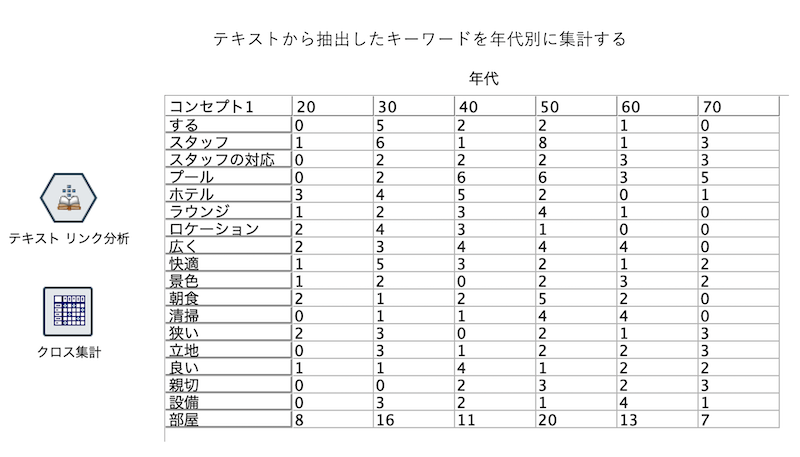
テキストから抽出したキーワードを年代別に集計する
この記事はSPSS Modeler Premium Ver18.6から追加された日本語テキスト機能を利用して書かれています。SPSS Modeler Professionalをお使いの方はアップグレードするかPython連携を用いて実現します。
