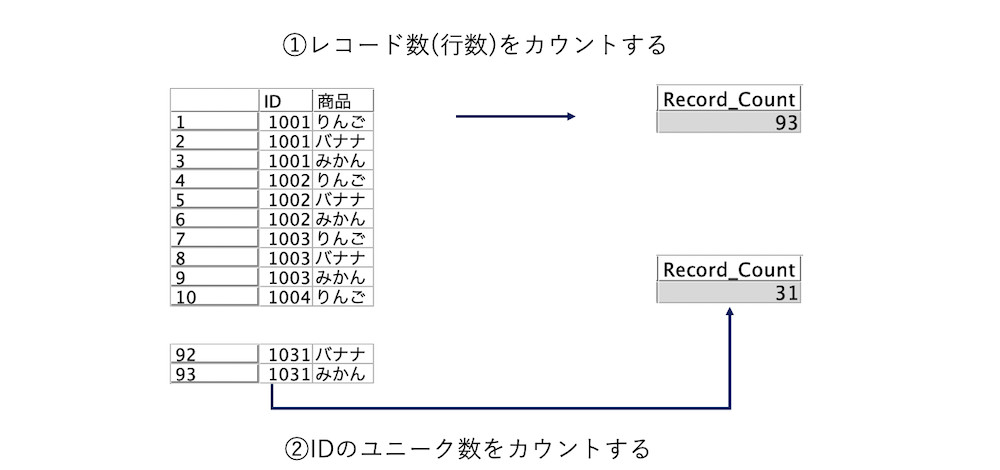
レコード数/ユニークなID数をカウント(レコードカウント)
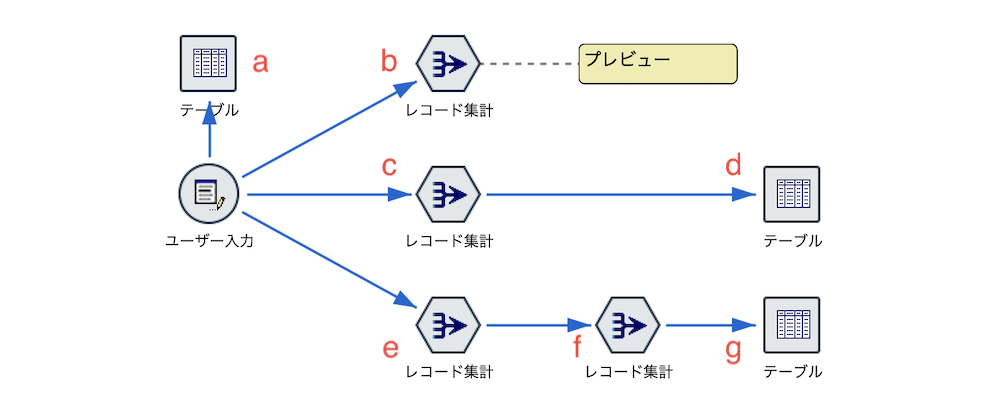
1.想定される利用目的
・読み込んだデータの概要確認
2.サンプルストリームのダウンロード
3.サンプルストリームの説明
[テーブル]ノードのウィンドウにレコード数(行数)とフィールド数(列数)
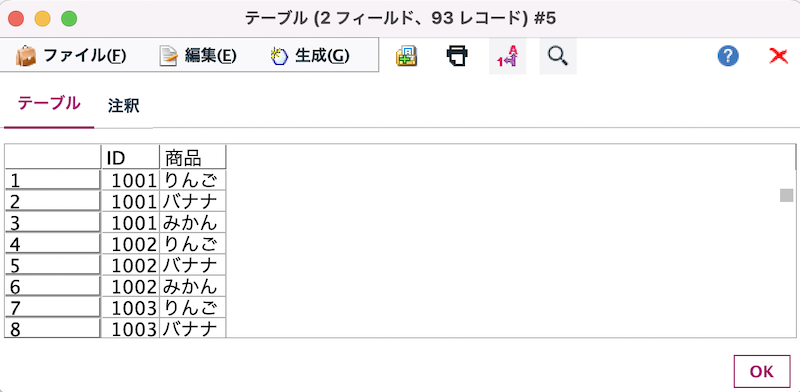
a.入力するデータは以下の通りです。[テーブル]ノードのヘッダーに[2フィールド,93レコード]と表示されるためこの時点でテーブル全体が93行だとわかります。
レコード集計を設定しないでプレビューする
b.[レコード集計]ノードを何も設定しないでプレビューします。読み込んだデータの行数を最も早く知る方法です。SQLプッシュバックが有効の場合はSQLで集計済みの値のみを返すため高速処理が期待できます。

