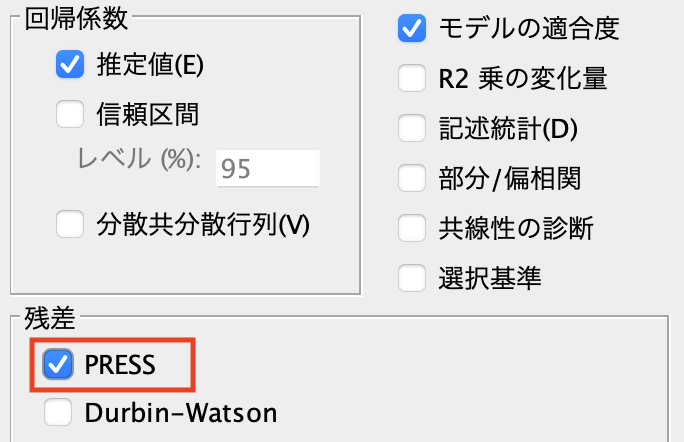
該当レコードは学習には用いない調整済み残差でPRESS(予測残差平方和)を求める

*予測残差平方和はSPSS Statistics 29.0.1で以下の通り、標準搭載されましたがSPSS Modelerではノードを繋いで求める必要があります。
1.想定される利用目的
・回帰モデルを複数作成した際の評価に利用
2.サンプルストリームのダウンロード
①一般的なスコアリングを用いる場合
②該当レコードは学習には用いない調整済み残差で求める場合(Modelerスクリプトを利用)
3.サンプルストリームの説明
①一般的なスコアリングを用いる場合