Python連携を紹介する記事はこちら
1.想定される利用目的
・回答者属性別のキーワード集計
・コンタクトセンターに入電される顧客のステータス別クレームワード集計
2.ストリームとデータのダウンロード
ストリーム
3.サンプルストリームの説明
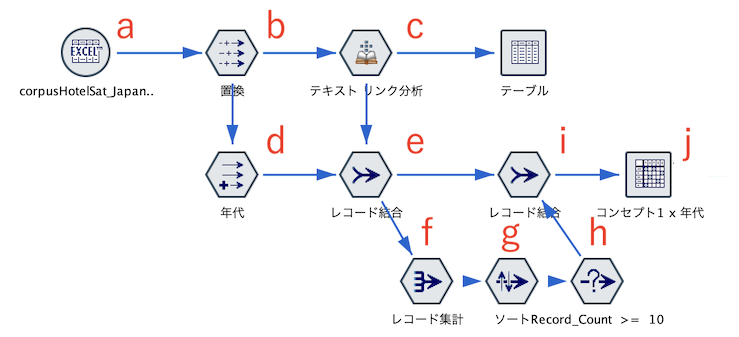
a.入力データは以下の通りです。

データはPremium版インストール時に同梱のエクセルファイルを利用しています。入力パスは自動的にマッピングされます。
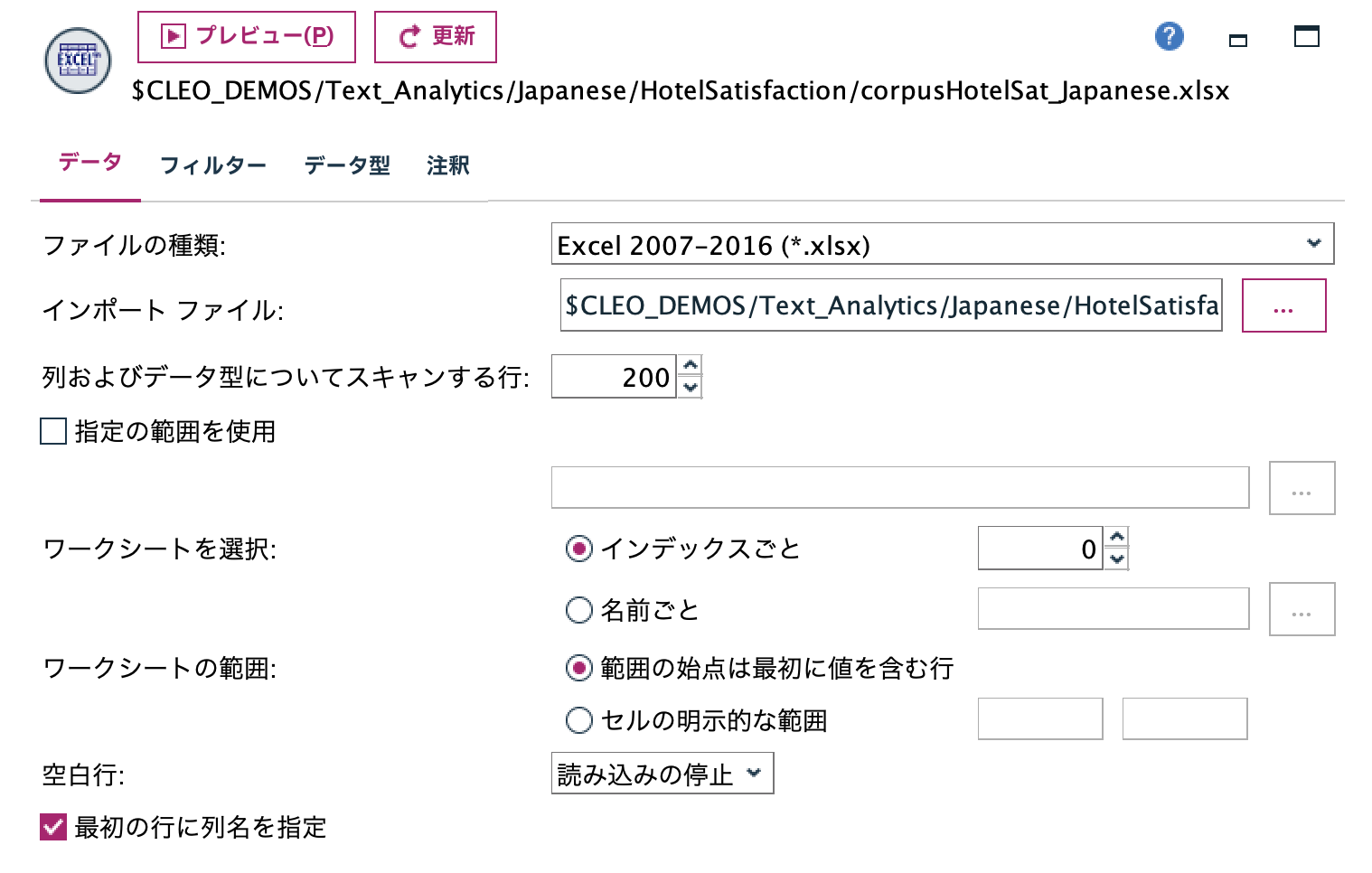
b.[置換]ノードを編集します。一度分岐させた情報を後続で結合する際、[id]が整数と文字列で不一致を起こさないように文字列で固定します。