SQLプッシュバックは以下の記事で解説しています。
c.bと同じで何も設定していません。
d.[テーブル]を実行します。bと同じレコード数のみが表示されます。

IDのユニーク数を確認する
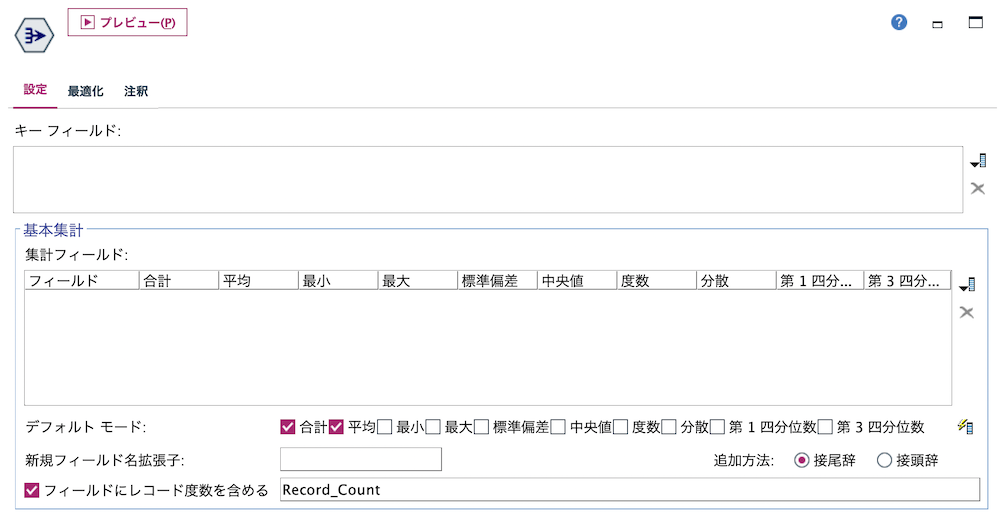
e.[レコード集計]ノードを編集します。[キーフィールド]に[ID]を選択し、[フィールドにレコード度数を含める]からチェックを外します。
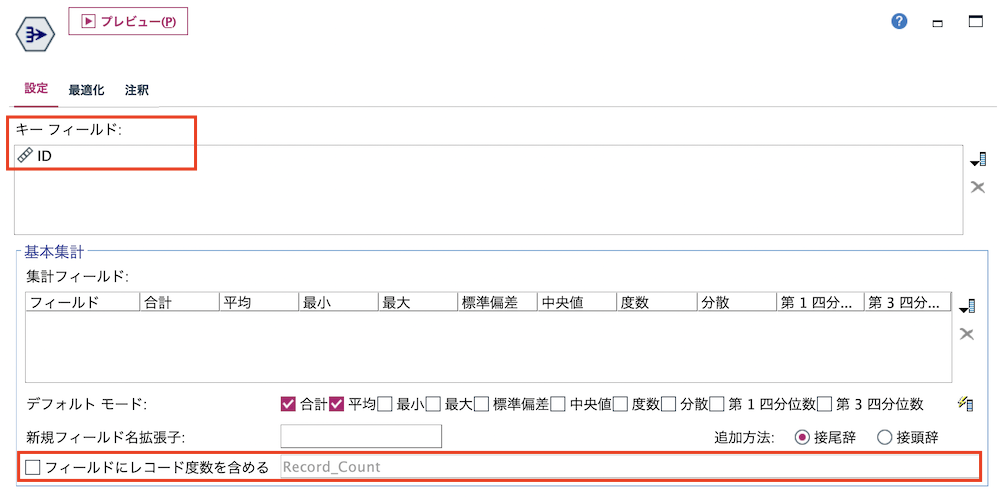
[プレビュー]します。IDをキーにしたのでIDのリストが表示されます。

f.[レコード集計]ノードを編集します。ひとつ前のテーブルのレコード数がIDの行数になるため[キーフィールド]をブランク、[フィールドにレコード度数を含める]にチェックを入れます。
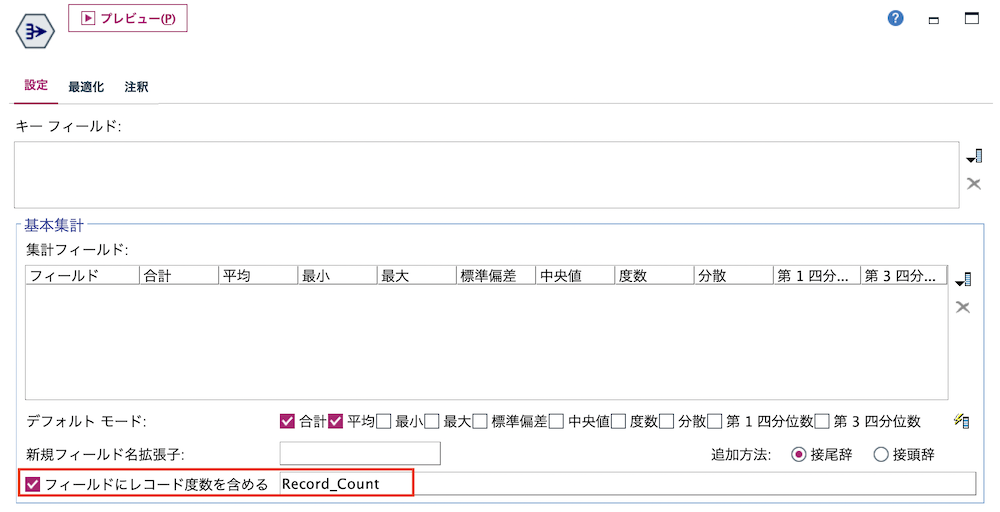
g.[テーブル]ノードを実行します。

注意事項
aで読み込むテーブルの規模が小さい場合には問題ありませんが、大規模な場合全レコードを表示するのに時間がかかり、Serverやクラウドにデータが存在する場合トラフィックに負荷がかかります。そのためレコード集計とサンプリングを効果的に利用してデータ理解を進めることをお勧めします。
4.参考情報
[レコード集計]ノードを扱った記事
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)