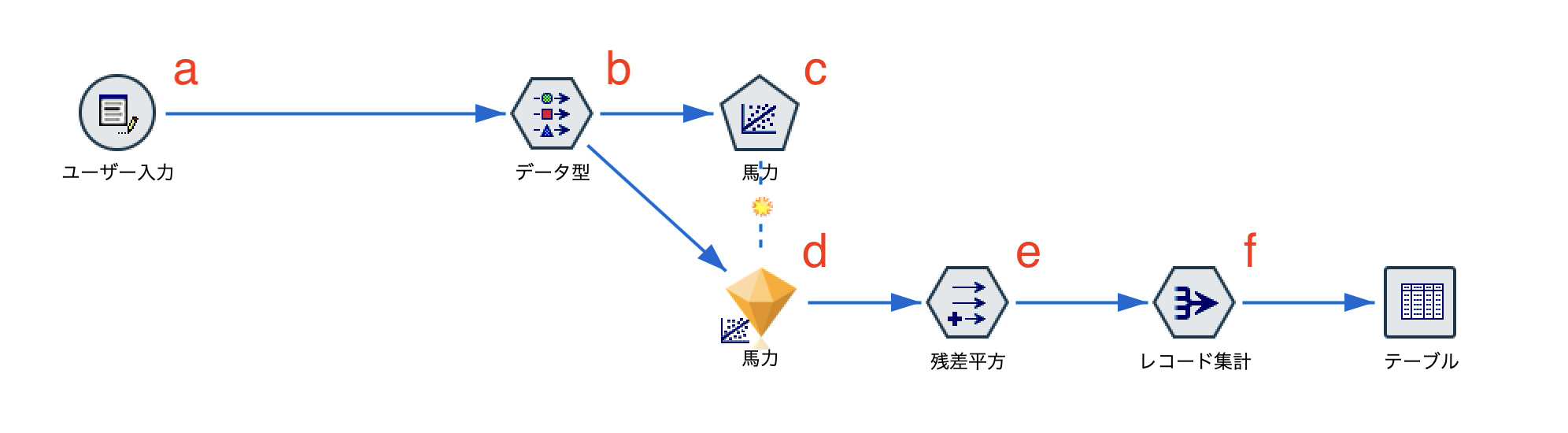
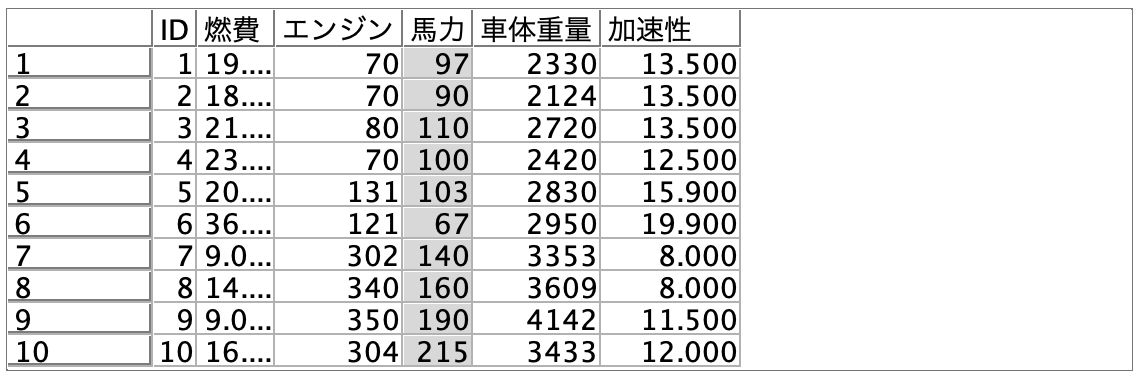
a.入力するデータは以下の通りです。
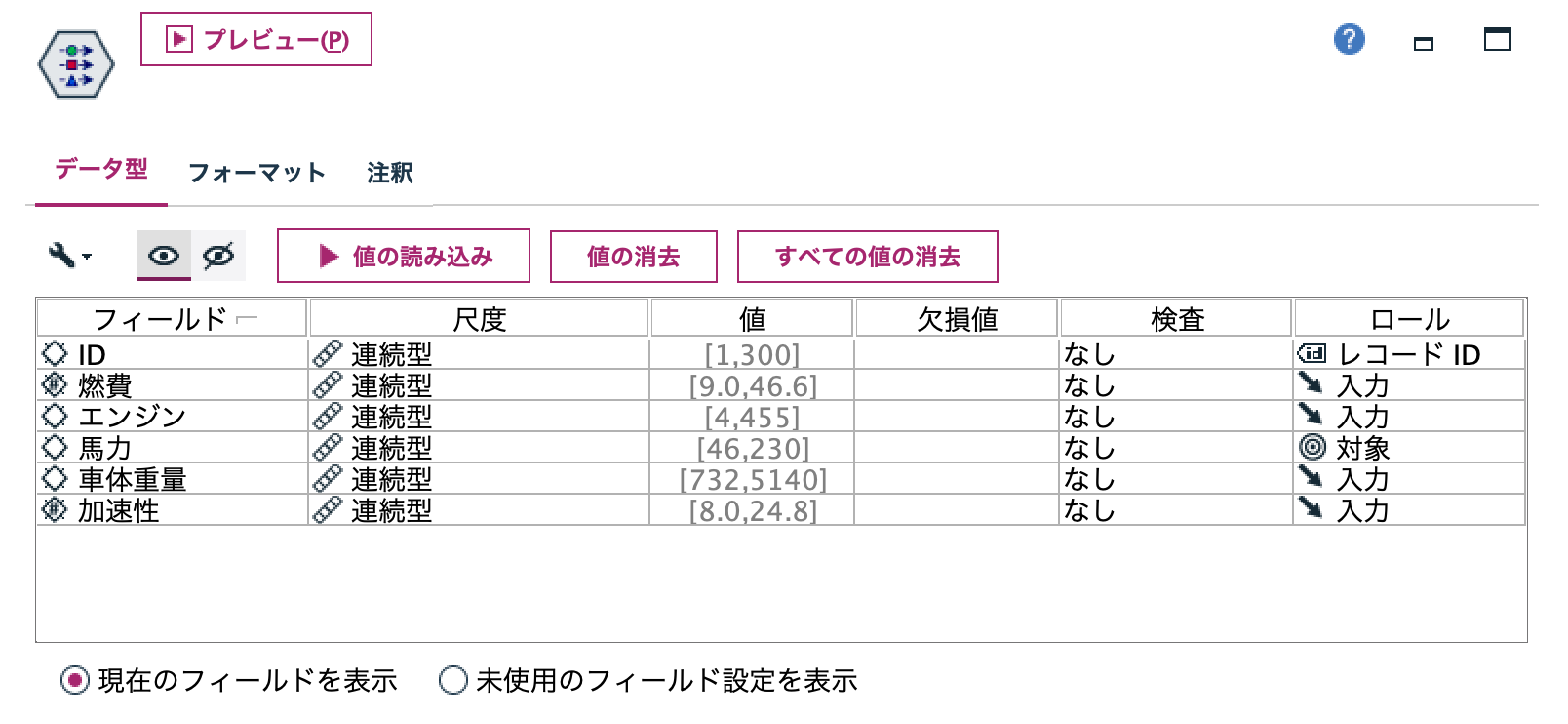
b.[データ型]ノードを以下のように設定します。馬力を予測するモデルを作成します。
c.[線型回帰]ノードを配置して実行します。
d.モデルナゲットを右クリックして[プレビュー]を選択します。予測フィールドが追加されました。
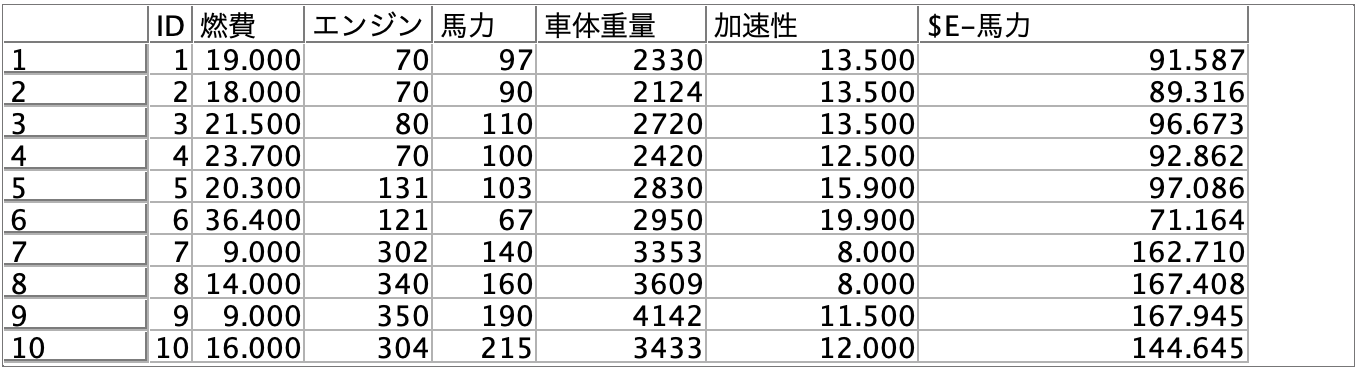