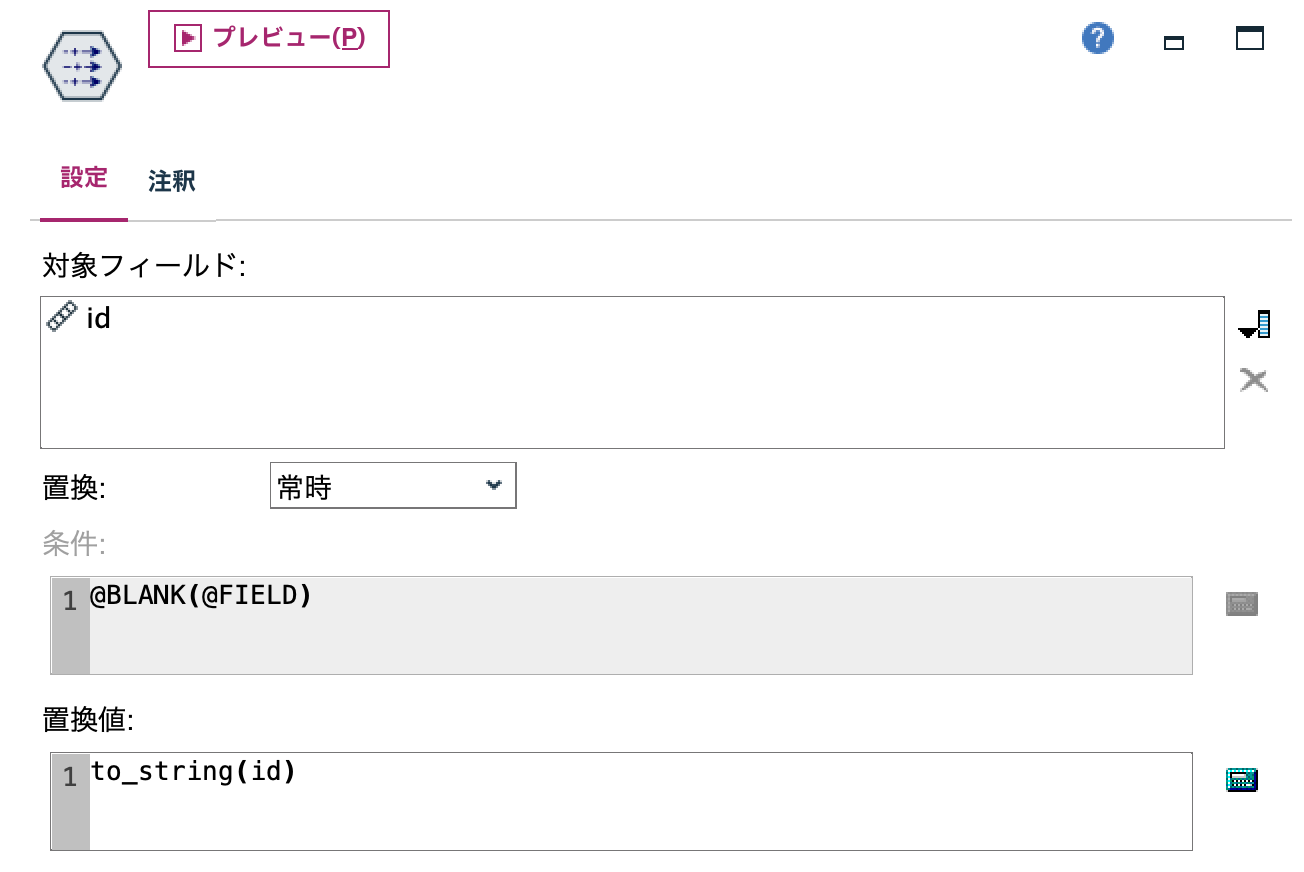
c.[テキストリンク分析]ノードを編集します。
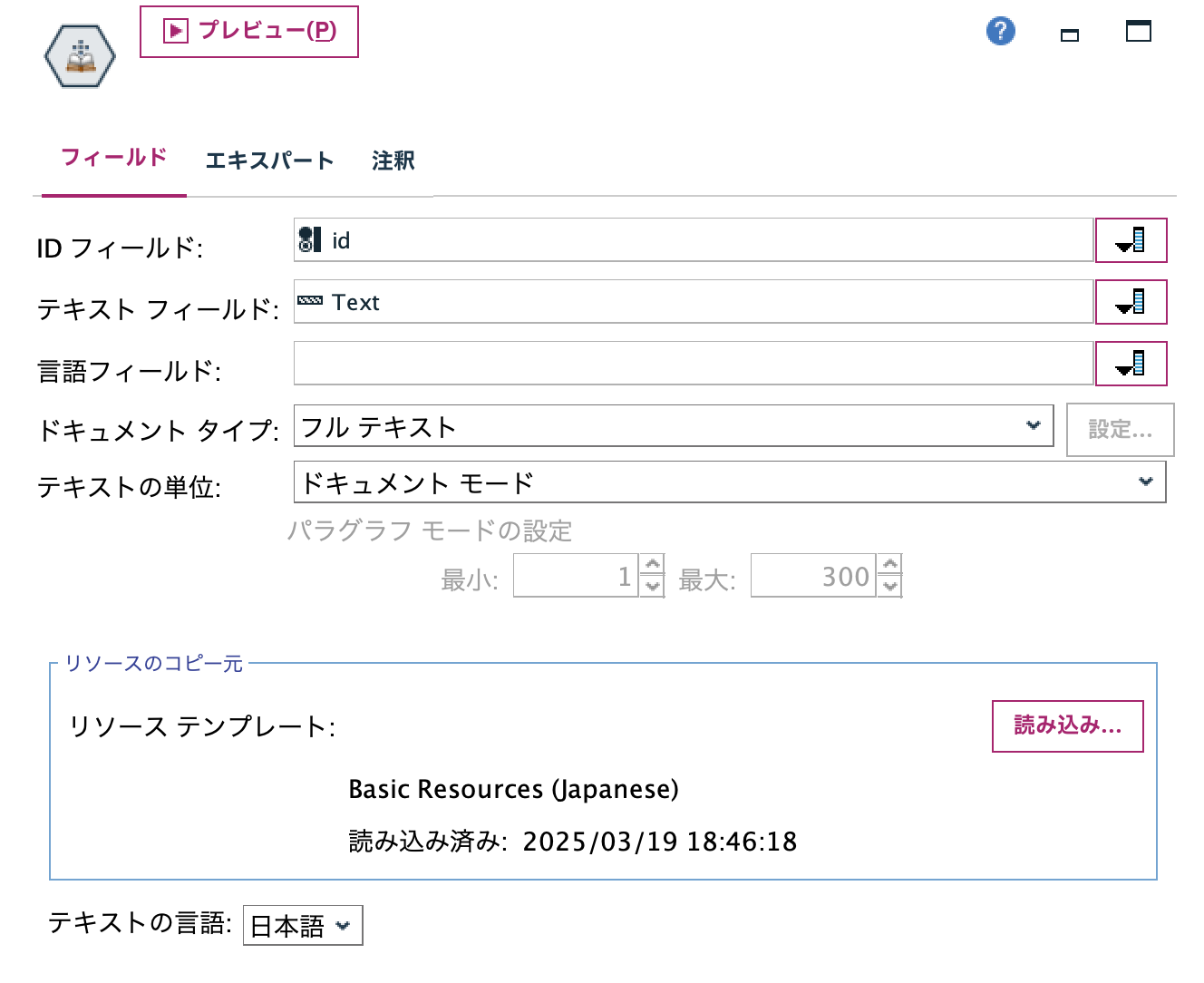
[テーブル]ノードを実行します。 このノードは切り出されたコンセプト(キーワード)の分レコードが増やします。[id]に属性を結合、集計しやすい形式になっています。

