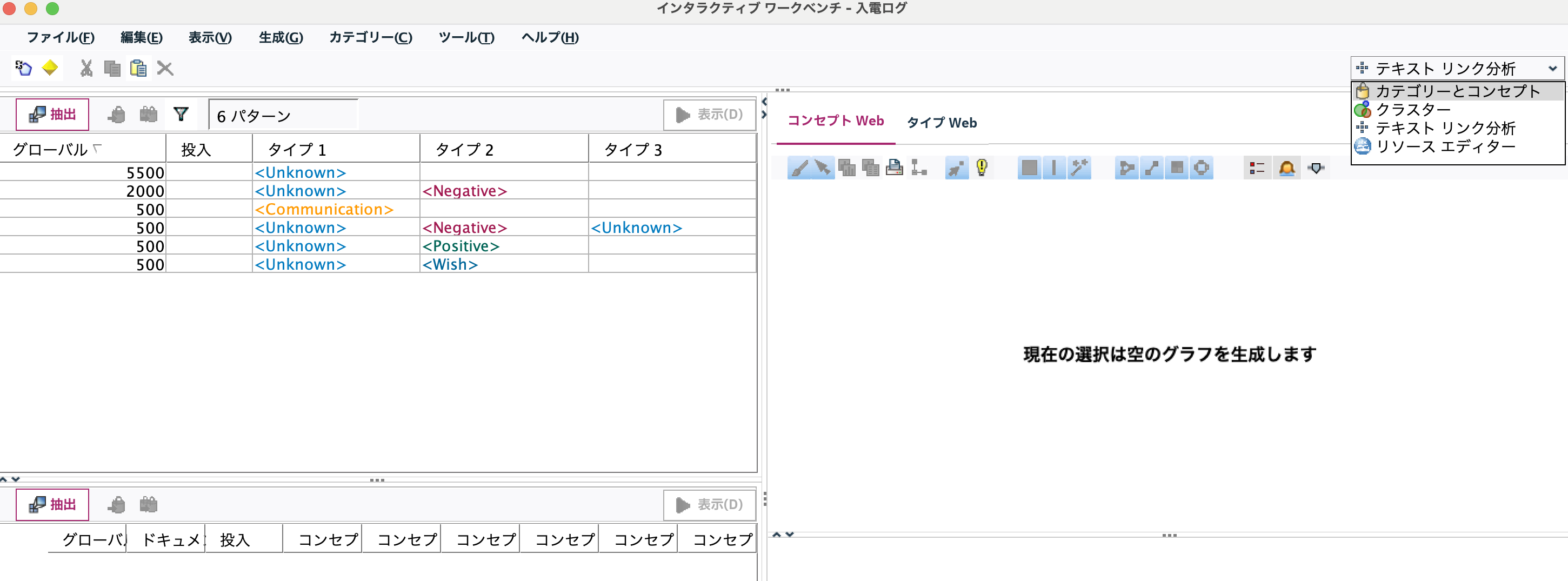
左上の[作成]ボタンを押して自動でカテゴリーを作成します。メッセージが表示されたら[編集]を選択します。
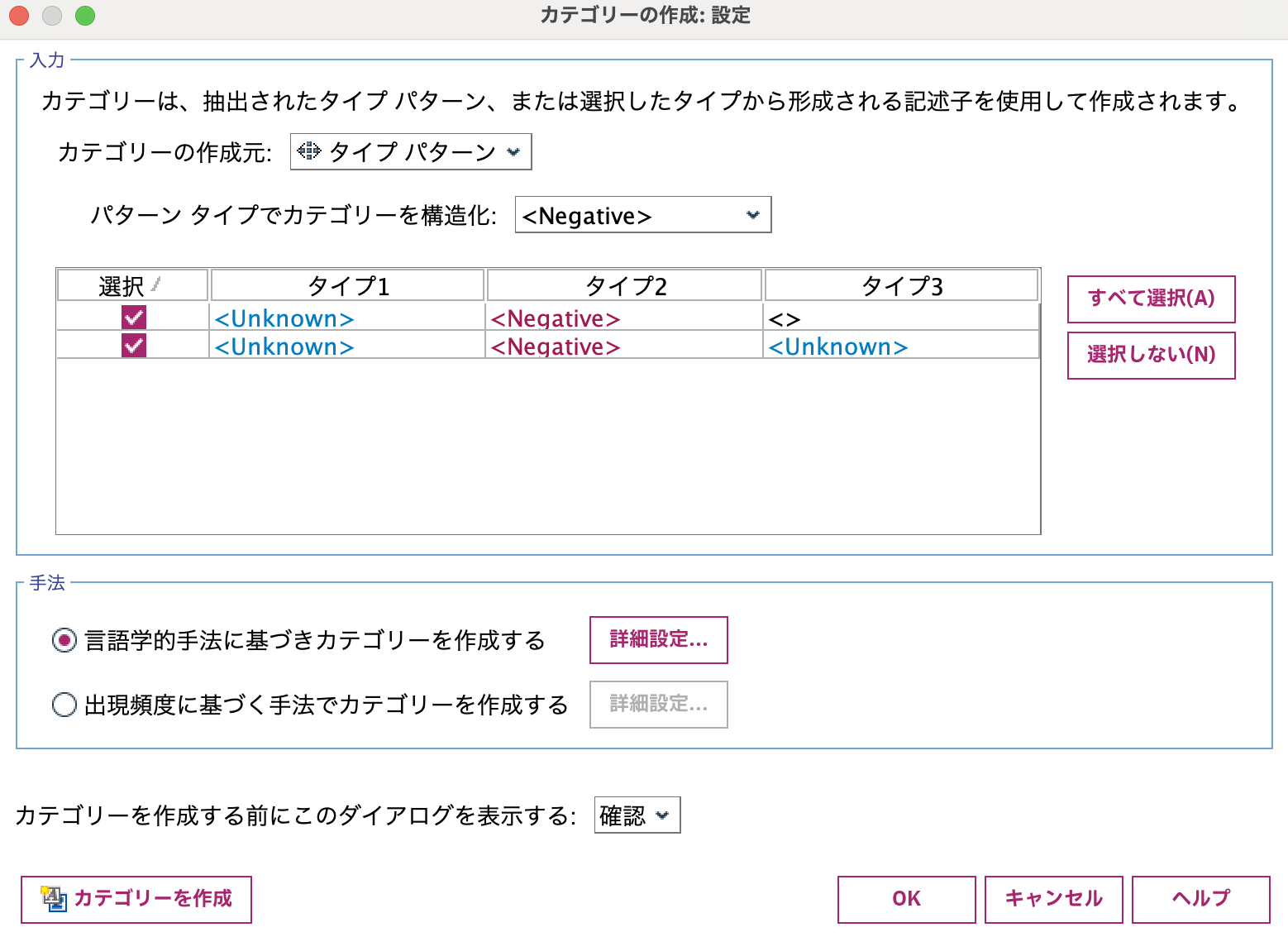
以下のように設定して[カテゴリー]を選択します。
カテゴリーが二つ作成されました。任意のカテゴリー名に変更します。