e.[フィールド作成]ノードを編集します。残差と予測の差を2乗します。
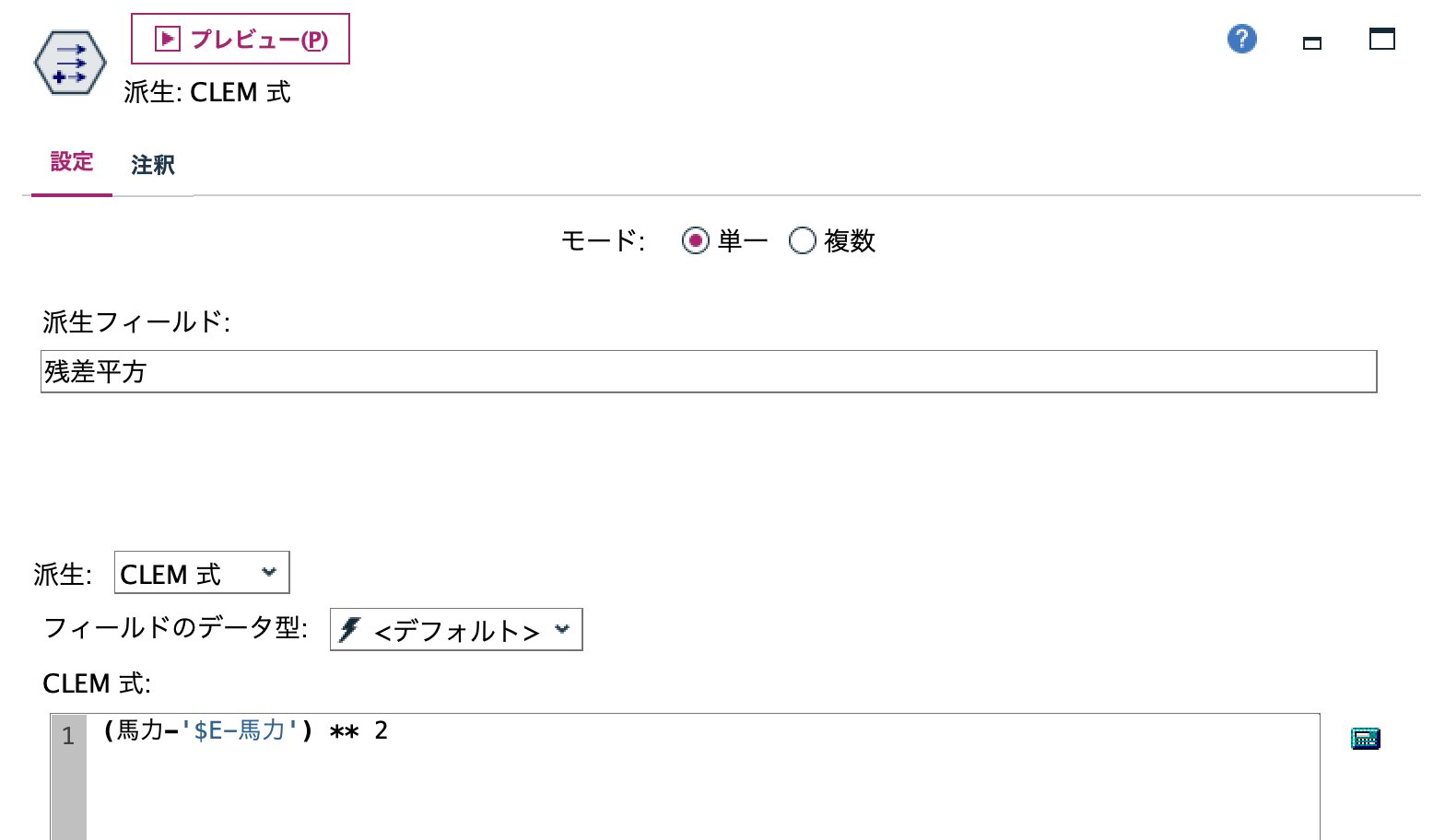
[プレビュー]を実行します。
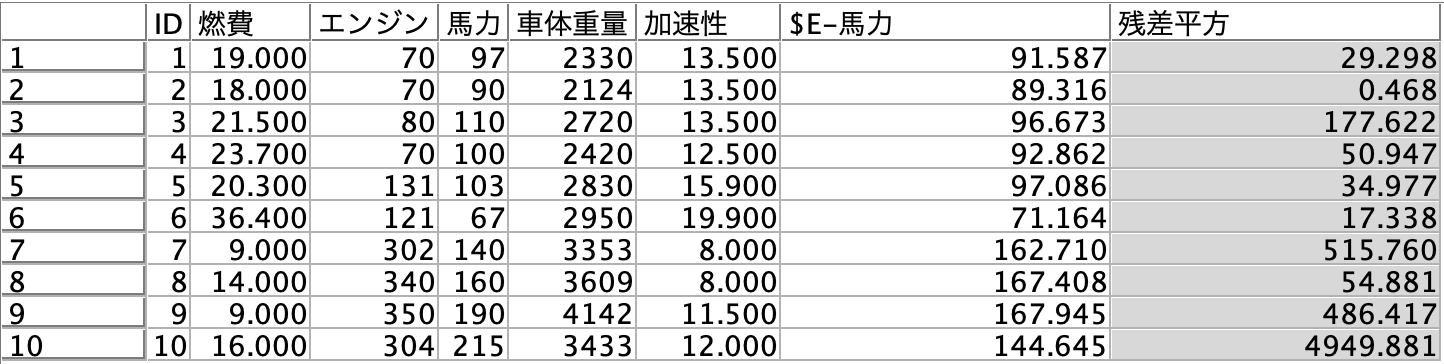
f.[レコード集計]ノードを編集します。残差平方和を求めます。
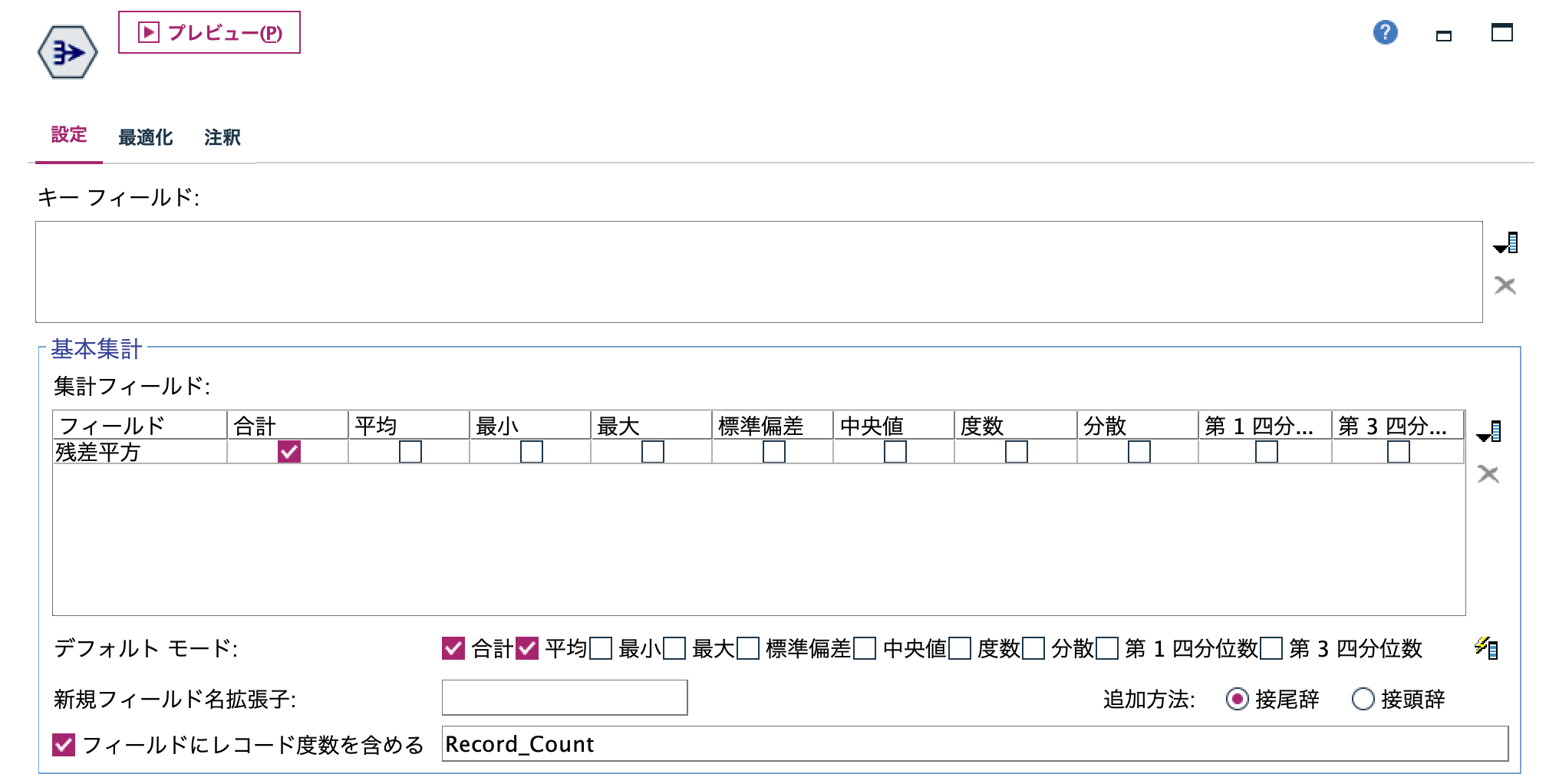
[テーブル]を実行します。
②該当レコードは学習には用いない調整済み残差で求める場合
300回ループさせて、全レコード(行)に対して該当レコードを含まない学習データで作成した予測値と残差を利用します。SPSS StatisticsのPRESSと同じ演算方法です。