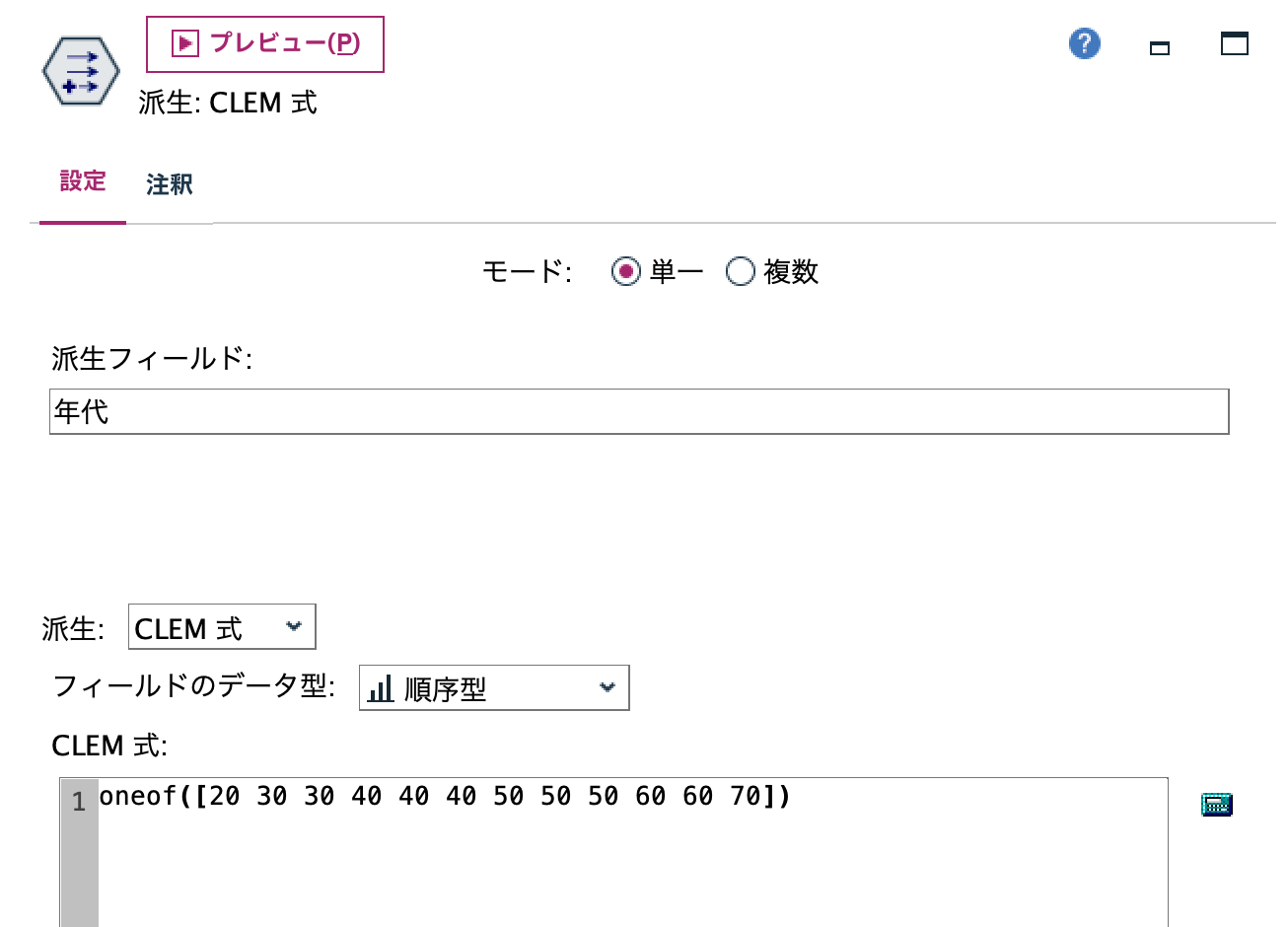
d.[フィールド作成]ノードを編集します。年代を毎回ランダムに割り当てます。
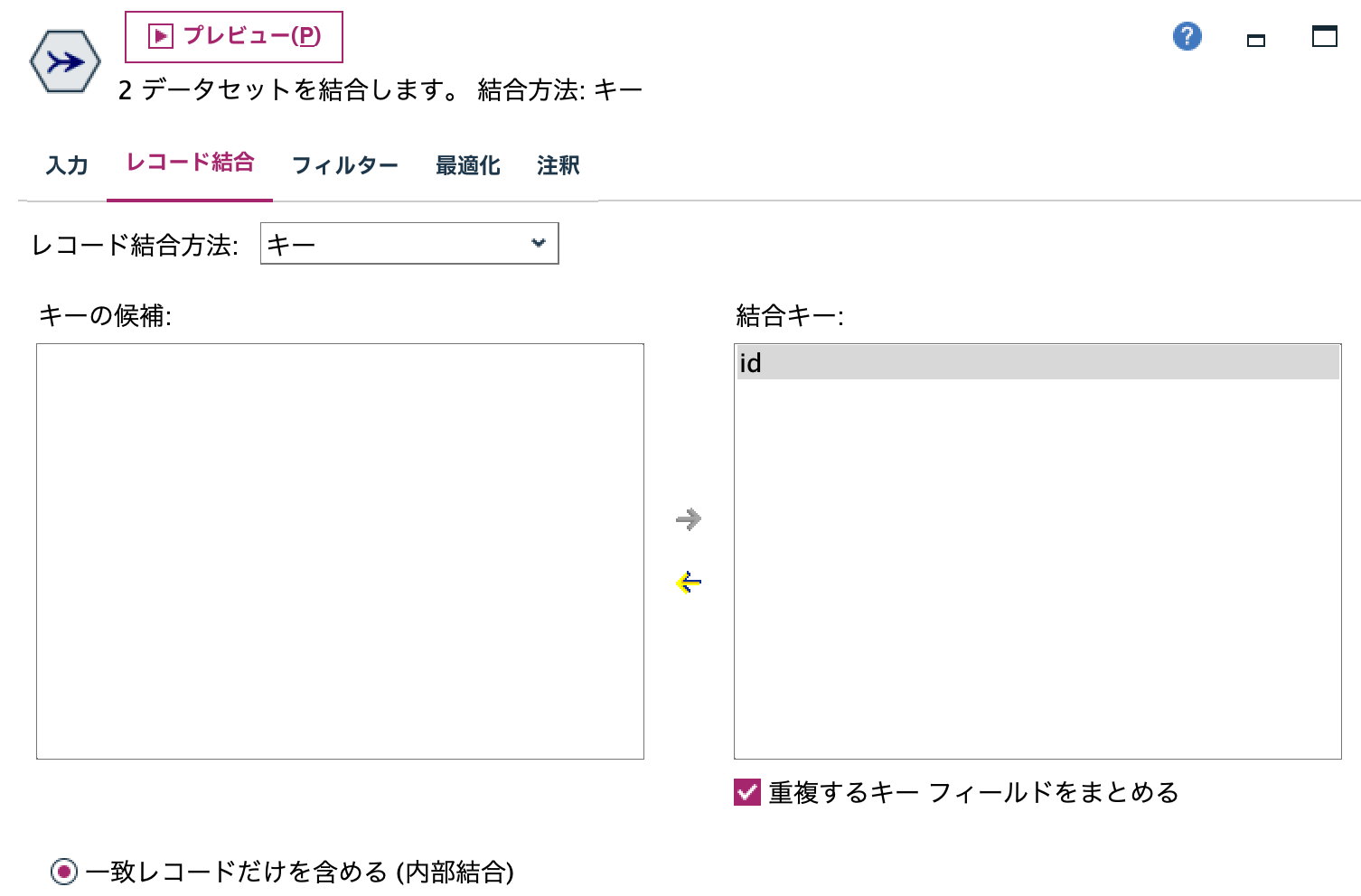
e.[レコード結合]ノードを編集します。
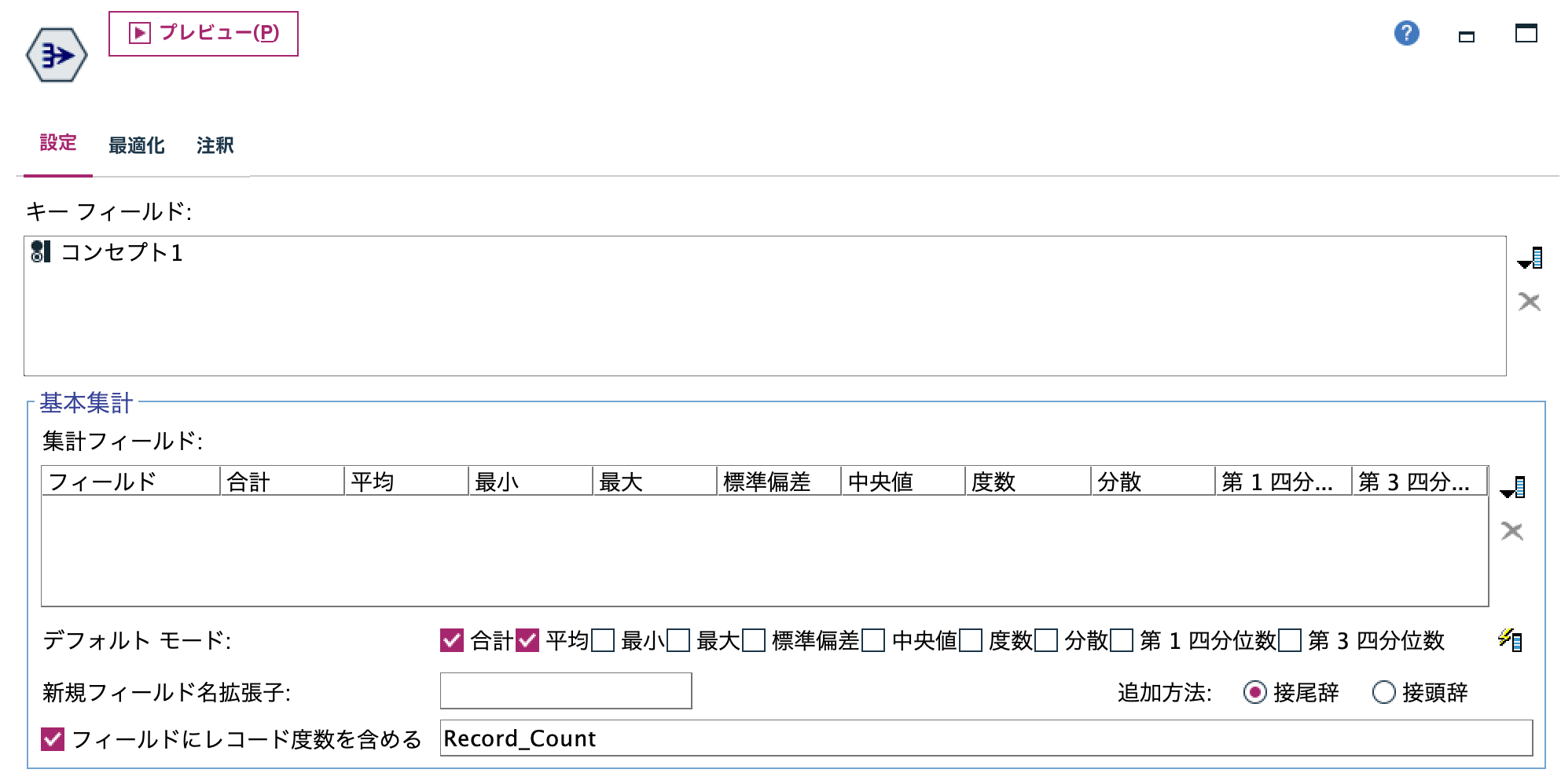