左上のダイヤモンドのボタンでフラグ化します。
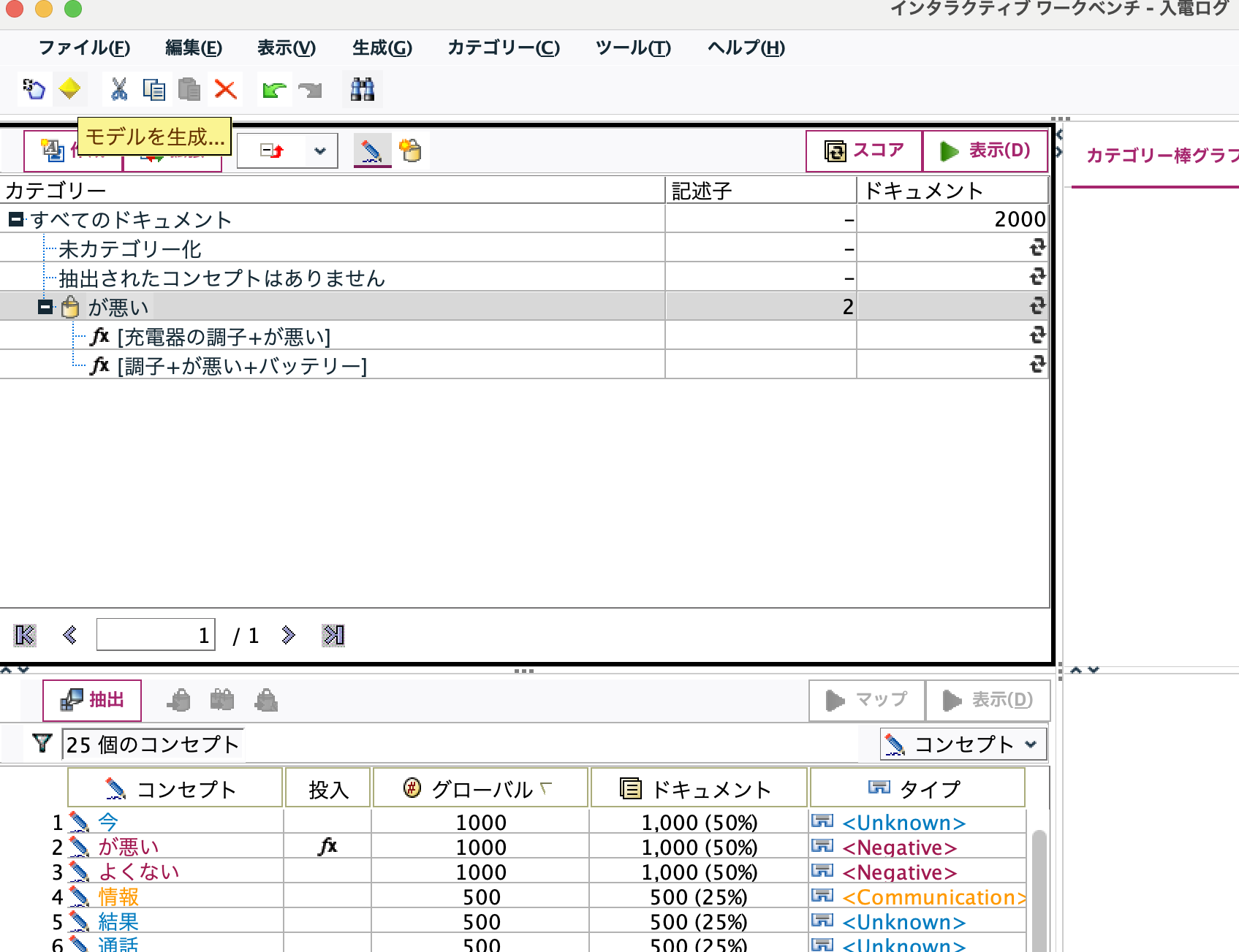
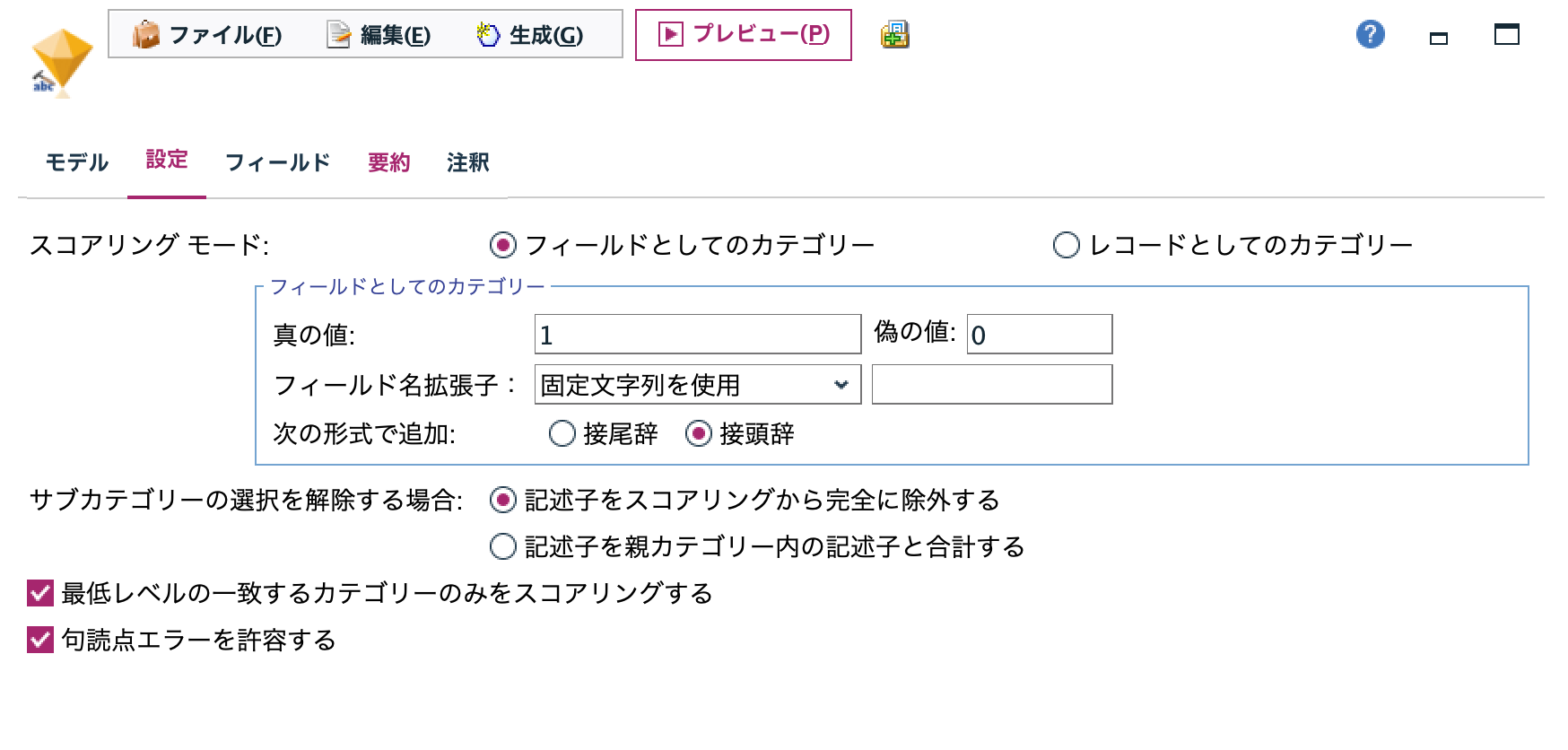
c.[テキストマイニング]ナゲットを編集します。[設定タブ]で真偽をT/Fから1/0へ[フィールド名拡張子]をブランクにします。
d.[重複]ノードは便宜的に増幅されたデータを非表示するために利用しています。
[テーブル]ノードを編集します。

注意事項
実際には自動のみでは十分なカテゴリー作成ができることはなく、次の記事で紹介されるTAPを参考に手動で作成します。
4.参考情報
Python連携によるテキストマイニング
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)