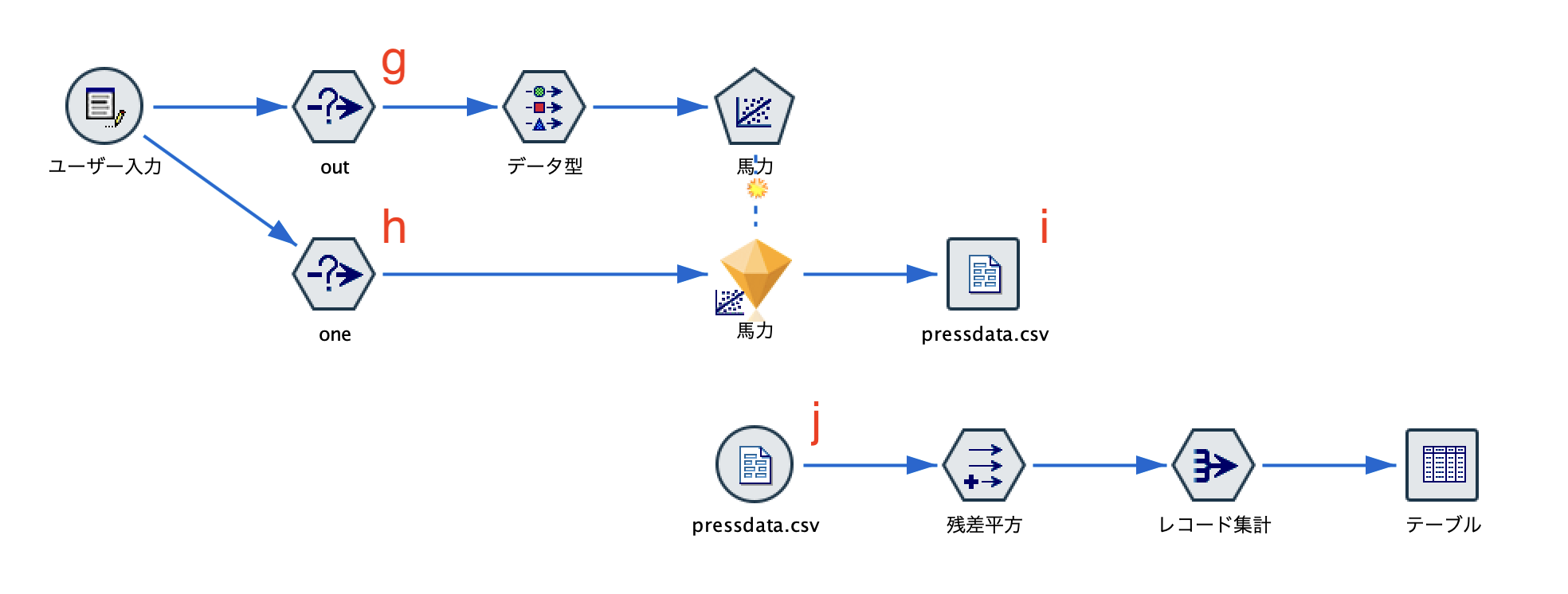
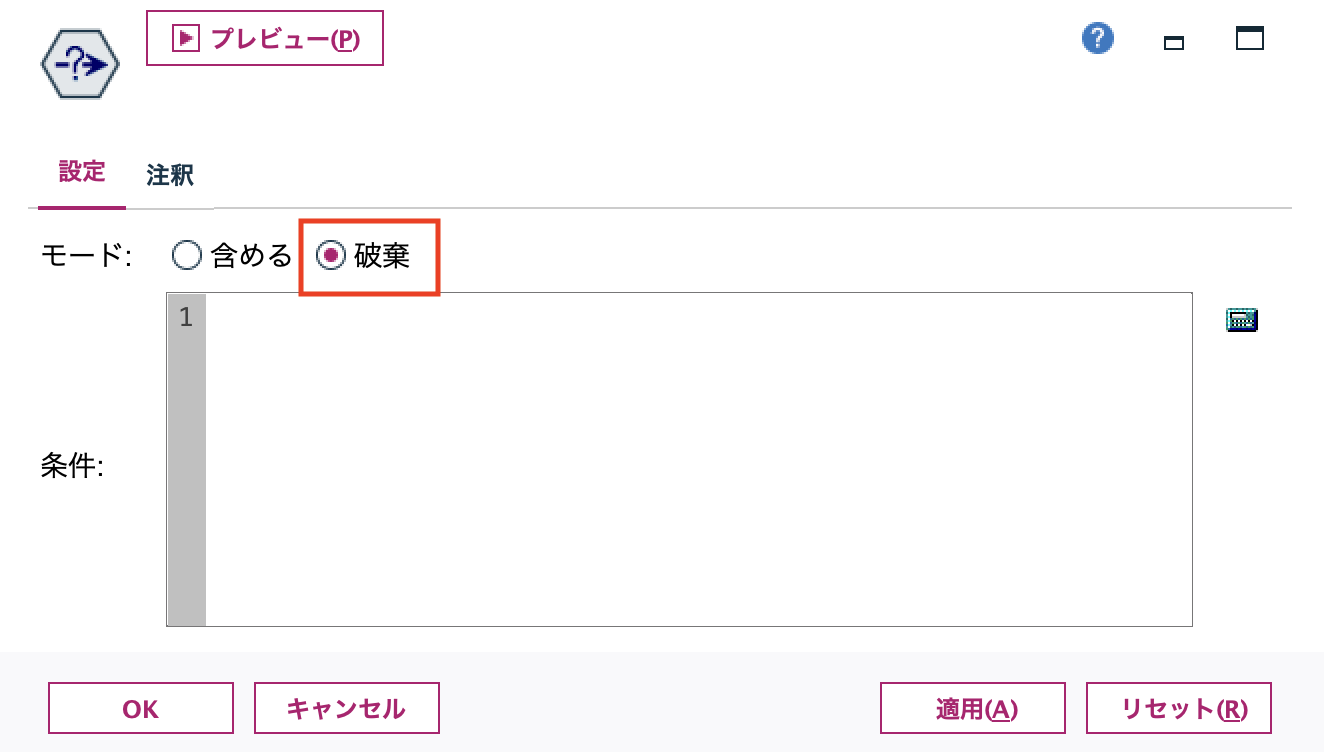
g.[条件抽出]ノードを配置します。条件はブランクのまま [モード]を[破棄]にします。
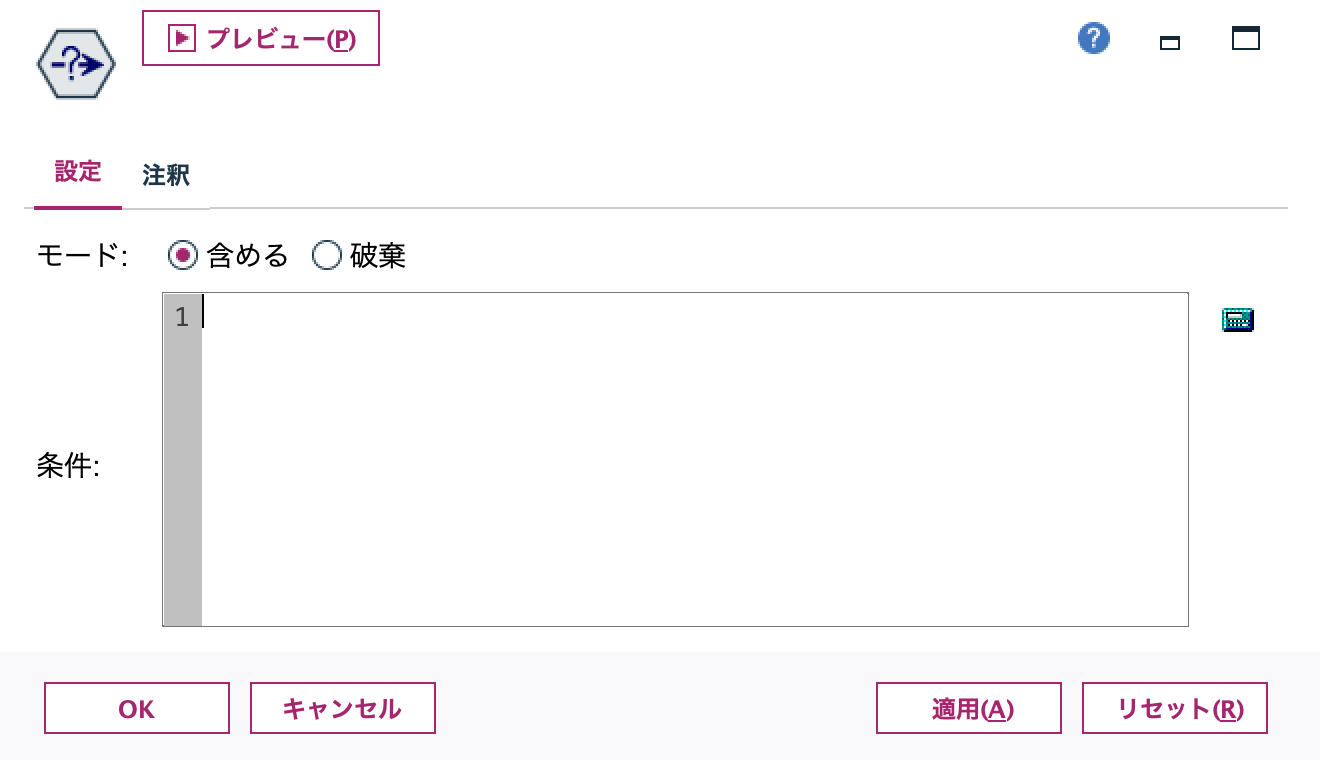
h.[条件抽出]ノードを配置します。条件はブランクのまま [モード]を[含める]にします。
i.[フラットファイル]ノードを編集します。ファイル名とパスを指定して[データのインポートノードを生成]にチェックをして実行します。