f.[レコード集計]ノードを編集します。頻度の多いコンセプトに絞るため集計します。
g.[レコード結合]ノードを編集します。結果的に不要なノードですが、ストリーム作成時にはここで
テーブル出力しカッとオフする件数を確定します。
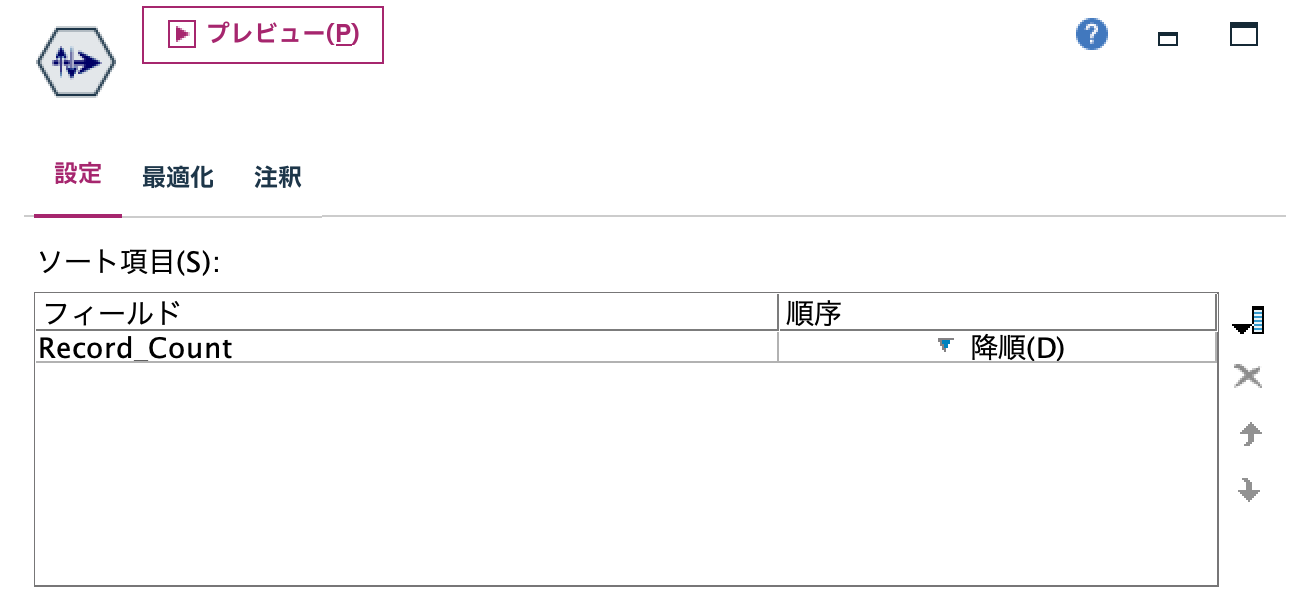
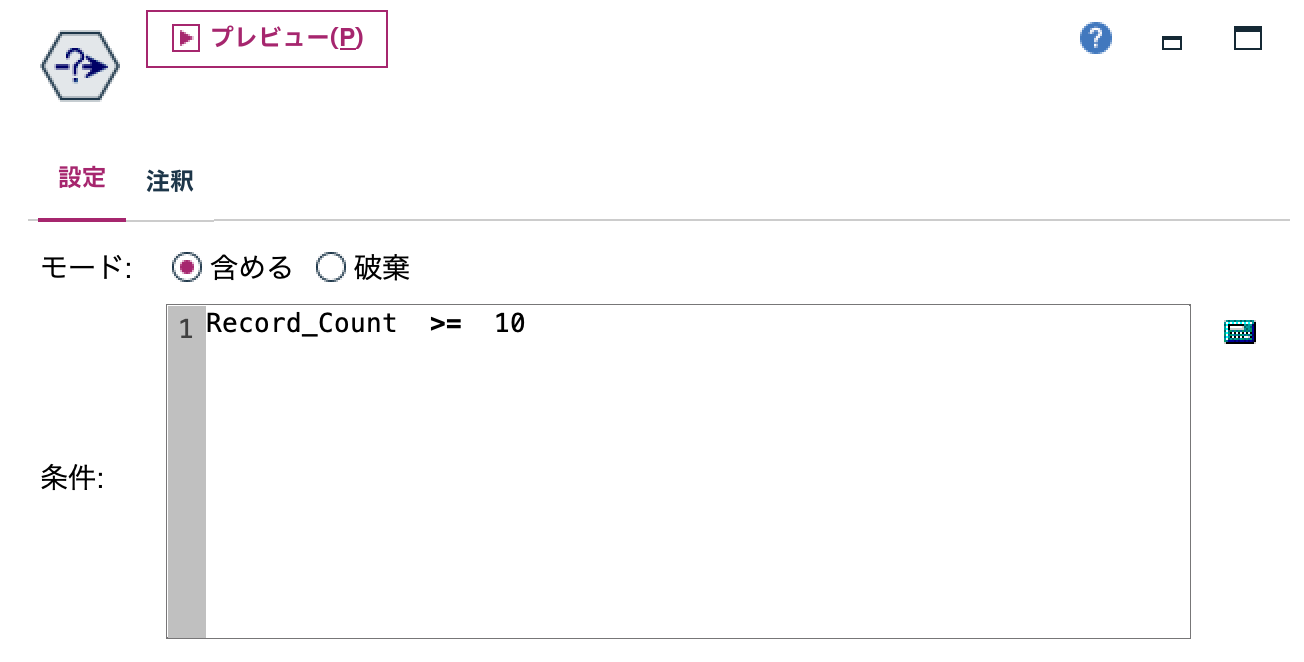