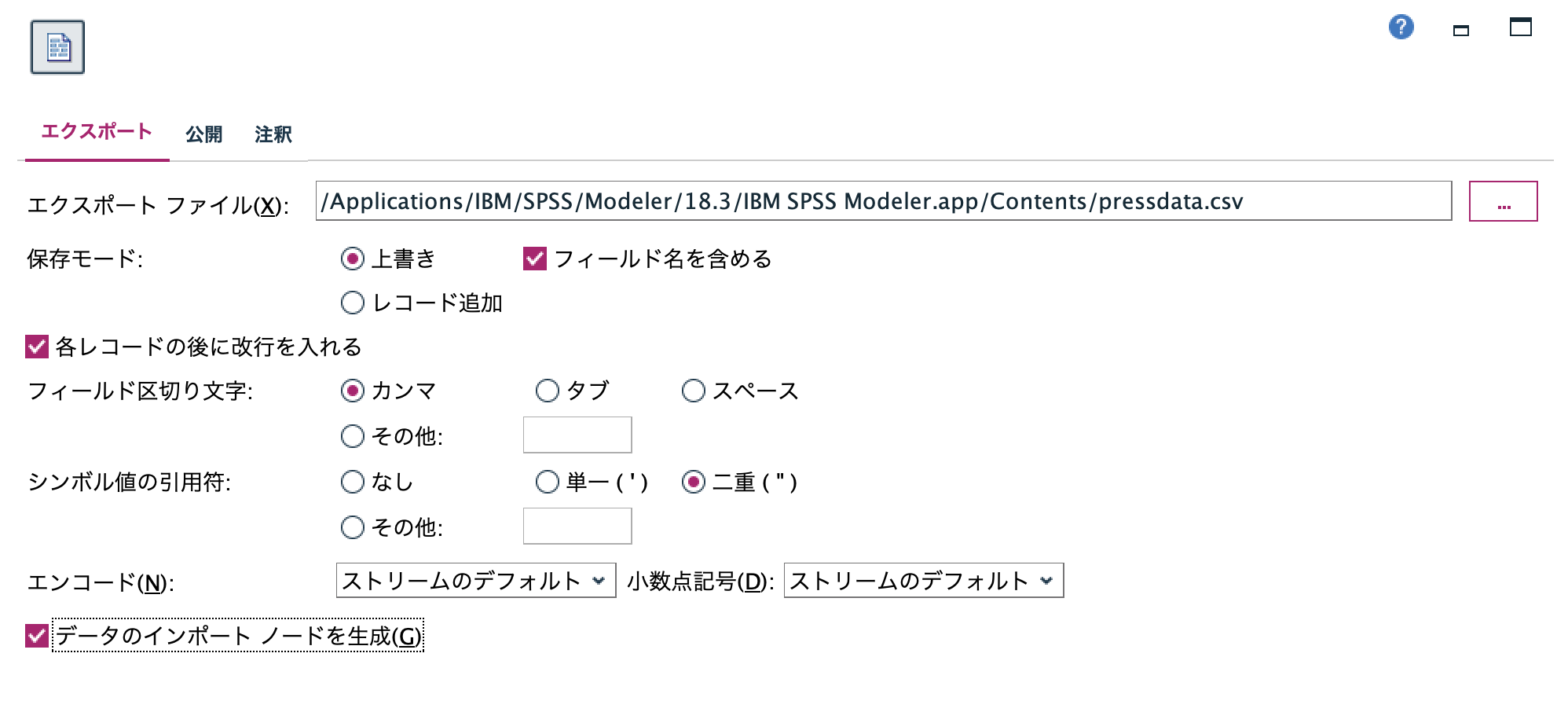
j.インポートノードが自動生成されました。先のiで指定した[データのインポートノードを生成]のチェックを外してから
後続としてeとfを複製して接続します。
Modelerスクリプトでループを設定する
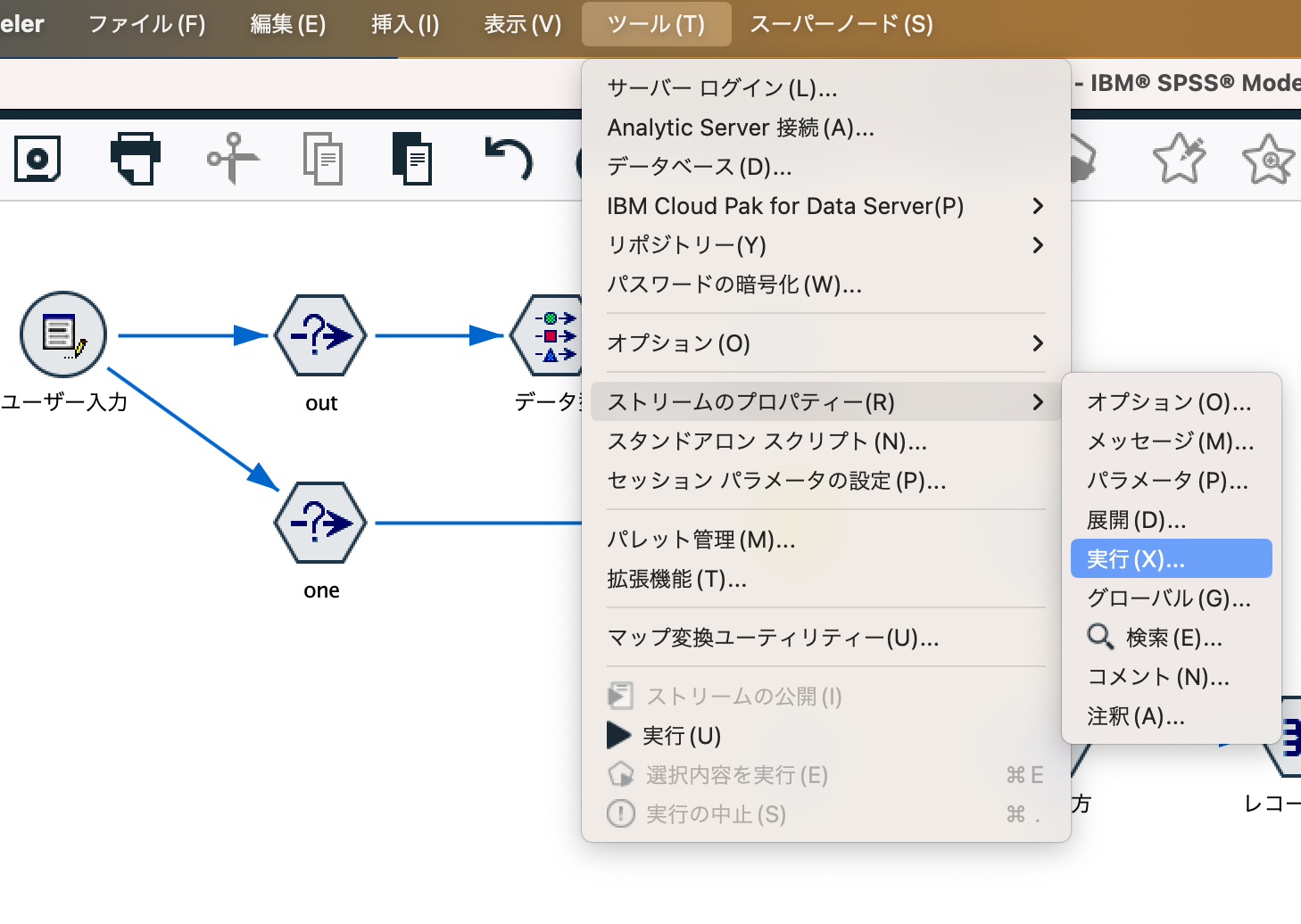
Pythonモードで以下のようにスクリプトを記述します。[このスクリプトを実行]を選択します。
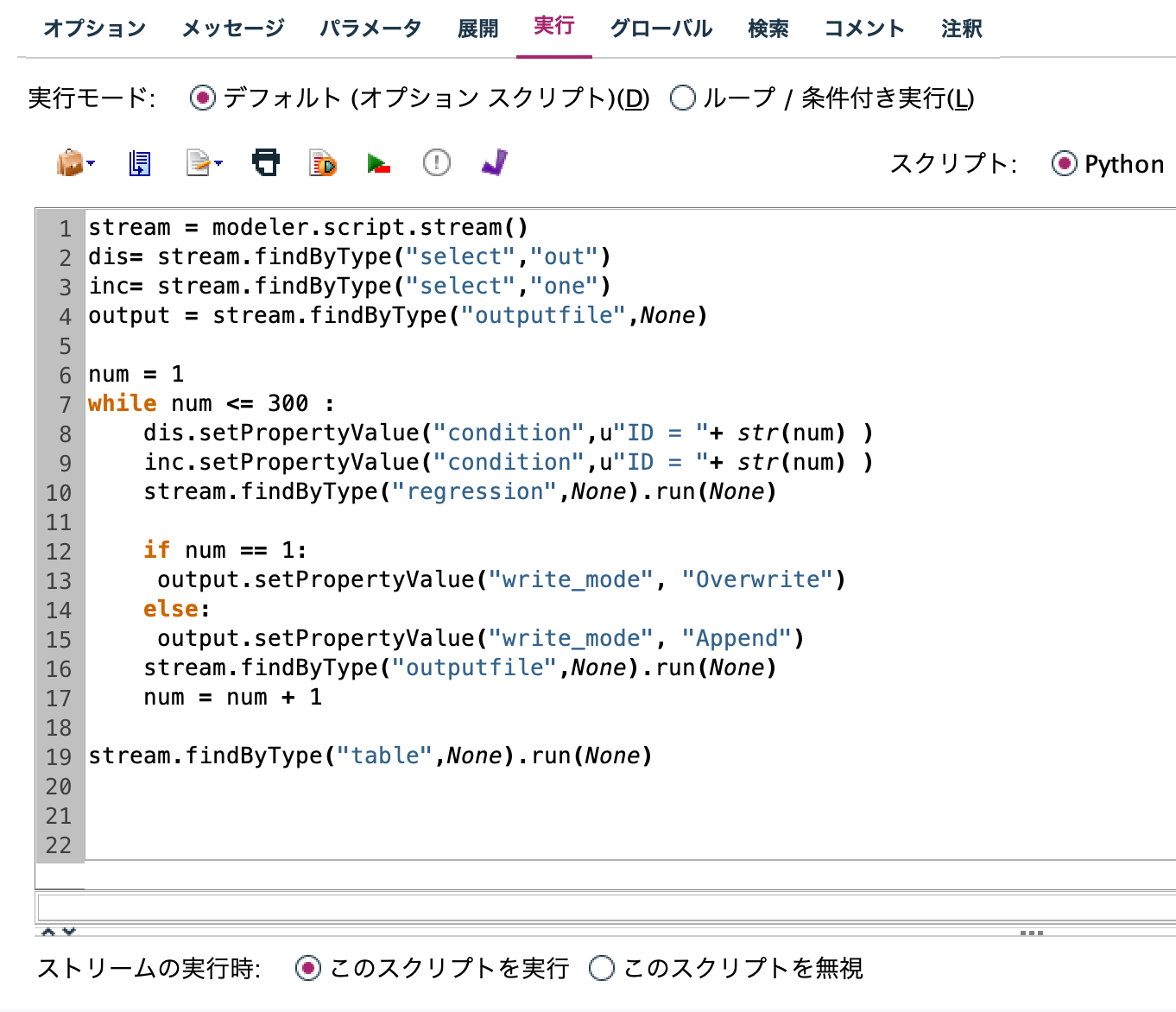
stream = modeler.script.stream()