h.[レコード抽出]ノードを編集します。10以上のコンセプトに絞っています。
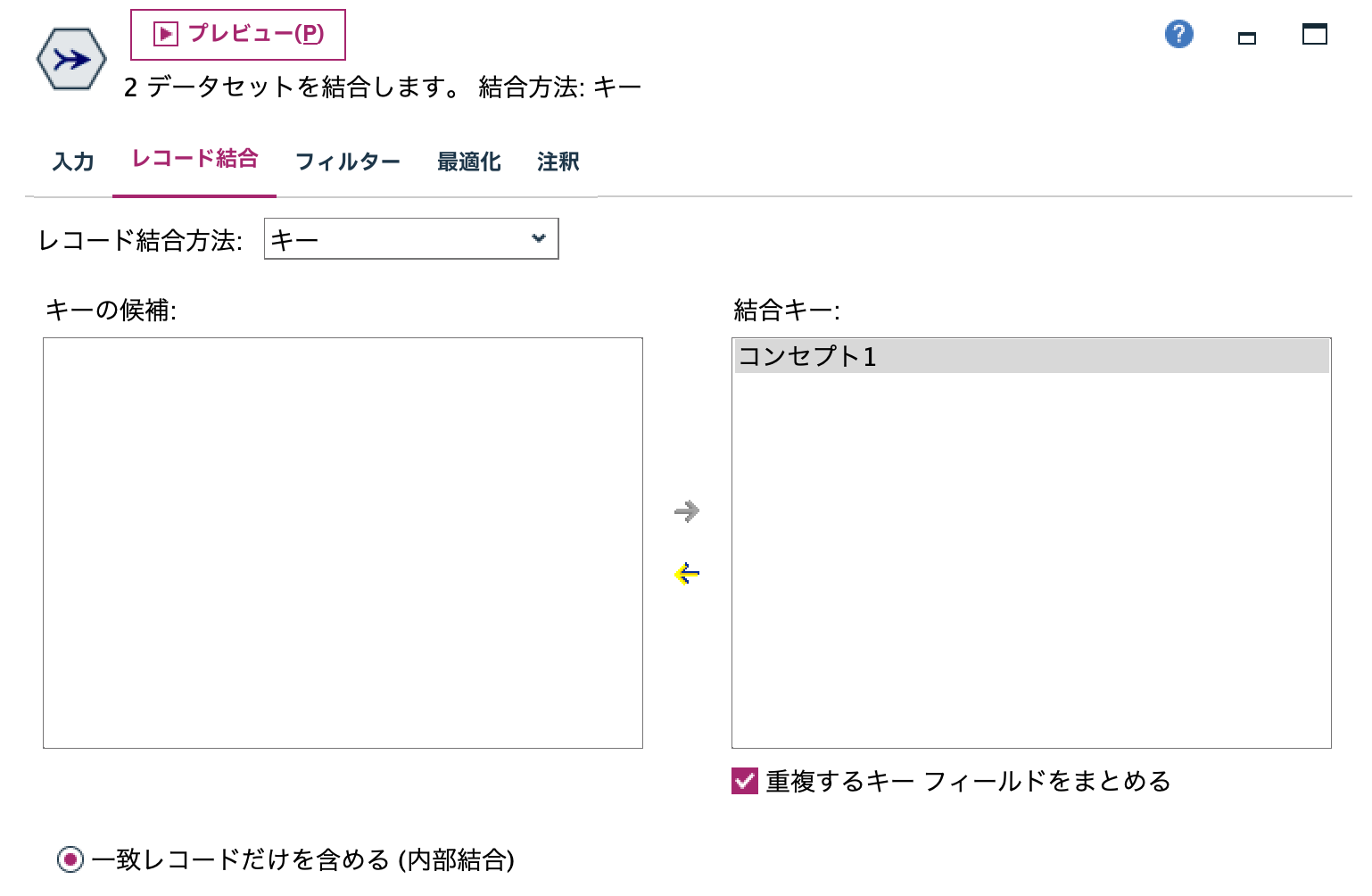
i.[レコード結合]ノードを編集します。
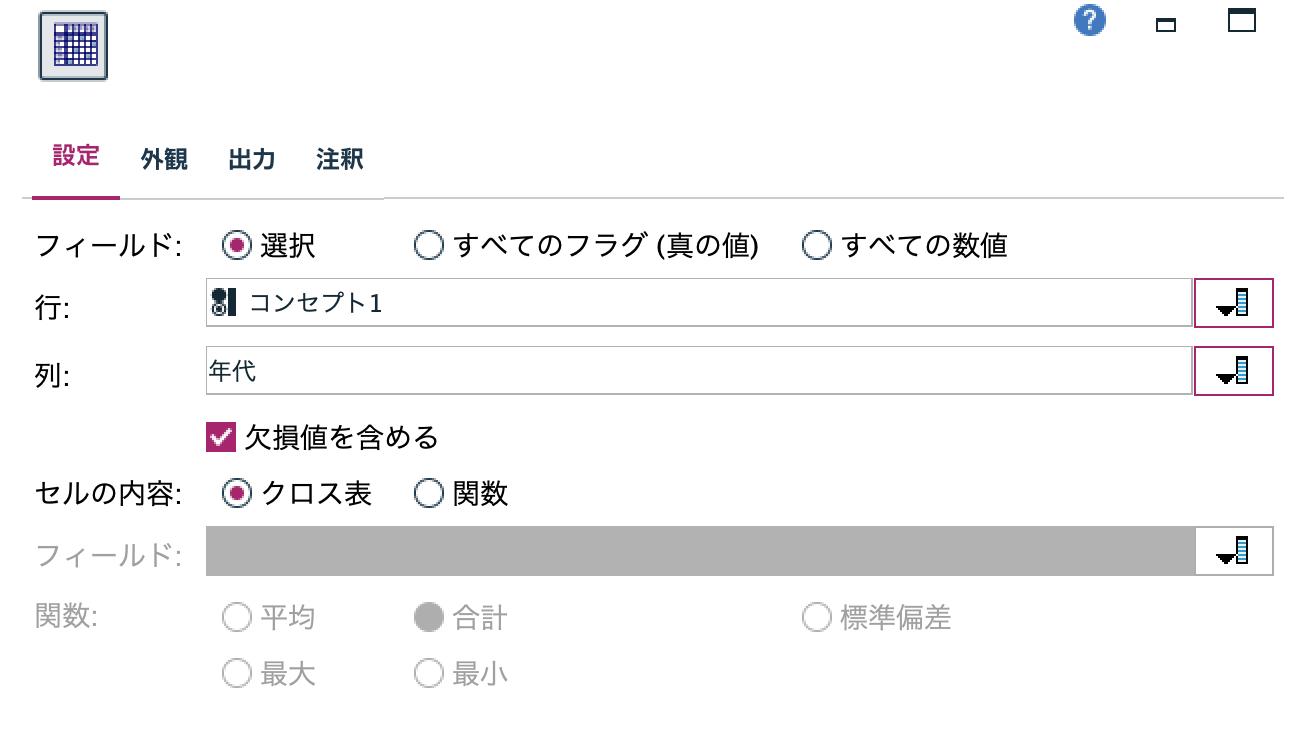
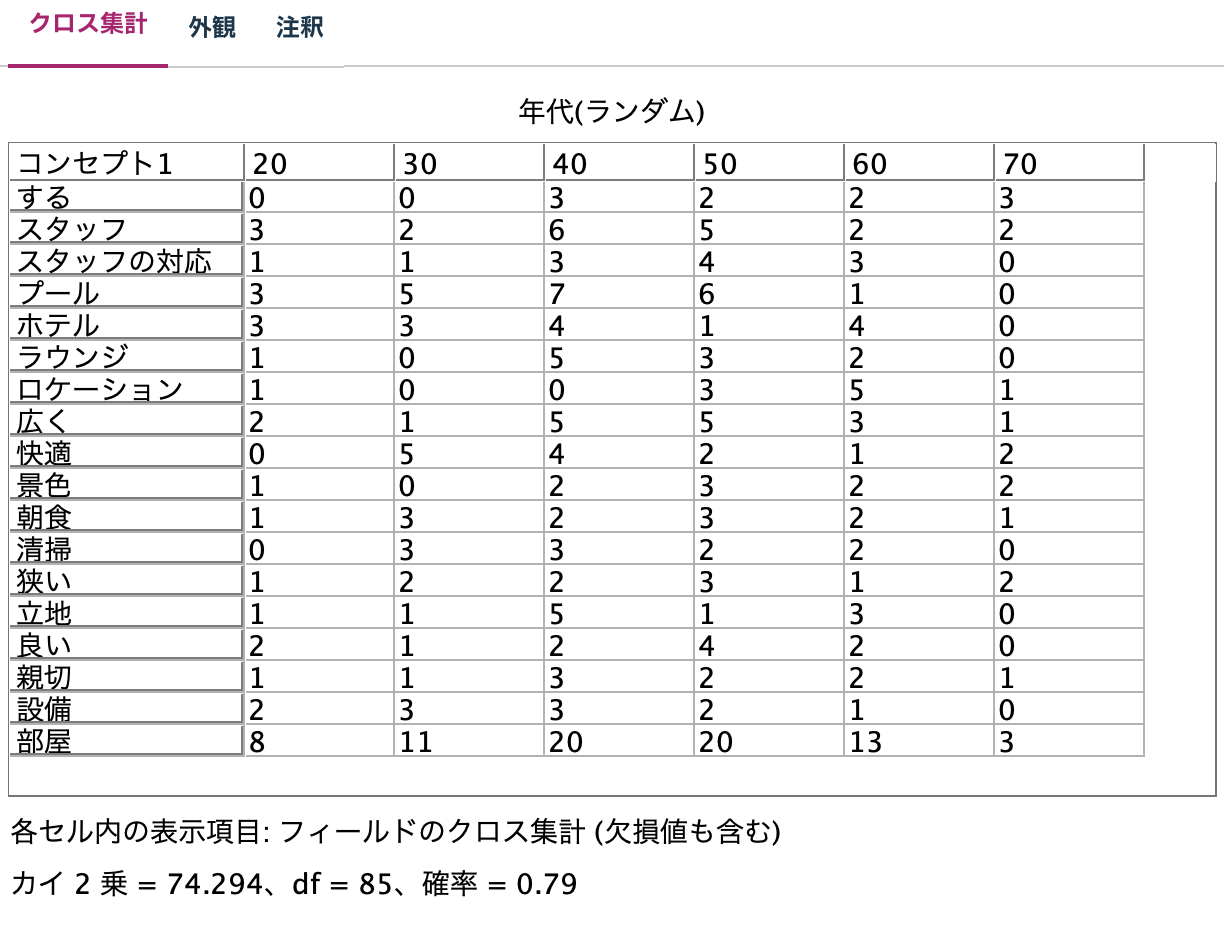
j.[クロス集計]ノードを編集します。
実行します。[年代]が毎回ランダムに割り振られるので出力は都度異なります。
注意事項
[年代]が毎回ランダムに割り振られるので出力は都度異なります。
4.参考情報
Python連携によるテキストマイニング
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)