dis= stream.findByType("select","out")
inc= stream.findByType("select","one")
output = stream.findByType("outputfile",None)
num = 1
while num <= 300 :
dis.setPropertyValue("condition",u"ID = "+ str(num) )
inc.setPropertyValue("condition",u"ID = "+ str(num) )
stream.findByType("regression",None).run(None)
if num == 1:
output.setPropertyValue("write_mode", "Overwrite")
else:
output.setPropertyValue("write_mode", "Append")
stream.findByType("outputfile",None).run(None)
num = num + 1
stream.findByType("table",None).run(None)
ループ処理を実行する
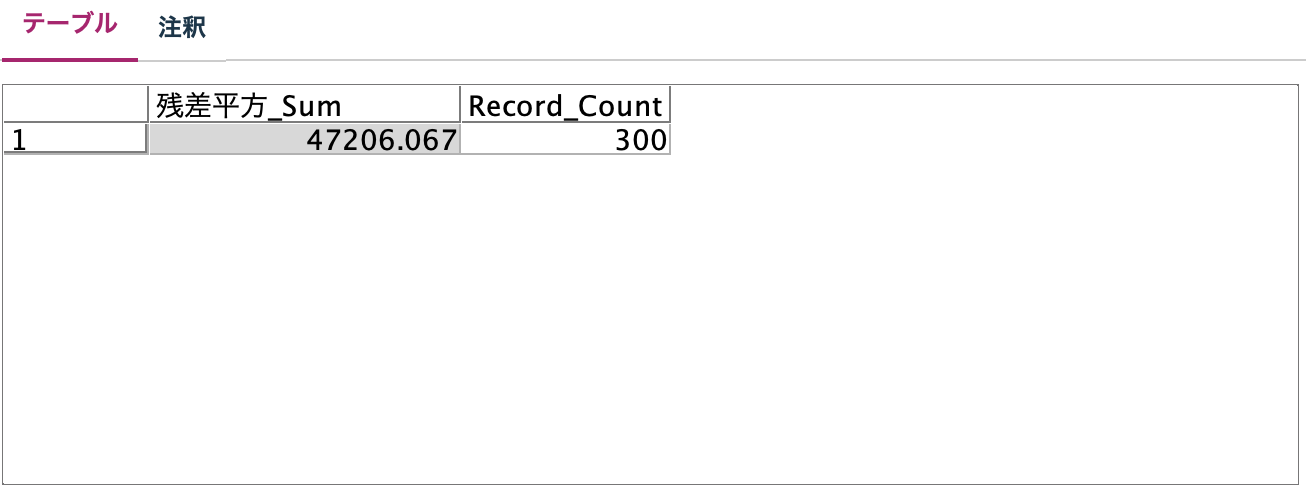
画面の▶︎ボタンを押すと300回モデルをループしながら作成します。
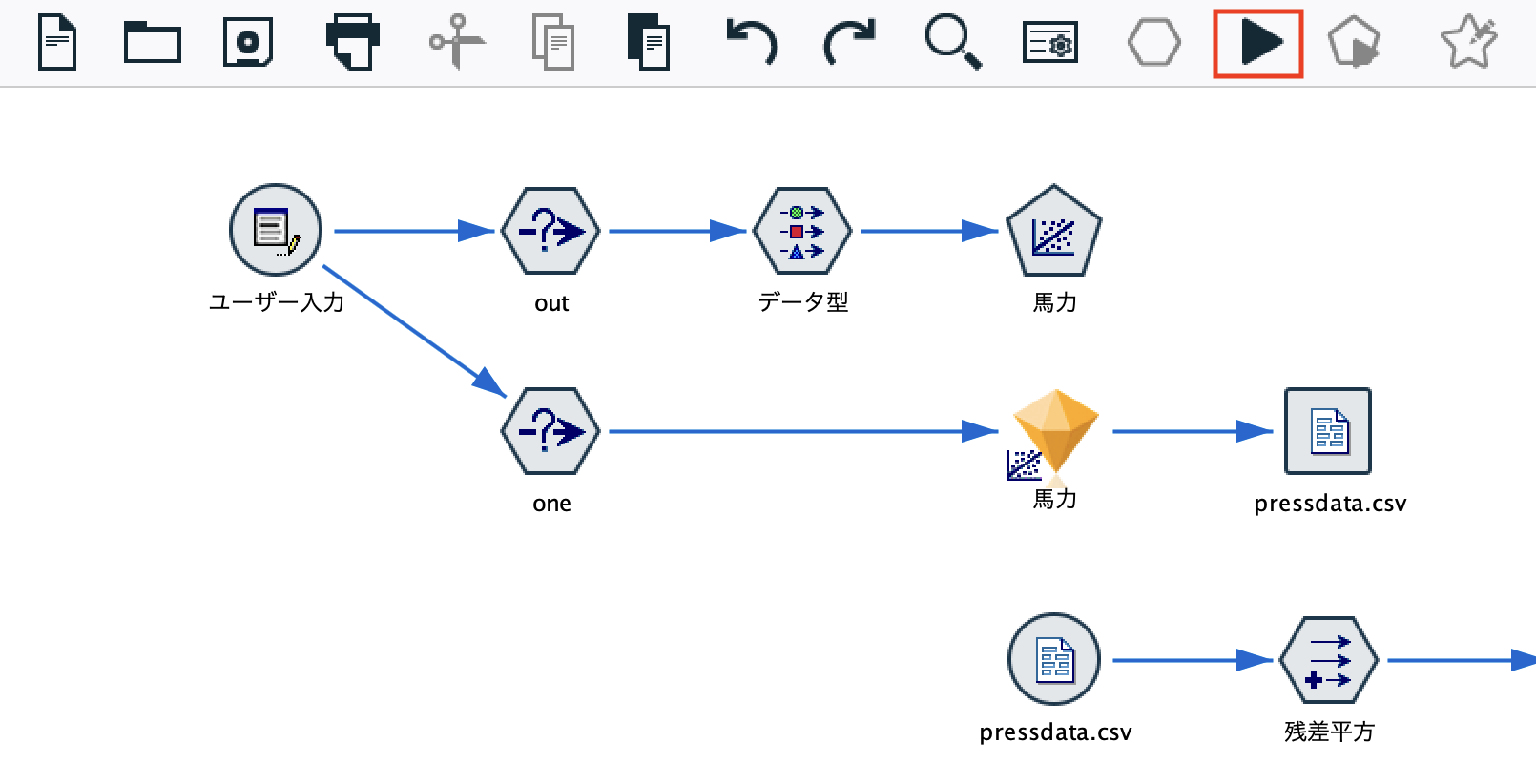
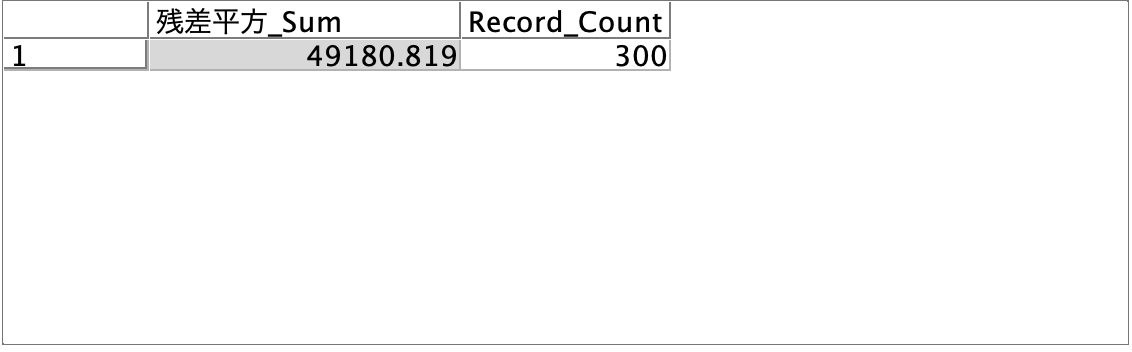
処理が終了するとPERSSが表示されます。
注意事項
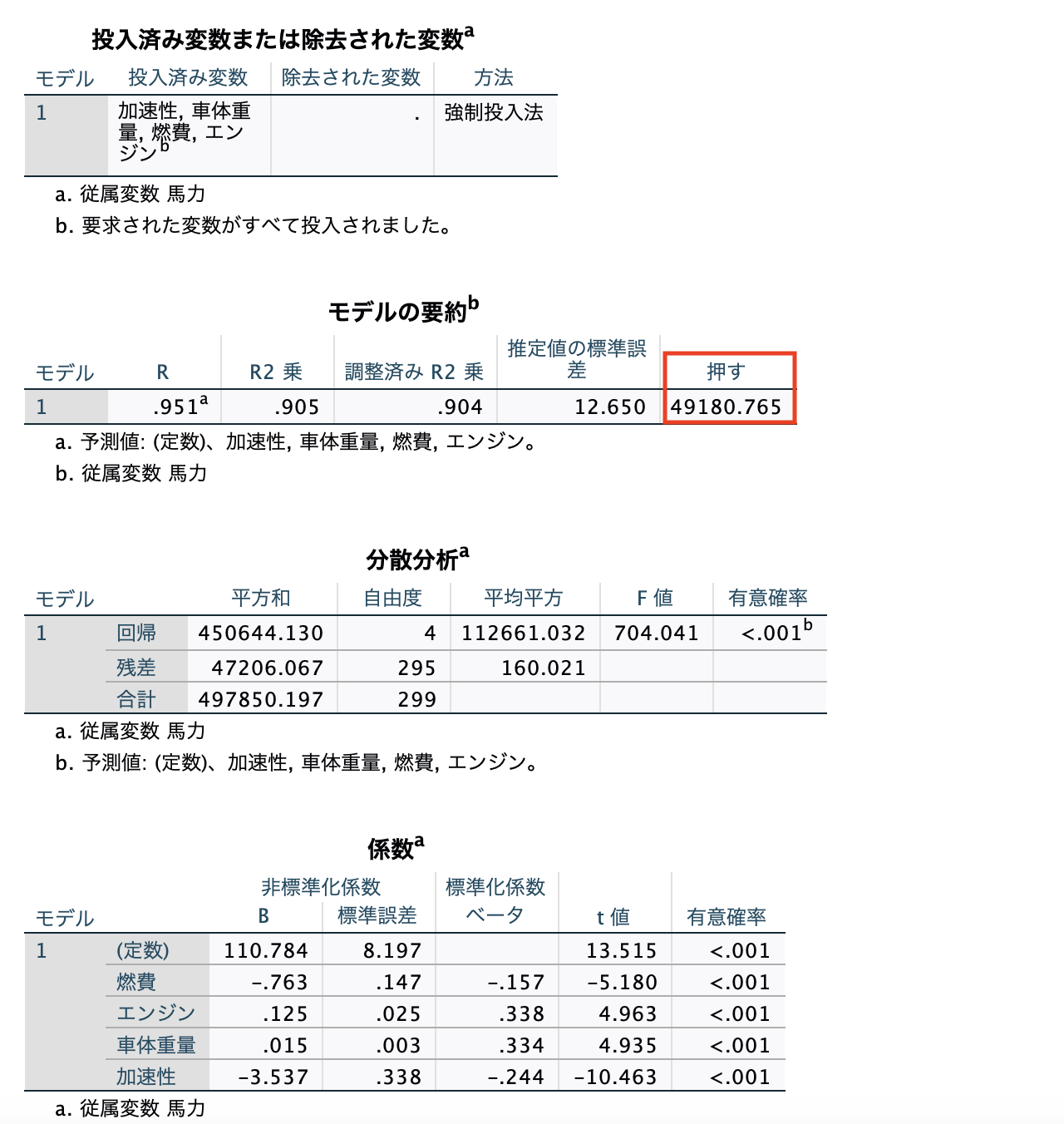
以下StatisiticsのPRESS(表示が誤訳になっています)との比較です。Statisticsの予測の少数桁数がModelerと異なった影響でわずかに差が生じました。
4.参考情報
PRESSを扱った記事
Modelerスクリプトを扱った記事
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)